Science:内侧前额叶皮层解决利用-探索困境的神经机制
在日常生活中,我们经常需要选择调整现有的解决方案或者探索新的方案,被称为利用-探索困境(exploitation-exploration dilemmas),这涉及到内侧前额叶皮层(mPFC)的功能。颅内电生理记录表明,腹内侧前额叶皮层(vmPFC)的神经活动与预测未来行为结果、评估和检测正在进行计划的可靠性和探索新方案有关。背内侧前额叶皮层(dmPFC)往往与对行为结果评估、选择改善或是放弃已有计划有关。因此,mPFC通过两个阶段的神经加工过程解决了利用-探索困境:即vmPFC主要涉及主动构建未来行为结果的意义和功能;dmPFC主要涉及对已有行为结果的评估和反馈。本文发表在Science杂志(可添加微信号siyingyxf或18983979082获取原文)。
背景:
在日常生活中,我们经常会在调整正在进行的行动计划和探索一个新计划之间进行权衡,即利用-探索困境。核磁共振的结果发现,vmPFC的激活反映了主观评定的行为价值,而dmPFC则在该价值下降时激活,此时人们往往选择放弃已有计划以探索新的计划。然而利用-探索困境的认知神经机制仍不清楚。
为了解决这个问题,在一个不确定、变化和开放的环境中,学者使用颅内脑电图记录被试执行一项利用-探索困境的任务时诱发的神经元活动。被试是6名将电极植入vmPFC和dmPFC的癫痫患者,这些癫痫患者都是被诊断为颞叶或顶叶癫痫,自身前额叶(PFC)没有异常。利用计算模型,从被试的行为中识别出“Stay试次”,即被试通过强化学习调整和维持他们正在进行的行动计划,以及“Switch试次”,即行动结果反馈导致被试放弃已有计划,并在接下来的试次中探索新的计划。接着在stay试次和switch试次中,分析vmPFC和dmPFC的神经活动。
方法
被试
6名局灶性癫痫患者(1名女性;年龄范围:25 - 49岁)。植入部位的选择是根据临床要求进行的,与本研究无关。
颅内脑电记录
作者收集6例患者的颅内脑电图(iEEG)记录。他们被长期植入12到15个立体定向多导深度电极2到3周。这些半刚性电极(DIXI Medical Instrument)直径为0.8 mm,根据目标结构的不同,由5 ~ 15个线性排列的接触导线(2mm宽)组成,两个连续导线之间的间隙为1.5 mm。通过扫描T1加权像获得电极的解剖位置。术后8天记录iEEG(8.6天,1.4 SEM);采用128通道视频脑电图监测系统(Micromed;采样率,512hz)。iEEG数据在线带通滤波(0.1 ~ 200hz)。
实验范式
被试完成威斯康辛卡片分类测试(Wsiconsin card sorting test ,WCST),通过试错来学习数字和反应按钮的组合。组合的变化是不可预测的。屏幕中央的黑色背景上显示了四个代表四个响应按钮的白色方框(图1B)。每次试次开始时,在800毫秒的时间里,每个盒子里都会显示一个白色的数字(三个可能的数字中的一个)。患者通过按四个按钮中的一个对刺激做出反应。在整个实验过程中,患者必须用同一根手指按同一个按钮。刺激发生后,除了与按钮相关的框中显示的数字,所有显示的数字在1800到2200毫秒之间消失:如果被试按正确的按钮,这个数字有90%概率变绿(正反馈),10%概率变红(负反馈)。如果被试按下另一个按钮,正反馈和负反馈的概率就会反转,因此响应反馈是随机的。如果在刺激开始的1500毫秒内没有反应,那么刺激消失,呈现没有信息的中性的反馈(每个盒子里都有破折号)。响应反馈时间为800ms,800毫秒后,反馈消失了,呈现四个判断盒。从反馈开始的呈现时间为1200到1600毫秒。被试知道试次中的每个数字只与一个正确的响应按钮相关,不同的数字与不同的响应相关(见图1C),且反馈并不是完全可靠的(被试不知道确切的反馈概率)。最后,被试被告知数字反应组合会发生偶发性和不可预测的变化,但没有向被试提供额外的转换提示。
该任务诱导被试根据反馈不断地在两种选择之间做出判断:
(i)通过适当调整维持预期的组合;
(ii)放弃预期组合去探索新的组合。
在每一次试次中,被试的反应可能是正确的(correct,概率为25%),维持(perseverating,在当前事件中是错误的,但在前一事件中是正确的;概率为25%),或辅助(ancillary,既不正确也不持续;概率为50%)。
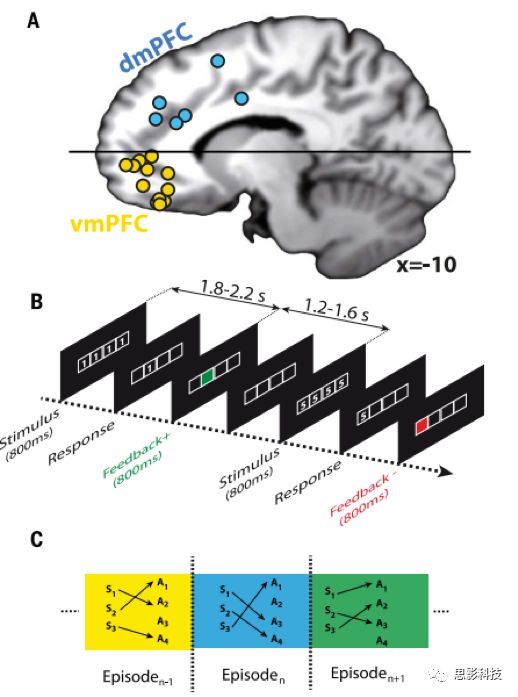
图1 实验过程
(A)被试的大脑前额叶内侧的横向电极的定位;(B)流程图;(C)实验中的行为反应结构组成
计算模型
作者提出了一个计算模型来描述人类前额叶功能如何在不确定、变化和开放的环境中指导适应性行为。
在每个试次t中,外部偶发事件,即刺激st、作用at和结果ot之间的统计关系,只依赖于外在的隐藏状态(潜在的原因) 。该模型假设外部环境是不确定的、不断变化的、开放的。因此,隐藏状态是可计数的、潜在的、无限的、不可直接观察的。隐藏状态的出现与刺激和行为无关,且相互独立,可能以不同的频率出现。
。该模型假设外部环境是不确定的、不断变化的、开放的。因此,隐藏状态是可计数的、潜在的、无限的、不可直接观察的。隐藏状态的出现与刺激和行为无关,且相互独立,可能以不同的频率出现。
行动计划TSm(Task-Sets)对应于隐藏状态(潜在原因):每个储存在长期记忆中的计划都是人们习得隐藏状态相关的外部偶发事件和最大行为回报率的结果。行动计划包括三个内部映射:
(1)选择性映射:对于刺激s的反馈o给予期望评价值r[o]。

(2)预测映射:对于刺激s和可能的反馈o给予可能的结果评价。
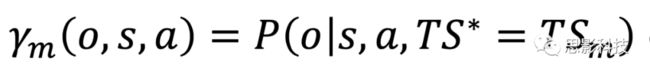
(3)上下文映射:对于刺激s给予可能的隐藏状态m的概率评价。

预测映射:是动作结果的预测器,独立于任何结果值或奖励值的概念。预测映射需要用于评估外部突发事件的不确定性,特别是外部状态和行动结果的可能变异性。
选择性映射:从行动结果编码奖励期望,并且是将行为导向最有回报的行动所必需的。在不确定和多变的环境中,选择映射和预测映射是有效适应行为的必要条件。
上下文映射:允许进一步学习预测外部状态的外部线索,也就是将这些外部线索与已经学习了与这些外部状态相对应的外部事件的行动计划联系起来。
行动计划的可靠性
该模型假设执行系统监控最多N个行动计划的可靠性,即推理缓冲容量为N。




模型拟合过程
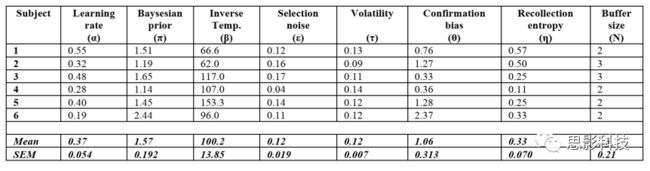
该模型有7个连续参数和1个离散参数。为了使模型适合每个被试的选择行为,作者使用了马尔可夫链和蒙特卡罗切片抽样方法。因此,作者从后验参数中提取了700万个样本(与先验参数范围一致;对于4种独立的集合,每个缓存大小从1到6的400,000个样本;50,000个burn-in)。作者计算每个被试的模型对数似然值,方法是将所有试次中模型epsilon softmax函数提供的对数似然值相加。为了获得稳健的个体参数估计,作者计算了使用最大后验概率的缓冲区大小估计的所有样本的对数似然加权平均值(表S2)。最后,作者通过对整个样本集进行随机重采样并计算其对数似然加权平均值,一次又一次地计算模型变量的蒙特卡洛估计值(前验可靠性、后验可靠性、选择值等)。
表S2 模型参数的贝叶斯估计
iEEG数据处理
作者只报告了位于mPFC的电极数据,他们使用EEGLAB执行了所有的预处理步骤。首先,使用频域回归和基于Thompson F统计值的阈值来消除伪迹(带宽2hz,滑动窗口长度为2-和1.5-s步长)。然后,iEEG数据取刺激开始前的2000毫秒到刺激开始后的5000毫秒,并使用三次多项式拟合进行去线性趋势分析。每一个电极都使用与他相邻的电极(双极导联)进行重参考。
使用基于MATLAB的FieldTrip工具箱进行时频分析,使用自适应多窗谱时频变换计算功率谱。较低的频率范围:4到32hz,六个周期,每窗口包含三种窗宽;更高的频率范围:32到200hz,固定时间窗口为240ms,每个窗口有4到31个窗宽。
iEEG数据分析
基于模型的gamma带活动分析
作者首先在每个试次在每个时间点上通过gamma和high gamma频段的平均功率谱,计算反映神经放电的局部神经活动。对于每个电极,作者在整个试次的平均时频图上归纳gamma波段的上下边界,平均下限值为41.9±5.6 Hz(平均SEM;至少40 Hz;最大60Hz),上限值为140.4±30.8Hz(平均SEM;最低110赫兹,最大200赫兹)。
其次,作者在试次中回归了gamma频段振幅。作者采用蒙特卡罗逐次估计模型变量的回归项。这些回归分别对每个电极进行,然后对电极和被试进行平均,计算平均值。在统计阈值为P < 0.05的情况下进行统计推断,进行了多重比较校正(FWE)。
Switch试次与Stay试次的比较分析
对于每个电极,在Switch试次和两个相邻Stay试次(相对于Switch试次,从-2到+2的试次)的每一频率的每一个时间步上,对功率进行配对样本T 检验,得到对应的T值,并在电极和被试水平进行了平均。在阈值为P < 0.05的情况下进行统计推断,进行了多重比较校正(FWE)。
与反馈相关的神经活动
为分析侧前额叶皮层和dmPFC局部场电位与响应相关反馈,作者计算在每一个试次每个时间步(从反馈开始-500 ms + 1500 ms)的功率,并在试次间进行平均。
心理生理相互作用
作者使用心理生理相互作用(PPI)分析在Stay试次之间反馈前的dmPFC高gamma活动侧前额叶皮层(平均400 ms反馈发作),选择编码值和之前行为可靠性和反馈后dmPFC高gamma活动(反馈开始后,从+300 ms到+600毫秒),而无符号编码预测错误。因此,作者测试了在Stay试次中,vmPFC和dmPFC脑区活动之间的相关性是否与这三个模型变量(选择值、行为可靠性和无符号预测误差)各不相同。作者对植入vmPFC和dmPFC电极被试的所有vmPFC-dmPFC电极进行了三次相应的PPI分析。
对于每次分析,作者首先根据感兴趣的模型变量将Stay试次分成30个bin。通过每个bin内的试次,作者计算了每对电极的vmPFC和dmPFC活动之间的相关性,即Fisher z转换相关系数。然后,作者通过计算这些Fisher z转换的相关系数和感兴趣的模型变量之间的Pearson’s r相关结果来估计每对电极的PPI。通过将接触对之间的Pearson’s r相关结果,使用单样本双侧t检验来评估PPI的统计显著性。
识别利用到探索的转换
为了确定被试何时从预设的方案转向探索新的方案,作者借鉴了之前一个采用近似于最佳自适应过程的在线算法的研究。根据这个模型,假定的组合形成了将数字、反应和预期反馈联系起来的行动计划。这些计划是在线监控的:算法概率推断出假定计划的可靠性。例如,当计划i0匹配当前组合的可能性大于不匹配时,例如,λi0>1-λi0(或等价的,λi0 >0.5)。此时算法处于调整状态:我们通过RL(强化学习,reinforce-ment learning)来调整预设的计划。而当我们的行为错误率较高,说明已有方案不可靠时(all λi <0.5),算法切换到探索状态:综合先前学习的计划,形成一个新计划,并从反馈中学习中印证。而当新计划可靠性较高时,算法最终返回到调整状态,若不可靠则推翻重来。
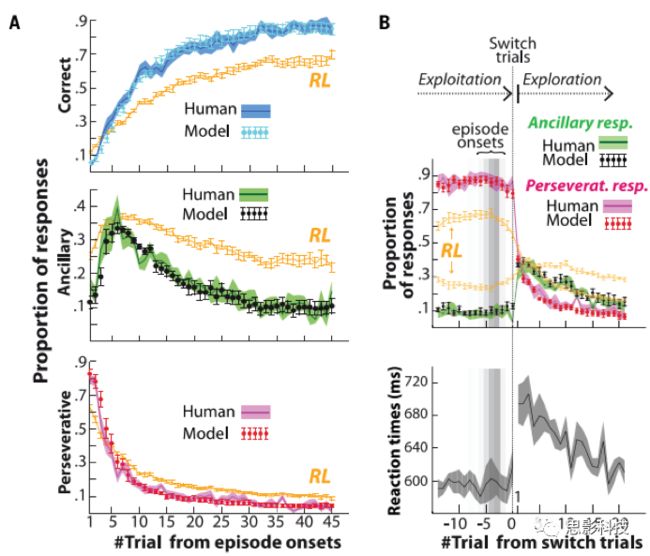
图2 行为结果
(A)被试的三种反应模式之比;(B)被试的反应与模型预测对比
模型图2A揭示了被试从利用(explotation)转向探索(exploration)的行为过程。正如作者所预期的,在情景发生变化后的2-8个试次时,大部分被试会从调整转向探索。在Switch试次中,错误反馈导致被试行为的可靠性下降到可靠阈值(λ= 0.5)以下,从而被试在后续试次中开始探索新的行为。图2B说明模型和被试的反应都是不受事件内容的影响:
在Stay试次时,大多数反应仍然持续的(~ 85%),而剩余的反应被随机分布在辅助(~ 10%)和正确的反应(~5%)。相比之下,在Switch试次后,模型和被试的持续反应都突然下降到~40%,而辅助和正确反应突然上升到接近他们的机会水平(chance level,~40和~20%)(图2B)。算法的突然改变也反映在被试的反应时上,Switch试次的反应时突然增加了约100ms,可能归因于增加Switch试次后的响应变化或发生意想不到的反馈。因此,在Switch试次中,反馈促使被试从他们正在进行的计划中切换到探索新的计划。相比之下,在Stay试次中,该模型显示被试的行为不是来自于行为强化过程,而是同化行为强化来适应外部的偶发事件,尤其是从探索模式转为调整模式。总的来说,模型认为switch试次取决于实际反馈,而不是先前行为可靠性。
行为可靠性的神经机制
作者用时频分析研究了在vmPFC和/或dmPFC中的局部神经处理是否一定程度上推断模型预测的行动可靠性。作者提取了高频gamma波段(50到150赫兹)的神经活动,反映了在每个时间点上的局部神经活动。作者采用了单次多元回归分析,将模型变量作为被试内回归变量,包括以下内容:
(i)与反馈相关的前、后行为可靠性(prior and posterior actorreliability ),按此顺序正交化,以便第二个回归变量仅从反馈中获取可靠性更新;
(ii)按照模型沿行动者监测的备选计划的可靠性进行回归;
(iii)所选动作的RL值,可用于测量了从prior actor可靠性运算后验时所涉及的正反馈概率。为了消除潜在的混杂因素,还加入了额外的回归变量。
vmPFC高频gamma活动几乎在整个试次(包括试次间隔)对prior actor可靠性进行了线性编码(图3)。此外在被试反应后约300毫秒,该波段活动进一步开始对所选值进行线性编码。这个编码在反馈出现时逐渐增加,然后下降,这表明vmPFC在反馈出现时也有所预期。最后,在反馈发生~350 ms后,进一步开始对posterior actor可靠性进行线性编码。未发现替代策略的可靠性之间存在显著相关性,证实了vmPFC在监控驱动持续行为的行动计划方面的特殊作用。相比之下,在dmPFC中高频gamma活动与之前的任何回归变量无关(图3)。最后,作者发现这两个区域与其他频段的神经活动没有显著相关性。
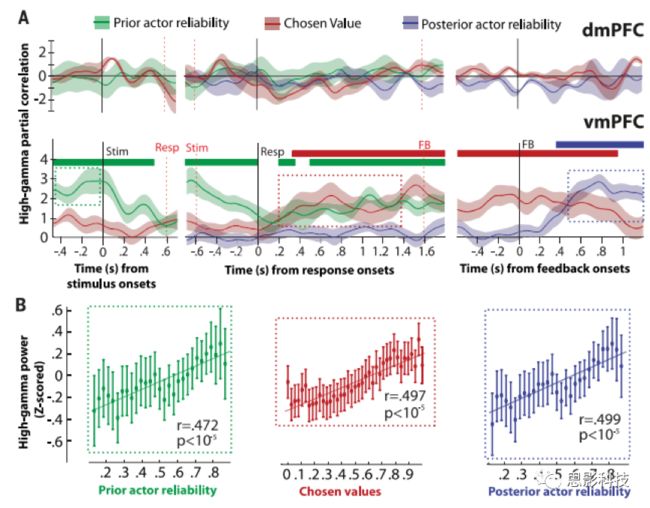
图3 mPFC中模型变量的神经编码
(A)在dmPFC和vmPFC内电极gamma活动时间进程;
(B)VmPFC high gamma活动与其它指标的对比
vmPFC及其探索预期
为了理解对行为可靠性的监控如何从调整转换到探索,作者比较了在switch和stay试次中的神经活动。在vmPFC中,与邻近的stay试次相比,switch试次只诱发了开始于~ 350ms的theta频带(13至30hz)神经活动的显著增加,并在反馈开始前~ 70ms达到峰值,反馈开始后约150ms消失(图4A)。这种预反馈效应与记录的beta波段活动在预测即将到来的刺激中的作用是一致的。而改变出现在switch试次中,但不出现在先前和随后的邻近试次(图4B),也导致消极或积极的反馈(图5)。因此,该结果不太可能反映stay和switch条件的奖励或反馈预期差异:在Switch试次和之前的stay试次中,积极反馈和选择的值(或反馈可能)几乎是相同的(图4D)。这种结果也不太可能反映行为的可靠性,因为行为的可靠性会逐渐降低,而beta波活动在Switch试次之前的Stay试次中保持不变(图4D)。
分析表明,被试是在行为反馈的影响下从调整模式转变为探索模式。因此,作者得出结论,在vmPFC中观察到的预反馈效应反映即将到来的反馈可能突然导致posterior actor可靠性越过阈值,或者同样地,prior actor可靠性足够接近阈值。vmPFC似乎在反馈发生前通过阈值来评估行为可靠性。
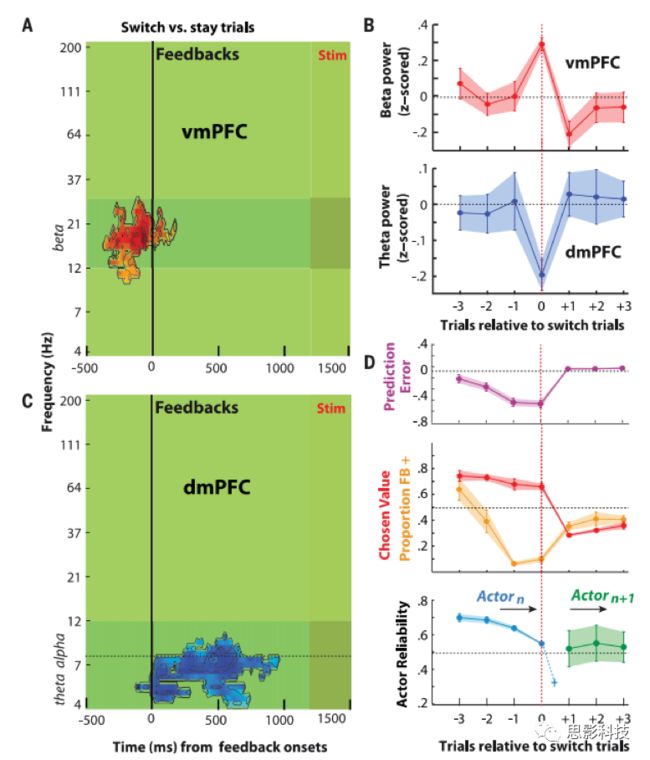
图4 Switch和Stay试次的mPFC神经活动。
dmPFC对探索触发和学习信号的反应
相比之下,在dmPFC中,Switch试次与邻近的Stay试次仅在反馈开始后才表现出显著的神经活动差异。活动从反馈开始,并持续至反馈结束后~ 200ms(即持续~1000ms)。这种后反馈效应发生在beta波段的频率(4到8Hz),少量扩展到alpha波段的频率(8到12Hz)(图4C)。尽管这种后反馈激活在Switch试次前后的Stay试次中保持不变,但在Switch试次中却突然下降(图4B)。与之相同的原因,这突然的后反馈效果既不能归因于人们对奖励反馈的预期的变化也不能归因于不同的奖励预测错误(reward prediction errors ,RPEs),因为这些错误在Switch和Stay试次中几乎都是相同的(图4 d)。此外,行为的可靠性与dmPFC的神经活动无关,并且仅在反馈开始后约350毫秒在vmPFC中更新。此外,在反馈开始出现的效果不太可能反映一个自下而上的反应过程,比较posterior actor的可靠性与0.5信度阈值,从而导致在switch试次中进行探索的决定。然而,当这种dmPFC后反馈效应出现时,vmPFC前反馈效应就开始下降。这说明在Stay和Switch之间,vmPFC主动调节dmPFC以处理不同的反馈即学习信号和探索触发。与这种解释一致,vmPFC前反馈效应出现在自上而下的预测性神经处理的beta带频率中,而dmPFC后反馈效应出现在反映了支持行为控制的theta频率中。
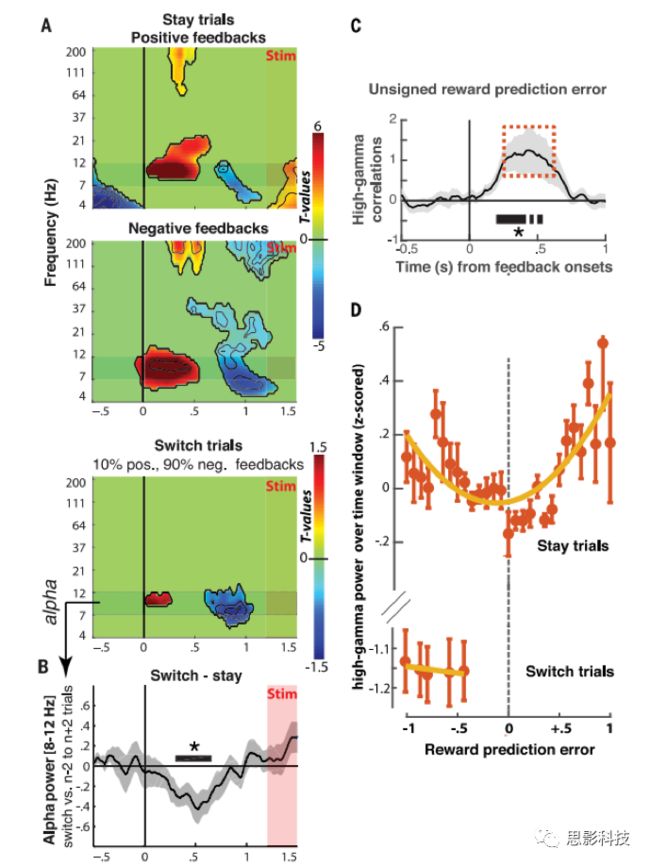
图6与响应反馈相关的dmPFC神经活动
在Stay试次中,dmPFC对正、负反馈的均表现为增强的alpha频段频率,此现象在约600毫秒后消失(图6A)。以dmPFC为中心的alpha波段活动被认为可以抑制与正在进行的行为无关的神经表征,从而有利于维持进行中的被试计划并根据反馈进行调整。与此一致的是,在反馈开始后的200 ~ 600毫秒内,dmPFC正、负反馈的神经反应表现出第二个共同特征,这与RL(强化学习)过程特征,即强烈的高gamma活动增加与无符号PREs(unsigned PREs,即选择值之间的差异和实际反馈)相对应。
因此,Stay试次中的dmPFC神经反应反馈瞬时编码无符号RPEs扩展RL过程。正如预期的那样,dmPFC中的这种后反馈RPE编码与作者在vmPFC中观察到的所选值的前反馈编码在功能上是相关的。vmPFC前反馈和dmPFC后反馈高频gamma波段的相关,并且这种跨时间相关性随着选择的值而增加(图7),这表明vmPFC中所选值的表征在dmPFC脑区加工以辅助RPE计算。同样,当无符号RPEs增加时,跨时间相关性进一步降低,且时间相关性与被试的可靠性无关(图7)。
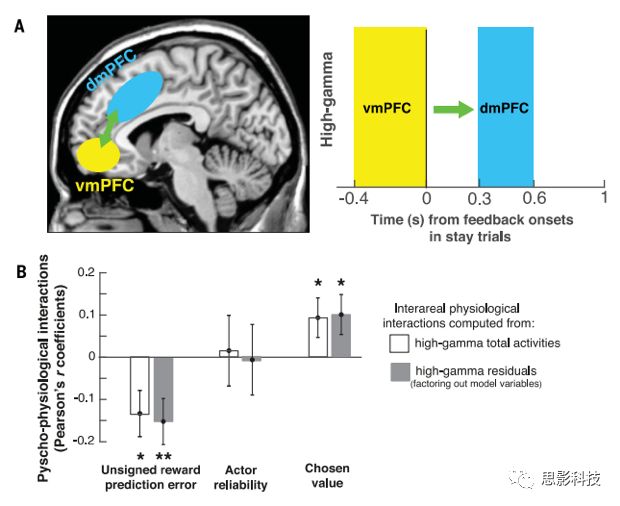
图7 在Stay试次中从vmPFC到dmPFC高gamma活动的功能连接分析
(A)300到600ms记录的dmPFC高gamma活动之间的生理相关性;(B)心理生理相互作用(PPI)
在Switch试次中,这种dmPFC对反馈的响应联动被破坏了。首先,与Stay试次相比,Switch试次dmPFC的theta波段活动从反馈开始就降低了;其次,dmPFC的alpha波段活动显著降低并在约250毫秒后迅速消失(图6,A和B);第三,反馈开始后,在持续试次中观察到在200 ~600 ms之间dmPFC高频gamma频段活动下降,这进一步停止了对任何RPEs的编码(图6,A和D)。因此,dmPFC在switch试次中处理的反馈不同于学习信号。随着alpha波段反应抑制可能释放与正在进行的行动计划无关的神经表征相关的抑制,并阻止RL过程调整这个行动计划。因此在Switch试次中,dmPFC似乎倾向于反馈开始后约250毫秒内形成新的行动计划。
通过预测编码解决利用-探索困境
vmPFC的gamma频段活动涉及正在进行的行动结果的可靠性的评估与追踪。在行动之后,它会主动标记可能的结果(通过beta波段频率),来决定是继续调整现有的计划还是探索新的方案。根据这个功能,dmPFC在theta波段频率上的活动似乎反映了dmPFC对动作结果的响应。dmPFC涉及对实际结果的反应,然后似乎通过抑制alpha频带频率的神经活动来实现调整到探索的转换。这有利于神经表征的出现,形成新的行动计划,并通过抑制dmPFC高gamma活动扩展RL过程,防止通过RL调整正在进行的计划。因此,mPFC通过从vmPFC到dmPFC的自上而下的预测编码过程解决了利用-探索困境。这种预测编码过程的优势在于加速放弃正在进行的行动计划,并防止引发探索的行动结果错误的充当学习信号。
最初开发用来描述知觉皮层过程的预测编码,也可能在前额执行过程中发挥作用。在知觉预测编码中,观察者对场景的先验信念改变了他们对场景的感知。作者的发现表明:在前额执行系统中,预测编码根据主体对自身行为的信念,主动改变行为事件的功能意义。
结论
通过一种最初为知觉提出的预测编码机制,mPFC解决了利用-探索困境的机制问题。vmPFC对正在进行的行动计划的可靠性进行监测,对即将到来的行动结果的功能意义设置为学习信号以加以利用,或对潜在的触发因素进行探索。dmPFC根据这个功能结构对行动结果做出反应,要么保持现状,通过强化学习来调整正在进行的计划,要么放弃这个计划去探索新的计划。这种预测编码机制的优势在于加速放弃正在进行的行动计划,并防止引发探索的行动结果不当地充当学习信号。这些发现支持了这样一种观点:即预测编码也在前额叶执行系统中运行,并构成了贯穿大脑皮层的信息处理的一般机制。在感知神经系统中,预测编码的操作使得观察者对一个场景的先验认知会改变他们对这个场景的感知。研究结果表明,在前额执行系统中,预测性编码是通过根据主体对自身行为的信念,主动改变行为事件的功能意义来运作的。
如需原文及补充材料请加思影科技微信:siyingyxf 或者18983979082获取,如对思影课程及服务感兴趣也可加此微信号咨询。觉得对您的研究有帮助,请给个转发,以及右下角点击一下在看,是对思影科技莫大的支持。

微信扫码或者长按选择识别关注思影
非常感谢转发支持与推荐
欢迎浏览思影的数据处理业务及课程介绍。(请直接点击下文文字即可浏览思影科技所有的课程,欢迎添加微信号siyingyxf或18983979082进行咨询,所有课程均开放报名,报名后我们会第一时间联系,并保留已报名学员名额):