论最强IO:MappedByteBuffer VS FileChannel
最近一直在研究MQ,开源社区中有很多高性能MQ:kafka、RocketMQ、ActiveMQ,抛开网络传输方式、数据结构设计、文件存储方式...等因素。Java 在 JDK 1.4 引入了 ByteBuffer 等 NIO 相关的类,使得 Java 程序员可以抛弃基于 Stream ,从而使用基于 Block 的方式读写文件。这些MQ有一个共同的特点就是:引入了 IO 性能优化之王MappedByteBuffer (零拷贝之内存映射:mmap) 和 FileChannel (sendFile) 。
| MQ | read/write |
| kafka | record记录基于FileChannel/FileChannel index的读写基于MMAP 更多介绍 |
| RocketMQ | MMAP/MMAP(默认,可通过修改配置,配置成 FileChannel,原因是作者想避免 PageCache 的锁竞争,通过两层架构实现读写分离) |
| ActiveMQ | RandomAccessFile/RandomAccessFile |
| QMQ | MMAP/FileChannel |
彻底理解零拷贝
read(file, tmp_buf, len);
write(socket, tmp_buf, len);
看似简单两个调用,但其实很多人并没有完全理解Linux下所谓的零拷贝功能,或者理解是有误的!
数据被复制了至少四次,并且执行了几乎相同数量的用户/内核上下文切换
图的上半部展示了上下文切换,而下半部展示了复制操作。这经历了4个步骤:
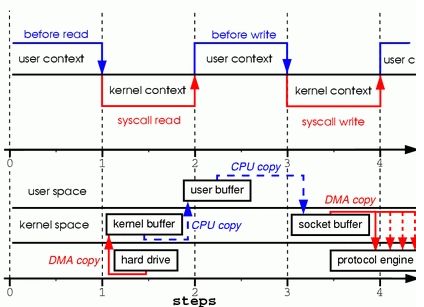
1. 系统调用read导致了从用户空间到内核空间的上下文切换。DMA模块从磁盘中读取文件内容,并将其存储在内核空间的缓冲区内,完成了第1次复制。
2. 数据从内核空间缓冲区复制到用户空间缓冲区,之后系统调用read返回,这导致了从内核空间向用户空间的上下文切换。此时,需要的数据已存放在指定的用户空间缓冲区内(参数tmp_buf),程序可以继续下面的操作。
3. 系统调用write导致从用户空间到内核空间的上下文切换。数据从用户空间缓冲区被再次复制到内核空间缓冲区,完成了第3次复制。不过,这次数据存放在内核空间中与使用的socket相关的特定缓冲区中,而不是步骤一中的缓冲区。
4. 系统调用返回,导致了第4次上下文切换。第4次复制在DMA模块将数据从内核空间缓冲区传递至协议引擎的时候发生,这与我们的代码的执行是独立且异步发生的。你可能会疑惑:“为何要说是独立、异步?难道不是在write系统调用返回前数据已经被传送了?write系统调用的返回,并不意味着传输成功——它甚至无法保证传输的开始。调用的返回,只是表明以太网驱动程序在其传输队列中有空位,并已经接受我们的数据用于传输。可能有众多的数据排在我们的数据之前。除非驱动程序或硬件采用优先级队列的方法,各组数据是依照FIFO的次序被传输的(图1中叉状的DMA copy表明这最后一次复制可以被延后)。
正如你所看到的,上面的过程中存在很多的数据冗余。某些冗余可以被消除,以减少开销、提高性能。作为一名驱动程序开发人员,我的工作围绕着拥有先进特性的硬件展开。某些硬件支持完全绕开内存,将数据直接传送给其他设备的特性。这一特性消除了系统内存中的数据副本,因此是一种很好的选择,但并不是所有的硬件都支持。此外,来自于硬盘的数据必须重新打包(地址连续)才能用于网络传输,这也引入了某些复杂性。为了减少开销,我们可以从消除内核缓冲区与用户缓冲区之间的复制入手。
思考:堆內/堆外内存的拷贝该如何实现的?
因此,DirectByteBuffer通过免去中间交换的内存拷贝也属于zero-copy范畴,可参阅我的另一篇Netty的资源泄露探测器:ResourceLeakDetector
而mmap和sendfile会在下文中展开讲。
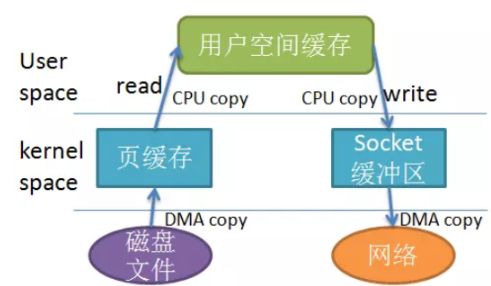
RandomAccessFile有啥问题
其实RandomAccessFile确实不快,这就是为何ActiveMQ在社区中反映平平。思考为何它比较慢呢?看下图就明白了!
从写文件理解PageCache
它是用户内存和磁盘之间的一层缓存,而java的写都是到PageCache 便是完成认为逻辑落盘成功,后续操作系统会把它刷到磁盘文件上。
mmap
mmap基于 OS 的 mmap 的内存映射技术,通过 MMU 映射文件,将文件直接映射到用户态的内存地址,使得对文件的操作不再是 write/read,而转化为直接对内存地址的操作,使随机读写文件和读写内存相似的速度。
mmap 把文件映射到用户空间里的虚拟内存,省去了从内核缓冲区复制到用户空间的过程,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,这样的文件读写文件方式少了数据从内核缓存到用户空间的拷贝,效率很高。
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);

接着着零拷贝的章节看,它经历了3个步骤:
1. mmap系统调用导致文件的内容通过DMA模块被复制到内核缓冲区中,该缓冲区之后与用户进程共享,这样就内核缓冲区与用户缓冲区之间的复制就不会发生。
2.write系统调用导致内核将数据从内核缓冲区复制到与socket相关联的内核缓冲区中。
3. DMA模块将数据由socket的缓冲区传递给协议引擎时,第3次复制发生。
通过调用mmap而不是read,我们已经将内核需要执行的复制操作减半。当有大量数据要进行传输是,这将有相当良好的效果。然而,性能的改进需要付出代价的;是用mmap与write这种组合方法,存在着一些隐藏的陷阱。例如,考虑一下在内存中对文件进行映射后调用write,与此同时另外一个进程将同一文件截断的情形。此时write系统调用会被进程接收到的SIGBUS信号中断,因为当前进程访问了非法内存地址。对SIGBUS信号的默认处理是杀死当前进程并生成dump core文件——而这对于网络服务器程序而言不是最期望的操作。
有两种方式可用于解决该问题:
第一种方式是为SIGBUS信号设置信号处理程序,并在处理程序中简单的执行return语句。在这样处理方式下,write系统调用返回被信号中断前已写的字节数,并将errno全局变量设置为成功。必须指出,这并不是个好的解决方式——治标不治本。由于收到SIGBUS信号意味着进程发生了严重错误,我不鼓励采取这种解决方式。
第二种方式应用了文件租借(在Microsoft Windows系统中被称为“机会锁”)。这才是解劝前面问题的正确方式。通过对文件描述符执行租借,可以同内核就某个特定文件达成租约。从内核可以获得读/写租约。当另外一个进程试图将你正在传输的文件截断时,内核会向你的进程发送实时信号——RT_SIGNAL_LEASE。该信号通知你的进程,内核即将终止在该文件上你曾获得的租约。这样,在write调用访问非法内存地址、并被随后接收到的SIGBUS信号杀死之前,write系统调用就被RT_SIGNAL_LEASE信号中断了。write的返回值是在被中断前已写的字节数,全局变量errno设置为成功。下面是一段展示如何从内核获得租约的示例代码。
mmap 是直接把 MappedByteBuffer 中的数据写入到磁盘吗?
no,mappedByteBuffer 的 put 行为实际讲数据写到了虚拟内存(可以近似理解成 PageCache,但不是),而虚拟内存是依赖于操作系统的定时刷盘的,但也可以手动通过 mappedByteBuffer.force() 接口来手动控制刷盘。
定时刷盘,是为了防止数据丢失,MMAP 和 FileChannel (sendFile)都有 force 方法
MMAP 有哪些注意事项?
- MMAP 使用时必须实现指定好内存映射的大小,mmap 在 Java 中一次只能映射 1.5~2G 的文件内存,其中RocketMQ 中限制了单文件1G来避免这个问题
- MMAP 可以通过 force() 来手动控制,但控制不好也会有大麻烦
- MMAP 的回收问题,当 MappedByteBuffer 不再需要时,可以手动释放占用的虚拟内存,但使用方式非常的麻烦
fileChannel.map之后会立刻获得一个 1.5G 的文件,但此时文件的内容全部是 0(字节 0),之后对内存中 MappedByteBuffer 做的任何操作,都会被最终映射到文件之中。
从源码中看最终调用了FileChannelImpl.map0(底层通过mmap64实现),对应JVM-HotSpot的linux源码、windows源码
//MappedByteBuffer 便是MMAP的操作类(获得一个 1.5G 的文件)
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 1.5 * 1024 * 1024 * 1024);
// write
byte[] data = new byte[4];
int position = 8;
//从当前 mmap 指针的位置写入 4b 的数据
mappedByteBuffer.put(data);
//指定 position 写入 4b 的数据
MappedByteBuffer subBuffer = mappedByteBuffer.slice();
subBuffer.position(position);
subBuffer.put(data);
// read
byte[] data = new byte[4];
int position = 8;
//从当前 mmap 指针的位置读取 4b 的数据
mappedByteBuffer.get(data);
//指定 position 读取 4b 的数据
MappedByteBuffer subBuffer = mappedByteBuffer.slice();
subBuffer.position(position);
subBuffer.get(data);sendFile
sendfile系统调用在内核版本2.1中被引入,目的是简化通过网络在两个本地文件之间进行的数据传输过程。sendfile系统调用的引入,不仅减少了数据复制,还减少了上下文切换的次数。FileChannel 的write 和 read 方法均是线程安全的,它内部通过一把 private final Object positionLock = new Object(); 锁来控制并发。

接着着零拷贝和mmap的章节看,它经历了2个步骤:
1. sendfile系统调用导致文件内容通过DMA模块被复制到某个内核缓冲区,之后再被复制到与socket相关联的缓冲区内。
2. 当DMA模块将位于socket相关联缓冲区中的数据传递给协议引擎时,执行第3次复制。
你可能会在想,我们在调用sendfile发送数据的期间,如果另外一个进程将文件截断的话,会发生什么事情?如果进程没有为SIGBUS注册任何信号处理函数的话,sendfile系统调用返回被信号中断前已发送的字节数,并将全局变量errno置为成功。
然而,如果在调用sendfile之前,从内核获得了文件租约,那么类似的,在sendfile调用返回前会收到RT_SIGNAL_LEASE。到此为止,我们已经能够避免内核进行多次复制,然而我们还存在一分多余的副本。这份副本也可以消除吗?当然,在硬件提供的一些帮助下是可以的。为了消除内核产生的素有数据冗余,需要网络适配器支持聚合操作特性。该特性意味着待发送的数据不要求存放在地址连续的内存空间中;相反,可以是分散在各个内存位置。在内核版本2.4中,socket缓冲区描述符结构发生了改动,以适应聚合操作的要求——这就是Linux中所谓的"零拷贝“。这种方式不仅减少了多个上下文切换,而且消除了数据冗余。从用户层应用程序的角度来开,没有发生任何改动,所有代码仍然是类似下面的形式:sendfile(socket, file, len);
1.sendfile系统调用导致文件内容通过DMA模块被复制到内核缓冲区中。
2. 数据并未被复制到socket关联的缓冲区内。取而代之的是,只有记录数据位置和长度的描述符被加入到socket缓冲区中。DMA模块将数据直接从内核缓冲区传递给协议引擎,从而消除了遗留的最后一次复制。
由于数据实际上仍然由磁盘复制到内存,再由内存复制到发送设备,有人可能会声称这并不是真正的"零拷贝"。然而,从操作系统的角度来看,这就是"零拷贝",因为内核空间内不存在冗余数据。应用"零拷贝"特性,出了避免复制之外,还能获得其他性能优势,例如更少的上下文切换,更少的CPU cache污染以及没有CPU必要计算校验和。

FileChannel 为什么比普通 IO 要快呢?
FileChannel 只有在一次写入 4kb 的整数倍时,才能发挥出实际的性能,这得益于 FileChannel 采用了 ByteBuffer 这样的内存缓冲区,让我们可以非常精准的控制写盘的大小,这是普通 IO 无法实现的。4kb 一定快吗?这主要取决你机器的磁盘结构,并且受到操作系统,文件系统,CPU 的影响。比如阿里云的ECS一次至少写入 64kb 才能发挥出最高的 IOPS。
FileChannel 是直接把 ByteBuffer 中的数据写入到磁盘吗?
NO,ByteBuffer 中的数据和磁盘中的数据还隔了一层,这一层便是 PageCache,是用户内存和磁盘之间的一层缓存。我们都知道磁盘 IO 和内存 IO 的速度可是相差了好几个数量级。我们可以认为 filechannel.write 写入 PageCache 便是完成了落盘操作,但实际上,操作系统最终帮我们完成了 PageCache 到磁盘的最终写入,理解了这个概念,你就应该能够理解 FileChannel 为什么提供了一个 force() 方法,用于通知操作系统进行及时的刷盘。
从源码中看最终调用了FileChannel.transferTo0(底层通过sendfile64),对应JVM-HotSpot的linux源码、windows源码
FileChannel fileChannel = new RandomAccessFile(new File("db.data"), "rw").getChannel();
// 写
byte[] data = new byte[4096];
long position = 1024L;
//指定 position 写入 4kb 的数据
fileChannel.write(ByteBuffer.wrap(data), position);
//或从当前文件指针的位置写入 4kb 的数据
//fileChannel.write(ByteBuffer.wrap(data));
// 读
ByteBuffer buffer = ByteBuffer.allocate(4096);
long position = 1024L;
//指定 position 读取 4kb 的数据
fileChannel.read(buffer,position);
//或从当前文件指针的位置读取 4kb 的数据
//fileChannel.read(buffer);选MMAP 还是 FileChannel?
理论分析下,FileChannel 同样是写入内存,但比 MMAP 多了一次内核缓冲区与用户空间互相复制的过程,所以在极端场景下,MMAP 表现的更加优秀。
MMAP 并非是文件 IO 的银弹,它只有在一次写入很小量数据的场景下才能表现出比 FileChannel 稍微优异的性能。很多人认为:读 4kb 以下的数据请使用 mmap,大于 4kb 以上请使用 FileChannel。由于本人采用的是window系统,测评程序并非如此:
* write(<4kb): RandomAccessFile(4.1s)>FileChannel(3.9s)>FileOutputStream(3.9s)>MappedByteBuffer(67ms)
* read(<4kb): RandomAccessFile(2.6s)>FileChannel(2.6s)>MappedByteBuffer(69ms)
*
* write(>=4kb): FileChannel(150ms)>RandomAccessFile(83.5ms)>FileOutputStream(83ms)>MappedByteBuffer(50ms)
* read(>=4kb): RandomAccessFile(197ms)>FileChannel(74ms)>MappedByteBuffer(72ms)
最后留下一个疑问:顺序读比随机读快,顺序写比随机写快,下篇展开讲解!
参阅资料
- Zero Copy: User-Mode Perspective