HBase内容分享(五):HBase读写性能优化
目录
一、HBase 读优化
1. HBase客户端优化
2. HBase服务器端优化
3. HBase列族设计优化
4. HDFS相关优化
5. HBase读性能优化归纳
二、HBase 写优化
1. 写性能优化切入点
2. 写异常问题检查点
一、HBase 读优化
1. HBase客户端优化
和大多数系统一样,客户端作为业务读写的入口,姿势使用不正确通常会导致本业务读延迟较高实际上存在一些使用姿势的推荐用法,这里一般需要关注四个问题:
1) scan缓存是否设置合理?
优化原理:在解释这个问题之前,首先需要解释什么是scan缓存,通常来讲一次scan会返回大量数据,因此客户端发起一次scan请求,实际并不会一次就将所有数据加载到本地,而是分成多次RPC请求进行加载,这样设计一方面是因为大量数据请求可能会导致网络带宽严重消耗进而影响其他业务,另一方面也有可能因为数据量太大导致本地客户端发生OOM。在这样的设计体系下用户会首先加载一部分数据到本地,然后遍历处理,再加载下一部分数据到本地处理,如此往复,直至所有数据都加载完成。数据加载到本地就存放在scan缓存中,默认100条数据大小。
通常情况下,默认的scan缓存设置就可以正常工作的。但是在一些大scan(一次scan可能需要查询几万甚至几十万行数据)来说,每次请求100条数据意味着一次scan需要几百甚至几千次RPC请求,这种交互的代价无疑是很大的。因此可以考虑将scan缓存设置增大,比如设为500或者1000就可能更加合适。笔者之前做过一次试验,在一次scan扫描10w+条数据量的条件下,将scan缓存从100增加到1000,可以有效降低scan请求的总体延迟,延迟基本降低了25%左右。
优化建议:大scan场景下将scan缓存从100增大到500或者1000,用以减少RPC次数
2) get请求是否可以使用批量请求?
优化原理:HBase分别提供了单条get以及批量get的API接口,使用批量get接口可以减少客户端到RegionServer之间的RPC连接数,提高读取性能。另外需要注意的是,批量get请求要么成功返回所有请求数据,要么抛出异常。
优化建议:使用批量get进行读取请求
3) 请求是否可以显示指定列族或者列?
优化原理:HBase是典型的列族数据库,意味着同一列族的数据存储在一起,不同列族的数据分开存储在不同的目录下。如果一个表有多个列族,只是根据Rowkey而不指定列族进行检索的话不同列族的数据需要独立进行检索,性能必然会比指定列族的查询差很多,很多情况下甚至会有2倍~3倍的性能损失。
优化建议:可以指定列族或者列进行精确查找的尽量指定查找
4) 离线批量读取请求是否设置禁止缓存?
优化原理:通常离线批量读取数据会进行一次性全表扫描,一方面数据量很大,另一方面请求只会执行一次。这种场景下如果使用scan默认设置,就会将数据从HDFS加载出来之后放到缓存。可想而知,大量数据进入缓存必将其他实时业务热点数据挤出,其他业务不得不从HDFS加载,进而会造成明显的读延迟毛刺
优化建议:离线批量读取请求设置禁用缓存,scan.setBlockCache(false)
2. HBase服务器端优化
一般服务端端问题一旦导致业务读请求延迟较大的话,通常是集群级别的,即整个集群的业务都会反映读延迟较大。可以从4个方面入手:
1) 读请求是否均衡?
优化原理:极端情况下假如所有的读请求都落在一台RegionServer的某几个Region上,这一方面不能发挥整个集群的并发处理能力,另一方面势必造成此台RegionServer资源严重消耗(比如IO耗尽、handler耗尽等),落在该台RegionServer上的其他业务会因此受到很大的波及。可见,读请求不均衡不仅会造成本身业务性能很差,还会严重影响其他业务。当然,写请求不均衡也会造成类似的问题,可见负载不均衡是HBase的大忌。
观察确认:观察所有RegionServer的读请求QPS曲线,确认是否存在读请求不均衡现象
优化建议:RowKey必须进行散列化处理(比如MD5散列),同时建表必须进行预分区处理
2) BlockCache是否设置合理?
优化原理:BlockCache作为读缓存,对于读性能来说至关重要。默认情况下BlockCache和Memstore的配置相对比较均衡(各占40%),可以根据集群业务进行修正,比如读多写少业务可以将BlockCache占比调大。另一方面,BlockCache的策略选择也很重要,不同策略对读性能来说影响并不是很大,但是对GC的影响却相当显著,尤其BucketCache的offheap模式下GC表现很优越。另外,HBase 2.0对offheap的改造(HBASE-11425)将会使HBase的读性能得到2~4倍的提升,同时GC表现会更好!
观察确认:观察所有RegionServer的缓存未命中率、配置文件相关配置项一级GC日志,确认BlockCache是否可以优化
优化建议:JVM内存配置量 < 20G,BlockCache策略选择LRUBlockCache;否则选择BucketCache策略的offheap模式;期待HBase 2.0的到来!
3) HFile文件是否太多?
优化原理:HBase读取数据通常首先会到Memstore和BlockCache中检索(读取最近写入数据&热点数据),如果查找不到就会到文件中检索。HBase的类LSM结构会导致每个store包含多数HFile文件,文件越多,检索所需的IO次数必然越多,读取延迟也就越高。文件数量通常取决于Compaction的执行策略,一般和两个配置参数有关:
hbase.hstore.compactionThreshold
hbase.hstore.compaction.max.size
前者表示一个store中的文件数超过多少就应该进行合并,后者表示参数合并的文件大小最大是多少,超过此大小的文件不能参与合并。这两个参数不能设置太’松’(前者不能设置太大,后者不能设置太小),导致Compaction合并文件的实际效果不明显,进而很多文件得不到合并。这样就会导致HFile文件数变多。
观察确认:观察RegionServer级别以及Region级别的storefile数,确认HFile文件是否过多
优化建议:hbase.hstore.compactionThreshold设置不能太大,默认是3个;设置需要根据Region大小确定,通常可以简单的认为 hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
4) Compaction是否消耗系统资源过多?
优化原理:Compaction是将小文件合并为大文件,提高后续业务随机读性能,但是也会带来IO放大以及带宽消耗问题(数据远程读取以及三副本写入都会消耗系统带宽)。正常配置情况下Minor Compaction并不会带来很大的系统资源消耗,除非因为配置不合理导致Minor Compaction太过频繁,或者Region设置太大情况下发生Major Compaction。
观察确认:观察系统IO资源以及带宽资源使用情况,再观察Compaction队列长度,确认是否由于Compaction导致系统资源消耗过多
优化建议:
-
Minor Compaction设置:hbase.hstore.compactionThreshold设置不能太小,又不能设置太大,因此建议设置为5~6;hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
-
Major Compaction设置:大Region读延迟敏感业务( 100G以上)通常不建议开启自动Major Compaction,手动低峰期触发。小Region或者延迟不敏感业务可以开启Major Compaction,但建议限制流量;
-
期待更多的优秀Compaction策略,类似于stripe-compaction尽早提供稳定服务
3. HBase列族设计优化
HBase列族设计对读性能影响也至关重要,其特点是只影响单个业务,并不会对整个集群产生太大影响。列族设计主要从以下方面检查:
1) Bloomfilter是否设置?是否设置合理?
优化原理:Bloomfilter主要用来过滤不存在待检索RowKey或者Row-Col的HFile文件,避免无用的IO操作。它会告诉你在这个HFile文件中是否可能存在待检索的KV,如果不存在,就可以不用消耗IO打开文件进行seek。很显然,通过设置Bloomfilter可以提升随机读写的性能。
Bloomfilter取值有两个,row以及rowcol,需要根据业务来确定具体使用哪种。如果业务大多数随机查询仅仅使用row作为查询条件,Bloomfilter一定要设置为row,否则如果大多数随机查询使用row+cf作为查询条件,Bloomfilter需要设置为rowcol。如果不确定业务查询类型,设置为row。
优化建议:任何业务都应该设置Bloomfilter,通常设置为row就可以,除非确认业务随机查询类型为row+cf,可以设置为rowcol
4. HDFS相关优化
HDFS作为HBase最终数据存储系统,通常会使用三副本策略存储HBase数据文件以及日志文件。从HDFS的角度望上层看,HBase即是它的客户端,HBase通过调用它的客户端进行数据读写操作,因此HDFS的相关优化也会影响HBase的读写性能。这里主要关注如下三个方面:
1) Short-Circuit Local Read功能是否开启?
优化原理:当前HDFS读取数据都需要经过DataNode,客户端会向DataNode发送读取数据的请求,DataNode接受到请求之后从硬盘中将文件读出来,再通过TPC发送给客户端。Short Circuit策略允许客户端绕过DataNode直接读取本地数据。(具体原理参考此处)
优化建议:开启Short Circuit Local Read功能,具体配置戳这里
2) Hedged Read功能是否开启?
优化原理:HBase数据在HDFS中一般都会存储三份,而且优先会通过Short-Circuit Local Read功能尝试本地读。但是在某些特殊情况下,有可能会出现因为磁盘问题或者网络问题引起的短时间本地读取失败,为了应对这类问题,社区开发者提出了补偿重试机制 – Hedged Read。该机制基本工作原理为:客户端发起一个本地读,一旦一段时间之后还没有返回,客户端将会向其他DataNode发送相同数据的请求。哪一个请求先返回,另一个就会被丢弃。
优化建议:开启Hedged Read功能,具体配置参考这里
3) 数据本地率是否太低?
数据本地率:HDFS数据通常存储三份,假如当前RegionA处于Node1上,数据a写入的时候三副本为(Node1,Node2,Node3),数据b写入三副本是(Node1,Node4,Node5),数据c写入三副本(Node1,Node3,Node5),可以看出来所有数据写入本地Node1肯定会写一份,数据都在本地可以读到,因此数据本地率是100%。现在假设RegionA被迁移到了Node2上,只有数据a在该节点上,其他数据(b和c)读取只能远程跨节点读,本地率就为33%(假设a,b和c的数据大小相同)。
优化原理:数据本地率太低很显然会产生大量的跨网络IO请求,必然会导致读请求延迟较高,因此提高数据本地率可以有效优化随机读性能。数据本地率低的原因一般是因为Region迁移(自动balance开启、RegionServer宕机迁移、手动迁移等),因此一方面可以通过避免Region无故迁移来保持数据本地率,另一方面如果数据本地率很低,也可以通过执行major_compact提升数据本地率到100%。
优化建议:避免Region无故迁移,比如关闭自动balance、RS宕机及时拉起并迁回飘走的Region等;在业务低峰期执行major_compact提升数据本地率
5. HBase读性能优化归纳
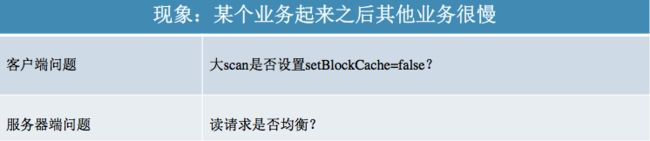
在本文开始的时候提到读延迟较大无非三种常见的表象,单个业务慢、集群随机读慢以及某个业务随机读之后其他业务受到影响导致随机读延迟很大。了解完常见的可能导致读延迟较大的一些问题之后,我们将这些问题进行如下归类,读者可以在看到现象之后在对应的问题列表中进行具体定位:


二、HBase 写优化
和读相比,HBase写数据流程倒是显得很简单:数据先顺序写入HLog,再写入对应的缓存Memstore,当Memstore中数据大小达到一定阈值(128M)之后,系统会异步将Memstore中数据flush到HDFS形成小文件。
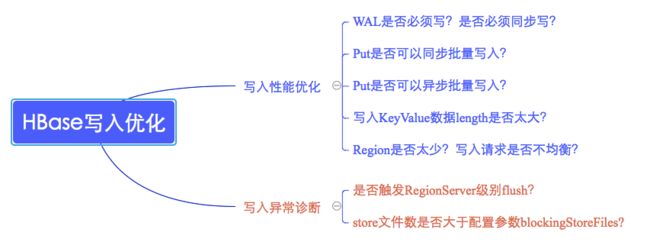
HBase数据写入通常会遇到两类问题,一类是写性能较差,另一类是数据根本写不进去。这两类问题的切入点也不尽相同,如下图所示:
1. 写性能优化切入点
1) 是否需要写WAL?WAL是否需要同步写入?
优化原理:数据写入流程可以理解为一次顺序写WAL+一次写缓存,通常情况下写缓存延迟很低,因此提升写性能就只能从WAL入手。WAL机制一方面是为了确保数据即使写入缓存丢失也可以恢复,另一方面是为了集群之间异步复制。默认WAL机制开启且使用同步机制写入WAL。首先考虑业务是否需要写WAL,通常情况下大多数业务都会开启WAL机制(默认),但是对于部分业务可能并不特别关心异常情况下部分数据的丢失,而更关心数据写入吞吐量,比如某些推荐业务,这类业务即使丢失一部分用户行为数据可能对推荐结果并不构成很大影响,但是对于写入吞吐量要求很高,不能造成数据队列阻塞。这种场景下可以考虑关闭WAL写入,写入吞吐量可以提升2x~3x。退而求其次,有些业务不能接受不写WAL,但可以接受WAL异步写入,也是可以考虑优化的,通常也会带来1x~2x的性能提升。
优化推荐:根据业务关注点在WAL机制与写入吞吐量之间做出选择
其他注意点:对于使用Increment操作的业务,WAL可以设置关闭,也可以设置异步写入,方法同Put类似。相信大多数Increment操作业务对WAL可能都不是那么敏感~
2) Put是否可以同步批量提交?
优化原理:HBase分别提供了单条put以及批量put的API接口,使用批量put接口可以减少客户端到RegionServer之间的RPC连接数,提高写入性能。另外需要注意的是,批量put请求要么全部成功返回,要么抛出异常。
优化建议:使用批量put进行写入请求
3) Put是否可以异步批量提交?
优化原理:业务如果可以接受异常情况下少量数据丢失的话,还可以使用异步批量提交的方式提交请求。提交分为两阶段执行:用户提交写请求之后,数据会写入客户端缓存,并返回用户写入成功;当客户端缓存达到阈值(默认2M)之后批量提交给RegionServer。需要注意的是,在某些情况下客户端异常的情况下缓存数据有可能丢失。
优化建议:在业务可以接受的情况下开启异步批量提交
使用方式:setAutoFlush(false)
4) Region是否太少?
优化原理:当前集群中表的Region个数如果小于RegionServer个数,即Num(Region of Table) < Num(RegionServer),可以考虑切分Region并尽可能分布到不同RegionServer来提高系统请求并发度,如果Num(Region of Table) > Num(RegionServer),再增加Region个数效果并不明显。
优化建议:在Num(Region of Table) < Num(RegionServer)的场景下切分部分请求负载高的Region并迁移到其他RegionServer;
5) 写入请求是否不均衡?
优化原理:另一个需要考虑的问题是写入请求是否均衡,如果不均衡,一方面会导致系统并发度较低,另一方面也有可能造成部分节点负载很高,进而影响其他业务。分布式系统中特别害怕一个节点负载很高的情况,一个节点负载很高可能会拖慢整个集群,这是因为很多业务会使用Mutli批量提交读写请求,一旦其中一部分请求落到该节点无法得到及时响应,就会导致整个批量请求超时。因此不怕节点宕掉,就怕节点奄奄一息!
优化建议:检查RowKey设计以及预分区策略,保证写入请求均衡。
6) 写入KeyValue数据是否太大?
KeyValue大小对写入性能的影响巨大,一旦遇到写入性能比较差的情况,需要考虑是否由于写入KeyValue数据太大导致。KeyValue大小对写入性能影响曲线图如下:

图中横坐标是写入的一行数据(每行数据10列)大小,左纵坐标是写入吞吐量,右坐标是写入平均延迟(ms)。可以看出随着单行数据大小不断变大,写入吞吐量急剧下降,写入延迟在100K之后急剧增大。
说到这里,有必要和大家分享两起在生产线环境因为业务KeyValue较大导致的严重问题,一起是因为大字段业务写入导致其他业务吞吐量急剧下降,另一起是因为大字段业务scan导致RegionServer宕机。
案件一:大字段写入导致其他业务吞吐量急剧下降
部分业务反馈集群写入忽然变慢、数据开始堆积的情况,查看集群表级别的数据读写QPS监控,发现问题的第一个关键点:业务A开始写入之后整个集群其他部分业务写入QPS都几乎断崖式下跌,初步怀疑黑手就是业务A。
下图是当时业务A的写入QPS(事后发现脑残忘了截取其他表QPS断崖式下跌的惨象),但是第一感觉是QPS并不高啊,凭什么去影响别人!

于是就继续查看其他监控信息,首先确认系统资源(主要是IO)并没有到达瓶颈,其次确认了写入的均衡性,直至看到下图,才追踪到影响其他业务写入的第二个关键点:RegionServer的handler(配置150)被残暴耗尽:
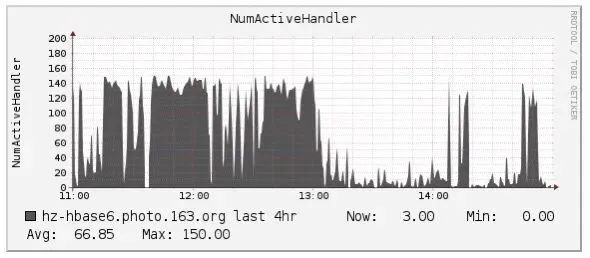
对比上面两张图,是不是发现出奇的一致,那就可以基本确认是由于该业务写入导致这台RegionServer的handler被耗尽,进而其他业务拿不到handler,自然写不进去。那问题来了,为什么会这样?正常情况下handler在处理完客户端请求之后会立马释放,唯一的解释是这些请求的延迟实在太大。
试想,我们去汉堡店排队买汉堡,有150个窗口服务,正常情况下大家买一个很快,这样150个窗口可能只需要50个服务。假设忽然来了一批大汉,要定制超大汉堡,好了,所有的窗口都工作起来,而且因为大汉堡不好制作导致服务很慢,这样必然会导致其他排队的用户长时间等待,直至超时。
可回头一想这可是写请求啊,怎么会有这么大的请求延迟!和业务方沟通之后确认该表主要存储语料库文档信息,都是平均100K左右的数据,是不是已经猜到了结果,没错,就是因为这个业务KeyValue太大导致。KeyValue太大会导致HLog文件写入频繁切换、flush以及compaction频繁触发,写入性能急剧下降。
目前针对这种较大KeyValue写入性能较差的问题还没有直接的解决方案,好在社区已经意识到这个问题,在接下来即将发布的下一个大版本HBase 2.0.0版本会针对该问题进行深入优化,详见HBase MOB,优化后用户使用HBase存储文档、图片等二进制数据都会有极佳的性能体验。
案件二:大字段scan导致RegionServer宕机
案件现场:有段时间有个0.98集群的RegionServer经常频繁宕机,查看日志是由于”java.lang.OutOfMemoryError: Requested array size exceeds VM limit”,如下图所示:

原因分析:通过查看源码以及相关文档,确认该异常发生在scan结果数据回传给客户端时由于数据量太大导致申请的array大小超过JVM规定的最大值( Interge.Max_Value-2)。造成该异常的两种最常见原因分别是:
-
表列太宽(几十万列或者上百万列),并且scan返回没有对列数量做任何限制,导致一行数据就可能因为包含大量列而数据超过array大小阈值
-
KeyValue太大,并且scan返回没有对返回结果大小做任何限制,导致返回数据结果大小超过array大小阈值
有的童鞋就要提问啦,说如果已经对返回结果大小做了限制,在表列太宽的情况下是不是就可以不对列数量做限制呢。这里需要澄清一下,如果不对列数据做限制,数据总是一行一行返回的,即使一行数据大小大于设置的返回结果限制大小,也会返回完整的一行数据。在这种情况下,如果这一行数据已经超过array大小阈值,也会触发OOM异常。
解决方案:目前针对该异常有两种解决方案,其一是升级集群到1.0,问题都解决了。其二是要求客户端访问的时候对返回结果大小做限制(scan.setMaxResultSize(210241024))、并且对列数量做限制(scan.setBatch(100)),当然,0.98.13版本以后也可以对返回结果大小在服务器端进行限制,设置参数hbase.server.scanner.max.result.size即可
2. 写异常问题检查点
上述几点主要针对写性能优化进行了介绍,除此之外,在一些情况下还会出现写异常,一旦发生需要考虑下面两种情况(GC引起的不做介绍):
Memstore设置是否会触发Region级别或者RegionServer级别flush操作?
问题解析:以RegionServer级别flush进行解析,HBase设定一旦整个RegionServer上所有Memstore占用内存大小总和大于配置文件中upperlimit时,系统就会执行RegionServer级别flush,flush算法会首先按照Region大小进行排序,再按照该顺序依次进行flush,直至总Memstore大小低至lowerlimit。这种flush通常会block较长时间,在日志中会发现“Memstore is above high water mark and block 7452 ms”,表示这次flush将会阻塞7s左右。
问题检查点:
-
Region规模与Memstore总大小设置是否合理?如果RegionServer上Region较多,而Memstore总大小设置的很小(JVM设置较小或者upper.limit设置较小),就会触发RegionServer级别flush。集群规划相关内容可以参考文章《HBase最佳实践-集群规划》
-
列族是否设置过多,通常情况下表列族建议设置在1~3个之间,最好一个。如果设置过多,会导致一个Region中包含很多Memstore,导致更容易触到高水位upperlimit
Store中HFile数量是否大于配置参数blockingStoreFile?
问题解析:对于数据写入很快的集群,还需要特别关注一个参数:hbase.hstore.blockingStoreFiles,此参数表示如果当前hstore中文件数大于该值,系统将会强制执行compaction操作进行文件合并,合并的过程会阻塞整个hstore的写入。通常情况下该场景发生在数据写入很快的情况下,在日志中可以发现”Waited 3722ms on a compaction to clean up ‘too many store files“
问题检查点:
-
参数设置是否合理?hbase.hstore.compactionThreshold表示启动compaction的最低阈值,该值不能太大,否则会积累太多文件,一般建议设置为5~8左右。hbase.hstore.blockingStoreFiles默认设置为7,可以适当调大一些。