oracle latch chain,Cache Buffer Chain Latch等待事件
产生的背景:
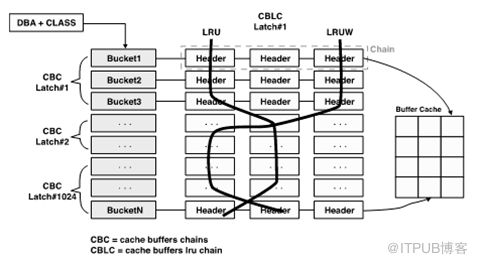
Oracle为了将物理IO最小化,把最近使用过的数据块保持在内存中。为了管理这些内存,oracle使用如图的结构,
Hash Chain的结构,Hash Chain位于共享池中,使用典型内存结构Bucket->Chain->Header结构进行管理。
Hash Chain结构的起点是Hash表,Hash表由多个hash bucket组成,块地址 是由file#+block#组成的,当扫描块时使用Hash函数
进行hash运算,使用hash值查找hash bucket,具有相同hash值的bufferhaeder在hash bucket上以chain形式链接。
Buffer header有指向实际缓冲区的指针。注意:Hash Chain结构是在共享池中,而实际缓冲区信息存储在高速缓冲区中。
Hash Chain结构利用cachebuffers chainLatch来保护。
当进程扫描特定的数据块时,必须获得相应数据块所在Hash Chain管理的cachebuffers chainLatch。基本上
一个进程获得仅有的一个cachebuffers chainLatch,一个cachebuffers chainLatch管理多个Hash Chain。
当多个进程同时检索Buffer Cache时,获得cachebuffers chainLatch的过程中发生争用,就会产生
cachebuffers chainLatch等待事件。
进程扫描特定的数据块整个过程。
1、Oracle以每个块的文件号、块号和类型做HASH运算,得到HASH值。根据HASH值,到HASH表中取出指定块的内存地址
2、获取CBC Latch
3、根据HASH值,搜索CBC链表
4、根据DBA找到BH(Buffer Header)加Buffer Pin
5、加完Buffer Pin马上释放CBC Latch
6、访问Buffer开始fetch数据
7、获取CBC Latch
8、释放Buffer Pin
9、释放CBC Latch
使用SQL语句可以获得hash_latches,hash_buckets数量,因此一个锁存器保护Bucket数量是1048576/32768=32个。
SQL> selectx.ksppinmname,
2y.ksppstvlvalue,
3y.ksppstdfisdefault,
4decode(bitand(y.ksppstvf, 7),
51,
6'MODIFIED',
74,
'SYSTEM_MOD',8
9'FALSE')ismod,
10decode(bitand(y.ksppstvf, 2), 2, 'TRUE', 'FALSE')isadj
11fromsys.x$ksppix,sys.x$ksppcvy
12wherex.inst_id=userenv('Instance')
13andy.inst_id=userenv('Instance')
14andx.indx=y.indx
15andx.ksppinmlike '%db_block_hash%'
16order by translate(x.ksppinm, ' _', ' ');
NAMEVALUEISDEFAUL ISMODISADJ
--------------------------------------------- --------------- -------- -------- --------
_db_block_hash_buckets1048576TRUEFALSEFALSE
_db_block_hash_latches32768TRUEFALSEFALSE
产生的原因:
1.执行效率低下的SQL,低效的SQL语句是发生Latch:cachebuffers chains争用的主要原因。发生在多个进程同时扫描大范围的表或索引时。
2.出现热块hot block时,由于编写SQL语句时,SQL持续扫描少数特定块(between and ,in,notin, exists),多个会话同时执行SQL语句时,发生Latch:cachebuffers chains争用。
【案例1 Latch:cachebuffers chains争用】
--1.创建测试表create table t1(id int,name varchar2(10));
insert into values(1,'xiaobo');
commit;
--2.获取t1表的第一行数据及ROWID,根据dbms_rowid包查出这行数据的文件号、块号
SQL> select rowid,
dbms_rowid.rowid_relative_fno(rowid) file#,
dbms_rowid.rowid_block_number(rowid) block#,
id,
name
from emm.t1
where rownum = 1; 2 3 4 5 6 7
ROWID FILE# BLOCK# ID NAME
------------------ ---------- ---------- ---------- --------------------
AAADfaAAFAAAACDAAA 5 131 1 xiaobo
注意:这里的DBA(Data Block Address)就是由5号文件和131号块组成
--3.根据DBA获取CBC Latch的地址
SQL> select hladdr from x$bh where file#=5 and dbablk=131;
HLADDR
----------------
00000001D1C266D8
--4.根据CBC Latch的地址可以查出这个CBC Latch被获得的次数
SQL> select addr,name,gets from v$latch_children where addr='00000001D1C266D8';
ADDR NAME GETS
---------------- -------------------------------- -----------------------------------------------
00000001D1C266D8 cache buffers chains 46
--5.再次读取t1表的第一行数据,再次产生一次逻辑读
SQL>select id,name from emm.t1 where rowid='AAADfaAAFAAAACDAAA';
ID NAME
-------- ------------
1 xiaobo
--6.CBC Latch的次数变为48,说明一次逻辑读产生两次CBC Latch
SQL> select addr,name,gets from v$latch_children where addr='00000001D1C266D8';
ADDR NAME GETS
---------------- -------------------------------- -----------------------------------------------
00000001D1C266D8 cache buffers chains 48
这里说明一次逻辑读要加两次CBC Latch,一次为了加Buffer Pin,一次为了释放Buffer Pin!
但是我不知道这里如何通过实验来证明,大家如果有好的建议,可以联系我。
使用oradebug跟踪CBC Latch争用事件
SQL> oradebug setmypid
Statement processed.
SQL> oradebug peek 0x1D1C266D8 4 -- 观察CBC Latch地址为0x1D1C266D8开始之后的4字节信息的值为0
[1D1C266D8, 1D1C266DC) = 00000000
SQL> oradebug poke 0x1D1C266D8 4 1 --修改CBC Latch地址为0x1D1C266D8开始的4字节信息的值为1,相当于获取了Latch
BEFORE: [1D1C266D8, 1D1C266DC) = 00000000 --修改前的值
AFTER: [1D1C266D8, 1D1C266DC) = 00000001 --修改后的值
--7. 再开一个新的会话,会话号为768
SQL> conn / as sysdba
Connected.
SQL> select sid from v$mystat where rownum=1;
SID
----------
768
--8.在新会话768下再查询T1表的第一行,我观察到不会堵塞。但是我看网上有些网友写的博客说这里会产生堵塞。
这样的说法是不正确的。原因我会做完下个实验给大家解释,这里多说一句,大家看到网上的一些技术文章,一定
要自己动手做实验。如果发现和文章说明的不一样,一定要查阅资料。一直到搞清楚。
SQL>select id,name from emm.t1 where rowid='AAADfaAAFAAAACDAAA';
ID NAME
-------- ------------
1 xiaobo
--9.我们回到oradebug的会话,这次我们不是使用select语句,而使用update语句来获取latch
SQL> update emm.t1 set id=2 where rowid='AAADfaAAFAAAACDAAA';
1 row updated.
--10.再次使用oradebug模拟获取latch
SQL> oradebug setmypid
Statement processed.
SQL> oradebug poke 0x1D1C266D8 4 1
BEFORE: [1D1C266D8, 1D1C266DC) = 00000000
AFTER: [1D1C266D8, 1D1C266DC) = 00000001
--11.回到刚才768会话下,查询T1表的第一行,这时我观察到产生了堵塞
SQL>select id,name from emm.t1 where rowid='AAADfaAAFAAAACDAAA';
--12.我们再开第三个会话,查看会话号768的等待事件,我们看到产生了CBC Latch的等待事件
SQL> select sid,event,p1raw,p2raw,p3raw from v$session where sid=768;
SID EVENT P1RAW P2RAW P3RAW
---------------- ------------------------------------- ------------------------- --------------------------- -------
768 latch: cache buffers chains 00000001D1C266D8 00000000000000B1 00
最后在第一个会话中释放lacth
SQL> oradebug poke 0x1D1C266D8 4 0
BEFORE: [1D1C266D8, 1D1C266DC) = 00000001
AFTER: [1D1C266D8, 1D1C266DC) = 00000000
总结:
在获取保护hash bucket的cache buffers chains latch时,如果是读取工作(select),就以shared模式获
得(这也是我们刚才在实验中select时没有产生争用的原因)。如果是修改工作(update),就以exclusive模式
获得。