(附源码)python基于Echarts的城科就业数据可视化系统 毕业设计150915
Python城科就业数据可视化系统
摘 要
对于处理广泛的数据并整合到本地,Python爬虫有着自已强大的功能,面对城科就业数据可视化系统研究,我们考虑借助Python爬虫的功能对其实现相应的处理,本文将详细论述将Python爬虫应用在城科就业数据调取有效数据的过程。
本系统的前端界面涉及的技术主要有Django, HTML,jQuery等等,通过这些技术可以实现前端页面的美观和动态效果使之符合广大群众的审美观,后台主要使用的技术主要有Python编程语言,MySQL数据库,Ajax异步交互,根据Ajax异步模式的数据爬取,解决了传统管理数据分析所带来的人力、物力和时间上的虚耗和交流深度的限定,这让交流的过程更快捷、准确、便利,同时完成城科就业数据可视化系统的基本功能:历史指数数据、月幸福排名、年幸福排名、幸福领域调查、改善调查,数据分析等。
关键词:数据爬取;就业数据;Python编程语言;MySQL数据库
Python urban science employment data visualization system
Abstract
For processing a wide range of data and integrating them locally, python crawler has its own powerful functions. Facing the research of urban science employment data visualization system, we consider using the functions of Python crawler to realize the corresponding processing. This paper will discuss in detail the process of applying Python crawler to urban science employment data to obtain effective data.
The technologies involved in the front-end interface of the system mainly include Django, HTML, jQuery and so on. Through these technologies, the beauty and dynamic effect of the front-end page can be realized to make it conform to the aesthetics of the masses. The main technologies used in the background mainly include python programming language, MySQL database and Ajax asynchronous interaction. According to the data crawling of Ajax asynchronous mode, it solves the manpower and The waste of material resources and time and the limitation of communication depth make the communication process faster, accurate and convenient. At the same time, it completes the basic functions of the urban science employment data visualization system: historical index data, monthly happiness ranking, annual happiness ranking, happiness field investigation, improvement investigation, data analysis, etc.
Key words:Data crawling; Employment data; Python programming language; Mysql database
目 录
第1章 绪论 1
1.1 研究背景与意义 1
1.2 数据可视化的发展现状 1
1.3 论文组成结构 2
第2章 开发工具及相关技术介绍 3
2.1 Pycharm简介 3
2.2 MySQL描述 3
2.3 Python编程语言 3
2.4 Django框架 4
第3章 系统分析 5
3.1 可行性分析 5
3.1.1 技术可行性 5
3.1.2 经济可行性 5
3.1.3 操作可行性 6
3.2 需求分析 6
3.3 系统业务流程分析 10
3.4 系统数据流程分析 10
第4章 系统设计 12
4.1 系统架构设计 12
4.2 系统功能结构 13
4.3 功能模块设计 13
4.4 数据库设计 15
4.4.1 概念模型设计 15
4.4.2 逻辑结构设计 15
第5章 系统实现 19
5.1 登录模块的实现 19
5.2 用户子系统模块的实现 20
5.3 管理员子系统模块的实现 28
第6章 系统测试 34
6.1 测试目的 34
6.2 测试用例 34
6.3 测试结果 35
第7章 总结与展望 36
参考文献 37
致谢 39
绪论
研究背景与意义
随着大数据时代的到来,数据信息可视化的应用遍布各行各业。近年来,在经济下行的宏观形势下,就业工作面临着各种压力。就业问题是最大的民生问题,要坚持就业优先,实现更高质量就业。“一带一路"建设、京津冀协同发展、长江经济带发展等重大战略目标的推进,“中国制造2025"、"互联网+"等行动计划的提出,乡村振兴战略的构建等,必将释放出巨大的市场活力,给大学生就业带来新的增长空间。
毕业生的就业率和高质量就业是高校发展的重要指标之一,就业情况直接影响高校在社会中的认可度。挖掘毕业生就业中的各类信息数据,借助可视化技术手段,能有效直观地了解就业情况。企业对学校人才培养、教育教学的反馈意见,促进学校的专业设置改革,强化专业实践环节,不断创新就业指导服务,帮助学生树立正确的就业观念。本文尝试通过利用Python爬虫,定向抓取大学生就业数据调查相关网站中与就业信息相关的内容,对挖掘到的文本进行关键信息抽取、分类、归纳,得到相应统计分析结果,并且利用Python将爬取到的内容与相应人群的参数做出关联分析,设计并编写相应的系统。本程序具有数据采集速度快.、简单实用、针对性强等优点。
总的来说网络爬虫是指通过已有的既定规则,自动地抓取网页信息的计算机程序,既通过程序模拟浏览器请求站点的方式,把站点返回的HTML代码/JSON数据/二进制数据爬到本地,进而提取自己需要的数据。其目地在于将目标网页数.据批量性的下载至本地,便利在本地对文件的分析和利用。爬虫技术相应优势:爬虫技术的兴起源于网络数据的广泛分布以及其可用性,所以通过爬虫技术,我们能够较为容易的获取网络数据,并通过对数据的分析,得出有价值的结论。基于Python语言的简单和通俗易懂,加上使用时配合上正则表达式以及已存在的爬虫框架和工具包便利了开发者的操作,使得数据抓取变得简单有趣。
数据可视化的发展现状
随着现代科技的高速发展,信息社会已经悄然来临,这种大数据时代的来临,使人们积累的数据越来越多,而庞大的数据群必然有更多的无用数据,同时也在激增的数据背后隐藏着更多重要的信息。人们想要更好的利用这海量的数据,就需要对其进行更高层次的分析。当前的数据库系统能够高效的完成数据的录入、查询、统计等功能,却无法轻易发现数据中隐藏的关系和某些重要信息,无法实现利用现有的数据预测将来的发展趋势,缺少发觉数据暗藏的知识的技术,导致了“数据爆炸但信息匮乏”的现象。
我们人类是对图形极其敏感的生物。尽管很少有人能从一堆数字中看出趋向,但即便小孩子也能看懂条形图,并能从这些图形中理解数字的含意。因此,数据可视化已经成为了一种趋势,成为与人沟通的最便捷的形式。把数据变为生动的图表就可以帮我们从一个崭新的角度来看懂这个世界,揭示一些以前隐藏的形式和趋向信息。通过数据的可视化技术将海量数据中的不可靠数据划出,对数据进行有效的分析,发现数据信息中隐藏的联系,在信息社会占尽先机。
论文组成结构
根据市场调研得到的信息数据,结合国内外前沿研究,利用相关系统开发和设计方法,最终设计出城科就业数据可视化系统。
本文共有七章,如下所示。
第一章概述了城科就业数据可视化系统的研究目的和意义;精炼地总结了目前数据分析领域的研究情况和未来的研究趋势,最后给出了论文的组成结构。
第二章简要概述了本文所用的开发技术和工具。
第三章简要对系统各业务流程进行需求分析、可行性分析。
第四章对城科就业数据可视化系统进行设计。
第五章对城科就业数据可视化系统进行实现,并贴出相关页面截图,语言描述出具体功能实现的操作方法。
第六章对城科就业数据可视化系统采用测试用例的方式来对一些主要功能模块测试,最后得出测试结果。
第七章总结全文并对未来的研究做出展望。
开发工具及相关技术介绍
Pycharm简介
PyCharm是用于Python脚本语言的最流行的IDE。
1.每个文件都有其输出窗口。
2.可以终止进程(只要点下按钮就行)。
3.各种提示超强:①没用的变量颜色会变灰②用错了的变量下面会有红色波浪线③书写提示(sublime也有但较弱)。
4.索引功能超强。
MySQL描述
现在MySQL数据库在网络上它可以支撑许多个用户,而且也可以适应客服机和服务器的部署或者配置等,我们这里的服务器和客户机其实就是一种软件上的概念,并且我们使用的计算机硬件也与他们不存在一一对应的关系。
MySQL是一款非常流行的关系型数据库管理系统,它的出现一直都是佼佼者,它不仅功能非常强大,而且使用起来非常方便,并且MySQL的跨平台能力也很好,软件开发人员非常喜欢它的这些强大的优点。不同于其他关系型数据库,对于数据库的管理它有着自己的一套方案,通过对用户设定相应的权限和角色来达到对数据库的管理。由此可见,MySQL是一个能够适用于吞吐量高,可靠性高,效率高的一款数据库管理软件。
优点一:MySQL中对于不同身份的用户都设定其不同的权限来完成不同的业务逻辑,这使得MySQL在安全和完整性远远超出了其他关系型数据库。
优点二:对于那些动画、图形和声音的数据类型MySQL也可以支持,这说明多数据类型MySQL也是可以支持的。
优点三:MySQL还可以做到多个平台的开发,软件开发的多种编程语言都可以实现对MySQL数据库的操作。
Python编程语言
Python是一种开发语言,能够以直译的方式进行计算机语言,而且可以面向对象编程。它是由Guido van Rossum在十九世纪八十年代末研发出来,并且在九一年公开发行使用。Python有很多特点,比如有简洁的语法,清晰的语句,丰富的类库。正式由于这些优点,能够非常快速的和其他语言进行结合,来实现各种功能模块。很多人给它起了个外号叫“黏黏胶”语言。使用Python快速生成程序的原型,是现在很多程序员使用的方法。如果其中有比较特殊要求的地方,也非常方便的进行修改。
而且PyQt具有双证,为它能够跨平台运行(例如UNIX,微软和苹果的平台)提供了保证。
使用Python语言之前,要进行平台的安装,用户需要根据不同的平台,下载不同的版本,然后进行环境变量的配置,便可以进行运行。
Python 特点:
1.相对于其他计算机语言来说学习起来比较简单:Python的关键字较少,结构相对简单,语法简单,对于刚学编程语言的人来说更容易上手。
2.阅读起来也相对简单:Python代码结构简洁明了,并在定义上看起来也非常清晰,所以在阅读的过程中更加简单。
3.维护起来方便:Python的维护简单方便。
4.标准库特别广泛:Python的最大的最大优势是有非常多的库,而且是跨平台的,而且对系统的兼容性很好,比如在UNIX,Windows和Macintosh系统上都能够进行兼容。
5.具有方便的互动模式:有了互动模式的支持,开发者可以从代码就可以看到结果,这样开发者对程序的测试与调试,变的更方便。
6.可移植性好:Python可以跨平台运行。
7.扩展性非常好的:如果有关键的代码,你可以用特殊的语言进行编写,也能够在系统中调试运行。
Django框架
Django是一个由Python编写的具有完整架站能力的开源Web框架。使用Django,只要很少的代码,Python的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的Web服务。
Django本身基于MVC模型,即Model(模型)+View(视图)+ Controller(控制器)设计模式,因此天然具有MVC的出色基因:开发快捷、部署方便、可重用性高、维护成本低等。Python加Django是快速开发、设计、部署网站的最佳组合。
系统分析
可行性分析
在软件开发的过程中系统的可行性分析是必不可少的,可行性的研究就是评估问题是否能得到解决并且是要以最少的时间和最少的代价来解决。为实现上面的目标还要必须考虑到解决这些问题的方法的优点和缺点,还要考虑到实现了这些系统规模的开发带来的经济效益。这里可以用技术的可行性,操作的可行性,经济的可行性对我们的系统进行可行性的研究。城科就业数据可视化系统的可行性分析如下所示:
技术可行性
城科就业数据可视化系统采用的是Python编程语言并于Django框架,数据库部分采用的是当前流行的MySQL数据库,城科就业数据可视化系统中的所有数据资源都存储在MySQL数据库中,本系统多处采用了Ajax的异步操作,Ajax技术可以对用户指定部分的数据进行局部刷新,不仅减少了服务器对页面的解析而且极大增加了用户的体验度。本系统的环境配置也较为简单,因为用的是Pycharm编辑器,而Pycharm里面有自带的Tomcat服务器和Python环境,因此不需要我们在重新配置。
本系统采用Python、MySQL来支持事务和数据逻辑用H5来做前台页面的显示。
HTML网页中的不同组成成分是采用标签的形式来进行标识的。以下是HTML的基本的组成布局:
图3-1 HTML基本构成图
经济可行性
城科就业数据可视化系统是在Python和MySQL的环境中运行的,而系统的成本也只是主要分布在软件的开发和维护上。但如果系统上线投入使用之后,不仅可以方便人们,还节省了用户的时间和精力,而且还极大限度的方便了运营者,减少了运营者的工作强度。城科就业数据可视化系统其实也不太复杂,在开发的时候经济支出也不大,在开发系统时时间用的也不多,从时间的优势和对经济利益方面产生的好处远超过维护和管理的成本,所以开发此系统是可行合适的。
操作可行性
本系统是基于浏览器和服务器的城科就业数据可视化系统,系统开发完成之后用户只需要在浏览器中输入正确的URL地址即可进行访问。本系统的前台页面简单明了,在没有操作指导的情况下也可以进行操作,无论是系统管理员还是普通用户在页面中所有的操作都是在浏览器中完成的,因此只要电脑在有网络的情况下,打开浏览器都能操作。而且在使用之前也不用进行相关的环境配置,因此本系统方便、简单、易于使用,所以该系统是容易并且可操作的。
需求分析
根据用户对系统的需求,要求系统简单操作,能够准确,完整的对信息进行管理。城科就业数据可视化系统在对需求做解析后,整个系统主要分为两个部分:管理员和普通用户,每个模块下的分支功能不一样。对功能做出如下说明:
管理员用例图如下所示。
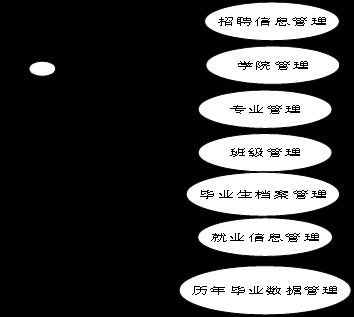
图3-1 管理员用例图
根据用例图,对一些重要的用例进行描述。
注册用例描述如下表所示。
表3-2 注册用例描述
用例名称 |
注册 |
参与者 |
用户 |
描述 |
用户填写相关注册数据完成注册成为系统的用户 |
前置条件 |
无 |
后置条件 |
用户填写相关注册数据并且要注册的账号不存在与系统中 |
事件流 |
|
补充说明 |
|
登录用例描述如下表所示。
表3-1 登录用例描述
用例名称 |
登录 |
参与者 |
用户 |
描述 |
用户填写用户名和密码登录系统 |
前置条件 |
用户拥有账号和密码 |
后置条件 |
用户名和密码都正确 |
事件流 |
(1)用户在登录页面输入用户名和密码 (2)系统检测用户输入的用户名和密码是否正确 (3)用户名和密码正确的话,显示登录成功并返回主页面 |
补充说明 |
(a)系统检查除密码不正确,返回登录页面 |
历年毕业数据管理用例描述如下表所示。
表3-1 历年毕业数据管理用例描述
用例名称 |
管理和修改历年毕业数据 |
参与者 |
用户 |
描述 |
用户查看、修改历年毕业数据 |
前置条件 |
用户已登录到系统中 |
后置条件 |
无 |
事件流 |
(1)用户查看历年毕业数据 (2)用户修改历年毕业数据 |
补充说明 |
(a)用户可修改统计 (b)用户可修改幸福程度调查统计资料 |
就业信息用例描述如下表所示。
表3-1 就业信息用例描述
用例名称 |
就业信息 |
参与者 |
用户 |
描述 |
用户发表就业信息 |
前置条件 |
用户已登录 |
后置条件 |
就业信息内容不违规 |
事件流 |
(1)在就业信息页输入就业信息数据,提交就业信息 (2)更新并显示就业信息板 |
补充说明 |
(a)就业信息内容不能为空 |
毕业生档案管理用例描述如下表所示。
表3-1 毕业生档案管理用例描述
用例名称 |
毕业生档案管理 |
参与者 |
用户 |
描述 |
用户发表毕业生档案管理 |
前置条件 |
用户已登录 |
后置条件 |
毕业生档案管理内容不违规 |
事件流 |
(1)在毕业生档案管理页输入毕业生档案管理数据,提交毕业生档案管理 (2)更新并显示毕业生档案管理板 |
补充说明 |
(a)毕业生档案管理内容不能为空 |
招聘信息用例描述如下表所示。
表3-1 招聘信息用例描述
用例名称 |
招聘信息 |
参与者 |
用户 |
描述 |
用户查询招聘信息操作 |
前置条件 |
用户已登录 |
后置条件 |
该数据存在,并且能进行招聘信息添加 |
事件流 |
(1)在页点击要发布的信息 (2)填写招聘信息表单 |
补充说明 |
(a)招聘信息表单数据不能为空 |
专业用例描述如下表所示。
表3-1 专业用例描述
用例名称 |
专业管理 |
参与者 |
用户 |
描述 |
用户提供新增、修改、删除、查阅等功能 |
前置条件 |
|
后置条件 |
无 |
事件流 |
(1)用户查看修改专业 (2)用户添加专业 (3)用户删除专业 |
补充说明 |
(a)新添加的专业不符合要求时会添加失败 (b)修改的专业不符合要求时会修改失败 |
班级管理用例描述如下表所示。
表3-1 班级管理用例描述
用例名称 |
班级管理 |
参与者 |
用户 |
描述 |
用户提供新增、修改、删除、查找等功能 |
前置条件 |
|
后置条件 |
无 |
事件流 |
(1)用户查看修改班级管理 (2)用户添加班级管理 (3)用户删除班级管理 |
补充说明 |
(a)新添加的班级管理不符合要求时会添加失败 (b)修改的班级管理不符合要求时会修改失败 |
系统业务流程分析
管理员拥有最高权限,在对各项信息进行增加、删除、修改后会更新后台数据库的内容,管理员在登录后进行用户管理、专业管理、班级管理、毕业生档案管理、招聘信息管理、历年就业数据管理等指令动作同样会更新后台数据。
系统数据流程分析
与强调控制逻辑的程序流程图不同,它更关心的是整个系统中数据的具体流动以及数据的加工处理的整个客观过程,是对数据规格的说明。也正因如此,系统数据流图作为系统结构化分析方法中极为重要的一种描述工具备受青睐。
城科就业数据可视化系统的顶层数据流如下图所示。

图3-4系统顶层数据流图
系统顶层数据流:外部实体为用户,第一个流程为登录验证,用户信息表返回密码验证,是否正确,正确则登录系统,错误则反馈信息,登录系统后,根据不同用户的功能选择,来读写数据库。
系统底层数据流如下图所示。
图3-5系统底层数据流图
系统底层数据流:外部实体为管理员和普通用户,数据流分别有管理员和普通用户流向系统数据流程,数据表提供数据支持,来完成逻辑操作。
系统设计
系统架构设计
由于本系统在逻辑事务处理方面对数据库的操作比较频繁所以系统在底层连接数据库封装之后相当于一个连接数据库的工具DB UTIL,这样使用起来会更加方便而且这样进行封装还可以降低系统中代码的冗余,当我们需要连接和使用数据库时只需要调用这个工具里面的一个方法就可以了。而且通过封装可以把对数据库的操作独立起来,当需要连接不同种类的数据库时只需要加以修改就可以达到目的。
DAO层本来并无这个类,它只是Python中MVC构造里的一个model概念,主要就是里面的一些方法,而这些方法就是用来访问数据库的方法。我们在软件开发时DAO层我们一般都放接口和接口的实现类,用于来规范实现类的我们叫它接口,实现类重点用于对数据库的操纵。
MVC是一种系统研发的关键模型,M是Model模型,它是系统内部关键程序运行的核心,主要进行对数据库的各种操作。视图View是V也叫做视图,主要的作用是对一些数据进行显示。控制器Controller 是C执行从View的视图层来读取数据,然后控制用户的输入。
系统架构如下图所示。

图4-1系统架构图
系统功能结构
进入系统后首先要进行登录,验证你的身份,赋予你不同的权限。当你成功登录后,页面会有多个板块,分别是用户信息、专业管理、班级管理、就业信息管理、招聘信息管理、历年毕业数据管理。里面界面简单易懂,根据标示可以直接进行方便快捷的操作。
系统功能结构图如下所示。
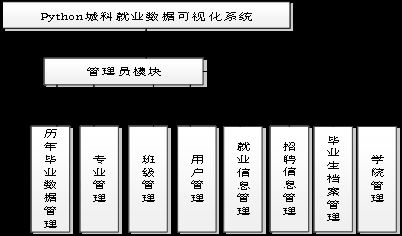
图4-2系统功能结构图
功能模块设计
管理员账户的基本信息管理。主要提供管理员账户的基本信息录入、删除、维护和查询等功能,包括:
管理员录入管理员账户基本信息;
管理员更新、增加及删除管理员账户基本信息;
系统管理员更改个人密码;
历年毕业数据管理。主要历年毕业数据信息录入、修改和查询功能,包括:
用户进行信息录入、年份、毕业人数、专业、就业人数等;
管理员更新、增加及删除历年毕业数据信息;
毕业生档案管理。主要提供毕业生档案录入、修改和查询功能,包括:
用户浏览学生信息、学院名称、专业、班级、入学时间、毕业时间等;
管理员更新、增加及删除毕业生档案;
管理员根据毕业生档案 ID 查询毕业生档案;
就业信息管理。主要提供改善调查的基本信息录入、删除、维护和查询功能,包括:
管理员录入就业信息;
管理员更新、增加改善调查;
管理员根据就业信息 ID 查询信息;
招聘信息的管理。主要提供招聘信息录入、删除、维护和查询功能,包括:
管理员录入招聘信息;
管理员更新、增加招聘信息;
管理员根据招聘信息ID 查询信息;
数据库设计
一个好的系统它的后台数据库一定要考虑的全面,这和我们建造房子一个概念,房子不是随心所欲建起来的,一切都是在合理设计的基础是实现的,地基打牢固了房子才能建的更高。数据库如果设计的很合理,而且每个方面都能考虑到了那么这个系统才能不会出现大的问题。
概念模型设计
系统的主要实体间关系E-R图如下图所示。
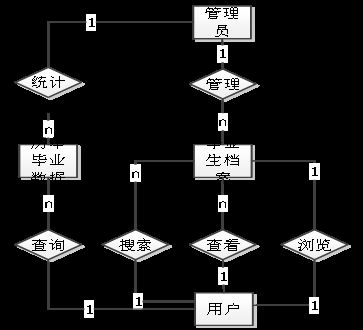
图4-3系统E-R图
逻辑结构设计
此环节把概念转变成数据。由于整个数据库所处理的信息过多,就只展示几个表。
student表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
student_id |
int |
11 |
是 |
是 |
学生ID |
gender |
varchar |
64 |
否 |
否 |
性别 |
examine_state |
varchar |
16 |
是 |
否 |
审核状态 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
user_id |
int |
11 |
是 |
否 |
用户ID |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
class_management表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
class_management_id |
int |
11 |
是 |
是 |
班级管理ID |
class_name |
varchar |
64 |
否 |
否 |
班级名称 |
class_type |
varchar |
64 |
否 |
否 |
班级类型 |
class_size |
int |
11 |
否 |
否 |
班级人数 |
college_name |
varchar |
64 |
否 |
否 |
学院名称 |
professional_name |
varchar |
64 |
否 |
否 |
专业名称 |
class_profile |
text |
0 |
否 |
否 |
班级简介 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
college_leaders表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
college_leaders_id |
int |
11 |
是 |
是 |
学院领导ID |
gender |
varchar |
64 |
否 |
否 |
性别 |
examine_state |
varchar |
16 |
是 |
否 |
审核状态 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
user_id |
int |
11 |
是 |
否 |
用户ID |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
college_management表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
college_management_id |
int |
11 |
是 |
是 |
学院管理ID |
college_number |
varchar |
64 |
否 |
否 |
学院编号 |
college_type |
varchar |
64 |
否 |
否 |
学院类型 |
college_name |
varchar |
64 |
否 |
否 |
学院名称 |
number_of_colleges |
int |
11 |
否 |
否 |
学院人数 |
college_profile |
text |
0 |
否 |
否 |
学院简介 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
graduate_files表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
graduate_files_id |
int |
11 |
是 |
是 |
毕业生档案ID |
full_name |
varchar |
64 |
否 |
否 |
姓名 |
gender |
varchar |
64 |
否 |
否 |
性别 |
age |
varchar |
64 |
否 |
否 |
年龄 |
id |
varchar |
64 |
否 |
否 |
身份证 |
college_name |
varchar |
64 |
否 |
否 |
学院名称 |
professional_name |
varchar |
64 |
否 |
否 |
专业名称 |
class_name |
varchar |
64 |
否 |
否 |
班级名称 |
admission_time |
date |
0 |
否 |
否 |
入学时间 |
graduation_time |
date |
0 |
否 |
否 |
毕业时间 |
student |
int |
11 |
否 |
否 |
学生 |
graduation_information |
varchar |
255 |
否 |
否 |
毕业信息 |
instructor |
int |
11 |
否 |
否 |
辅导员 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
graduation_data_over_the_years表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
graduation_data_over_the_years_id |
int |
11 |
是 |
是 |
历年毕业数据ID |
particular_year |
varchar |
64 |
否 |
否 |
年份 |
professional_name |
varchar |
64 |
否 |
否 |
专业名称 |
number_of_graduates |
int |
11 |
否 |
否 |
毕业人数 |
employment |
int |
11 |
否 |
否 |
就业人数 |
remarks |
text |
0 |
否 |
否 |
备注 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
professional_managemen表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
professional_management_id |
int |
11 |
是 |
是 |
专业管理ID |
discipline_number |
varchar |
64 |
否 |
否 |
专业编号 |
professional_type |
varchar |
64 |
否 |
否 |
专业类型 |
professional_name |
varchar |
64 |
否 |
否 |
专业名称 |
number_of_professionals |
int |
11 |
否 |
否 |
专业人数 |
college_name |
varchar |
64 |
否 |
否 |
学院名称 |
professional_profile |
text |
0 |
否 |
否 |
专业简介 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
recruitment_information表:
名称 |
类型 |
长度 |
不是null |
主键 |
注释 |
recruitment_information_id |
int |
11 |
是 |
是 |
招聘信息ID |
recruitment_no |
varchar |
64 |
否 |
否 |
招聘编号 |
recruitment_company |
varchar |
64 |
否 |
否 |
招聘公司 |
recruitment_type |
varchar |
64 |
否 |
否 |
招聘类型 |
recruitment_position |
varchar |
64 |
否 |
否 |
招聘职位 |
educational_requirements |
varchar |
64 |
否 |
否 |
学历要求 |
work_experience_requirements |
varchar |
64 |
否 |
否 |
工作经验要求 |
capability_requirements |
varchar |
64 |
否 |
否 |
能力要求 |
number_of_recruits |
varchar |
64 |
否 |
否 |
招聘人数 |
recruitment_cover |
varchar |
255 |
否 |
否 |
招聘封面 |
salary_range_ |
varchar |
64 |
否 |
否 |
薪资范围 |
employment_division |
int |
11 |
否 |
否 |
就业处 |
recruitment_content |
text |
0 |
否 |
否 |
招聘内容 |
company_profile |
text |
0 |
否 |
否 |
公司简介 |
hits |
int |
11 |
是 |
否 |
点击数 |
recommend |
int |
11 |
是 |
否 |
智能推荐 |
create_time |
datetime |
0 |
是 |
否 |
创建时间 |
update_time |
timestamp |
0 |
是 |
否 |
更新时间 |
系统实现
登录模块的实现
该登录模块利用JS进行设计,PythonScript函数CheckSubmit()对输入框是否为空进行验证,使用JS的技术结合MySQL5.7数据库的查询语句进行登录信息的验证。首先从文本框中分别获得账号user_name和密码user_pw,使用Sql语句“select * from t_user where user_name=‘”+user_name+“’ and user_pw=‘”+user_pw+“’”将查询结果赋给rs结果集,若rs.next()返回值为空,表示数据库找不到该用户数据,若rs.next()返回值不为空,则显示登录成功,进入主界面。
用户登录流程图如下所示。

图5-1用户登录流程
用户登录流程:用户只有输入正确的用户名和密码才会成功进入系统,用户输入用户名密码后点击登录按钮,系统会进行校验该用户名是否存在,如果用户名与密码不匹配或者用户名不存在,则返回主界面。
系统登录界面如下图所示。
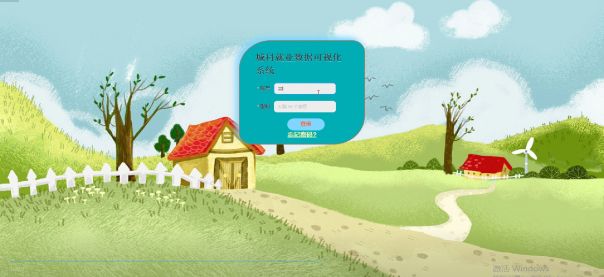
图5-2系统登录界面
用户子系统模块的实现
用户首页模块
在浏览器的地址栏里输入http://localhost:8080/index.html 地址,就可以跳转到酒店信息预览及在线预订系统的首页,首页是由4个页面组成的,包括top、left、down和center等页面,这里也是浏览者访问系统的入口,通过@ include引入。
首页载入流程图如下所示。

图5-3首页载入流程
首页载入流程:系统先连接数据库,显示界面参数初始化,读取数据库的数据表,读取html显示模板,对数据按添加时间排序,按照模板设计位置显示数据,刷新显示界面,断开数据库连接。
首页如下图所示。
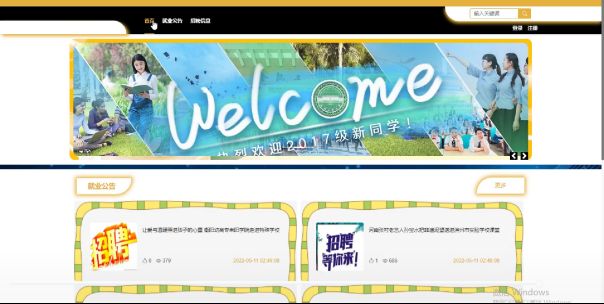
图5-4首页界面
用户注册模块
系统的用户通过自行注册生成,在系统首页点击用户注册菜单,系统跳转到对应的注册页面。点击重置按钮,清空所填数据,点击注册按钮完成注册。
用户注册流程图如下所示。

图5-5用户注册流程
注册个人信息实现流程为:填写个人信息,系统使用JQuery选择器获取在网页中输入的注册信息,再对联系方式、登录密码等信息进行验证,验证通过后用Ajax异步请求方式向服务器发送请求并把数据传送到后台,然后验证用户名是否已存在,如果已存在则注册失败提示“用户名已存在”;如果用户表中没有该用户名则把用户信息加入数据库,把操作状态以JSon字符串方式返回到前台。Ajax请求成功接收到返回的数据时会触发成功回调函数,然后解析返回的JSon字符串,系统根据返回信息弹出提示框,注册成功后返回登录页。
招聘信息模块
用户点击查看招聘信息指令,后台会自动生成招聘信息列表。从session中取出该招聘信息,前台发起请求,将对应的招聘信息、xindepId参数信息从前台传递XindeController类里,匹配到create()方法,create()方法调用XindeServiceImpl类的createXinde()方法获取数据,调用本类的getCartXindeItem()方法得到招聘信息列表。
招聘信息界面如下所示。
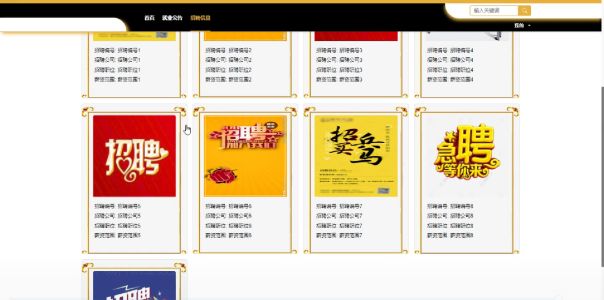
图5-6招聘信息界面
就业公告模块
管理员发布就业信息后,就业公告在系统前台显示,用户浏览就业公告,选择相应的就业公告,通过id传参,找到该公告信息。
就业公告流程如下图所示。

图5-7就业公告流程
就业公告界面如下图所示。
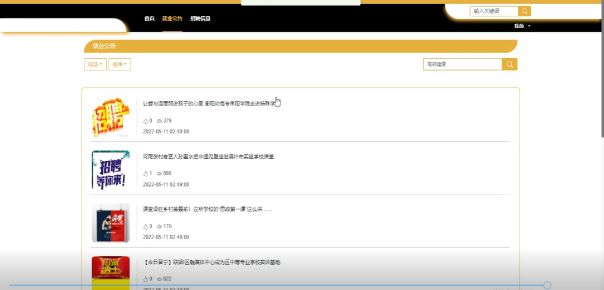
图5-8就业公告界面
管理员子系统模块的实现
历年毕业数据管理模块
历年毕业数据管理如下图所示。
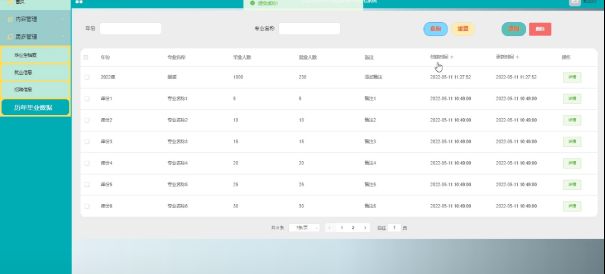
图5-9历年毕业数据管理界面
就业信息管理模块
就业信息管理包括新增就业信息、删除就业信息、修改就业信息、查询就业信息等,以就业信息新增为例,在视图层请求就业信息新增,反馈后,调用业务逻辑层,通过业务逻辑层的接口调用底层的数据逻辑层完成数据库联动操作。
就业信息管理的流程如所示。
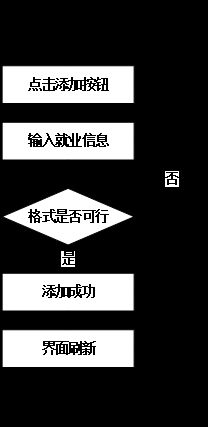
图5-10就业信息管理流程
就业信息添加的界面如所示。
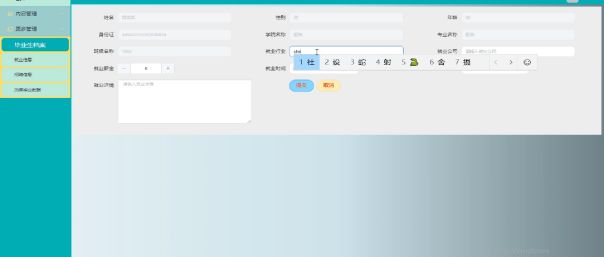
图5-11就业信息添加界面
就业信息管理的界面如所示。
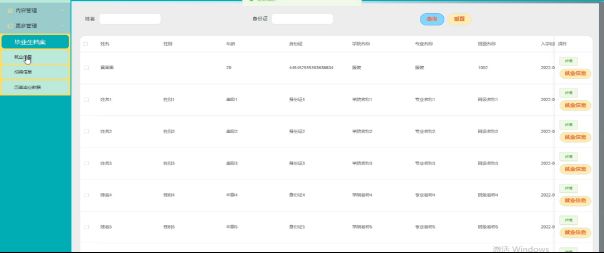
图5-12就业信息管理界面
系统测试
测试目的
在这个产品被投入使用前,首先需要进行试用,这是重要的环节。考虑到某个部分的开发没有缺陷情况下,把各种模块拼接,也有一定概率就存在矛盾。这就好比每个人都很独特,但聚在一起就显得杂乱无章,需要保证有默契的配合。对于测试,要看它的各项内容是否契合的原则。若与最初定下的标准有一定程度上的出入,那么就需要做出一些调整,让最终的大方向朝着目标前进。
测试用例
登录测试
登录测试用例如下表所示。
表6-1登录测试用例
输入 |
输出 |
|
用户名 |
密码 |
|
空 |
空 |
用户名或密码不能为空 |
蔡徐坤 |
123 |
用户名不能为汉字,请重新输入 |
789 |
789 |
用户名或密码错误 |
678 |
123456 |
登录成功 |
注册测试
注册测试用例如下表所示。
表6-2注册测试用例
输入 |
输出 |
|||
用户名 |
密码 |
确认密码 |
邮箱 |
|
空 |
空 |
空 |
空 |
请输入完整 |
001 |
001 |
001 |
注册成功 |
|
002 |
002 |
003 |
注册失败,两次密码不一致 |
|
003 |
003 |
003 |
003.com |
注册失败,邮箱格式不正确 |
历年毕业数据测试
历年毕业数据测试用例如下表所示。
表6-3历年毕业数据测试用例
功能 |
测试数据 |
预期结果 |
测试结果 |
历年毕业数据反馈 |
历年毕业数据内容: |
在历年毕业数据列表中显示历年毕业数据内容,历年毕业数据显示为未发布 |
和预期一致 |
发布历年毕业数据 |
历年毕业数据发布内容 |
历年毕业数据列表中的历年毕业数据显示已发布 |
和预期一致 |
删除历年毕业数据 |
删除历年毕业数据 |
历年毕业数据成功删除 |
和预期一致 |
招聘信息管理测试
招聘信息测试用例如下表所示。
表6-4添加招聘信息测试用例
输入 |
输出 |
|||
城市 |
公司规模 |
新资 |
备注 |
|
空 |
空 |
空 |
空 |
添加失败 |
招聘信息1 |
A |
1 |
|
添加成功 |
空 |
A |
1 |
|
添加失败,城市不能为空 |
招聘信息2 |
空 |
1 |
|
添加失败,请选择公司规模 |
测试结果
经过测试,得到测试结果如下表所示。
表6-6测试结果
测试项目 |
内容和目的 |
测试结果 |
用户登录 |
输入正确用户名与密码 |
可以登录 |
输入错误用户名与密码 |
提示错误的信息 |
|
历年毕业数据管理(添加,修改,删除) |
输入正确信息 |
成功完成 |
输入错误信息 |
操作失败 |
|
修改登录密码 |
修改新的密码 |
成功完成 |
就业管理(添加,修改,删除) |
输入正确信息 |
成功完成 |
输入错误信息 |
操作失败 |
|
招聘信息管理(添加,修改,删除) |
输入正确信息 |
成功完成 |
输入错误信息 |
操作失败 |
|
用户管理(添加,修改,删除) |
输入正确信息 |
成功完成 |
输入错误信息 |
操作失败 |
|
毕业生档案管理(添加,修改,删除) |
输入正确信息 |
成功完成 |
输入错误信息 |
操作失败 |
总结与展望
本次毕业论文的主要是利用Python+MySQL开发一个安全可靠,操作简易,同时具备业务可扩展的城科就业数据可视化系统。本文详细的论述了城科就业数据可视化系统的设计和开发,本系统的所有事务逻辑都是按照系统的需求分析进行设计的,系统有普通用户和系统管理员两种角色,本系统多处采用了Ajax的异步交互技术,同时它也叫异步交互技术,利用它我们可以让网页的局部进行数据刷新操作,Ajax和传统的数据更新技术大大增加了客户的体验程度,由于是对局部进行操作那么就减少了一些繁琐而又不必要的操作,减轻了服务器对页面解析的负担。
与其他系统相比,本系统有自身的优点,
例如:
(1)创新性强;
(2)业务逻辑性强,安全性高,在一些重要的功能模块需要通过审查之后才可使用;
(3)移植性高,在所有Window平台都可使用。
当然也还有很多需要进一步改进的地方:
(1)系统大多数页面都是全局刷新,缺乏局部刷新,这将增加服务器的压力,如果有大量用户在同一时间段操作同一个功能模块,可能会导致查询缓慢;
(2)页面没有经过专业的UI设计,美观程度不及其他市场其他网站系统,有待改善。
参考文献
[1]罗尧成,周蜜.高职院校毕业生就业问题与对策建议——基于L市2015—2019年毕业生就业数据的分析[J].教育探索,2021(08):58-61.
[2]孙丽.基于大数据的高职学生就业数据可视化分析[J].信息与电脑(理论版),2020,32(23):12-13.
[3]林慧君.高职高专物流管理专业学生就业数据可视化分析[J].科教导刊(上旬刊),2020(04):188-192.DOI:10.16400/j.cnki.kjdks.2020.02.086.
[4]项博良,唐淳淳,钱前,曹健东.基于网络爬虫的就业数据分析[J].智能计算机与应用,2020,10(01):223-226+230.
[5]王立彦.新常态下高校毕业生就业统计工作的浅析与思考[J].科技视界,2019(36):225-226.DOI:10.19694/j.cnki.issn2095-2457.2019.36.105.
[6]刘俊灼. 基于决策树算法的高校就业数据分析[D].景德镇陶瓷大学,2019.DOI:10.27191/d.cnki.gjdtc.2019.000121.
[7]刘娜. 基于数据分析的高校教学管理决策支持方法研究[D].浙江大学,2019.
[8]匡思莉.高校毕业生就业数据统计机制改进研究[J].高考,2019(01):7+11.
[9]孔令海.基于就业数据分析的人才分类培养策略研究——以吉林工程技术师范学院数学与应用数学专业为例[J].吉林工程技术师范学院学报,2018,34(02):63-65.
[10]周利华.学生就业数据可视化分析与设计——以深圳职业技术学院市场营销专业为例[J].教育信息技术,2018(Z1):25-27.
[11]汤迪娟.高校就业数据统计的现状与对策[J].统计与管理,2018(08):141-142.DOI:10.16722/j.issn.1674-537X.2018.08.051.
[12]张宝强.如何改进高校毕业生就业统计工作[J].高教发展与评估,2018,33(02):17-23+106-107.
[13]孙倩.高校毕业生就业市场化与就业统计机制构建[J].太原城市职业技术学院学报,2018(05):56-57.DOI:10.16227/j.cnki.tycs.2018.0390.
[14]郭军军,刘刚.毕业生就业数据网上直报与统计系统分析及实现[J].计算机时代,2018(02):29-30+33.
[15]张向伟.Python数据分析中的数据整理探讨[J].电子世界,2021(11):57-58.
[16]Do clinical and paraclinical findings have the power to predict critical conditions of injured patients after traumatic injury resuscitation? Using data mining artificial intelligence[J].中华创伤杂志英文版,2021,24(01):48-52.
[17]王宁宁.基于ARIMA模型数据的分析与预测[J].智能计算机与应用,2020,10(05):240-243+247.
[18]Hailun Liang,Lei Yang,Lei Tao,Leiyu Shi,Wuyang Yang,Jiawei Bai,Da Zheng,Ning Wang,Jiafu Ji.Data mining-based model and risk prediction of colorectal cancer by using secondary health data: A systematic review[J].Chinese Journal of Cancer Research,2020,32(02):242-251.
致谢
经过几个月时间的努力终于完成了这篇文章,在文章的写作与研究的过程中遇到了很多困难,都在同学和老师的帮助下解决了。尤其非常感谢我最敬爱的老师,他对我进行了无私的指导和帮助,不厌其烦的帮助进行文章的修改。老师严谨的治学态度、渊博的学术知识、诲人不倦的敬业精神以及宽容的待人风范使我获益颇丰。此外,在校图书馆查找资料的时候,图书馆的老师也给我提供了很多方面的支持与帮助。在此,向帮助和指导过我的老师表示最衷心的感谢!感谢这篇文章所涉及到的各位学者。本文引用了数位学者的文献,如果没有各位学者的研究成果的帮助和启发,我将很难完成本篇文章的写作。感谢我的同学、朋友以及所在单位的同事,在我写文章的过程中给与了我很多素材和帮助,还在文章的撰写和排版过程中提供热情的帮助。同时,感谢我的室友对我的热心指导和帮助,经常有不懂之处都是大家在帮助我,才使得我比较顺利的完成了这篇文章。由于我水平有限,所写文章难免有不足之处,恳请各位老师和学友批评和指正!
免费领取项目源码,请关注点赞+私聊