Shell编程笔记(二)
Shell常用命令
1 expr 命令
求表达式变量的值
注意:
注意:
- 运算符、每个数字之间都是要有空格的,不然就是一个字符串;
- 使用乘号的时候要使用转义符号
\*; - 四则运算中,使用了小括号(),也需要转义
\( 1 + 1 \); - 只对整数进行运算。
expr用法:
注:
(1)、数值表达式("+ - * / %")和比较表达式("< <= = == != >= >")会先将两端的参数转换为数值,转换失败将报错。所以可借此来判断参数或变量是否为整数
(2)、expr中的很多符号需要转义或使用引号包围
(3)、所有操作符的两边,都需要有空格
举例:
(1)、计算字串长度
[root@kk bkeep]# expr length "bkeep zbb" {包含空格在内}
9
(2)、抓取字串
[root@kk bkeep]# expr substr "bkeep zbb" 4 9
ep zbb
(3)、抓取第一个字符数字串出现的位置
[root@kk bkeep]# expr index "bkeep zbb" e
3
(4)、整数运算
[root@kk bkeep]# expr 14 % 9
5
[root@kk bkeep]# expr 30 / 3 / 2 {运算符与数字间一定要有空格}
5
(5)、增量计数
说明:expr在循环中用于增量计算。先将变量初始化为0,然后循环值加1
LOOP=0
LOOP=`expr $LOOP + 1`
(6)、数值测试
说明:用expr测试一个数。如果试图计算非整数,则会返回错误。
rr=3.4
expr $rr + 1
expr: non-numeric argument
rr=5
expr $rr + 1
6
(7)、模式匹配
说明:expr也有模式匹配功能。可以使用expr通过指定冒号选项计算字符串中字符数。
.* 表示任何字符重复0次或多次
[root@kk bkeep]# expr bkeep.doc : '.*'
9
(8)、在expr中可以使用字符串匹配操作,这里使用模式抽取.doc文件附属名。
[root@kk bkeep]# expr bkeep.doc : '.*.doc'
bkeep
2 seq 命令
打印数字序列,用于生成从一个数到另一个数之间的所有整数。
用法:
seq [选项] 尾数
seq [选项] 首数 尾数
seq [选项] 首数 增量 尾数
选项:
-f, --format=FORMAT : 指定输出格式
-s,–separator=STRING : 指定分隔符
-w,–equal-width: 指定输出数字同宽
–help 显示此帮助信息并退出
–version 显示版本信息并退出
拓展:
%g用来输出实数,它根据数值的大小,自动选f格式或e格式(选择输出时占宽度较小的一种),
且不输出无意义的0。即%g是根据结果自动选择科学记数法还是一般的小数记数法。
对于指数小于-4或者大于给定精度的数值,按照%e的控制输出,否则按照%f的控制输出。
%02g : 02表示不足两位,前面补0输出;超过两位的不影响。
3 awk命令
3.1 介绍
awk是一种强大的编辑工具,相较于sed常常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理,因为awk相当适合小型的文本数据。
awk 比较倾向于将一行分成多个字段然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
3.2 工作原理
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
在使用awk命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||”表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
3.3 格式
awk 选项 '模式或条件 {操作}' 文件 1 文件 2 …
awk -f 脚本文件 文件 1 文件 2 …
3.4 常见的内建变量
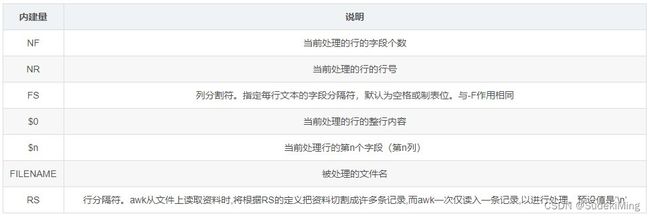
3.5 awk命令使用——BEGIN、END模式
(1)格式
awk 'BEGIN{...}; {...}; END{...}' 文件
- BEGIN模式是在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;
- awk再处理指定的文本,之后再执行END模式中指定的动作;
- END{ } 语句块中,往往会放入打印结果等语句。
4 fsck.ext4命令
fsck.ext4命令语法
fsck.ext4[必要参数][选择参数][设备代号]
功能
fsck.ext4命令只针对ext4型文件系统进行检测。如果你使用的是ext3文件系统,请使用fack.ext3命令。
#参数
-a 非互交模式,自动修复
-c 检查是否存在有损坏的区块。
-C<反叙述器> fsck.ext3命令会把全部的执行过程,都交由其逆向叙述,便于监控程序
-d 详细显示命令执行过程
-f 强制进行检查
-F 检查文件系统之前,先清理该保存设备块区内的数据
-l<损坏区块文件> 把文件中所列出的损坏区块,加入标记
-L<损坏区块文件> 清除所有损坏标志,重新标记
-n 非交互模式,把欲检查的文件系统设成只读
-P<数字> 设置fsck.ext2命令所能处理的inode大小为多少
-r 交互模式
-R 忽略目录
-s 顺序检查
-S 效果和指定“-s”参数类似
-t 显示fsck.ext2命令的时序信息。
-v 显示详细的处理过程
-y 关闭互动模式
-b<分区第一个磁区地址> 指定分区的第一个磁区的起始地址/Super Block
-B<区块大小> 设置该分区每个区块的大小
-I 设置欲检查的文件系统,其inode缓冲区的区块数目
-V 显示版本信息
5 挂载命令mount
5.1 语法
mount [-hV]
mount -a [-fFnrsvw] [-t vfstype]
mount [-fnrsvw] [-o options [,...]] device | dir
mount [-fnrsvw] [-t vfstype] [-o options] device dir
5.2 参数选项
#参数说明:
-V:显示程序版本
-h:显示辅助讯息
-v:显示较讯息,通常和 -f 用来除错。
-a:将 /etc/fstab 中定义的所有档案系统挂上。
-F:这个命令通常和 -a 一起使用,它会为每一个 mount 的动作产生一个行程负责执行。在系统需要挂上大量 NFS 档案系统时可以加快挂上的动作。
-f:通常用在除错的用途。它会使 mount 并不执行实际挂上的动作,而是模拟整个挂上的过程。通常会和 -v 一起使用。
-n:一般而言,mount 在挂上后会在 /etc/mtab 中写入一笔资料。但在系统中没有可写入档案系统存在的情况下可以用这个选项取消这个动作。
-s-r:等于 -o ro
-w:等于 -o rw
-L:将含有特定标签的硬盘分割挂上。
-U:将档案分割序号为 的档案系统挂下。-L 和 -U 必须在/proc/partition 这种档案存在时才有意义。
-t:指定档案系统的型态,通常不必指定。mount 会自动选择正确的型态。
-o async:打开非同步模式,所有的档案读写动作都会用非同步模式执行。
-o sync:在同步模式下执行。
-o atime、-o noatime:当 atime 打开时,系统会在每次读取档案时更新档案的『上一次调用时间』。当我们使用 flash 档案系统时可能会选项把这个选项关闭以减少写入的次数。
-o auto、-o noauto:打开/关闭自动挂上模式。
-o defaults:使用预设的选项 rw, suid, dev, exec, auto, nouser, and async.
-o dev、-o nodev-o exec、-o noexec允许执行档被执行。
-o suid、-o nosuid:
允许执行档在 root 权限下执行。
-o user、-o nouser:使用者可以执行 mount/umount 的动作。
-o remount:将一个已经挂下的档案系统重新用不同的方式挂上。例如原先是唯读的系统,现在用可读写的模式重新挂上。
-o ro:用唯读模式挂上。
-o rw:用可读写模式挂上。
-o loop=:使用 loop 模式用来将一个档案当成硬盘分割挂上系统。
6 卸载命令umount
语法:
umount [-ahnrvV] [-t <文件系统类型>] [文件系统]
参数:
-a 卸除/etc/mtab中记录的所有文件系统。
-h 显示帮助。
-n 卸除时不要将信息存入/etc/mtab文件中。
-r 若无法成功卸除,则尝试以只读的方式重新挂入文件系统。
-t<文件系统类型> 仅卸除选项中所指定的文件系统。
-v 执行时显示详细的信息。
-V 显示版本信息。
拓展:
1、直接卸载
[root@localhost /]# umount /data1/img
umount: /data1/img: device is busy
umount: /data1/img: device is busy
2、提示被占用,使用强制卸载
[root@localhost /]# umount -f /data1/img
umount2: Device or resource busy
umount: /data1/img: device is busy
umount2: Device or resource busy
umount: /data1/img: device is busy
注: 使用-f 参数进行强制卸载时一般建议等一会儿再进行下面的操作,一些情况下处理需要1-2分钟的时间。
7 eval命令
功能说明:告知shell取出eval的参数,重新运算求出参数的内容。
语 法:eval [参数]
补充说明:eval可读取一连串的参数,然后再依参数本身的特性来执行。
参 数:参数不限数目,彼此之间用分号分开。
eval 执行以下两个步骤:
第一步,执行变量替换,类似与C语言的宏替代;
第二步,执行替换后的命令串。
例:
1、执行含有带字符串的命令
我们可以新建一个文件test将字符串”HelloWorld!“写入文件中,把cat test赋值给变量WORD,如果我们echo WORD并不能的到test中的内容;然而eval WORD则能显示文件中的内容,因为eval命令对后面的命令进行了两次扫描,第一次将WORD替换为 cat test,第二次执行cat test。
这些需要进行两次扫描的变量有时被称为复杂变量。不过这些变量本身并不复杂。eval命令不仅可以回显复杂变量,也可以用于回显简单变量。
2、回显简单变量
echo SNAME
eval echo SNAME
3、eval命令还可以获取传给shell的最后一个参数
如果我们知道参数个数,我们想要查看最后一个参数的内容可以使用echo直接显示,如输入 first last两个参数我们可以用echo $2 来查看最后一个参数;
但是,如果我们不知道参数个数还想查看最后一个参数内容该怎么办呢?这是我们就想到使用 KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲为传给shell脚本的参数个数…#”后显示的其实是参数个数,而使用eval echo “$$#”才显示最后一个参数的内容。
4、条件筛选
在file文件中写入两列数据,第一列对应KEY 、第二列为VALUE,使用eval命令将KEY与VALUE的值对应起来,从文件中读取
8 使用sgdisk进行磁盘分区
fdisk创建MBR分区,sgdisk创建GPT分区
gdisk软件包中包含sgdisk命令。 需要事先安装gdisk
apt-get install gdisk
sgdisk是Linux下操作GPT分区的工具, sgdisk程序使用完全基于命令行的用户界面,使其适用于脚本或想要对磁盘进行一次或两次快速更改的专家。
#语法格式
sgdisk [参数] [设备]
常用参数:
| p | 打印分区表 |
|---|---|
| -d x | 删除分区 |
| -n x:y:z | 创建一个编号 x 的新分区,从 y扇区 开始,到 z扇区 结束 |
| -c x:y | 更改分区 x 的名称为 y |
| -t x:y | -t x:y 将分区 x 的类型更改为 y |
| –list-types | 列出分区类型代码 |
例:
#格式化磁盘设备清除所有分区数据
sgdisk -Z -o /dev/mmcblk0
-Z Zap(销毁)GPT和MBR数据结构,然后退出
-o 清除所有分区数据
#重读分区表
partprobe /dev/mmcblk0
9 mkfs.ext4
其功能是用于对磁盘设备进行Ext4格式化的操作。
语法格式:
mkfs.ext4 [参数] 设备
常用参数:
| -c | 格式化前检查分区是否有坏块 |
|---|---|
| -q | 执行时不显示任何信息 |
| -b | 指定block size大小 |
| -F | 强制格式化 |
10 fdisk 和 parted磁盘分区命令
在 Linux 中有专门的分区命令 fdisk 和 parted。其中 fdisk 命令较为常用,但不支持大于 2TB 的分区;如果需要支持大于 2TB 的分区,则需要使用 parted 命令,当然 parted 命令也能分配较小的分区。我们先来看看如何使用 fdisk 命令进行分区。
#查看当前系统的磁盘分区情况
fdisk -l
#例:
#查看磁盘指定分区情况
fdisk -l /dev/mmcblk0
#查看磁盘指定分区情况
fdisk -l /dev/mmcblk1
fdisk -l 显示所有磁盘分区的信息
如果有多个磁盘,会依次显示全部的磁盘,每个磁盘信息会列出其分区信息。
# fdisk -l
Disk /dev/vda: 107.4 GB, 107374182400 bytes, 209715200 sectors '// 扇区个数'
Units = sectors of 1 * 512 = 512 bytes '// 柱面单元大小 (一个扇区作为一个柱面)'
Sector size (logical/physical): 512 bytes / 512 bytes '// 扇区大小'
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x00040353
Device Boot Start End Blocks Id System
/dev/vda1 * 2048 1026047 512000 83 Linux
/dev/vda2 1026048 209715199 104344576 8e Linux LVM
参数解释:
Device: 分区,这里有2个分区;
Boot: 启动分区,`用*表示的是启动分区`;
Start: 表示开始的柱面:
End: 表示结束的在面;
Blocks:block 块数量;
Id: 分区类型Id;
System: 分区类型。
-
总磁盘大小: 107374182400 bytes(B) / 1024 = 104857600 KB / 1024 = 102400 MB / 1024 = 100 GB
-
每个柱面的大小Units: 512 bytes (这里一个柱面一个扇区)
-
扇区个数是sectors: 107374182400 bytes / 512 bytes = 209715200
-
/dev/vda1的大小是:柱面数=1026047(结束位置)-2048(起始位置) = 1023999 约等于1024000.
那么/dev/vda1的大小 = 1024000 × 512 bytes = 524288000 bytes / 1024 = 512000 K / 1024 = 500M
-
/dev/vda2的大小是:(209715199 - 1026048) × 512 bytes / 1024 / 1024 / 1024 = 99.5G
# 命令
fdisk [选项] [设备名]
# 命令选项(参数)
p 打印分区表。
n 新建一个新分区。
d 删除一个分区。
q 退出不保存。
w 把分区写进分区表,保存并退出。
注意,千万不要在当前的硬盘上尝试使用 fdisk,这会完整删除整个系统,一定要再找一块硬盘,或者使用虚拟机。
输入 fdisk /dev/sda,可进入分割硬盘模式
| 命令 | 说 明 |
|---|---|
| a | 设置可引导标记 |
| b | 编辑 bsd 磁盘标签 |
| c | 设置 DOS 操作系统兼容标记 |
| d | 删除一个分区 |
| 1 | 显示已知的文件系统类型。82 为 Linux swap 分区,83 为 Linux 分区 |
| m | 显示帮助菜单 |
| n | 新建分区 |
| 0 | 建立空白 DOS 分区表 |
| P | 显示分区列表 |
| q | 不保存退出 |
| s | 新建空白 SUN 磁盘标签 |
| t | 改变一个分区的系统 ID |
| u | 改变显示记录单位 |
| V | 验证分区表 |
| w | 保存退出 |
| X | 附加功能(仅专家) |
11 swupdate
swupdate -v -i /media/d9_tf*.swu
12 Linux系统日志命令 logger
12.1 logger语法
#命令格式
logger [options] [messages]
#参数
选项 说明
-d 使用数据报(UDP)而不是使用默认的流连接(TCP)连接到此套接字。
-i 逐行记录每一次logger的进程ID。
-f file_name 记录特定的文件。
-p priority_level 指定输入消息的优先级,默认级别是 “user.notice”。
-s 将消息记录到标准错误以及系统日志。
-t tag 指定标记,标记记录中的每一行。
-u socket 按指定的方式写入socket,而不是系统日志例程。
12.2 消息日志级别优先级 " facility.level" 的格式
-p priority_level 优先级可以是数字或者指定为 “facility.level” 的格式。比如:"-p local3.info " local3 这个设备的消息级别为info。
例:" -p local3.info " 表示自定义local3 这个设备的消息级别为 info。消息日志默认级别是 “user.notice”。
facility:用来定义由谁产生的日志信息,即哪个软件、子系统运行过程中产生的日志信息。
选项 说明
auth 用户授权。
authpriv 授权和安全。
cron 计划任务。
daemon 系统守护进程。
kern 与内核有关的信息。
lpr 与打印服务有关的信息。
mail 与电子邮件有关的信息。
news 来自新闻服务器的信息。
syslog 由syslog生成的信息。
user 用户的程序生成的信息,默认值。
ftp 来自ftp服务器的信息。
uucp 由uucp生成的信息。
local0~7 用来定义本地策略。
level:用来定义记录什么类型的日志信息。
选项 说明
debug 7,调试。
info 6,正常消息。
notice 5,正常但是要注意,默认值。
warning 4,警告。
error 3,错误状态。
crit 2,临界状态。
alert 1,需要立即采取动作。
emerg 0,系统不可用。
例:本机运行命令,生成messages日志
logger -i -t “my_test” -p local3.notice “test_info”
命令说明:
-i :在每行都记录logger进程ID;
-t my_test:每行记录都加上“my_test”这个标签;
-p local3.notice :设置记录的设备local3的级别为notice;
“test_info”:输出信息为test_info。
13 创建一个文件shell命令 touch
touch [文件名.文件扩展名]
eg:
touch hello.sh
14 tar常用解压命令
# .tar.gz 格式解压为
tar -zxvf xx.tar.gz
# .tar.bz2 格式解压为
tar -jxvf xx.tar.bz2
# .tar.xz 格式解压为
tar -xvf xx.tar.xz
15 dmesg 命令
Dmesg用于显示内核环形缓冲区的内容,内核在其中存储各种消息。
#查看命令版本
dmesg -V
#获取命令帮助
dmesg -help
#查看所有开机日志信息
dmesg
#过滤想查看信息,建议使用-i参数过滤时忽略大小写
dmesg |grep -i cpu
#打印并清除内核环形缓冲区
dmesg-c
使用语法:
dmesg [选项]
参数选项 参数说明
-C, --clear 清除内核环形缓冲区(ring butter)
-c, --read-clear 读取并清除所有消息
-D, --console-off 禁止向终端打印消息
-d, --show-delta 显示打印消息之间的时间差
-e, --reltime 以易读格式显示本地时间和时间差
-E, --console-on 启用向终端打印消息
-F, --file <文件> 用 文件 代替内核日志缓冲区
-f, --facility <列表> 将输出限制为定义的设施
-H, --human 易读格式输出
-k, --kernel 显示内核消息
-L, --color 显示彩色消息
-l, --level <列表> 限制输出级别
-n, --console-level <级别> 设置打印到终端的消息级别
-P, --nopager 不将输出通过管道传递给分页程序
-r, --raw 打印原生消息缓冲区
-S, --syslog 强制使用 syslog(2) 而非 /dev/kmsg
-s, --buffer-size <大小> 查询内核环形缓冲区所用的缓冲区大小
-T, --ctime 显示易读的时间戳(如果您使用了SUSPEND/RESUME 则可能不准)
-t, --notime 不打印消息时间戳
-u, --userspace 显示用户空间消息
-w, --follow 等待新消息
-x, --decode 将设施和级别解码为可读的字符串
-h, --help 显示此帮助并退出
-V, --version 输出版本信息并退出
16 find命令
实时查找工具,通过遍历指定路径下的文件系统完成文件查找。
find命令的工作方式如下:沿着文件层次结构向下遍历,匹配符合条件的文件,执行响应的操作。
语法:
find [options]… [查找条件][处理动作]
查找路径:指定具体的目标路径,默认为当前目录。
查找条件:指定的查找标准,可以是文件名、大小、类型、权限等,默认为找出指定路径下的所有文件。
16.1 根据文件名查找
-name “文件名称”:支持通配符查找;
-iname “文件名称”:不区分文件名大小写;
例:
#匹配/home/dou目录下所有以.txt为结尾的文件
find /home/dou -name "*.txt" -print
16.2 根据属主、属组查找
-user USERNAME:查找属主为指定用户的文件;
-group GROUPNAME:查找属组为指定用户的文件;
-uid USERID:查找属主为指定uid号的文件;
-gid GroupID:查找属组为指定GID号的文件;
-nouser:查找没有属主的文件;
-nogroup:查找没有属组的文件;
例:
#打印出当前目录下sudeki拥有的所有文件
find . -type f -user sudeki -print
16.3 根据文件类型查找
#-type TYPE
f:普通文件;
d:目录文件;
l:符号链接文件;
s:套接字文件;
b:块设备文件;
c:字符设备文件;
p:管道文件;
例:
#匹配当前目录下所有的目录文件
find . -type d -print
16.4 组合条件
与:-a
或:-o
非:-not,!
例:
#匹配包含这两种文件类型的文件
find . \(-name "*.txt" -o "*.pdf"\) -print
16.5 根据文件大小进行查找
-size [+,-]num单位,常用单位有:k、M、G
num单位:显示的是大于num-1,小于等于num这个区间内的值;
-num单位:显示的是大于等于0,小于等于num-1区间内的值;
+num单位:大于num至无穷大区间内的所有值;
例:
#匹配当前目录下大于2K的文件
find . -type f -size +2k
16.6 根据文件时间进行查找
访问时间(-atime):用户最近一次访问文件的时间;
修改时间(-mtime):文件内容最后一次被修改的时间;
变换时间(-ctime):文件元数据(例如权限和所有权)最后一次改变的时间
例:
#匹配打印最近7天内别访问的所有文件
find . -type f -atime -7 -print
amin:访问时间-分钟
-mmin:修改时间-分钟
-cmin:变化时间-分钟
例:
#打印出访问时间超过7分钟的所有文件
find . -type -amin +7 -print
16.7 根据目录的深度进行查找
-mindepth
-maxdepth
选项来限制find命令遍历的目录深度
例:
#列出当前目录下的所有以f开头的文件,即使有子目录,也不会被打印和遍历
find . -maxdepth 1 -name "f*" -print
17 处理动作
-print:默认处理动作,显示至屏幕;
-ls:类似于对查找到的文件执行"ls -l"命令;
-delete:删除查找到的文件
-fls /PATH/TO/SOMEFILE:查找到的所有文件的长格式信息保存至指定文件中
18 xargs命令
xargs可以读取标准输入和管道中的数据,用于弥补有些命令(如echo、kill、rm)不能从管道中读取数据的不足。
#命令参数
-0(数字零)默认以空格、Tab制表符、回车符为分隔符和结束符,当有的文件本身包含空格时,就会出问题
-n 指定一次读取几个参数
-I 指定一个替换字符串
-i 与-I类似,如果不指定替换符,默认为{}
-r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。
19 chmod 给权限指令
19.1 linux系统下的文件颜色含义
绿色文件: 可执行文件,可执行的程序
红色文件:压缩文件或者包文件
蓝色文件:目录
白色文件:一般性文件,如文本文件,配置文件,源码文件等
浅蓝色文件:链接文件,主要是使用ln命令建立的文件
红色闪烁:表示链接的文件有问题
黄色:表示设备文件
灰色:表示其他文件
19.2 chmod +x的使用
chmod +x就是赋予用0户文件的执行权限
#命令格式
chmod +x 文件名(包括扩展后缀)
chmod u+x代表设置某个用户获得执行文件的权限
u 代表用户.
g 代表用户组.
o 代表其他.
a 代表所有
19.3 chmod +x和chmod 777区别
chmod +x 是将文件状态改为可执行,而chmod 777 是改变文件读写权限。
注:777 代表 rwxrwxrwx 所有用户都可读可写可执行。
20 查看内核版本指令
#用于显示系统信息
uname -a
#语法
uname [-amnrsv][--help][--version]
#参数选项
-a或--all 显示全部的信息。
-m或--machine 显示电脑类型。
-n或--nodename 显示在网络上的主机名称。
-r或--release 显示操作系统的发行编号。
-s或--sysname 显示操作系统名称。
-v 显示操作系统的版本。
--help 显示帮助。
--version 显示版本信息。
21 file命令
file命令用于辨识文件类型
#语法
file [-bcLvz][-f <名称文件>][-m <魔法数字文件>...][文件或目录...]
#参数选项
-b 列出辨识结果时,不显示文件名称。
-c 详细显示指令执行过程,便于排错或分析程序执行的情形。
-f<名称文件> 指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称。
-L 直接显示符号连接所指向的文件的类别。
-m<魔法数字文件> 指定魔法数字文件。
-v 显示版本信息。
-z 尝试去解读压缩文件的内容。
[文件或目录...] 要确定类型的文件列表,多个文件之间使用空格分开,可以使用shell通配符匹配多个文件。
22 rsync命令
rsync是linux系统下的数据镜像备份工具。使用快速增量备份工具Remote Sync可以远程同步,支持本地复制,或者与其他SSH、rsync主机同步。
rsync支持很多特性:
- 可以镜像保存整个目录树和文件系统
- 可以很容易做到保持原来文件的权限、时间、软硬链接等等
- 无须特殊权限即可安装
- 快速:第一次同步时rsync会复制全部内容,但在下一次只传输修改过的文件。rsync在传输数据的过程中可以实行压缩及解压缩操作,因此可以使用更少的带宽
- 安全:可以使用scp、ssh等方式来传输文件,当然也可以通过直接的socket连接
- 支持匿名传输,以方便进行网站镜像
#Rsync的命令格式常用的有以下三种:
rsync [OPTION]... SRC DEST
rsync [OPTION]... SRC [USER@]HOST:DEST
rsync [OPTION]... [USER@]HOST:SRC DEST
#rsync常用选项
-a, --archive #归档
-v, --verbose #啰嗦模式
-q, --quiet #静默模式
-r, --recursive #递归
-p, --perms #保持原有的权限属性
-z, --compress #在传输时压缩,节省带宽,加快传输速度
--delete #在源服务器上做的删除操作也会在目标服务器上同步
#rsync参数选项
一般同步传输目录都使用azv选项.
-v, --verbose 详细模式输出
-q, --quiet 精简输出模式
-c, --checksum 打开校验开关,强制对文件传输进行校验
-a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性,等于-rlptgoD
-r, --recursive 对子目录以递归模式处理
-R, --relative 使用相对路径信息
-b, --backup 创建备份,也就是对于目的已经存在有同样的文件名时,将老的文件重新命名为~filename。可以使用--suffix选项来指定不同的备份文件前缀。
--backup-dir 将备份文件(如~filename)存放在在目录下。
-suffix=SUFFIX 定义备份文件前缀
-u, --update 仅仅进行更新,也就是跳过所有已经存在于DST,并且文件时间晚于要备份的文件。(不覆盖更新的文件)
-l, --links 保留软链结
-L, --copy-links 想对待常规文件一样处理软链结
--copy-unsafe-links 仅仅拷贝指向SRC路径目录树以外的链结
--safe-links 忽略指向SRC路径目录树以外的链结
-H, --hard-links 保留硬链结
-p, --perms 保持文件权限
-o, --owner 保持文件属主信息
-g, --group 保持文件属组信息
-D, --devices 保持设备文件信息
-t, --times 保持文件时间信息
-S, --sparse 对稀疏文件进行特殊处理以节省DST的空间
-n, --dry-run现实哪些文件将被传输
-W, --whole-file 拷贝文件,不进行增量检测
-x, --one-file-system 不要跨越文件系统边界
-B, --block-size=SIZE 检验算法使用的块尺寸,默认是700字节
-e, --rsh=COMMAND 指定使用rsh、ssh方式进行数据同步
--rsync-path=PATH 指定远程服务器上的rsync命令所在路径信息
-C, --cvs-exclude 使用和CVS一样的方法自动忽略文件,用来排除那些不希望传输的文件
--existing 仅仅更新那些已经存在于DST的文件,而不备份那些新创建的文件
--delete 删除那些DST中SRC没有的文件
--delete-excluded 同样删除接收端那些被该选项指定排除的文件
--delete-after 传输结束以后再删除
--ignore-errors 及时出现IO错误也进行删除
--max-delete=NUM 最多删除NUM个文件
--partial 保留那些因故没有完全传输的文件,以是加快随后的再次传输
--force 强制删除目录,即使不为空
--numeric-ids 不将数字的用户和组ID匹配为用户名和组名
--timeout=TIME IP超时时间,单位为秒
-I, --ignore-times 不跳过那些有同样的时间和长度的文件
--size-only 当决定是否要备份文件时,仅仅察看文件大小而不考虑文件时间
--modify-window=NUM 决定文件是否时间相同时使用的时间戳窗口,默认为0
-T --temp-dir=DIR 在DIR中创建临时文件
--compare-dest=DIR 同样比较DIR中的文件来决定是否需要备份
-P 等同于 --partial
--progress 显示备份过程
-z, --compress 对备份的文件在传输时进行压缩处理
--exclude=PATTERN 指定排除不需要传输的文件模式
--include=PATTERN 指定不排除而需要传输的文件模式
--exclude-from=FILE 排除FILE中指定模式的文件
--include-from=FILE 不排除FILE指定模式匹配的文件
--version 打印版本信息
--address 绑定到特定的地址
--config=FILE 指定其他的配置文件,不使用默认的rsyncd.conf文件
--port=PORT 指定其他的rsync服务端口
--blocking-io 对远程shell使用阻塞IO
-stats 给出某些文件的传输状态
--progress 在传输时现实传输过程
--log-format=formAT 指定日志文件格式
--password-file=FILE 从FILE中得到密码
--bwlimit=KBPS 限制I/O带宽,KBytes per second
-h, --help 显示帮助信息
rsync与传统的cp、tar备份方式相比,rsync具有安全性高、备份迅速、支持增量备份等优点,通过rsync可以解决对实时性要求不高的数据备份需求,例如定期的备份文件服务器数据到远端服务器,对本地磁盘定期做数据镜像等。
随着应用系统规模的不断扩大,对数据的安全性和可靠性也提出的更好的要求,rsync在高端业务系统中也逐渐暴露出了很多不足,首先,rsync同步数据时,需要扫描所有文件后进行比对,进行差量传输。如果文件数量达到了百万甚至千万量级,扫描所有文件将是非常耗时的。而且正在发生变化的往往是其中很少的一部分,这是非常低效的方式。其次,rsync不能实时的去监测、同步数据,虽然它可以通过linux守护进程的方式进行触发同步,但是两次触发动作一定会有时间差,这样就导致了服务端和客户端数据可能出现不一致,无法在应用故障时完全的恢复数据。基于以上原因,rsync+inotify组合的出现解决了这个问题。
23 sh -c命令
利用 “sh -c” 命令,它可以让 bash 将一个字串作为完整的命令来执行,这样就可以将 sudo 的影响范围扩展到整条命令。
例如:
#使用rsync进行本地文件夹之间同步备份数据
sudo sh -c 'rsync -arvHp /mnt/. ~/custom_iso'
24 mkisofs命令
mkisofs可将指定的目录与文件做成ISO 9660格式的映像文件,以供刻录光盘。
#mkisofs命令行格式
mkisofs [-adDfhJlLNrRTvz][-print-size][-quiet][-A<应用程序ID>][-b<开机映像文件>][-c<开机文件名称>][-hide<目录或文件名>][-hide-joliet<文件或目录名>][-m<目录或文件名>][-M<映像文件>][-o<映像文件>][-sysid <系统ID>][-V <volume ID >][-x<目录>][目录或文件]
基本参数
| -o | 设置输出文件名 |
|---|---|
| -V | Set Volume ID |
| -v | verbose |
| -m <目录或文件名> or -exclude <目录或文件名> | 排除某目录或文件,其将不会放入映像文件中 |
| -M <映像文件> or -prev-session <映像文件> | Iso文件合并 与指定的映像文件合并 |
启动光盘参数
| -no-emul-boot | Boot image is 'no emulation’image 非模拟模式启动 |
|---|---|
| -b <开机映像文件> or -eltorito-boot <开机映像文件> | 指定在制作启动光盘时所需的开机映像文件 -b:启动image |
| -c <开机文件名称> | -c:cat文件 制作启动光盘时,mkisofs会将开机映像文件中的全**-eltorito-catalog***文件的全部内容作成一个文件 |
| -J或-joliet | Generate Joliet directory information 生成Joliet 格式信息 Joliet是用于在 Windows环境下使用的光盘 |
| -R或-rock | Generate Rock Ridge directory information 生成Rock Ridge目录格式信息 Rock Ridge用于 UNIX/Linux环境下的光盘。 文件名区分大小写,同时记录文件长度 |
| -r或-rational-rock | 使用Rock Ridge 并开放全部文件的读取权限 |
其他参数
| -hide-rr-moved | Rename RR_MOVED to .rr_moved in Rock Ridge tree 隐藏 Unix RR 目录 |
|---|---|
| -hide <目录或文件名> | 使指定的目录或文件在ISO 9660或Rock RidgeExtensions的系统中隐藏 |
| -hide-joliet<目录或文件名> | 使指定的目录或文件在Joliet系统中隐藏 |
| -O | 采用 MD5 空间优化 |
| -C<盘区编号,盘区编号> | 将许多节区合成一个映像文件时,必须使用此参数 |
| -l -relaxed-filenames -gbk4dos-filenames -gbk4win-filenames | 允许长文件名 扩展的文件名 DOS下支持中文 WIN下支持中文 |
25 xorriso 命令
用来将映像文件烧录到 CD/DVD 光盘中。
26 time命令
测量命令的执行时间,或者给出系统资源的使用情况。
#time命令最常用的使用方式就是在其后面直接跟上命令和参数:
time [options]command [arguments...]
(1) real:从进程 ls 开始执行到完成所耗费的 CPU 总时间。该时间包括 ls 进程执行时实际使用的 CPU 时间,ls 进程耗费在阻塞上的时间(如等待完成 I/O 操作)和其他进程所耗费的时间(Linux 是多进程系统,ls 在执行过程中,可能会有别的进程抢占 CPU)。
(2) user:进程 ls 执行用户态代码所耗费的 CPU 时间。该时间仅指 ls 进程执行时实际使用的 CPU 时间,而不包括其他进程所使用的时间和本进程阻塞的时间。
(3) sys:进程 ls 在内核态运行所耗费的 CPU 时间,即执行内核系统调用所耗费的 CPU 时间。
27 apt命令
apt(Advanced Packaging Tool)是一个在 Debian 和 Ubuntu 中的 Shell 前端软件包管理器。
apt 命令提供了查找、安装、升级、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
apt 命令执行需要超级管理员权限(root)。
27.1 apt语法
#apt语法
apt [options] [command] [package ...]
#命令参数
-h 帮助文件。
-q 输出到日志 - 无进展指示
-qq 不输出信息,错误除外
-d 仅下载 - 不安装或解压归档文件
-s 不实际安装。模拟执行命令
-y 在需要确认的场景中回应 yes
-f 尝试修正系统依赖损坏处
-m 如果归档无法定位,尝试继续
-u 同时显示更新软件包的列表
-b 获取源码包后编译
-V 显示详细的版本号
-c=? 阅读此配置文件
-o=? 设置自定的配置选项,如 -o dir::cache=/tmp
27.2 apt和apt-get命令之间的区别
| apt 命令 | 取代的命令 | 命令的功能 |
|---|---|---|
| apt install | apt-get install | 安装软件包 |
| apt remove | apt-get remove | 移除软件包 |
| apt purge | apt-get purge | 移除软件包及配置文件 |
| apt update | apt-get update | 刷新存储库索引 |
| apt upgrade | apt-get upgrade | 升级所有可升级的软件包 |
| apt autoremove | apt-get autoremove | 自动删除不需要的包 |
| apt full-upgrade | apt-get dist-upgrade | 在升级软件包时自动处理依赖关系 |
| apt search | apt-cache search | 搜索应用程序 |
| apt show | apt-cache show | 显示装细节 |
27.3 apt升级和安装指令
apt-get update // 更新源文件,并不会做任何安装升级操作
apt-get upgrade // 升级所有已安装的包
apt-get install packagename // 安装指定的包
apt-get install packagename --only-upgrade // 仅升级指定的包
apt-get install packagename --reinstall // 重新安装包
apt-get -f install // 修复安装
apt-get build-dep packagename // 安装相关的编译环境
apt-get source packagename // 下载该包的源代码
apt-get dist-upgrade // 升级系统
apt-get dselect-upgrade
27.4 apt显示和查询指令
apt-cache search packagename // 查询指定的包
apt-cache show packagename // 显示包的相关信息,如说明、大小、版本等
apt-cache depends packagename // 了解使用该包依赖哪些包
apt-cache rdepends packagename // 查看该包被哪些包依赖
27.5 apt删除和清理
apt-get remove packagename // 删除包
apt-get remove packagename -- purge // 删除包,包括删除配置文件等
apt-get autoremove packagename --purge // 删除包及其依赖的软件包+配置文件等(只对6.10有效,推荐使用)
apt-get clean // 清理无用的包
apt-get autoclean // 清理无用的包
apt-get check // 检查是否有损坏的依赖
28 从Web下载文件命令 wget
wget是一个Linux环境下用于从万维网上提取文件的工具,它支持HTTP和FTP协议,支持代理服务器功能,能够自动递归远程主机的目录,找到合乎条件的文件并将其下载到本地。wget可在后台运行,所以他可以批量下载文件
#默认下载到当前目录下
wget http://cloud.xieyongbin.press:10000/nohup.out
#基本语法
wget [options] [url]
#url的格式如下
http://host[:port]/path
-O 选项以其他名称保存下载的文件
-P 选项将文件下载到指定目录
-c 选项断点续传
-b 选项在后台下载
-i 选项下载多个文件
--limit-rate 选项限制下载速度
-U 选项设定模拟下载
--tries 选项增加重试次数
28.1 参数介绍
28.1.1 指令启动相关
| 参数 | 作用 |
|---|---|
| -V, –version | 显示Wget的版本 |
| -h, –help | 显示帮助文档 |
| -b, -background | 在启动之后会离开转到后台运行 |
| -e, -execute=COMMAND | 执行一个.wgetrc里面的COMMAND指令,.wgettrc命令其实是一个参数列表,直接将软件需要的参数写在一起就可以了 |
28.1.2 文件处理相关
| 参数 | 作用 |
|---|---|
| -o, –output-file=FILE | 将软件输出信息保存到文件中去 |
| -a, -append-output=FILE | 将软件输出信息追加到文件中去 |
| -q, –quiet | 安静模式(不显示任何信息) |
| -v, –verbose | 冗长模式(这是内定值). |
| -nv, –non-verbose | 关闭verboseness,但不是安静模式. |
| -i, –input-file=FILE | 从指定的文件中取出url |
28.1.3 下载相关
| 参数 | 作用 |
|---|---|
| -t, –tries=NUMBER | 设定重复尝试次数(0表示无限制,一直尝试) |
| -O –output-document=FILE | 把下载的文件写到FILE里,相当于对下载的文件重命名 |
| -nc, –no-clobber | 不覆盖已经存在的文件. |
| -c, –continue | 继续下载已经下载了一部分的文件 |
| –dot-style=STYLE | 设定取回状况的显示风格. |
| -N, –timestamping | 只下载比本地新的文件 |
| -S, –server-response | 显示服务器的响应消息 |
| –spider | 不下载任何数据 |
| -T, –timeout=SECONDS | 设定读取时超过的时间,单位秒 |
| -w, –wait=SECONDS | 接受不同文件之间等待的时间,单位秒 |
| -Y, –proxy=on/off | 开启或关闭Proxy. |
| Q, –quota=NUMBER | 设定接受数据的限额大小 |
28.1.4 目录
| 参数 | 作用 |
|---|---|
| -nd –no-directories | 不创建目录. |
| -x, –force-directories | 强制建立目录 |
| -nH, –no-host-directories | 不创建含有主机名称的目录. |
| -P, –directory-prefix=PREFIX | 保存文件前先创建指定名称的目录(将文件下载到指定目录) |
| –cut-dirs=NUMBER | 忽略远程文件中指定数目的目录层 |
28.1.5 HTTP选项
| 参数 | 作用 |
|---|---|
| –http-user=USER | 配置HTTP用户名 |
| –http0passwd=PASS | 配置http用户密码 |
| -C, –cache=on/off | 开启/关闭使用服务器中高速缓存中的数据(默认开启) |
| –ignore-length | 忽略Content-Length文件头字段 |
| –proxy-user=USER | 设定代理服务器的用户名 |
| –proxy-passwd=PASS | 设定代理服务器的密码 |
| -s, –save-headers | 将http存入文件中 |
| -U, –user-agent=AGENT | 使用AGENT取代Wget/VERSION作为UA的识别代号 |
28.1.5 FTP选项
| 参数 | 作用 |
|---|---|
| –retr-symlinks | 在递归模式中,下载链接所指示的文件 |
| -g, –glob=on/off | 设置是否展开有通配符的文件名 |
| –passive-ftp | 使用被动传输模式. |
28.1.6 使用递回方式的取回
| 参数 | 作用 |
|---|---|
| -r, –recursive | 递归下载 |
| -l, –level=NUMBER | 最大递归深度,0表示无限 |
| –delete-after | 删除下载后的文件 |
| -k, –convert-links | 将绝对连接转换为相对链接 |
29 dpkg命令
dpkg命令的英文全称是“Debian package”,故名意思是Debian Linux系统用来安装、创建和管理软件包的实用工具。
#语法格式
dpkg [参数]
常用参数:
| -i | 安装软件包 |
|---|---|
| -r | 删除软件包 |
| -l | 显示已安装软件包列表 |
| -L | 显示于软件包关联的文件 |
| -c | 显示软件包内文件列表 |
实例:
#安装包
dpkg -i package.deb
#删除包
dpkg -r package.deb
#列出当前已安装包
dpkg -l
#列出deb包内容
dpkg -c package.deb
#配置
dpkg --configure package
#获取安装的特定软件包的列表
dpkg --get-selections | grep postgres
#[allow-insecure=yes] 某些软件源无安全认证,需要加 [allow-insecure=yes] 忽略安全问题
deb [arch=amd64 allow-insecure=yes] ${localapt}/ubuntu/ hcfa main"
30 source命令
source命令是一个内置的shell命令,用于从当前shell会话中的文件读取和执行命令。source命令通常用于保留、更改当前shell中的环境变量。简而言之,source一个脚本,将会在当前shell中运行execute命令。
source命令可用于:
刷新当前的shell环境
#为ls -al定义一个别名为ll:
echo "alias ll='ls -al'" >> ~/.bashrc
#在~/.bashrc文件中定义完别名,可以使用source命令刷新当前shell环境
source ~/.bashrc
在当前环境使用source执行Shell脚本
source web.sh
从脚本中导入环境中一个Shell函数
#func.sh
#!/bin/bash
foo(){
echo "test function!"
}
#当前的shell会话中导入上述脚本的功能
source func.sh
#执行命令:foo
#输出结果
test function!
从另一个Shell脚本或者配置文件中读取变量或内容
#取出文件中的参数值,.表示当前路径下
source ./packages_config.cfg
31 make 参数
31.1 make 参数 ARCH与CROSS_COMPILE
make ARCH=arm CROSS_COMPILE=arm-none-linux-gnueabi-
ARCH即architecture,就是选择编译哪一种cpu architecture,也就是编译arch/目录下的哪一个子目录
CROSS_COMPILE。如指定make ARCH=arm就是编译arch/arm下的代码。如果不指定,make将使用本机(用什么机器编译就是什么)的cpu作为缺省ARCH.注意:arch/arm下不但有arm体系架构特有的代码,还有arm特有的kconfig,也就是配置选项,所以在make menuconfig,make xxxx_defconfig的时候也必须指定ARCH=arm。
即交叉编译器的前缀(prefix),也就是选择将代码编译成目标cpu的指令的工具,如指定make CROSS_COMPILE=arm-none-linux-gnueabi-就是使用arm-none-linux-gnueabi-gcc, arm-none-linux-gnueabi-ld等工具将代码编译成arm的可执行指令。
如果不指定CROSS_COMPILE参数,make时将认为prefix为空,即使用gcc来编译。这里cross_compile的设置,是假定所用的交叉工具链的gcc程序名称为arm-linux-gcc。如果实际使用的gcc名称是some-thing-else-gcc,则这里照葫芦画瓢填some-thing-else-即可。总之,要省去名称中最后的gcc那3个字母。
1)ARCH=arm 表示ARCH给出了目标处理器的架构这里用的是arm 处理器。
2)CROSS_COMPILE给出了编译程序所用的交叉工具链的名称,比如:CROSS_COMPILE=arm-none-linux-
3)通过这个命令,把这些参数传递给Makefile中的预留参数,程序就可以顺利编译下去了
31.2 make clean
#清除上次的make命令所产生的object文件(后缀为“.o”的文件)及可执行文件
make clean
#将编译成功的可执行文件安装到系统目录中,一般为/usr/local/bin目录
make install
#产生发布软件包文件(即distribution package)。
#这个命令将会将可执行文件及相关文件打包成一个tar.gz压缩的文件用来作为发布软件的软件包
make dist
#生成发布软件包并对其进行测试检查,以确定发布包的正确性。
#这个操作将自动把压缩包文件解开,然后执行configure命令,并且执行make,来确认编译不出现
make distcheck
#类似make clean,但同时也将configure生成的文件全部删除掉,包括Makefile文件。
make distclean