2024-01-01 力扣高频SQL50题目 练习笔记
1. 1661求机器平均运行时间
在做这道题的时候,我遇到了4个问题
# 求平均的问题 如何找到个数? -> 相减对应列值后,直接average 就行。因为avg就是自动确定要除的个数(当然要联合正确的group by 分组)
# 怎么根据machine_id和process_id 去匹配 -> 自联结
# start 和 end 如何确定 -> 自联结指定
# group by 分组 如果没有加分组,可能就不对。什么时候要加分组呢?聚合函数avg,sum,count的时候,都“应该”加。还有就是需要根据xx分组。筛选出每个唯一的值,并根据这些唯一的值进行查询
2 577员工奖金
这是一个很简单的连表查询,要求找出奖金小于1000元的员工姓名和金额。
于是,我最开始这样写:
select e.name,b.bonus from Employee e left join Bonus b on e.empId = b.empId
where b.bonus <1000
但显示不对。我发现答案里面有null,说明在Bonus中的bonus有可能是null,也就是没有这条数据。那么就需要加上判断是否是null。
select e.name,b.bonus from Employee e left join Bonus b on e.empId = b.empId
where b.bonus is null or b.bonus <1000
3 1280.学生们参加各科测试的次数
这个题目我写了好几遍。
第一次尝试,没有写出来,看了提解启发思路,再写,不对
select a.student_id student_id,a.student_name ,b.subject_name ,count(b.subject_name)attended_exams
from Students a right join Examinations c on a.student_id = c.student_id
left join Subjects b on b.subject_name = c.subject_name group by a.student_id,a.student_name
,b.subject_name order by a.student_id,b.subject_name
第二次尝试,不对
select a.student_id ,a.student_name ,b.subject_name ,count(b.subject_name)attended_exams
from Students a join Subjects b left join Examinations c on a.student_id = c.student_id
and b.subject_name = c.subject_name group by a.student_id,a.student_name
order by a.student_id,b.subject_name
第三次尝试,不对
select a.student_id ,a.student_name ,b.subject_name ,count(b.subject_name)attended_exams
from Students a join Subjects b left join Examinations c on a.student_id = c.student_id
and b.subject_name = c.subject_name group by a.student_id, c.subject_name
order by a.student_id,b.subject_name
最后一次,比对提解,逐帧查看问题出在哪里
select a.student_id ,a.student_name ,b.subject_name ,count(c.subject_name)attended_exams
from Students a join Subjects b left join Examinations c on a.student_id = c.student_id
and b.subject_name = c.subject_name group by a.student_id, a.student_name,b.subject_name
order by a.student_id,b.subject_name
# 问题1 考试次数 0 的没有罗列出来 -> 我换个表连接方向,但好像还是不行唉。后来发现是分组和count()列的问题。
# 问题2 分组条件 我选学生名 学生id 这不对的。
# 问题3 分组条件 我选择 考试表的subject_name,也是不对的。
正确做法:应该根据科目表的subject_name分组,不然就没有考试表次数为0的记录。
# 问题4 count的时候,要去count考试表里的subject_name。
看来,分组条件不是随便选的,要起到唯一性,如果分组条件不唯一,可能会导致查询结果的重复或错误。而count的列名也不是随便选的!
4. 570.至少有5名直接下属的经理
最开始,我这样写
select t.name from (select e1.name as name,count(e2.managerId) from Employee e1,Employee e2 where e1.id = e2.managerId
group by e1.name having count(e2.managerId) >4 ) t
我点击运行,看通过了测试用例,就开心大吉了。
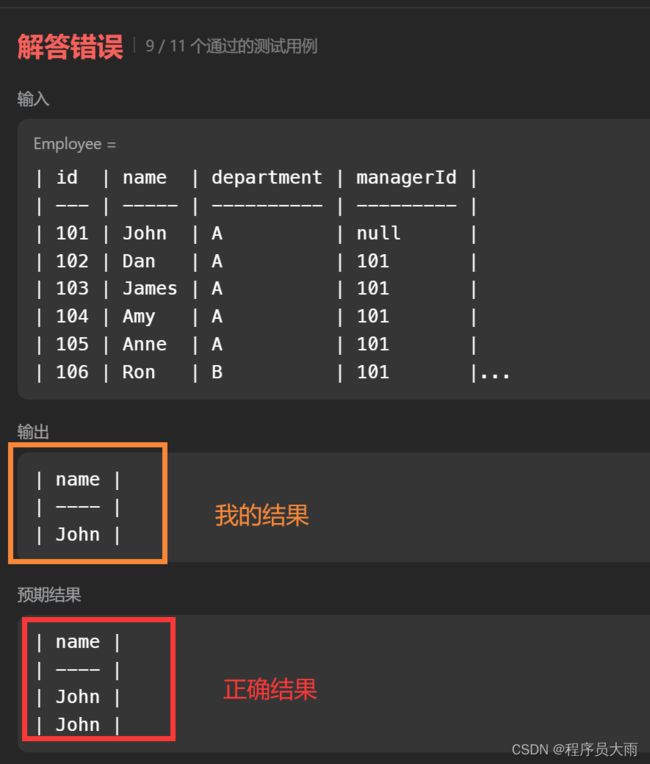
但是当我点击提交的时候,提示我解答错误,没有通过全部的测试用例。
这里我没有仔细看,我以为是没有去重,于是我这样写
select distinct t.name from (select e1.name as name,count(e2.managerId) from Employee e1,Employee e2 where e1.id = e2.managerId
group by e1.name
having count(e2.managerId) >4 ) t
发现还是不对,点开源码,我才明白,我上面写的SQL无法解决重名的问题!
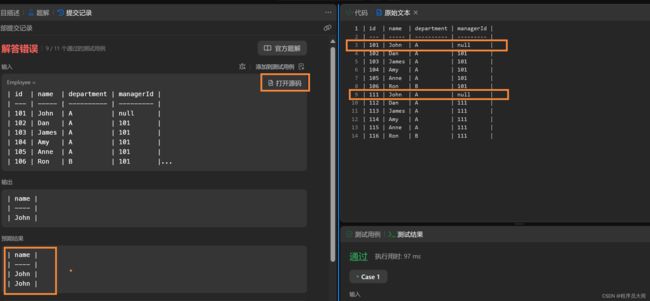
因此,需要去掉distinct,以及在分组的时候不要根据姓名name分组,而是要根据主键id去分组。
select t.name from (select e1.name as name,count(e2.managerId) from Employee e1,Employee e2 where e1.id = e2.managerId
group by e1.id
having count(e2.managerId) >4 ) t
5.1934 确认率
在写这道题的时候,我想到了以下问题:
# 联表时候 怎么 自联结?因为我想,需要找出“确认”的个数。->后面发现直接用if(条件,1,0),这样就可以实现这个效果。而总个数直接count(c.action)就可以。
# 怎么确认 timeout 和 confirmed 的个数?count什么呢?-> 同上。
# sum 怎么统计 action里 为 某个值的 个数 sum(),注意要group by 要准确的条件。
select s.user_id,ifnull((sum(if(c.action = 'confirmed',1,0)) / count(c.action)),0) as confirmation_rate from Signups s left join Confirmations c on s.user_id = c.user_id group by c.user_id
最后的ifnull 是因为这里提示要为0.
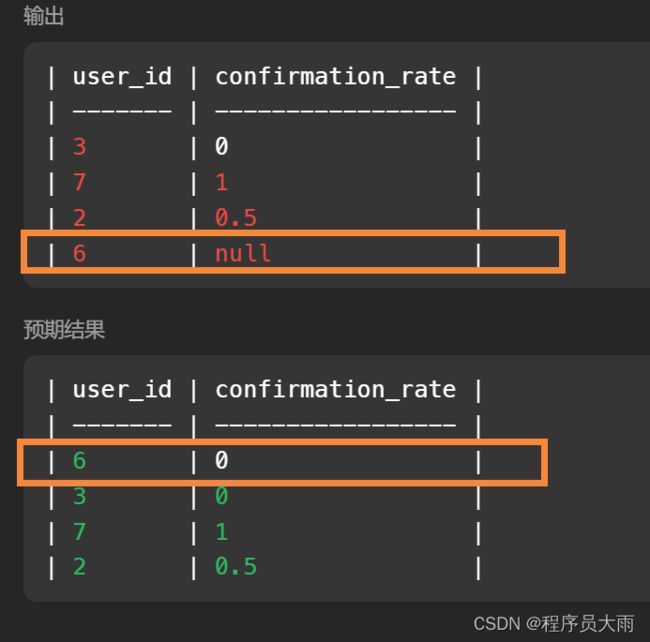
但是这样写有个问题,# 如果c.action 没有记录怎么办 ->用avg
select s.user_id,round(ifnull(avg(c.action = 'confirmed'),0),2) as confirmation_rate from Signups s left join Confirmations c on s.user_id = c.user_id group by c.user_id
这里为啥avg(c.action = 'confirmed')就能计算出平均成功率是多少呢?我没太理解