CUDA编程第五章: 共享内存&常量内存
前言:
本章内容:
-
了解数据在共享内存中是如何被安排的
-
掌握从二维共享内存到线性全局内存的索引转换
-
解决不同访问模式中存储体中的冲突
-
在共享内存中缓存数据以减少对全局内存的访问
-
使用共享内存避免非合并全局内存的访问
-
理解常量缓存和只读缓存之间的差异
-
使用线程束洗牌指令编程
在前面的章节中, 已经介绍了几种全局内存的访问模式. 通过安排全局内存访问模式, 我们学会了如何实现良好的性能并且避免了浪费事务. 未对齐的内存访问是没有问题的, 因为现代的GPU硬件都有一级缓存, 但在跨全局内存的非合并内存访问, 仍然会导致带宽利用率不会达到最佳标准. 根据算法性质和相应的访问模式, 非合并访问可能是无法避免的. 然而, 在许多情况下, 使用共享内存来提高全局内存合并访问是有可能的. 共享内存是许多高性能计算应用程序的关键驱动力.
在本章中, 你将学习如何使用共享内存进行编程、数据在共享内存中如何被存储、数据元素是怎样使用不同的访问模式被映射到内存存储体中的. 还将掌握使用共享内存提高核函数性能的方法.
5.1 CUDA共享内存概述:
GPU中有两种类型的内存:
-
板载内存(以内存颗粒的形式贴于显卡PCB上)
-
片上内存(集成于芯片内部)
全局内存是较大的板载内存, 具有相对较高的延迟. 共享内存是较小的片上内存, 具有相对较低的延迟, 并且共享内存可以提供比全局内存高得多的带宽. 可以把它当作一个可编程管理的缓存. 共享内存通常的用途有:
-
块内线程通信的通道
-
用于全局内存数据的可编程管理的缓存
-
高速暂存存储器, 用于转换数据以优化全局内存访问模式
共享内存:
这里就给原文了, 之前那些奇怪的翻译怎么就不给
共享内存(shared memory, SMEM)其特点:
- 每个SM上都有一个独立的共享内存
其作用更像L1 & L2缓存 - 被SM上执行的所有线程共享
通常用于线程间的相互协作, 大大降低了核函数所需的全局内存带宽 - 通过程序显式的管理
所以称之为可编程管理的缓存 - 带宽比全局内存块10倍, 而延时通常低20倍以上
物理上更接近CUDA核心
以Kepler核心的SM为例:
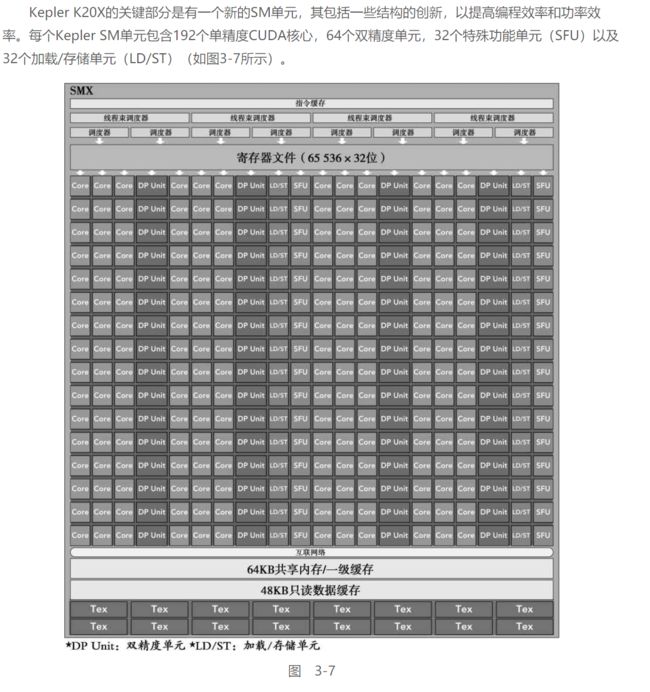
SM基本存储顺序:

共享内存访问事物:
与全局内存相同, 线程通过类似的方式访问共享内存, 这里不再赘述
但如果过个线程访问共享内存中个同一个字, 则在一个线程读取该字后, 将会通过多播的形式广播给其他线程
可编程管理的缓存:
缓存(L1 & L2)对于程序而言是透明的, 编译器才能处理所有数据的移动, 而并非程序员
而共享内存是一个可编程管理的缓存, 所以可以通过在数据布局上提供更多的细粒度控制和改善片上数据的移动, 使得对优化应用程序代码变得更简单
共享内存的分配:
共享内存使用__shared__修饰符进行声明
如:
__shared__ float tile[size_y][size_x];
如果一个共享内存的大小在编译时是未知的(相当于每个线程使用时大小不一样), 则需要添加extern修饰
并且==此时只能声明一维数组==
extern __shared__ int tile[];
在每个核函数被调用时, 需要动态分配共享内存 这部分操作在主机端进行
即在<<<>>>后头多加一个参数, 注意这里是以字节为单位
kernel<<<grid, block, isize * sizeof(int)>>>(...)
共享内存存储体和访问模式
优化内存性能时要度量的两个关键属性是:延迟和带宽
共享内存可以用来隐藏全局内存延迟和带宽对性能的影响(第四章所述)
内存存储体:
为了获得高内存带宽, 共享内存被分为32个同样大小的内存模型, 它们被称为存储体, 它们可以被同时访问
这里和线程束大小32相同
此造就了以下特点:
如果通过线程束发布共享内存加载或存储操作, 且在每个存储体上只访问不多于一个的内存地址, 那么该操作可由一个内存事务来完成. 否则, 该操作由多个内存事务来完成, 这样就降低了内存带宽的利用率
存储体冲突:
上头刚说到的问题
当多个地址请求落在相同的内存存储体中时, 就会发生存储体冲突, 这会导致请求被重复执行
硬件会将存储体冲突的请求分割到尽可能多的独立的无冲突事务中, 有效带宽的降低是由一个等同于所需的独立内存事务数量的因素导致的
和上一章讲到的相似, 当线程束发出共享内存请求时, 有以下3种典型的模式:
-
并行访问:多个地址访问多个存储体
-
串行访问:多个地址访问同一个存储体
如线程束中的32个线程都访问同一个存储体中的不同地址, 将需要32个内存事务, 所消耗的时间也是单一请求的32倍 -
广播访问:单一地址读取单一存储体
此仅适用多个线程访问一个存储体中的同一个地址, 此时不发生存储体冲突此种情况虽然仅需要一个内存事务, 但是由于访问的数据量很小, 所以带宽的利用度很差

访问模式:
共享内存存储体的宽度规定了共享内存地址与共享内存存储体的对应关系
-
计算能力2.x的设备中为4字节(32位)
-
计算能力3.x的设备中为8字节(64位)
对于Fermi设备, 存储体的宽度是32位并且有32个存储体. 每个存储体在每两个时钟周期内都有32位的带宽. 连续的32位字映射到连续的存储体中
使用共享内存的字节地址计算出存储体的索引:
存 储 体 索 引 = 字 节 地 址 字 节 数 / 存 储 体 % 32 个 存 储 体 存储体索引 = \frac{字节地址}{字节数/存储体} \% 32个存储体 存储体索引=字节数/存储体字节地址%32个存储体
也就是说, 存储体在共享内存中的分布是这样的:


这样的布局是为了相邻的字被分配到不同的存储体中, 在线程块中的线程执行连续访问时, 能分配到不同的存储体中, 以最大限度的提高线程束中可能的并发访问数量
同样的, 同一个线程束中的多个线程对同一个地址访问时会使用广播, 并不会引发存储体冲突, 但如果是写入操作的话则需要排队, 并且顺序未知
对于Kepler架构而言:
其同样有32个存储体, 但是其有32位和64位两种地址模式, 后者显然能更好的降低存储体冲突的概率(总是产生相同或更少的存储体冲突)
而在32位模式下, 64位的存储体被分割成俩:
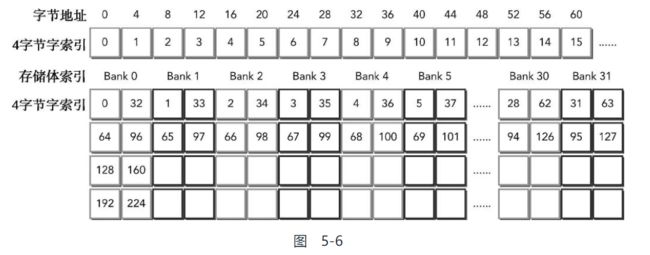
如图, 同时访问Bank0 的0和32索引单元并不会引发存储体冲突, 因为他们属于一个存储体中连续的64位, 在一个时钟周期中可以同时传送
但是, 如果访问的不是连续的64位, 如以下两种情况, 则会导致存储体冲突:

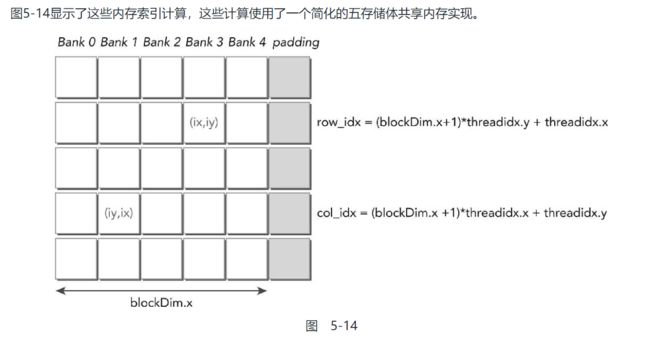
内存填充:
内存填充是避免存储体冲突的一种方法
假设有5个存储体, 其中的数据以如下排布:

如果要访问bank0的不同地址, 则会发生5项内存冲突
而内存填充的思想就是通过额外的字, 将原本储存在统一存储体中的数据分散到不同的存储体中
如图, 在N=5个元素之后添加一个额外的字, 其元素排布将变成如下:

内存填充的思想&优点:
- 对于行, 在进行行主序读取时, 仍能保证不发生存储体冲突
- 对于列, 由于打乱了原先在同一列中的元素排布, 所以对于列主序读取, 也能做到不发生存储体冲突
综上, 就是无论使用行主序 或 列主序, 都不会发生存储体冲突
内存填充的缺点:
-
添加了额外的无用数据, 将使线程块可用的总共享内存减少
-
由于其涉及到存储体的具体数量, 所以不同架构的显卡中应用内存填充将使用不同的策略
需要修改写入和访问的索引不修改会导致应用到不同架构上可能出现存储体冲突
访问模式配置:
之前说到Kepler架构有两种共享内存工作模式, 默认是在4字节(32位)
使用此函数可以在运行时查看:
cudaError_t cudaDeviceGetSharedMemConfig(enum cudaSharedMemConfig *pConfig);

使用此函数进行共享内存工作模式的配置:
cudaError_t cudaDeviceSetSharedMemConfig(enum cudaSharedMemConfig config);

一个大的存储体可能为共享内存访问产生更高的带宽, 但是可能会导致更多的存储体冲突
根据情况设置
配置共享内存:
CUDA为配置一级缓存和共享内存的大小提供了两种方法:
-
按设备进行配置
-
按核函数进行配置
设备全局配置:
使用以下函数配置一级缓存和共享内存的大小:
cudaError_t cudaDeviceSetCacheConfig(enum cudaFuncCache cacheConfig);
支持的参数如下:

一般有两个配置策略:
-
当核函数使用较多的共享内存时, 倾向于更多的共享内存
-
当核函数使用更多的寄存器时, 倾向于更多的一级缓存
核函数单独配置:
cudaError_t cudaFuncSetCacheConfig(const void *func, enum cudaFuncCache cacheConfig);
参数与上头相同
其中func是指定配置的核函数的指针
对于每个核函数, 仅需要调用一次配置函数即可
同步:
既然是并行计算语言, 必然会有同步机制, CUDA提供几个运行时函数来执行块内同步:
这里又开始迷惑HAPI翻译了, 翻译的烂就算了, 译者还不给原文名
-
障碍
块内的所有线程都到达barrier点后才会继续执行 -
内存栅栏
所有调用的线程必须等到全部内存修改对其余调用线程可见时才能继续执行
后者的理解需要先了解一下CUDA的弱排序内存模型
这是什么鬼翻译, 这里比较好的翻译应该是弱内存顺序模型或弱内存模型 Weak Memory Models
理解了准确意思即可
弱排序内存模型
GPU线程在不同内存(如共享内存、全局内存、锁页主机内存或对等设备的内存)中写入数据的顺序, 不一定和这些数据在源代码中访问的顺序相同
一个线程的写入顺序对其他线程可见时, 它可能和写操作被执行的实际顺序不一致
同样, 如果指令之间是相互独立的, 线程从不同内存中读取数据的顺序和读指令在程序中出现的顺序不一定相同
为了显式地强制程序以一个确切的顺序执行, 必须在应用程序代码中插入内存栅栏和障碍
这是保证与其他线程共享资源的核函数行为正确的唯一途径
显式障碍:
在核函数中, 通过使用以下函数来设置障碍:
void __syncthreads();
它要求块中的线程必须等待直到所有线程都到达该点
并确保在障碍点之前, 被这些线程访问的所有全局和共享内存对同一块中的所有线程都可见
所以__syncthreads通常用于协调同一块中线程间的通信, 如访问同一地址的内存空间时可能产生的问题(写后读、读后写、写后写)
使用这玩意时还需要注意死锁问题:
当线程块中的线程走不同的程序路径时, 在分支中使用__syncthreads()可能导致部分线程永远无法到达同步点而形成死锁:

内存栅栏:
这里需要简单了解一下并发中的可见性 & 有序性:
- 缓存导致了可见性问题
- 编译优化导致了有序性问题
可以理解可见性就是:
一个线程修改了内存数据, 其他同步范围内的线程都能够正确访问到这个被修改后的数值, 而非是修改前的数值
(缓存问题会导致部分修改的数值仅在缓存中, 而并没有同步到其他线程可见的地步, 这个在Java并发编程中有涉及)
内存栅栏的功能可确保栅栏前的任何内存写操作对栅栏后的其他线程都是可见的
根据所需范围, 有3种内存栅栏:块、网格或系统, 分别对应三种栅栏函数:
void __threadfence_block(); //线程块级别
void __threadfence(); //网格级别
void __threadfence_system(); //系统级别
其都是在不同范围内保证所有写操作对范围内的所有线程可见
而一个比较特殊的是__threadfence_block()块内内存同步, 书里是这样讲的:
内存栅栏不执行任何线程同步, 所以对于一个块中的所有线程来说, 没有必要实际执行这个指令
又开始谜语人了, 之前哪里有说过?
这里先放着
volatile修饰符:
C++中的volatile修饰符也能用在CUDA中, 使用后编译器会取消对该变量的缓存优化, 每次改变都会执行内存同步( 即不进行数据缓存, 而直接写回到内存中)
5.2 共享内存的数据布局:
为了全面了解如何有效地使用共享内存, 本节将使用共享内存研究几个简单的例子, 其中包括下列主题:
-
方阵与矩阵数组
-
行主序与列主序访问
-
静态与动态共享内存的声明
-
文件范围与内核范围的共享内存
-
内存填充与无内存填充
当使用共享内存设计核函数时, 重点应放在以下两个概念上:
-
跨内存存储体映射数据元素
-
从线程索引到共享内存偏移的映射
当这些概念了然于心时, 就可以设计一个高效的核函数了, 它可以避免存储体冲突, 并充分利用共享内存的优势
方形共享内存:
方形共享内存说白了就是方形排布的共享内存:
可以直接使用一个二维线程块来访问, 分为行主序 & 列主序
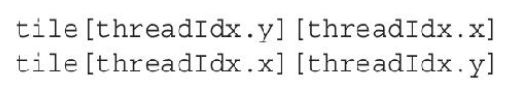
第一种是行主序, 线程块的行对应着内存块的行
第二种则相反
很容易能看到, 第一种行主序的方法能呈现出更好的性能和更少的存储体冲突:
由于线程束是按x优先进行划分的, 所以邻近threadIdx.x 的线程会被划分到同一个线程束中, 这样访问共享内存时, 线程束中的每个线程都能访问到不同的存储体
行主序访问 & 列主序访问:
这里就是实践行主序 & 列主序的区别, 比较性能差异
行主序访问:

此时没有存储体冲突
列主序访问:

此时会导致大量的存储体冲突
使用nvprof能很好的看到性能差异:
书里使用的是K40c
执行时间的差异:

存储体冲突的差异:
在nvprof中使用以下两个指标检测存储体冲突:


行主序写 & 列主序读:
下面的核函数实现了共享内存中按行主序写入和按列主序读取


所以这个例子有啥意义, 这不是猜都能猜到的么
动态共享内存:
这里使用上头讲到的动态内存
动态共享内存可以在核函数之外声明, 其作用域将是整个文件
也可以在核函数之内声明, 其作用域将仅限于核函数
例程:
核函数中按行主序写入, 按列主序读取


nvprof结果:

所以表明了使用动态共享内存也会存在相同的问题
填充动态声明的共享内存:
这里是对动态共享内存执行内存填充
填充动态声明的共享内存数组更加复杂

因为在以上核函数中用于存储数据的全局内存小于填充的共享内存, 所以需要3个索引:一个索引用于按照行主序写入共享内存, 一个索引用于按照列主序读取共享内存, 一个索引用于未填充的全局内存的合并访问

这些结果和填充静态声明的共享内存是一致的
所以这里证明的是, 无论是静态共享内存还是动态共享内存都能被有效的填充
方形共享内存内核性能的比较:
到目前为止, 从所有执行过的内核运行时间可以看出:
-
使用填充的内核可提高性能, 因为它减少了存储体冲突
-
带有动态声明共享内存的内核增加了少量的消耗

矩形共享内存:
这一部分的行文逻辑基本上和上一节相同, 讨论共享内存的几个点, 只不过吧上头的方阵替换为了矩阵
矩形共享内存是一个更普遍的二维共享内存, 他与方形共享内存的区别就是行列数不等 ( 矩阵 & 方阵的区别)
本部分的所有核函数调用都使用以下执行配置:

行主序访问 & 列主序访问:
这里的结果 & 结论基本上与上头的方阵相同
所以简单看下就好
就是将上头的方阵替换为了矩阵内存, 并执行内存转置操作:

这里使用的应该是16个数据, 而并非之前方阵的32个, 所以数据不同, 但是结论是相同的
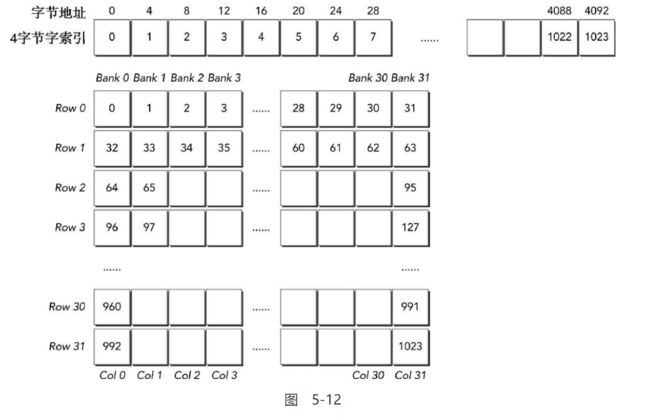
共享内存的存储和加载请求, 由setRowReadRow核函数中的一个事务完成. 同样的请求在setColReadCol函数中由8个事务完成. Kepler K40的存储体宽度是8个字, 一列16个4字节的数据元素被安排到8个存储体中, 如图5-6所示, 因此, 该操作有一个8路冲突
行主序写 & 列主序读:
使用共享内存进行矩阵转置的核函数. 通过最大化低延迟的加载和存储来提高性能, 并合并全局内存访问

内核有3个内存操作:
-
写入每个线程束的共享内存行, 以避免存储体冲突
-
读取每个线程束中的共享内存列, 以完成矩阵转置
-
使用合并访问(上一章讲到的)写入每个线程束的全局内存行

该存储操作是无冲突的, 加载操作报告了一个8路冲突
与预期相同
store时是行主序, load时是列主序
动态共享内存:
还是紧接着上头的例子进行修改, 将其中的静态内存改为动态内存, 继续实现矩阵转置


结果与使用静态内存相同
所以结论就是:
动态分配共享内存不会影响存储体冲突
填充静态共享内存:



在前面的宏中若将填充数据元素的数量从2改到1, 则nvprof报告有两个事务完成共享内存的加载操作, 即发生一个双向存储体冲突
所以结论是:
填充的元素个数与行列数是有关系的, 数量不当仍将导致存储体冲突
填充动态共享内存:
大致套路和静态共享内存相同:

结论就是:
动态内存的填充比静态内存的仍然要复杂
其有专门的计算index 的代码
矩形共享内存内核性能的比较:
在一般情况下, 和上一节说到的一样:
- 核函数使用共享内存填充消除存储体冲突以提高性能
- 使用动态共享内存的核函数会显示有少量的消耗

5.3 减少全局内存访问:
使用共享内存的主要原因之一是要缓存片上的数据, 从而减少核函数中全局内存访问的次数
在本节中, 将重新使用第三章中的并行归约核函数, 但是这里使用共享内存作为可编程管理缓存以减少全局内存的访问
使用共享内存的并行归约:
首先是一个仅使用全局内存的归约核函数, 作为所有核函数的起点与性能的基点:


而后是带有共享内存的全局内存操作的归约函数

此核函数就是利用共享内存将全局内存中的数据进行了缓存, 而后的归约都只在共享内存中进行(替代了直接读写全局内存的操作)
二者对比如下:

使用共享内存的核函数比只使用全局内存的核函数快了1.84倍
使用nvprof的俩参数查看全局内存加载&存储事务:


使用展开的并行归约
这里就是在上一节的例子中加上之前的循环展开方法:
以下内核展开了4个线程块, 即每个线程处理来自于4个数据块的数据元素
可预期的效果是:
-
通过在每个线程中提供更多的并行I/O, 增加全局内存的吞吐量
-
全局内存存储事务减少了1/4
-
整体内核性能的提升




qs, 加载量保持不变, 但是由于是4展开, 所以存储量下降(原先需要存储多次的过程被压缩到了一个线程中进行)
使用动态共享内存的并行归约
这里一笔带过, 直接上结论;
用动态分配共享内存实现的核函数和用静态分配共享内存实现的核函数之间没有显著的差异
有效带宽:
由于归约核函数是受内存带宽约束的, 所以评估它们时所使用的适当的性能指标是有效带宽
有效带宽是在核函数的完整执行时间内I/O的数量(以字节为单位)
对于内存约束的应用程序, 有效带宽是一个估算实际带宽利用率的很好的指标
计算公式:
有 效 带 宽 ( G B / s ) = ( 读 字 节 数 + 写 字 节 数 ) 运 行 时 间 ∗ 1 0 9 有效带宽(GB/s) = \frac{(读字节数+写字节数)}{运行时间*10^9} 有效带宽(GB/s)=运行时间∗109(读字节数+写字节数)
以下是前头的4个函数的有效带宽:

显然, 可以通过展开块来获得有效带宽的显著改进
每个线程运行中同时有多个请求, 会导致内存总线高饱和
5.4 合并的全局内存访问:
使用共享内存也能帮助避免产生未合并的全局内存访问
之前的矩阵转置核函数中, 读操作是合并的, 但写操作是交叉访问的
在使用共享内存之后, 可以将共享内存作为缓存, 先在共享内存中进行交叉访问, 利用共享内存的低延时&高带宽降低时间损耗, 完成后在整块写回到全局内存中, 以实现合并写入
在本章前面的部分, 测试了一个矩阵转置核函数, 该核函数使用单个线程块对共享内存中的矩阵行进行写入, 并读取共享内存中的矩阵列
在本节中, 将扩展该核函数, 具体方法是使用多个线程块对基于交叉的全局内存访问重新排序到合并访问
基准转置核函数:
和上一节的行文逻辑相同, 先确定一个性能比较的基准
下面的核函数是一个仅使用全局内存的矩阵转置的朴素实现
其中, 全局内存读操作在线程束内是被合并的, 而全局内存写操作在相邻线程间是交叉访问的

而后这个核函数将作为优化的性能上限
其中读写操作都将被合并, 仍执行相同数量的IO

后头测试用的矩阵大小将使用212 * 212, 线程块大小为32*16
基准核函数的运行结果:
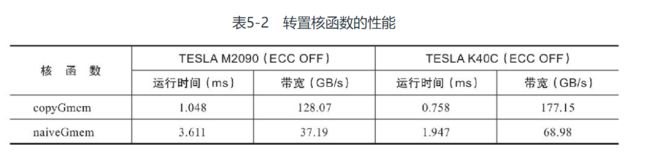
副本内核比朴素内核快了将近3倍
由于朴素内核写入全局内存, 使其带有了4096个元素的跨度, 所以一个单一线程束的存储内存操作是由32个全局内存事务完成的. 可以使用以下nvprof指标来确认这一点


使用共享内存的矩阵转置:
为了避免交叉全局内存访问, 可以使用二维共享内存来缓存原始矩阵的数据

实现的核函数:
可以看做是上一节中的setRowReadCol的扩展, 前者使用的单一线程块, 而后者将其扩展为了使用多个线程块和数据块

核函数的程序步骤:
kerneltransposeSmem函数可被分解为以下几个步骤:
-
线程束执行合并读取一行, 该行存储在全局内存中的原始矩阵块中.
-
然后, 该线程束按行主序将该数据写入共享内存中, 因此, 这个写操作没有存储体冲突.
-
因为线程块的读/写操作是同步的, 所以会有一个填满全局内存数据的二维共享内存数组.
-
该线程束从二维共享内存数组中读取一列. 由于共享内存没有被填充, 所以会发生存储体冲突.
-
然后该线程束执行数据的合并写入操作, 将其写入到全局内存的转置矩阵中的某行
核函数具体的实现就暂且略过了(详见书里), 这里来看其实现的特点:
- 全局内存的读取是合并的
- 共享内存的写入没有发生存储体冲突
- 共享内存的读取发生存储体冲突
是按列读取 - 全局内存的写入是合并的

性能对比:
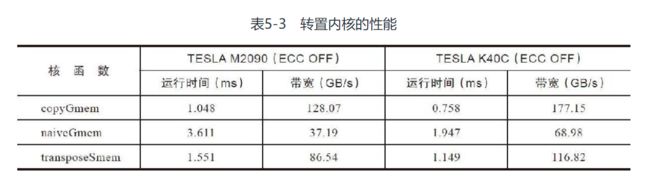

全局内存存储的重复数量从32减少到2
这是由于转置块中的块宽为16, 所以线程束前半部分的写操作和线程束后半部分的写操作间隔了4080
因此线程束的写入请求是有两个事务完成的
将线程块大小更改到32×32会把重复次数减少到1, 但是前者(32*16)将显现出更多的并行性

显然, 读取二维共享内存数组中的一列会产生存储体冲突
使用填充共享内存的矩阵转置:
这里就是应用之前的填充
通过给二维共享内存数组tile中的每一行添加列填充, 可以将原矩阵相同列中的数据元素均匀地划分到共享内存存储体中
需要填充的列数取决于设备的计算能力和线程块的大小
对于一个大小为32×16的线程块被测试内核来说, 在Tesla K40中必须增加两列填充, 在Tesla M2090中必须增加一列填充
修改之前的共享内存声明如下:



使用展开的矩阵转置:
就是在添加一个循环展开
下面的核函数展开两个数据块的同时处理:每个线程现在转置了被一个数据块跨越的两个数据元素
这种转化的目标是通过创造更多的同时加载和存储以提高设备内存带宽利用率


核函数的其他详细实现直接去看书, 其特点都在上头的这个图里

增大并行性:
这里是通过调整线程块的维度来提升性能

块大小为16×16时展示出了最好的性能, 因为它有更多的并发线程块, 从而有最好的设备并行性
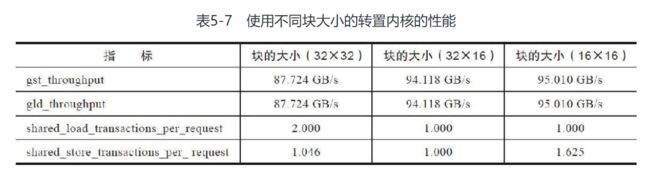
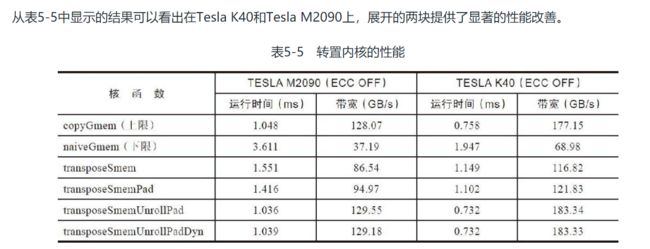
表5-7总结了在Tesla K40中从transposeSmemUnrollPadDyn函数上获得全局内存吞吐量和共享内存存储体冲突的nvprof结果. 虽然线程块配置为32×16时最大程度地减少了存储体冲突, 但线程块配置为16×16时最大程度地增加了全局内存吞吐量
由此, 可以得出结论, 与共享内存吞吐量相比, 内核受到全局内存吞吐量的约束更多
5.5 常量内存:
常量内存是一种专用的内存
其对内核代码而言是只读的,但它对主机而言既是可读又是可写的
常量内存位于设备的DRAM上(和全局内存一样),并且有一个专用的片上缓存
每个SM常量内存缓存大小的限制为64KB
与其他类型的内存不同, 常量内存有一个最优访问模式:
- 当线程束中的so哦有线程都访问相同的位置, 此时访问模式是最优的
- 如果线程束访问不同的地址, 则需要串行访问
所以常量内存的读取成本与线程束中读取的地址数量息息相关
使用__constant__声明一个常量变量
由于常量内存在设备上只读, 所以必须在主机上进行初始化:
cudaError_t cudaMemcpyToSymbol(const void *symbol, const void *src, size_t count, size_t offset __dv(0), enum cudaMemcpyKind kind __dv(cudaMemcpyHostToDevice));
cudaMemcpyToSymbol函数将src指向的数据复制到设备上由symbol指定的常量内存中。枚举变量kind指定了传输方向,默认情况下,kind是cudaMemcpyHostToDevice。
常量内存的几个特点
- 生存期与应用程序相同
- 对网格内的所有线程可见
- 主机也可以直接访问
使用常量内存实现一维模板:
又开始了, 神奇的翻译
这里介绍了一个莫名其妙的九点模板(搜都搜不到, 什么HAPI翻译 )
这里重点不是理解这个九点模板, 而是考虑到他的使用场景:


- 9个x作为输入, 一个输出
- 公式中有c0, c1, c2, c3 四个常数, 并且每个线程都需要
所以可以用广播式的访问模式, 线程束中的每个线程同时引用相同的常量内存地址
所实现的核函数

代码实现具体看书, 这里重点关注他的常量内存的使用:

与只读缓存的比较:
这里要讲到Kepler架构中添加的独立只读数据缓存:

这里需要注意, 好像仅仅是Kepler架构中有这玩意, 在后续的架构中并没有这玩意:

可以看到, Kepler的SM中仅有48KB的只读缓存
所以, 制度缓存在分散读取方面比一级缓存更好, 当线程束中的线程都读取相同地址时, 不应使用只读缓存
只读缓存的使用:
当通过只读缓存访问全局内存时,需要向编译器指出在内核的持续时间里数据是只读的
-
使用内部函数__ldg

-
全局内存的限定指针

通常选用第一种__ldg方法
尤其是在只读缓存机制需要更多显式控制的情况下,或者在代码非常复杂以至于编译器无法检测到只读缓存的使用是否是安全的情况下
与常量内存的对比:
- 常量缓存加载的数据必须是少量的, 并且需要访问的一致性才能获得较好的性能
- 制度缓存加载的数据可以是比较大的, 而且能在一个非统一的模式下进行访问
所以可以得出以下结论:
- 常量缓存在读取同一地址的数据中可以更好的性能
- 只读缓存更适合于分散读取
核函数实现:
此核函数和上头的唯一区别就是函数声明部分


在Tesla K40上,使用nvprof测试得出的以下结果表明,对此应用程序使用只读内存时其性能实际上会降低。这是由于coef数组使用了广播访问模式,相比于只读缓存,该模式更适合于常量内存:

5.6 线程束洗牌指令:
从用Kepler系列的GPU(计算能力为3.0或更高)开始,洗牌指令(shuffle instruction)作为一种机制被加入其中,只要两个线程在相同的线程束中,那么就允许这两个线程直接读取另一个线程的寄存器
洗牌指令比共享内存有更低的延迟,并且该指令在执行数据交换时不消耗额外的内存
首先介绍一下束内线程(lane)的概念
简单来说, 一个束内线程指的是线程束内的单一线程, 每个束内线程都有唯一的束内线程索引, 为[0,31], 但没有单独存储束内线程索引的变量, 而是通过块内线程索引threadIdx.x计算得到:

线程束洗牌指令的不同形式:
有两组洗牌指令:一组用于整型变量,另一组用于浮点型变量。每组有4种形式的洗牌指令
这里仅介绍整型变量的4中洗牌指令, 对于单精度浮点的洗牌则与整型的完全相同
广播:
在线程束内交换整型变量,其基本函数标记如下:
__CUDA_FP16_DECL__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__shfl))__half2 __shfl(const __half2 var, const int delta, const int width = warpSize)
书里的是这个形式:
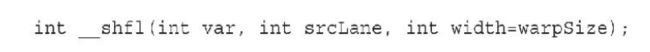
这个函数能使线程束中的每个线程都可以直接从一个特定的线程中获取某个值
线程束内所有活跃的线程都同时产生此操作,这将导致每个线程中有4字节数据的移动
参数解释:
-
返回值:
其他线程从root线程获得到的值 -
var
root线程共享出来的值 -
srcLane:
Lane代表的是束内线程, 所以可知这玩意是用来指定束内线程的 -
width:
洗牌分段
默认=warpSize=32 , 此时洗牌操作的作用范围是整个线程束
但是通过手动设置值可以调的更细, 使每段包含有width个线程, 并且每段上指定独立的洗牌操作此时srcLane使用的线程ID与束内线程ID不同, 其使用如下公式计算:


那么线程0~15将从线程3接收x的值,线程16~31将从线程19接收x的值(在线程束的前16个线程中其偏移量为3)
所以可知, 这个操作有点类似于MPI中的广播
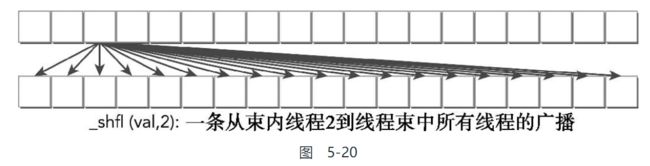
但是这里是吧__shlf中的参数写死了的情况
如果使用动态参数, 可以得到下一节中的循环交换的效果:


复制:
__CUDA_FP16_DECL__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__shfl_up))__half2 __shfl_up(const __half2 var, const unsigned int delta, const int width = warpSize);
__CUDA_FP16_DECL__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__shfl_down))__half2 __shfl_down(const __half2 var, const unsigned int delta, const int width = warpSize);
参数介绍:
- delta
线程束偏移量
其他参数都和上头的广播相似
偏移量这个就是下图所展现的
而这两个函数的区别就是方向不同:
- up向高index方向复制
- down向低index方向复制
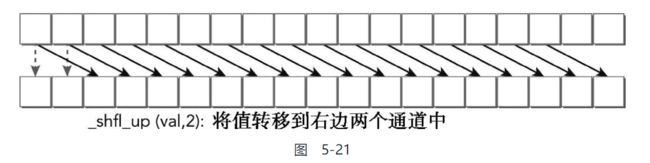
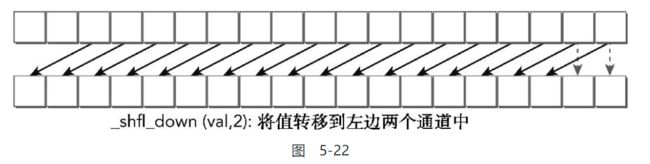
并且从图中也可以看到, 需要注意的是:
头尾部分的线程束的值保持不变, 并没有首尾相接的交换
交叉交换:
__CUDA_FP16_DECL__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__shfl_xor))__half2 __shfl_xor(const __half2 var, const int delta, const int width = warpSize)

不具体阐述了
线程束内的共享数据
在本节中,会介绍几个有关线程束洗牌指令的例子,并说明线程束洗牌指令的优点
洗牌指令将被应用到以下3种整数变量类型中:
-
标量变量
-
数组
-
向量型变量
下头就全是例子, 就中间的循环移动需要看看以外, 其他的都一笔带过
线程束内的值广播:
这里就是对上一节讲到的洗牌指令进行应用:


执行结果:

线程束内上移:
这里还是应用


线程束内下移:

线程束内环绕移动:
这里实现的就是上头所没有实现的环绕式移动, 即首尾相接的__shfl_up 或 __shfl_down

- 正偏移量为左移
- 负偏移量为右移

蝴蝶(交叉)交换:

交换数组值:
这个其实就是__shfl_xor()的花式应用
在下面的内核中,每个线程都有一个寄存器数组value,其大小是SEGM。每个线程从全局内存d_in中读取数据块到value中,使用由掩码确定的相邻线程交换该块,然后将接收到的数据写回到全局内存数组d_out中


使用数组索引交换数值:
这里实现的是在两个线程各自的数组中以不同的偏移量交换它们之间的元素,需要有基于洗牌指令的交换函数
本部分先放着

布尔变量pred被用于识别第一个调用的线程,它是交换数据的一对线程。要交换的数据元素是由第一个线程的firstIdx和第二个线程的secondIdx偏移标识的。第一个调用线程通过交换firstIdx和secondIdx中的元素开始,但此操作仅限于本地数组。然后在两线程间的secondIdx位置执行蝴蝶交换。最后,第一个线程交换接收自secondIdx返回到firstIdx的元素


使用线程束洗牌指令的并行归约
这里就是将前头的洗牌指令应用到之前的归约例子中
基本思路非常简单,它包括3个层面的归约:
-
线程束级归约
-
线程块级归约
-
网格级归约
详细的解释可以看书:


这里直接看结果:
用洗牌指令实现线程束级并行归约获得了1.42倍的加速

5.7 总结:
为了获得最大的应用性能,需要有一个能显式管理的内存层次结构。在C语言中,没有直接控制数据移动的方式。在本章中,介绍了不同CUDA内存层次结构类型,如共享内存、常量内存和只读缓存。介绍了当从共享内存中引入或删除数据时如何显式控制以显著提高其性能。还介绍了常量内存和只读缓存的行为,以及如何最有效地使用它们。
共享内存可以被声明为一维或二维数组,它能为每个程序提供一个简单的逻辑视图。物理上,共享内存是一维的,并能通过32个存储体进行访问。避免存储体冲突是在共享内存应用优化过程中一个重要的因素。共享内存被分配在所有常驻线程块中,因此,它是一个关键资源,可能会限制内核占用率。
在内核中使用共享内存有两个主要原因:一个是用于缓存片上数据并且减少全局内存访问量;另一个是传输共享内存中数据的安排方式,避免非合并的全局内存访问。
常量内存对只读数据进行了优化,这些数据每次都将数据广播到许多线程中。常量内存也使用自己的SM缓存,防止常量内存的读操作通过一级缓存干扰全局内存的访问。因此,对合适的数据使用常量内存,不仅可优化特定项目的访问,还可能提高整体全局内存吞吐量。
只读纹理缓存提供了常量内存的替代方案,该方案优化了数据的分散读取。只读缓存访问全局内存中的数据,但它使用一个独立的内存访问流水线和独立的缓存,以使SM可以访问数据。因此,只读缓存共享了常量内存的许多好处,同时对不同的访问模式也进行了优化。
洗牌指令是线程束级的内部功能,能使线程束中的线程彼此之间快速直接地共享数据。洗牌指令具有比共享内存更低的延迟,并且不需要分配额外的资源。使用洗牌指令可以减少内核中线程束同步优化的数目。然而,在许多情况下,洗牌指令不是共享内存的替代品,因为共享内存在整个线程块中都可见。
本章对一些有特殊用途的内存类型进行了深度了解。虽然这些内存类型比全局内存使用得少,但是适当地使用它们可以提高带宽利用率,降低整体的内存延迟。如果你正在研究优化的因素,那么牢记共享内存、常量内存、只读缓存和洗牌指令都是非常重要的。