机器学习预处理:特征工程
什么是特征工程
特征是⽤于描述数据中的各种属性、变量或维度的信息,它们是模型⽤来做 出预测或分类的输⼊。特征⼯程是使⽤专业背景知识和技巧处理数据,使得特征能 在机器学习算法上发挥更好的作⽤的过程。良好的特征⼯程可以显著提⾼模型的性能,⽽糟糕的特征选择或构建可能导致模型性能下降。
意义:会直接影响机器学习的效果
特征⼯程的主要⽬标包括:
1. 特征选择:选择最相关的特征,以减少维度和噪声,提⾼模型的泛化能⼒。这 可以通过统计⽅法、领域知识、特征重要性评估等⽅式来完成。
2. 特征构建:创建新的特征,以提供更多的信息或改善模型的性能。这可能包括 将原始特征组合、进⾏数学变换、提取时间序列特征等操作。
3. 特征缩放:确保特征具有相似的尺度,以避免某些特征对模型的权重产⽣不适 当的影响。常⻅的缩放⽅法包括标准化和归⼀化。
4. 处理缺失数据:处理缺失值,可以使⽤插补⽅法来填充缺失值,或者考虑是否 删除包含缺失值的样本。
5. 处理分类特征:将分类特征进⾏编码,例如独热编码(One-Hot Encoding) 或标签编码(Label Encoding),以使其适⽤于机器学习模型。
6. 特征交叉:将不同特征之间的关联性考虑在内,通过创建特征交叉来提供更多 信息。
7. 特征选择和降维:使⽤降维技术(如主成分分析PCA)来减少特征的数量,以 提⾼模型的效率和可解释性。
基本预处理
- 基本预处理:缺失值处理
- 删除属性或者删除样本:如果⼤部分样本该属性都缺失,这个属性能提供的信息有限,可以选择放弃使⽤该维属性
- 统计填充:对于缺失值的属性,尤其是数值类型的属性,根据所有样本关于这维属性的统计值对其进⾏填充,如使⽤平均数、中位数、众数、 最⼤值、最⼩值等,具体选择哪种统计值需要具体问题具体分析。
- 统⼀填充:常⽤的统⼀填充值有:“空”、“0”、“正⽆穷”、“负⽆ 穷”等。
- 预测/模型填充:可以通过预测模型利⽤不存在缺失值的属性来预测缺失值,也就是先⽤预测模型把数据填充后再做进⼀步的⼯作,如统计、 学习等。虽然这种⽅法⽐较复杂,但是最后得到的结果⽐较好。 pandas库: fillna sklearn库: Imputer
- pandas库:fillna
- sklearn库:Imputer
⽤特征⼯程处理泰坦尼克号的预数据
字段说明:
| 字段1 | 说明1 | 字段2 | 说明2 |
| Passenge rId | 乘客ID | Survived | ⽣存情况,1为存活,0为死 亡 |
| Pclass | 客舱等级,1为⾼级,2 为中级,3为低级 | Name | 乘客名字 |
| Sex | 乘客性别 | Age | 乘客年龄 |
| SibSp | 在船兄弟姐妹数/配偶数 | Parch | 在船⽗⺟数/⼦⼥数 |
| Ticket | 船票编号 | Fare | 船票价格 |
| Cabin | 客舱号 | Embarked | 登船港⼝ |
首先导入模块
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore') # 忽略警告,不写也不影响代码运行导入数据,显示前5行:
df_train = pd.read_csv('train.csv')
print(df_train.head()) # 打印前5行运行结果
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S[5 rows x 12 columns]
显示行列数
print(df_train.shape) 运行结果:891行,12列
(891, 12)
看一下它大致有哪些字段,字段的类型
print(df_train.info())运行结果
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
Non-Null Count 显示非空数据,总共891条,Age 和 Cabin 有空值。
看整体的情况:
print(df_train.describe())运行结果
PassengerId Survived Pclass ... SibSp Parch Fare
count 891.000000 891.000000 891.000000 ... 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 ... 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 ... 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 ... 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 ... 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 ... 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 ... 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 ... 8.000000 6.000000 512.329200[8 rows x 7 columns]
可以看到,中间有省略,默认显示数值列,如果不是数值列,是不能够进行显示的,如果希望显示全部,可以这样写
print(df_train.describe(include='all'))运行结果
PassengerId Survived Pclass ... Fare Cabin Embarked
count 891.000000 891.000000 891.000000 ... 891.000000 204 889
unique NaN NaN NaN ... NaN 147 3
top NaN NaN NaN ... NaN B96 B98 S
freq NaN NaN NaN ... NaN 4 644
mean 446.000000 0.383838 2.308642 ... 32.204208 NaN NaN
std 257.353842 0.486592 0.836071 ... 49.693429 NaN NaN
min 1.000000 0.000000 1.000000 ... 0.000000 NaN NaN
25% 223.500000 0.000000 2.000000 ... 7.910400 NaN NaN
50% 446.000000 0.000000 3.000000 ... 14.454200 NaN NaN
75% 668.500000 1.000000 3.000000 ... 31.000000 NaN NaN
max 891.000000 1.000000 3.000000 ... 512.329200 NaN NaN[11 rows x 12 columns]
我们看看哪些数据有异常情况,缺失值怎么去处理。
缺失值的处理
缺失值处理,以Age年龄为例
删除属性或者删除样本
- 统计补充
- 统⼀补充
- 模型预测补充
取出年龄数据
print(df_train['Age'])运行结果
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
...
886 27.0
887 19.0
888 NaN
889 26.0
890 32.0
Name: Age, Length: 891, dtype: float64
1. 使用pandas填充
df_train['Age'].fillna(value=df_train['Age'].mean())
print(df_train['Age'])运行结果
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
...
886 27.0
887 19.0
888 NaN
889 26.0
890 32.0
Name: Age, Length: 891, dtype: float64
没有填充成功是因为inplace默认是False
2. sklearn SimpleImputer 函数 填充
from sklearn.impute import SimpleImputer # 导入模块
imp = SimpleImputer(strategy='mean') # 实例化对象
print(type(df_train[['Age']]))运行结果:
通过赋值的方式用fit_transform进行转换
df_train[['Age']] = imp.fit_transform(df_train[['Age']].values) # 注意用两层中括号表示它是dataframe格式
print(df_train.info())运行结果
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
可以看到,Age列已经填充完毕
数值型特征
数值型的幅度变换:
- log变换、多项式变换
- 幅度缩放(数据预处理):MinMaxScaler 、 StandardScaler
- 统计数值: Max、Min、AVG...
- 四则运算:+ - * /
查看Age的唯一值
print(df_train['Age'].unique()) # 查看唯一值运行结果
[22. 38. 26. 35. 29.69911765 54.
2. 27. 14. 4. 58. 20.
39. 55. 31. 34. 15. 28.
8. 19. 40. 66. 42. 21.
18. 3. 7. 49. 29. 65.
28.5 5. 11. 45. 17. 32.
16. 25. 0.83 30. 33. 23.
24. 46. 59. 71. 37. 47.
14.5 70.5 32.5 12. 9. 36.5
51. 55.5 40.5 44. 1. 61.
56. 50. 36. 45.5 20.5 62.
41. 52. 63. 23.5 0.92 43.
60. 10. 64. 13. 48. 0.75
53. 57. 80. 70. 24.5 6.
0.67 30.5 0.42 34.5 74. ]
可以看到,年龄从几个月到80不等。
1)对数变换
df_train['log_age'] = df_train['Age'].apply(lambda x:np.log(x))
print(df_train.head(5))运行结果
PassengerId Survived Pclass ... Cabin Embarked log_age
0 1 0 3 ... NaN S 3.091042
1 2 1 1 ... C85 C 3.637586
2 3 1 3 ... NaN S 3.258097
3 4 1 1 ... C123 S 3.555348
4 5 0 3 ... NaN S 3.555348[5 rows x 13 columns]
可以看到 log_age数据小了很多
2)MinMaxScaler()最大最小归一化处理
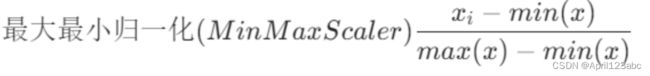
其中 min 是样本中最⼩值, max是样本中最⼤值
from sklearn.preprocessing import MinMaxScaler
# 实例化最大最小转换器
mm_scaler = MinMaxScaler()
# 用fit_transform处理船票的价格
fare_trans = mm_scaler.fit_transform(df_train['Fare'])
print(fare_trans)运行结果如下
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
fare_trans = mm_scaler.fit_transform(df_train[['Fare']]) # 加上一个中括号
print(fare_trans)可以正常运行,运行结果比较多,就不展示了。 最大最小归一化处理可以取得[0-1]之间的任何值,能取到0, 也能取到1.
3)标准化处理

from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
fare_std_fares = std_scaler.fit_transform(df_train[['Fare']])
print(fare_std_fares)对数变换 处理右偏或者左偏的数据使用对数变换可以让这个数据更加接近正态分布,有助于我们对模型的处理。
用的最多的是标准化处理,数据是标准的正态分布。
最大最小归一化涉及到最大值和最小值,很容易受到极值的影响。
总的来说:数据量大,要求精度的用标准化处理,数据量小,不要求精度的,可以使用最大最小归一化处理,数据如果呈现明显的左偏、右偏,用对数变换。
描述性统计分析
# 最⼤最⼩值,在电商⾥经常⽤到
max_age = df_train['Age'].max()
min_age = df_train['Age'].min()
print(max_age)
print(min_age)
# 分位数
# 1/4分位数
age_quarter_1 = df_train['Age'].quantile(0.25)
# 3/4分位数
age_quarter_3 = df_train['Age'].quantile(0.75)
print(age_quarter_1)
print(age_quarter_3)运行结果
80.0
0.42
22.0
35.0
计算家庭总人数
df_train.loc[:,'family_size'] = df_train['SibSp']+df_train['Parch']+1
print(df_train.head())运行结果
PassengerId Survived Pclass ... Embarked log_age family_size
0 1 0 3 ... S 3.091042 2
1 2 1 1 ... C 3.637586 2
2 3 1 3 ... S 3.258097 1
3 4 1 1 ... S 3.555348 2
4 5 0 3 ... S 3.555348 1[5 rows x 14 columns]
⾼次特征与交叉特征
preprocessing.PolynomialFeatures
是什么:
PolynomialFeatures 变换⽤于在机器学习中创建多项式特征,它的主要⽬的 是扩展特征空间,使模型能够更好地拟合⾮线性关系。这种变换通常⽤于线性回 归、逻辑回归、⽀持向量机(SVM)等模型,特别是当原始特征与⽬标之间存 在复杂的⾮线性关系时,多项式特征变换可以提⾼模型的性能。
怎么⽤:
对于给定的输⼊特征,例如⼀个特征向量 [x1, x2, x3],PolynomialFeatures 将其转换为多项式的形式,包括原始特征的各种幂和交叉项。例如,对于⼆次多 项式,它会⽣成 [x1, x2, x3, x1^2, x2^2, x3^2, x1x2, x1x3, x2x3]。
什么时候⽤:
1. ⾮线性关系: 当你有理由相信⽬标变量与特征之间存在⾮线性关系时,多 项式特征变换可以⽤来更好地捕捉这些⾮线性关系。
2. 特定特征之间的交互效应: 如果你怀疑某些特征之间的交互效应对⽬标变 量有影响,你可以使⽤多项式特征变换来引⼊这些交互项,以改善模型性 能。
3. 特征⼯程: 在⼀些情况下,多项式特征变换是特征⼯程的⼀部分,⽤于改 进模型的性能。
4. ⾼次特征: 如果你认为某些特征具有⾼次项的影响,例如 x^2, x^3, 等 等,你可以使⽤多项式特征变换来引⼊这些⾼次项,以更好地描述数据的复 杂性。
5. ⽤于⽀持向量机 (SVM): 在⽀持向量机中,多项式特征变换可以将数据映 射到⾼维空间,从⽽使⽀持向量机能够更好地分隔不同类别的数据。
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2) # 到x的二次方就截止了
print(df_train[['SibSp', 'Parch']].head())
poly_fea = poly.fit_transform(df_train[['SibSp','Parch']])
print(poly_fea)运行结果
SibSp Parch
0 1 0
1 1 0
2 0 0
3 1 0
4 0 0
[[1. 1. 0. 1. 0. 0.]
[1. 1. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 0.]
...
[1. 1. 2. 1. 2. 4.]
[1. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0.]]
离散化
df_train.loc[:,'fare_cut'] = pd.cut(df_train['Fare'],5)
print(df_train.head())
print(df_train['fare_cut'].unique()) # 查看区间唯⼀值运行结果
PassengerId Survived Pclass ... log_age family_size fare_cut
0 1 0 3 ... 3.091042 2 (-0.512, 102.466]
1 2 1 1 ... 3.637586 2 (-0.512, 102.466]
2 3 1 3 ... 3.258097 1 (-0.512, 102.466]
3 4 1 1 ... 3.555348 2 (-0.512, 102.466]
4 5 0 3 ... 3.555348 1 (-0.512, 102.466][5 rows x 15 columns]
[(-0.512, 102.466], (204.932, 307.398], (102.466, 204.932], (409.863, 512.329]]
Categories (5, interval[float64, right]): [(-0.512, 102.466] < (102.466, 204.932] <
(204.932, 307.398] < (307.398, 409.863] <
(409.863, 512.329]]
字符型特征
类别型:
- pandas get_dummies/哑变量
- OneHotEncoder()/独热向量编码
- 标签编码LabelEncoder()
get_dummies() 是 pandas 库中的⼀个函数,⽤于将分类数据转换为虚拟(⼆进制)变量
embarked = pd.get_dummies(df_train['Embarked'])
print(embarked)运行结果
C Q S
0 False False True
1 True False False
2 False False True
3 False False True
4 False False True
.. ... ... ...
886 False False True
887 False False True
888 False False True
889 True False False
890 False True False[891 rows x 3 columns]
参数说明:
- data: 要进⾏虚拟编码的数据,可以是⼀个 DataFrame 或 Series。
- columns (可选): ⼀个⽤于指定要编码的列名的列表。如果不指定,函数将 尝试对数据中的所有⾮数值列进⾏编码。
- prefix (可选): ⼀个字符串或字符串列表,⽤于指定⽣成的虚拟列的前缀。 如果提供了多个前缀,它们将与列名⼀⼀对应。默认情况下,⽣成的虚拟列 的名称将与原始分类值相同。
- prefix_sep (可选): ⽤于分隔前缀和列名的字符串。默认为下划线 "_”。
- drop_first (可选): 如果设置为 True,则将删除每个虚拟列中的第⼀个级 别,以避免多重共线性。默认为 False。
- dummy_na (可选): 如果设置为 True,将为缺失值创建虚拟列,表示原始 列中的缺失值。默认为 False。
- sparse (可选): 如果设置为 True,则⽣成稀疏矩阵,否则⽣成密集矩阵。 稀疏矩阵在具有⼤量零值的情况下可以节省内存。默认为 False。
- dtype (可选): ⽤于指定⽣成虚拟列的数据类型。默认为 None,会⾃动根据 数据类型选择。
embarked_out = pd.get_dummies(df_train[['Embarked']])
print(embarked_out)运行结果
Embarked_C Embarked_Q Embarked_S
0 False False True
1 True False False
2 False False True
3 False False True
4 False False True
.. ... ... ...
886 False False True
887 False False True
888 False False True
889 True False False
890 False True False[891 rows x 3 columns]
小结
- 对于数值型的特征中,特征的属性是⽆序的,⽤独热编码/哑变量,⽐如说: 性别、颜⾊、星期;
- 对于数值型的特征中,特征的属性是有序的,⽤标签编码(LabelEncoder)。⽐ 如说:公司的成⽴时间、职位;