YOLOv8中加入跨维度注意力机制注意力机制GAM,效果超越CMBA,NAM

一、Global Attention Mechanism论文

论文地址:2112.05561.pdf (arxiv.org)
二、GAM结构
GAM_Attention专注于全局注意力的设计,在YOLOv8中加入GAM_Attention旨在通过全局信息对整个输入的图片上的火焰烟雾特征进行建模,使YOLOv8的网络能够更好地了解图像中的全局结构与关系。 GAM_Attention通常包含多个层次的注意力机制,允许模型在不同的空间尺度上进行特征建模。这有助于网络适应不同尺度和分辨率的目标,提高对多尺度目标的感知能力。
GAM_Attention基于CBAM(Convolutional Block Attention Module)[10]结构,对其中的通道和空间两个子模块进行了改进。通过考虑通道、空间宽度和空间高度这三个维度之间的注意力权重提高模型检测的效率,同时加强跨维度的相互作用。GAM_Attention的结构、通道注意力子模块和空间注意力子模块结构图如下图所示。
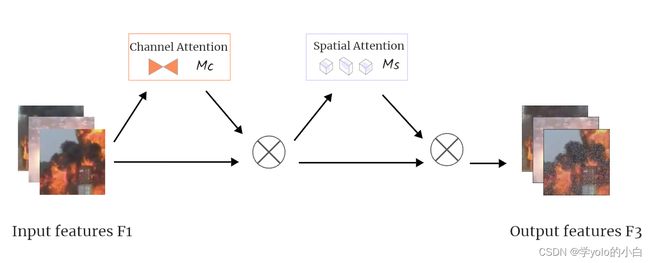 GAM_Attention的结构
GAM_Attention的结构
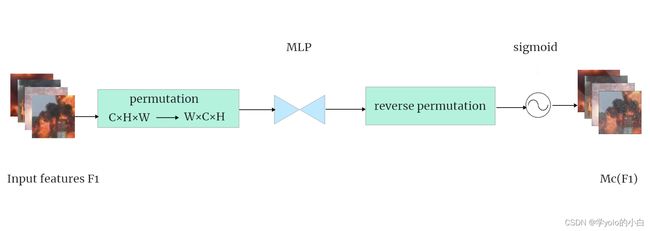 通道注意力子模块
通道注意力子模块
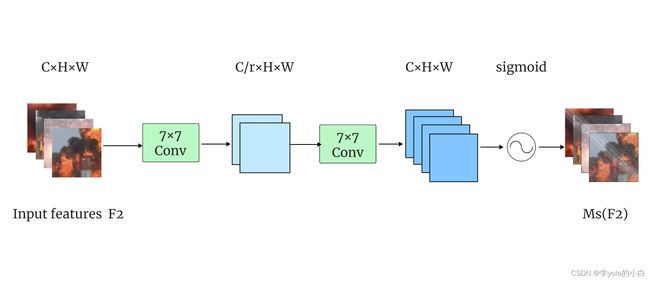 空间注意力子模块
空间注意力子模块
GAM_Attention的过程可由公式表示:

三、代码实现
1、在官方的yolov8包中ultralytics\ultralytics\nn\modules\__init__.py文件中的from .conv import和__all__中声明GAM模块。
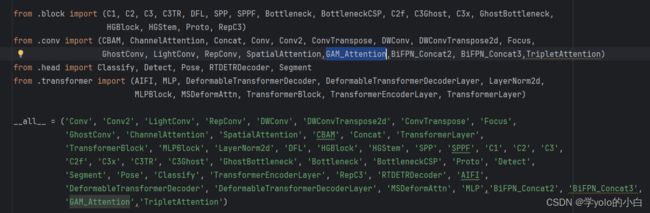
2、在ultralytics\ultralytics\nn\modules\conv.py文件中上边__all__中同样声明GAM模块。

并在该conv.py文件中添加GAM模块代码:
###### 添加GAM注意力机制 ########
class GAM_Attention(nn.Module):
def __init__(self, in_channels, c2, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(in_channels, int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(in_channels / rate), in_channels)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(int(in_channels / rate), in_channels, kernel_size=7, padding=3),
nn.BatchNorm2d(in_channels)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2).sigmoid()
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
out = x * x_spatial_att
return out
if __name__ == '__main__':
x = torch.randn(1, 64, 20, 20)
b, c, h, w = x.shape
net = GAM_Attention(in_channels=c)
y = net(x)
print(y.size())3、在 ultralytics\ultralytics\nn\tasks.py文件中开头声明GAM模块。

并在该文件 def parse_model模块中加入GAM结构代码:
elif m in {GAM_Attention}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not output
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]4、创建yolov8+GAM的yaml文件:
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8-SPPCSPC.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 3, GAM_Attention, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)5、运行验证:
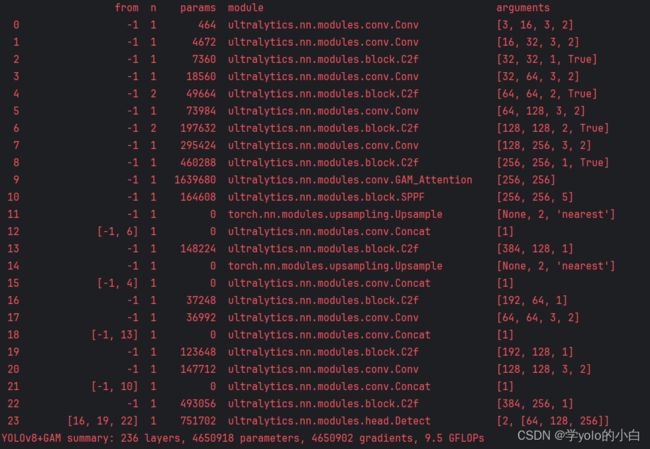
可以看出模型结构中已将包含GAM注意力机制。
四、精度对比
| Type | P(%) | R(%) | [email protected](%) | [email protected]:0.9(%) |
| YOLOv8n | 72.2 | 70.2 | 75.1 | 52.0 |
| YOLOv8n+GAM |
85.4 | 80.1 | 79.6 | 54.5 |
各个指标均涨点明显!