【Linux】理解文件系统
需要云服务器等云产品来学习Linux的同学可以移步/–>腾讯云<–/官网,轻量型云服务器低至112元/年,优惠多多。(联系我有折扣哦)
文章目录
- 1. 了解磁盘
-
- 1.1 磁盘的物理结构
- 1.2 磁盘的逻辑结构
- 1.3 磁盘的存储结构
- 2. 文件系统
-
- 2.1 磁盘的组织方式
- 2.2 inode的概念
- 2.3 文件的访问方式
在上一节中,我们了解了被打开的文件是怎么被管理的,怎么被使用的,怎么和进程联系起来的…这些东西都是对被打开的文件的管理。但是除了这些被打开的文件之外,还有非常多的没有被打开的文件,静悄悄的躺在磁盘上。那么这些文件也是需要被管理起来的,接下来我们来了解一下这些没有被打开的文件是怎么管理起来的。
1. 了解磁盘
我们知道,没有被打开的文件是存放在磁盘上的,所以,要了解未被打开的文件是怎么被管理的就首先要了解磁盘的结构,包括物理结构、逻辑结构和存储结构。这里以机械硬盘为例,来了解一下磁盘的结构。
1.1 磁盘的物理结构

磁盘由一系列的物理结构组合而成,其中最重要的部分就是磁头、盘面。数据是存放在盘面上的,通过磁头来将数据读取或者写入。
1、磁盘中每个盘片的每一面都配有一个磁头,且磁头和盘面是没有接触的,二者的距离非常非常低,而一旦有灰尘等杂质落入到磁盘中就可能会导致磁头撞击灰尘从而刮花盘面,所以磁盘拆开后就会损坏。
2、现在一般个人的笔记本都是使用固态硬盘 SSD,而不再使用磁盘,因为磁盘的磁头与盘面距离非常近,所以为了避免磁盘与盘面接触而刮花盘面导致数据丢失,磁盘不能抖动;但是笔记本通常要进行移动,很可能会发生上述故障;同时,SSD 的读写速度要高于磁盘。
3、但是在企业端,磁盘仍然是存储的主流,因为企业中主机都统一放置在机房中,轻易不会移动;同时,SSD 存在造价贵、读写次数有限等缺点。
4、磁盘是计算机中唯一一个纯机械结构的设备,同时磁盘还是外设,所以磁盘进行数据读写的速度很慢。
1.2 磁盘的逻辑结构
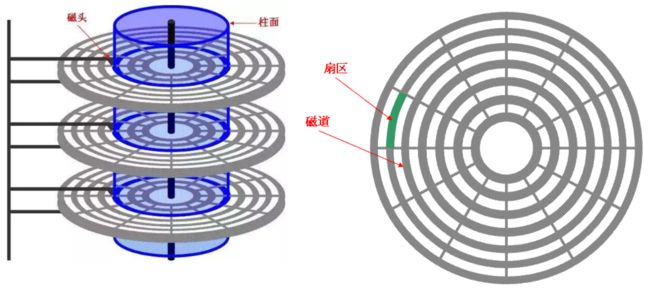
磁道:磁盘的表面即盘面由一些磁性物质组成,可以用这些磁性物质来记录二进制数据;同时,盘面被划分为一个个同心圆,这些同心圆被称为 磁道 (一个同心圆就是一个磁道),相邻磁道之间是有间隙的,我们的数据就存在磁道上。
扇区:从圆心向外放射,与磁道围成的一小块区域称为扇区,一个磁道会被划分为许多个扇区,每个扇区就是一个 “磁盘块”,这是磁盘寻址的基本单位,即数据进行 IO 的单位,大小一般为 512 byte。(注:每个扇区的大小是固定的,所以从圆心往外,扇区的数据存储密度会随着扇区面积的增大而减小)
柱面:磁盘中所有盘面的同一个磁道被称为一个柱面,可以说,柱面和磁道是等价的。
简单的示意图如下
磁盘寻址的过程:
磁盘在IO的过程中,需要进行寻址。寻址的过程主要如下:1.定位磁道,也就是在哪一个柱面(cylinder)2. 确定在哪一个盘面,也就是用哪一个磁头(head)3. 最后再确定在哪一个扇区(sector)
上述过程在物理上的表现方式如下:启动主轴后,所有的盘片以同样的方式进行高速旋转,同时所有的磁头也共同从圆心到半径左右摆动,当定位到柱面后,磁头停止摆动,盘片继续旋转,当盘片对应扇区旋转到磁头下方后,对应盘面的磁头向扇区中写入/读取数据。
所以,在磁盘中定位任意一个/多个扇区,采用的基本硬件定位方式是 柱面、磁头、扇区定位,即 CHS 定位法。
1.3 磁盘的存储结构
相比较于这种三维立体的结构,实际上线性的结构更方便去管理。所以在存储的过程中,我们是把这个磁盘的立体结构转化成线性的存储结构来管理

现在就可以把原来对物理结构的管理转换成了对数组的管理
所以只要知道了这个扇区的下标就算定位了一个扇区。在操作系统内部,我们把这种地址称为LBA地址(logic block address)
举个例子:
假设我们现在有这样的参数:有4个盘面,每个盘面有10个磁道,每个磁道有100个扇区,每个扇区有512个字节。
那么现在如果给出指定的LBA地址,就能够找到对应的CHS参数,也就能够定位到对应的磁盘的物理地址了。
假设要找LBA地址是123对应的物理地址:
盘面号 = LBA地址 / (磁道数 * 扇区数) = 123 / 10 * 100 = 0号盘面
磁道号 = LBA地址 / 扇区数 = 123 / 100 = 1号磁道
扇区号 = LBA地址 % 扇区数 = 123 % 100 = 23号扇区
为什么OS要进行逻辑抽象,直接用CHS不行吗?
1. 便于OS管理
2. 不想让OS的代码和硬件强耦合
2. 文件系统
2.1 磁盘的组织方式
文件在磁盘中是如何存储的呢?
我们已经知道了磁盘空间的管理方式是使用线性的结构来管理的。磁盘的空间很大虽然对应的磁盘访问的基本单位是512个字节,但是依旧是很小的!OS内的文件系统定制了多个扇区读取–>1KB,2KB,4KB为基本单位。即使本来希望读取的是1bit,也必须将4KB的内容load进内存,进行读取或者修改。所以我们采用分治的思想,来管理磁盘空间进行分区:大的磁盘空间->小空间,对于每个小空间管理好了,然后把这些小空间组织起来即可。
在win10系统中右键此电脑,点击管理、磁盘管理,就能看到这个界面这里好像是把自己的磁盘分成了很多块,实际上,这并不是很多块磁盘,而是把一个磁盘进行了分区。


当然,这个分区和分组的大小是笔者自己杜撰的,便于理解,实际中不一定存在这种分区大小。
实际上对于分区之后的管理,都有一些比较细节的东西
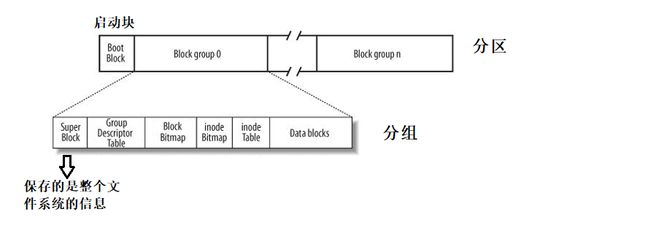
- Boot Block:启动块,存在于每个分区的开头,备份文件与启动相关的。在当前的分区中剩下的空间将会被继续分组,分成很多个Block Group
- Super Block:保存所在分区的整个文件系统的信息。这里将superblock在每个分组中保存的原因是用于备份,如果其中一个superblock损坏,可以通过拷贝其他分组中的superblock来恢复。
2.2 inode的概念
文件 = 内容 + 属性
Linux的文件属性和文件内容是分批存储的
-
保存文件属性的是
inode。inode块的大小是固定的,为128字节。一般来说,一个文件有一个inode,包含了这个文件几乎所有的属性(文件名除外)。 -
文件内容是存储在
data bloack中的,不同文件存放的内容不同,这些文件内容的大小随着文件类型的大小也在变化 -
每个文件都有一个inode,所以会有很多inode。为了区分,所以每个inode都有自己的ID,可以使用
ls -li来查看inode编号:

实际上,在每个分组中,都有着对应的区域用于存放对应的内容
Super Block:存放所在分区的整个文件系统的信息,在这个分区中的每个分组中都有备份Groupe Descriptor Table:GDT,块组表述表。记录了每个块组的起始块号、空闲块数量、空闲索引节点数量等信息,同时也包括块位图和索引节点位图的起始位置Block Bitmap:data block对应的位图结构,存放对应的data block是否被使用的标志inode Bitmap:inode对应的位图结构,存放对应的inode是否被使用的标志inode Table:保存了分组内部所有可用的inode(包含已经使用的和没有使用的)Data blocks:是真正存放文件内容的内存块,除了上述的内容外,整个分组的所有空间都是数据块
2.3 文件的访问方式
1. 访问文件的属性
首先找到这个文件对应的inode,然后通过inode来访问到inode Table中的数据,这里存放的就是文件的属性相关信息。
2. 访问文件的内容
我们知道文件的内容是存放在Data Blocks中的。那么需要访问文件内容的时候,访问这些DataBlocks即可。
但是我怎么知道这些Data Blocks中的数据是哪个文件的?所以这就需要将inode与DataBlocks联系起来
我们知道inode中存放了文件的属性,那么在inode中再存一个数组,数组内的内容就是使用的Data Blocks。那么就可以通过inode来找到这个文件使用的DataBlocks了
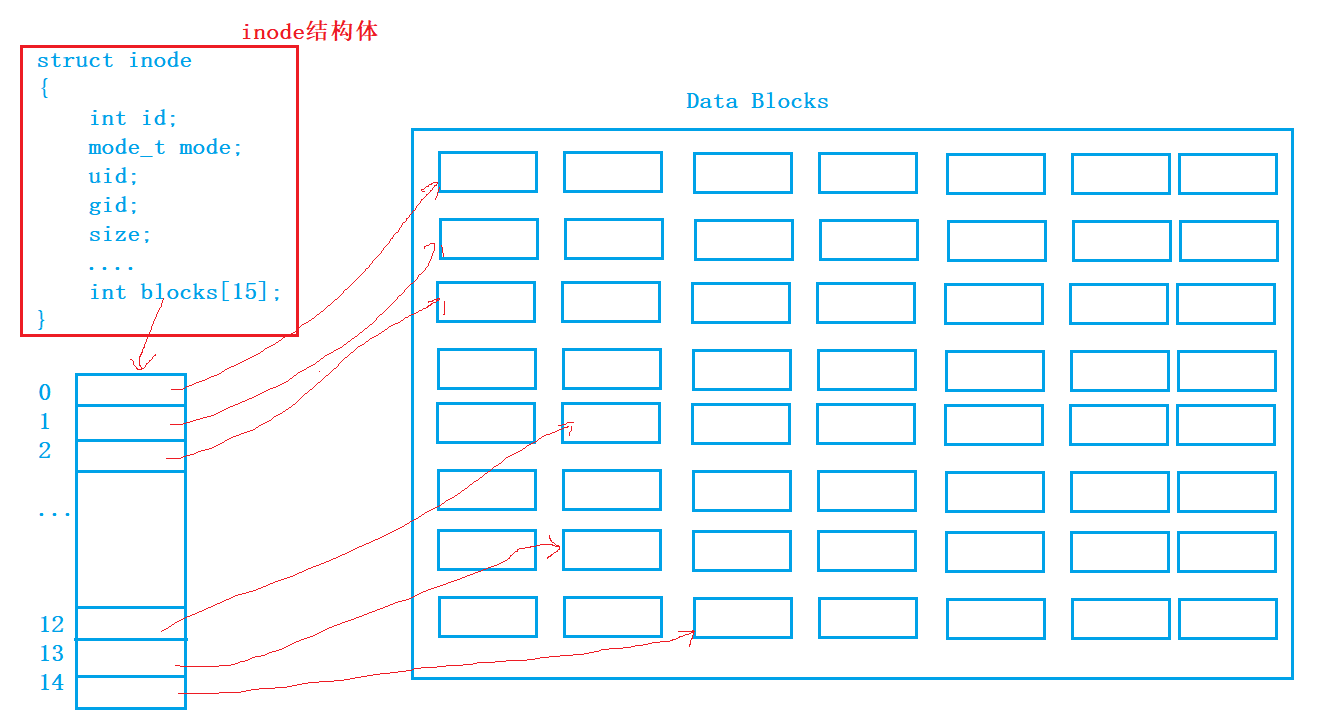
还有一个问题:这个blocks中一共有15个元素,每个元素保存一个DataBlocks,每个datablocks的大小一般是4KB,那么一共也就只能存放4*15=60KB,这也太小了吧?
实际上,在Linux中采用了混合索引的方式来组织这些数据块所谓的混合索引就是在blocks数组的最后几个元素中存放的数据块地址里面存放的内容是其他数据块的地址。一般来说最后三个分别是一级二级和三级索引。
通过文件的访问,我们了解到了文件系统内对文件的管理形式,那么创建文件和删除文件的方法也就显而易见了
**创建文件:**在inode Bitmap中找到一个编号为0的,将其比特位置为1,同时找到找到对应的inode编号,把文件的属性填进去,文件的内容数据写到block里面,在inode和block之间建立映射关系,然后返回inode编号
删除一个文件:删除文件也需要用到inode,实际上删除一个文件时,我们只需要找到inode在inode bitmap当中的比特位,把比特位由1置为0就删除了。所以删除一个文件根本不需要把数据属性和内容清空,只要把inode bitmap的1置为0,属性就删除了,这个文件也占着数据块,也把block的比特位也置为0。所以把文件删除是能够恢复的,一旦删除只是把bit位清掉了,想要恢复只要得到inode的编号,然后把inode bitmap里的比特位由0置为1,在去inode table对应的映射表,在block bitmap的0置为1。
如果在Linux中误删除一个文件,还是能恢复的,但是前提必须是inode和data block没有被占用,所以当误删除一个文件时,最好的办法就是什么都不做。而我们在Windows中删除文件到回收站,只是转移了目录,在回收站中删除才是真正的删除。这里最好为自己的Linux手动设置一个回收站,可以参考这篇博文中的设置方法来做:【Linux】基本知识和权限_
上述我们在说一个文件的时候,使用的都是inode来说的,但是我们在使用文件的时候用的是文件名啊,并不是inode!!!
我们知道,目录也是一个文件,那么目录也有inode,也就是说目录也有数据块,实际上目录的数据块中存放的内容就是当前目录下的文件名和这个文件对应的inode的映射关系所以在权限的章节的时候说了要显示当前目录的所有文件就需要这个目录的读权限,在这个目录下创建文件就需要写权限,这其实都是对这个目录的数据块的读写权限
也有inode,也就是说目录也有数据块,实际上目录的数据块中存放的内容就是当前目录下的文件名和这个文件对应的inode的映射关系所以在权限的章节的时候说了要显示当前目录的所有文件就需要这个目录的读权限,在这个目录下创建文件就需要写权限,这其实都是对这个目录的数据块的读写权限**