R语言学习笔记(1~3)
R语言学习笔记(1~3)
一、R语言介绍
x <- rnorm(5)
创建了一个名为x的向量对象,它包含5个来自标准正态分布的随机偏差。
1.1 注释
由符号#开头。
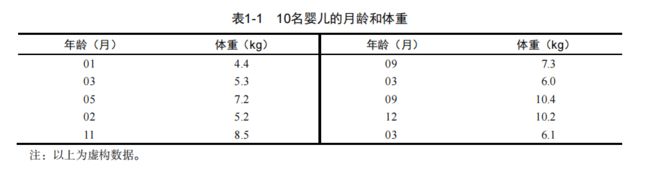
#函数c()以向量的形式输入月龄和体重数据,此函数可将其参数组合成一个向量或列表。
age<-c(1,3,5,2,11,9,3,9,12,3)
weight<-c(4.4,5.3,7.2,5.2,8.5,7.3,6.0,10.4,10.2,6.1)
mean(weight) #平均值
sd(weight) #标准差
cor(age,weight) #相关度
plot(age,weight) #plot()函数,用图形展示月龄和体重的关系,
#用可视化的方式检查其中可能存在的趋势
q() #函数q()将结束会话并允许你退出R
可视化数据:
1.2 获取帮助
R中的帮助函数:
help.start()
#打开帮助文档首页
help("foo")
#或
?foo
#查看函数foo的帮助(引号可以省略)
help.search("foo")
#或
??foo
#以foo为关键词搜索本地帮助文档
example("foo")
函数foo的使用示例(引号可以省略)
RSiteSearch("foo")
#以foo为关键词搜索在线文档和邮件列表存档
apropos("foo", mode="function")
#列出名称中含有foo的所有可用函数
data()
#列出当前已加载包中所含的所有可用示例数据集
vignette()
#列出当前已安装包中所有可用的vignette文档
vignette("foo")
#为主题foo显示指定的vignette文档
1.3 工作空间
工作空间(workspace)就是当前R的工作环境,它存储着所有用户定义的对象(向量、矩阵、函数、数据框、
**列表)。**在一个R会话结束时,你可以将当前工作空间保存到一个镜像中,并在下次启动R时自动载入它。
各种命令可在R命令行中交互式地输入。使用上下方向键查看已输入命令的历史记录。这样我们就可以选择一个之
前输入过的命令并适当修改,最后按回车重新执行它。
**当前的工作目录(working directory)**是R用来读取文件和保存结果的默认目录。我们可以使用函数getwd()来查
看当前的工作目录,或使用函数setwd()设定当前的工作目录。如果需要读入一个不在当前工作目录下的文件,则
需在调用语句中写明完整的路径。记得使用引号闭合这些目录名和文件名。
用于管理工作空间的部分标准命令如下:
getwd()
#显示当前的工作目录
setwd("mydirectory")
#修改当前的工作目录为 mydirectory
ls()
#列出当前工作空间中的对象
rm(objectlist)
#移除(删除)一个或多个对象
help(options)
#显示可用选项的说明
options()
#显示或设置当前选项
history(#)
#显示最近使用过的#个命令(默认值为 25)
savehistory("myfile")
#保存命令历史到文件 myfile 中(默认值为.Rhistory)
loadhistory("myfile")
#载入一个命令历史文件(默认值为.Rhistory)
save.image("myfile")
#保存工作空间到文件 myfile 中(默认值为.RData)
save(objectlist, file="myfile")
#保存指定对象到一个文件中
load("myfile")
#读取一个工作空间到当前会话中(默认值为.RData)
q() #退出R,将会询问你是否保存工作空间
实例:
setwd("C:/Users/B-612/Desktop")
# 修改当前工作路径
options()
options(digits=3) #数字将被格式化,显示为具有小数点后三位有效数字的格式
x <- runif(20) #包含20个均匀分布随机变量的向量
summary(x) #摘要统计量
hist(x) #绘制直方图
q()
首先,当前工作目录被设置为C:/Users/B-612/Desktop,当前的选项设置情况将显示出来,而数字将被格式化,
显示为具有小数点后三位有效数字的格式。
然后,创建了一个包含20个均匀分布随机变量的向量,生成了此数据的摘要统计量和直方图。
当q()函数被运行的时候,程序将向用户询问是否保存工作空间。
如果用户输入y:
- 命令的历史记录保存到文件.Rhistory中,
- 工作空间(包含向量x)保存到当前目录中的文件.RData中,会话结束,R程序退出。
注意:
setwd()命令的路径中使用了正斜杠。R将反斜杠(\)作为一个转义符。
即使在Windows平台上运行R,在路径中也要使用正斜杠。
-
同时注意,函数setwd()不会自动创建一个不存在的目录。
-
如果必要的话,可以使用函数dir.create()来创建新目录,然后使用setwd()将工作目录指向这个新目录。
1.4 输入与输出
1.4.1 输入
函数source(“filename”)
可在当前会话中执行一个脚本。如果文件名中不包含路径,R将假设此脚本在当前工作目录中。
举例来说,source(“myscript.R”)将执行包含在文件myscript.R中的R语句集合。依照惯例,脚本文件以.R作为扩展
名,不过这并不是必需的。
1.4.2 文本输出
函数sink(“filename”)
将输出重定向到文件filename中。默认情况下,如果文件已经存在,则它的内容将被覆盖。
使用参数append=TRUE可以将文本追加到文件后,而不是覆盖它。
参数split=TRUE可将输出同时发送到屏幕和输出文件中。不加参数调用命令sink()将仅向屏幕返回
输出结果。
1.4.3 图形输出
虽然sink()可以重定向文本输出,但它对图形输出没有影响。
要重定向图形输出,使用函数如下:
bmp("filename.bmp") #BMP 文件
jpeg("filename.jpg") #JPEG 文件
pdf("filename.pdf") #PDF 文件
png("filename.png") #PNG 文件
postscript("filename.ps") #PostScript 文件
svg("filename.svg") #SVG 文件
win.metafile("filename.wmf") #Windows 图元文件
最后使用dev.off()将输出返回到终端。
示例:
假设我们有包含R代码的三个脚本文件script1.R、script2.R和script3.R。执行语句:
source("script1.R")
将会在当前会话中执行script1.R中的R代码,结果将出现在屏幕上。
如果执行语句:
sink("myoutput", append=TRUE, split=TRUE)
# append=TRUE可以将文本追加到文件后
# 参数split=TRUE可将输出同时发送到屏幕和输出文件中
pdf("mygraphs.pdf")
source("script2.R")
文件script2.R中的R代码将执行,结果也将显示在屏幕上。
除此之外,文本输出将被追加到文件myoutput中,图形输出将保存到文件mygraphs.pdf中。
最后,如果我们执行语句:
sink()
dev.off()
source("script3.R")
文件script3.R中的R代码将执行,结果将显示在屏幕上。
这一次,没有文本或图形输出保存到文件中。
1.5 包
1.5.1 包相关信息
计算机上存储包的目录称为库(library)。
-
函数libPaths()能够显示库所在的位置
-
函数library()则可以显示库中有哪些包
R自带了一系列默认包(包括base、datasets、utils、grDevices、graphics、stats以及methods),它们提供了
种类繁多的默认函数和数据集。
其他包可通过下载来进行安装。安装好以后,它们必须被载入到会话中才能使用。
命令search()可以告诉你哪些包已加载并可使用。
1.5.2 包的安装
-
第一次安装一个包,使用命令install.packages()即可。
- 举例来说,不加参数执行命令install.packages()将显示一个CRAN镜像站点的列表,选择其中一个镜像站点之后,将看到所有可用包的列表,选择其中的一个包即可进行下载和安装。
-
如果知道自己想安装的包的名称,可以直接将包名作为参数提供给这个函数。
- 例如,包gclus中提供了创建增强型散点图的函数。可以使用命令install.packages(“gclus”)来下载和安装它。
-
一个包仅需安装一次。但和其他软件类似,包经常被其作者更新。
- 使用命令update.packages()可以更新已经安装的包。
- 要查看已安装包的描述,可以使用installed. packages()命令,这将列出安装的包,以及它们的版本号、依赖关系等信息。
1.5.3 包的载入
例如,要使用gclus包,执行命令:
library(gclus)
1.5.4 包的使用
命令**help(package=“package_name”)**可以输出某个包的简短描述以及包中的函数名称和数据集名称的列表。
使用函数help()可以查看其中任意函数或数据集的更多细节。
1.5.5 常见错误
R语言编程中的常见错误:
有一些错误是R的初学者和经验丰富的R程序员都可能常犯的。如果程序出错了,请检查以下几方面:
❑使用了错误的大小写。
help()、Help()和HELP()是三个不同的函数(只有第一个是正确的)。
❑忘记使用必要的引号。install.packages("gclus")能够正常执行,然而Install.packages(gclus)将会报错。
❑在函数调用时忘记使用括号。例如,要使用help()而非help。即使函数无需参数,仍需加上()。
❑在Windows上,路径名中使用了\。R将反斜杠视为一个转义字符。
setwd("c:\mydata")会报错。正确的写法是setwd("c:/mydata")或setwd("c:\\mydata")。
❑使用了一个尚未载入包中的函数。函数order.clusters()包含在包gclus中。
如果还没有载入这个包就使用它,将会报错。
例题:利用汽车数据mtcars执行一次简单线性回归,通过车身重量(wt)预测每加仑行驶的英里数(mpg)。
lmfit <- lm(mpg~wt, data=mtcars)
# 以上赋值语句创建了一个名为lmfit的列表对象,其中包含了分析的大量信息(包括预测值、残差、回归系数等)
summary(lmfit)
# 显示分析结果的统计概要
plot(lmfit)
# 生成回归诊断图形
cook<-cooks.distance(lmfit)
# 计算和保存影响度量统计量
plot(cook)
# 对其绘图
predict(lmfit, mynewdata)
# 在新的车身重量数据上对每加仑行驶的英里数进行预测
要了解某个函数的返回值,查阅这个函数在线帮助文档中的“Value”部分即可。
本例中应当查阅help(lm)或?lm中的对应部分。这样就可以知道将某个函数的结果赋值到一个对象时,保存下来的
结果具体是什么。
1.6 实践示例
以下是任务描述:
(1) 打开帮助文档首页,并查阅其中的“Introduction to R”。
(2) 安装vcd包(一个用于可视化类别数据的包,你将在第11章中使用)。
(3) 列出此包中可用的函数和数据集。
(4) 载入这个包并阅读数据集Arthritis的描述。
(5) 显示数据集Arthritis的内容(直接输入一个对象的名称将列出它的内容)。
(6) 运行数据集Arthritis自带的示例。(如果不理解输出结果,也不要担心。它基本上显示了接受治疗的关节炎患者
较接受安慰剂的患者在病情上有了更多改善)
(7) 退出。
help.start()
install.packages("vcd")
help(package="vcd")
library(grid) #载入需要的程辑包:grid
library(vcd)
help(Arthritis)
Arthritis
example(Arthritis)
q()
二、创建数据集
2.1 数据集的概念
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
不同的行业对于数据集的行和列叫法不同:
-
统计学家称它们为观测(observation)和变量(variable)
-
数据库分析师则称其为记录(record)和字段(field)
-
数据挖掘和机器学习学科的研究者则把它们叫作示例(example)和属性(attribute)
病例数据集:

所示的数据集中:
PatientID是行/实例标识符,AdmDate是日期型变量,Age是连续型变量,
Diabetes是名义型变量,Status是有序型变量。
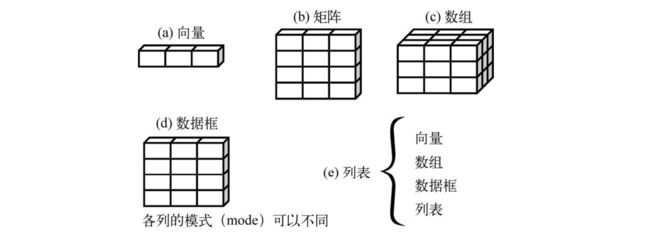
R中有许多用于存储数据的结构,包括标量、向量、数组、数据框和列表。
上示病例数据集实际上对应着R中的一个数据框。
R可以处理的数据类型(模式)包括:
数值型、字符型、逻辑型(TRUE/FALSE)、复数型(虚数)和原生型(字节)。
-
在R中,PatientID、AdmDate和Age为数值型变量,而Diabetes和Status则为字符型变量。
-
另外,你需要分别告诉R:PatientID是实例标识符,AdmDate含有日期数据,Diabetes和Status分别是名义型和有序型变量。
-
R将实例标识符称为rownames(行名),将类别型(包括名义型和有序型)变量称为因子(factors)。
2.2 数据结构
R拥有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框和列表。
它们在存储数据的类型、创建方式、结构复杂度,以及用于定位和访问其中个别元素的标记等方面均有所不同。
2.2.1 向量
向量是用于存储数值型、字符型或逻辑型数据的一维数组。执行组合功能的函数c()可用来创建向量。
各类向量:
a <- c(1, 2, 5, 3, 6, -2, 4) #数值型向量
b <- c("one", "two", "three") #字符型向量
c <- c(TRUE, TRUE, TRUE, FALSE, TRUE, FALSE) #逻辑型向量
注意:
-
单个向量中的数据必须拥有相同的类型或模式(数值型、字符型或逻辑型)。同一向量中无法混杂不同模式的数据。
-
标量是只含一个元素的向量
- 例如f <- 3、g <- "US"和h <- TRUE。它们用于保存常量。
通过在方括号中给定元素所处位置的数值,我们可以访问向量中的元素。
例如,a[c(2, 4)]用于访问向量a中的第二个和第四个元素。
> a <- c("k", "j", "h", "a", "c", "m")
> a[3]
[1] "h"
> a[c(1, 3, 5)]
[1] "k" "h" "c"
> a[2:6]
[1] "j" "h" "a" "c" "m"
最后一个语句中使用的冒号用于生成一个数值序列。例如,a <- c(2:6)等价于a <- c(2, 3, 4, 5, 6)。
2.2.2 矩阵
矩阵是一个二维数组,只是每个元素都拥有相同的模式(数值型、字符型或逻辑型)。
可通过函数matrix()创建矩阵。一般使用格式为:
myymatrix <- matrix(vector, nrow=number_of_rows, ncol=number_of_columns, byrow=logical_value, dimnames=list(char_vector_rownames, char_vector_colnames))
- 其中vector包含了矩阵的元素,nrow和ncol用以指定行和列的维数,
- dimnames包含了可选的、以字符型向量表示的行名和列名。
- 选项byrow则表明矩阵应当按行填充(byrow=TRUE)还是按列填充(byrow=FALSE),默认情况下按列填充。
示例:
> y <- matrix(1:20, nrow=5, ncol=4)
> y
[,1] [,2] [,3] [,4]
[1,] 1 6 11 16
[2,] 2 7 12 17
[3,] 3 8 13 18
[4,] 4 9 14 19
[5,] 5 10 15 20
> cells <- c(1,26,24,68)
> rnames <- c("R1", "R2")
> cnames <- c("C1", "C2")
> mymatrix <- matrix(cells, nrow=2, ncol=2, byrow=TRUE,
dimnames=list(rnames, cnames)) #按行填充
> mymatrix
C1 C2
R1 1 26
R2 24 68
> mymatrix <- matrix(cells, nrow=2, ncol=2, byrow=FALSE,
dimnames=list(rnames, cnames)) #按列填充
> mymatrix
C1 C2
R1 1 24
R2 26 68
我们可以使用下标和方括号来选择矩阵中的行、列或元素。
X[i,]指矩阵X中的第i行,X[,j]指第j列,X[i, j]指第i行第j 个元素。选择多行或多列时,下标i和j可为数值型向量。
> x <- matrix(1:10, nrow=2)
> x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> x[2,]
[1] 2 4 6 8 10
> x[,2]
[1] 3 4
> x[1,4]
[1] 7
> x[1, c(4,5)]
[1] 7 9
2.2.3 数组
数组(array)与矩阵类似,但是维度可以大于2。数组可通过array函数创建,形式如下:
myarray <- array(vector, dimensions, dimnames)
-
其中vector包含了数组中的数据,
-
dimensions是一个数值型向量,给出了各个维度下标的最大值,
-
而dimnames是可选的、各维度名称标签的列表。
一个创建三维(2×3×4)数值型数组示例:
> dim1 <- c("A1", "A2")
> dim2 <- c("B1", "B2", "B3")
> dim3 <- c("C1", "C2", "C3", "C4")
> z <- array(1:24, c(2, 3, 4), dimnames=list(dim1, dim2, dim3))
> z
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24
从数组中选取元素的方式与矩阵相同。
2.2.4 数据框
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。
数据框是在R中最常处理的数据结构。
数据框可通过函数data.frame()创建:
mydata <- data.frame(col1, col2, col3,...)
其中的列向量col1、col2、col3等可为任何类型(如字符型、数值型或逻辑型)。每一列的名称可由函数names指定。
> patientID <- c(1, 2, 3, 4)
> age <- c(25, 34, 28, 52)
> diabetes <- c("Type1", "Type2", "Type1", "Type1")
> status <- c("Poor", "Improved", "Excellent", "Poor")
> patientdata <- data.frame(patientID, age, diabetes, status)
> patientdata
patientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
由于数据框与分析人员通常设想的数据集的形态较为接近,在讨论数据框时将交替使用术语列和变量。
选取数据框中元素的方式有若干种。你可以使用前述(如矩阵中的)下标记号,亦可直接指定列名。
> patientdata[1:2]
patientID age
1 1 25
2 2 34
3 3 28
4 4 52
> patientdata[c("diabetes", "status")]
diabetes status
1 Type1 Poor
2 Type2 Improved
3 Type1 Excellent
4 Type1 Poor
> patientdata$age➊
[1] 25 34 28 52
第三个例子中的记号$是新出现的➊。它被用来选取一个给定数据框中的某个特定变量。
例如,如果你想生成糖尿病类型变量diabetes和病情变量status的列联表,使用以下代码即可:
> table(patientdata$diabetes, patientdata$status)
Excellent Improved Poor
Type1 1 0 2
Type2 0 1 0
可以联合使用函数attach()和detach()或单独使用函数with()来简化代码。
1. attach()、detach()和with()
函数attach()可将数据框添加到R的搜索路径中。R在遇到一个变量名以后,将检查搜索路径中的数据框。
以第1章中的mtcars数据框为例,可以使用以下代码获取每加仑行驶英里数(mpg)变量的描述性统计量,并分别
绘制此变量与发动机排量(disp)和车身重量(wt)的散点图:
summary(mtcars$mpg)
plot(mtcars$mpg, mtcars$disp)
plot(mtcars$mpg, mtcars$wt)
以上代码也可写成:
attach(mtcars)
summary(mpg)
plot(mpg, disp)
plot(mpg, wt)
detach(mtcars) #函数detach()将数据框从搜索路径中移除,detach()并不会对数据框本身做任何处理
当名称相同的对象不止一个时,会出现以下情况:
> mpg <- c(25, 36, 47)
> attach(mtcars)
The following object(s) are masked _by_ '.GlobalEnv': mpg
> plot(mpg, wt)
Error in xy.coords(x, y, xlabel, ylabel, log) : 'x' and 'y' lengths differ
> mpg
[1] 25 36 47
这里,在数据框mtcars被绑定(attach)之前,你们的环境中已经有了一个名为mpg的对象。
**在这种情况下,原始对象将取得优先权,**这与想要的结果有所出入。由于mpg中有3个元素而disp中有32个元素,
故plot语句出错。函数attach()和detach()最好在你分析一个单独的数据框,并且不太可能有多个同名对象时使
用。任何情况下,都要当心那些告知某个对象已被屏蔽(masked)的警告。
除此之外,另一种方式是使用函数with()。可以这样重写上例:
with(mtcars, {
print(summary(mpg))
plot(mpg, disp)
plot(mpg, wt)
})
在这种情况下,花括号{}之间的语句都针对数据框mtcars执行,这样就无需担心名称冲突了。
如果仅有一条语句(例如summary(mpg)),那么花括号{}可以省略。
函数with()的局限性在于,赋值仅在此函数的括号内生效:
> with(mtcars, {
stats <- summary(mpg)
stats
})
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.40 15.43 19.20 20.09 22.80 33.90
> stats
Error: object 'stats' not found
如果需要创建在with()结构以外存在的对象,使用特殊赋值符<<-替代标准赋值符(<-)即可,它可将对象保存到
with()之外的全局环境中。
> with(mtcars, {
nokeepstats <- summary(mpg)
keepstats <<- summary(mpg)
})
> nokeepstats
Error: object 'nokeepstats' not found
> keepstats
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.40 15.43 19.20 20.09 22.80 33.90
2. 实例标识符
在病例数据中,病人编号(patientID)用于区分数据集中不同的个体。
在R中,实例标识符(case identifier)可通过数据框操作函数中的rowname选项指定。例如,语句:
patientdata <- data.frame(patientID, age, diabetes,
status, row.names=age)
> patientdata
patientID age diabetes status
25 1 25 Type1 Poor
34 2 34 Type2 Improved
28 3 28 Type1 Excellent
52 4 52 Type1 Poor
将patientID指定为R中标记各类打印输出和图形中实例名称所用的变量。
2.2.5 因子
变量可归结为名义型、有序型或连续型变量。
名义型变量是没有顺序之分的类别变量。
糖尿病类型Diabetes(Type1、Type2)是名义型变量的一例。
即使在数据中Type1编码为1而Type2编码为2,这也并不意味着二者是有序的。
有序型变量表示一种顺序关系,而非数量关系。
病情Status(poor、improved、excellent)是顺序型变量的一个上佳示例。
我们明白,病情为poor(较差)病人的状态不如improved(病情好转)的病人,但并不知道相差多少。
连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量。
年龄Age就是一个连续型变量,它能够表示像14.5或22.8这样的值以及其间的其他任意值。
很清楚,15岁的人比14岁的人年长一岁。
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。
- 因子在R中非常重要,因为它决定了数据的分析方式以及如何进行视觉呈现。
函数factor()以一个整数向量的形式存储类别值,整数的取值范围是[1…k](其中k是名义型变量中唯一值的个
数),同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
例如:
diabetes <- c("Type1", "Type2", "Type1", "Type1")
diabetes <- factor(diabetes)
语句diabetes <- factor(diabetes)将此向量存储为(1, 2, 1, 1),并在内部将其关联为1=Type1和2=Type2(具体赋值根据字母顺序而定)。
针对向量diabetes进行的任何分析都会将其作为名义型变量对待,并自动选择适合这一测量尺度的统计方法。
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE。给定向量:
status <- c("Poor", "Improved", "Excellent", "Poor")
status <- factor(status, ordered=TRUE)
语句status <- factor(status, ordered=TRUE)会将向量编码为(3, 2, 1, 3),并在内部将这些值关联为1=Excellent、
2=Improved以及3=Poor。
另外,针对此向量进行的任何分析都会将其作为有序型变量对待,并自动选择合适的统计方法。
出现问题:
对于字符型向量,因子的水平默认依字母顺序创建。
这对于因子status是有意义的,因为“Excellent”“Improved”“Poor”的排序方式恰好与逻辑顺序相一致。
如果“Poor”被编码为“Ailing”,会有问题,因为顺序将为“Ailing”“Excellent”“Improved”。
如果理想中的顺序是“Poor” “Improved”“Excellent”,则会出现类似的问题。
- 按默认的字母顺序排序的因子很少能够让人满意。
这种情况下,可以通过指定levels选项来覆盖默认排序。例如:
status <- factor(status, order=TRUE, levels=c("Poor", "Improved", "Excellent"))
各水平的赋值将为1=Poor、2=Improved、3=Excellent。
注意:
请保证指定的水平与数据中的真实值相匹配,因为任何在数据中出现而未在参数中列举的数据都将被设为缺失值。
数值型变量可以用levels和labels参数来编码成因子。如果男性被编码成1,女性被编码成2,则以下语句:
sex <- factor(sex, levels=c(1, 2), labels=c("Male", "Female"))
把变量转换成一个无序因子。注意到标签的顺序必须和水平相一致。
在这个例子中,性别将被当成类别型变量,标签“Male”和“Female”将替代1和2在结果中输出,而且所有不是1或2
的性别变量将被设为缺失值。
普通因子和有序因子的不同如何影响数据分析:
#以向量形式输入数据
> patientID <- c(1, 2, 3, 4)
> age <- c(25, 34, 28, 52)
> diabetes <- c("Type1", "Type2", "Type1", "Type1")
> status <- c("Poor", "Improved", "Excellent", "Poor")
> diabetes <- factor(diabetes)
> status <- factor(status, order=TRUE)
> patientdata <- data.frame(patientID, age, diabetes, status)
> str(patientdata) #显示对象的结构
‘data.frame’: 4 obs. of 4 variables:
$ patientID: num 1 2 3 4
$ age : num 25 34 28 52
$ diabetes : Factor w/ 2 levels "Type1","Type2": 1 2 1 1
$ status : Ord.factor w/ 3 levels "Excellent"<"Improved"<..: 3 2 1 3
> summary(patientdata) #显示对象的统计概要
patientID age diabetes status
Min. :1.00 Min. :25.00 Type1:3 Excellent:1
1st Qu.:1.75 1st Qu.:27.25 Type2:1 Improved :1
Median :2.50 Median :31.00 Poor :2
Mean :2.50 Mean :34.75
3rd Qu.:3.25 3rd Qu.:38.50
Max. :4.00 Max. :52.00
函数str(object)可提供R中某个对象(本例中为数据框)的信息。
- 它清楚地显示diabetes是一个因子,而status是一个有序型因子,以及此数据框在内部是如何进行编码的。
函数summary()会区别对待各个变量。
- 它显示了连续型变量age的最小值、最大值、均值和各四分位数,并显示了类别型变量diabetes和status(各水平)的频数值。
2.2.6 列表
列表(list)是R的数据类型中最为复杂的一种。一般来说,列表就是一些对象(或成分,component)的有序集
合。
列表允许你整合若干(可能无关的)对象到单个对象名下。某个列表中可能是若干向量、矩阵、数据框,甚至其他
列表的组合。
可以使用函数list()创建列表:
mylist <- list(object1, object2, ...)
还可以为列表中的对象命名:
mylist <- list(name1=object1, name2=object2, ...)
示例:
> g <- "My First List"
> h <- c(25, 26, 18, 39)
> j <- matrix(1:10, nrow=5)
> k <- c("one", "two", "three")
> mylist <- list(title=g, ages=h, j, k)
> mylist
$title
[1] "My First List"
$ages
[1] 25 26 18 39
[[3]]
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
[[4]]
[1] "one" "two" "three"
> mylist[[2]] #访问第二个元素
[1] 25 26 18 39
> mylist[["ages"]] #访问第二个元素
[[1] 25 26 18 39
本例创建了一个列表,其中有四个成分:一个字符串、一个数值型向量、一个矩阵以及一个字符型向量。
- 可以组合任意多的对象,并将它们保存为一个列表。
可以通过在双重方括号中指明代表某个成分的数字或名称来访问列表中的元素。
- 此例中,mylist[[2]]和mylist[[“ages”]]均指那个含有四个元素的向量。
- 对于命名成分,mylist$ages也可以正常运行。
由于两个原因,列表成为了R中的重要数据结构。
-
首先,列表允许以一种简单的方式组织和重新调用不相干的信息。
-
其次,许多R函数的运行结果都是以列表的形式返回的。需要取出其中哪些成分由分析人员决定。
R语言特性:
❑对象名称中的句点(.)没有特殊意义,但美元符号($)却有着和其他语言中的句点类似的含义,
即指定一个数据框或列表中的某些部分。
例如,A$x是指数据框A中的变量x。
❑R不提供多行注释或块注释功能。
必须以#作为多行注释每行的开始。出于调试目的,
也可以把想让解释器忽略的代码放到语句if(FALSE){... }中。将FALSE改为TRUE 即允许这块代码执行。
❑将一个值赋给某个向量、矩阵、数组或列表中一个不存在的元素时,R将自动扩展这个
数据结构以容纳新值。举例来说,考虑以下代码:
> x <- c(8, 6, 4)
> x[7] <- 10
> x
[1] 8 6 4 NA NA NA 10
通过赋值,向量x由三个元素扩展到了七个元素。x <- x[1:3]会重新将其缩减回三个元素。
❑R中没有标量。标量以单元素向量的形式出现。
❑R中的下标不从0开始,而从1开始。在上述向量中,x[1]的值为8。 ❑变量无法被声明。它们在首次被赋值时生成。
2.3 数据的输入
R可从键盘、文本文件、Microsoft Excel和Access、流行的统计软件、特殊格式的文件、多种关系型数据库管理系
统、专业数据库、网站和在线服务中导入数据。
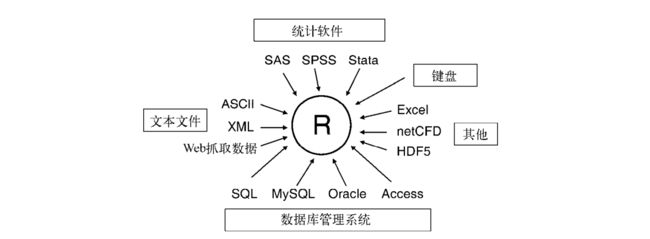
2.3.1 使用键盘输入数据
输入数据最简单的方式就是使用键盘。
有两种常见的方式:用R内置的文本编辑器和直接在代码中嵌入数据。
首先考虑文本编辑器。
R中的函数edit()会自动调用一个允许手动输入数据的文本编辑器。具体步骤如下:
-
(1) 创建一个空数据框(或矩阵),其中变量名和变量的模式需与理想中的最终数据集一致;
-
(2) 针对这个数据对象调用文本编辑器,输入你的数据,并将结果保存回此数据对象中。
在下例中,将创建一个名为mydata的数据框,它含有三个变量:age(数值型)、gender(字符型)和
weight(数值型)。然后调用文本编辑器,键入数据,最后保存结果。
mydata <- data.frame(age=numeric(0),
gender=character(0), weight=numeric(0))
mydata <- edit(mydata)
类似于age=numeric(0)的赋值语句将创建一个指定模式但不含实际数据的变量。
注意,编辑的结果需要赋值回对象本身。函数edit()事实上是在对象的一个副本上进行操作的。
如果不将其赋值到一个目标,所有修改将会全部丢失!
在Windows上调用函数edit()的结果如图所示:
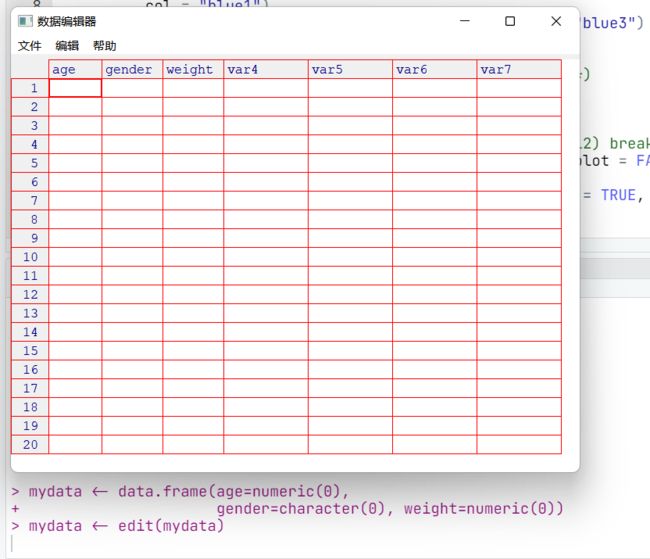
单击列的标题,就可以用编辑器修改变量名和变量类型(数值型、字符型)。还可以通过单击未使用列的标题来添
加新的变量。
编辑器关闭后,结果会保存到之前赋值的对象中(本例中为mydata)。再次调用mydata <- edit(mydata),就能
够编辑已经输入的数据并添加新的数据。
语句mydata <- edit(mydata)的一种简捷的等价写法是fix(mydata)。
此外,可以直接在你的程序中嵌入数据集:
mydatatxt <- "
age gender weight
25 m 166
30 f 115
18 f 120
"
mydata <- read.table(header=TRUE, text=mydatatxt)
以上代码创建了和之前用edit()函数所创建的一样的数据框。
- 一个字符型变量被创建于存储原始数据
- read.table()函数被用于处理字符串并返回数据框
键盘输入数据的方式在你在处理小数据集的时候很有效。
2.3.2 从带分隔符的文本文件导入数据
可以使用read.table()从带分隔符的文本文件中导入数据。
此函数可读入一个表格格式的文件并将其保存为一个数据框。表格的每一行分别出现在文件中每一行。
mydataframe <- read.table(file, options)
其中,file是一个带分隔符的ASCII文本文件,options是控制如何处理数据的选项。常见的选项如下:
header #一个表示文件是否在第一行包含了变量名的逻辑型变量
sep #分开数据值的分隔符。默认是sep="",这表示了一个或多个空格、制表符、换行或回车。
#使用sep=","来读取用逗号来分隔行内数据的文件,使用sep="\t"来读取使用制表符来分割行内数据的文件
row.names #一个用于指定一个或多个行标记符的可选参数
col.names #如果数据文件的第一行不包括变量名(header=FASLE),可以用col.names去指定一个包含变量名的字符向量。如果header=FALSE以及col.names选项被省略了,变量会被分别命名为V1、V2,以此类推
na.strings #可选的用于表示缺失值的字符向量。比如说,na.strings=c("-9", "?")把-9 和?值在读取数据的时候转换成 NA
colClasses #可选的分配到每一列的类向量。比如说,colClasses=c("numeric", "numeric","character", "NULL", "numeric")把前两列读取为数值型变量,把第三列读取为字符型向量,跳过第四列,把第五列读取为数值型向量。如果数据有多余五列,colClasses 的值会被循环。当你在读取大型文本文件的时候,加上 colClasses 选项可以可观地提升处理的速度
quote #用于对有特殊字符的字符串划定界限的自负床。默认值是双引号(")或单引号(')
skip #读取数据前跳过的行的数目。这个选项在跳过头注释的时候比较有用
stringsAsFactors #一个逻辑变量,标记处字符向量是否需要转化成因子。默认值是 TRUE,除非它被 colClases所覆盖。当你在处理大型文本文件的时候,设置成 stringsAsFactors=FALSE 可以提升处理速度
text #一个指定文字进行处理的字符串。如果 text 被设置了,file 应该被留空。
考虑一个名为studentgrades.csv的文本文件,它包含了学生在数学、科学、和社会学习的分数。
文件中每一行表示一个学生,第一行包含了变量名,用逗号分隔。每一个单独的行都包含了学生的信息,它们也是
用逗号进行分隔的。文件的前几行如下:
StudentID,First,Last,Math,Science,Social Studies
011,Bob,Smith,90,80,67
012,Jane,Weary,75,,80
010,Dan,"Thornton, III",65,75,70
040,Mary,"O'Leary",90,95,92
这个文件可以用以下语句来读入成一个数据框:
grades <- read.table("studentgrades.csv", header=TRUE, row.names="StudentID", sep=",")
> grades
First Last Math Science Social.Studies
11 Bob Smith 90 80 67
12 Jane Weary 75 NA 80
10 Dan Thornton, III 65 75 70
40 Mary O'Leary 90 95 92
> str(grades)
'data.frame': 4 obs. of 5 variables:
$ First : Factor w/ 4 levels "Bob","Dan","Jane",..: 1 3 2 4
$ Last : Factor w/ 4 levels "O'Leary","Smith",..: 2 4 3 1
$ Math : int 90 75 65 90
$ Science : int 80 NA 75 95
$ Social.Studies: int 67 80 70 92
变量名Social Studies被自动地根据R的习惯所重命名。
列StudentID现在是行名,不再有标签,也失去了前置的0。
Jane的缺失的科学课成绩被正确地识别为缺失值。
在Dan的姓周围用引号包围住,从而能够避免Thornton和III之间的空格。否则,R会在那一行读出七个值而不是六个值。
也在O’Leary左右用引号包围住了,负载R会把单引号读取为分隔符。
最后,姓和名都被转化成为因子。
默认地,read.table()把字符变量转化为因子。
很少情况下,我们才会把回答者的评论转化成为因子。可用多种方法去掉这个行为。
- 加上选项stringsAsFactors=FALSE对所有的字符变量都去掉这个行为。
此外,你可以用colClasses选项去对每一列都指定一个类(比如说,逻辑型、数值型、字符型或因子型):
grades <- read.table("studentgrades.csv", header=TRUE, row.names="StudentID", sep=",",
colClasses=c("character", "character", "character", "numeric", "numeric", "numeric"))
> grades
First Last Math Science Social.Studies
011 Bob Smith 90 80 67
012 Jane Weary 75 NA 80
010 Dan Thornton, III 65 75 70
040 Mary O'Leary 90 95 92
> str(grades)
'data.frame': 4 obs. of 5 variables:
$ First : chr "Bob" "Jane" "Dan" "Mary"
$ Last : chr "Smith" "Weary" "Thornton, III" "O'Leary"
$ Math : num 90 75 65 90
$ Science : num 80 NA 75 95
$ Social.Studies: num 67 80 70 92
**注意:**行名保留了前缀0,而且First和Last不再是因子。此外,grades作为实数而不是整数来进行排序。
2.3.3 导入 Excel 数据
读取一个Excel文件的最好方式,就是在Excel中将其导出为一个逗号分隔文件(csv),并使用前文描述的方式将其导入R中。
此外,你可以用xlsx包直接地导入Excel工作表。
- 请确保在第一次使用它之前先进行下载和安装。
- 也需要xlsxjars和rJava包,以及一个正常工作的Java安装(http://java.com)。
xlsx包可以用来对Excel 97/2000/XP/2003/2007文件进行读取、写入和格式转换。
函数read.xlsx()导入一个工作表到一个数据框中。最简单的格式是read.xlsx(file, n)
- 其中file是Excel工作簿的所在路径,n则为要导入的工作表序号。
library(xlsx)
workbook <- "c:/myworkbook.xlsx"
mydataframe <- read.xlsx(workbook, 1)
2…3.4 导入 SPSS 数据
IBM SPSS数据集
- 可以通过foreign包中的函数read.spss()导入到R中
- 也可以使用Hmisc包中的spss.get()函数。
- 函数spss.get()是对read.spss()的一个封装,它可以为你自动设置后者的许多参数,让整个转换过程更加简单一致,最后得到数据分析人员所期望的结果。
首先,下载并安装Hmisc包(foreign包已被默认安装):
载入需要的程辑包:lattice
载入需要的程辑包:survival
载入需要的程辑包:Formula
载入需要的程辑包:ggplot2
library(lattice)
library(survival)
library(Formula)
library(ggplot2)
install.packages("Hmisc")
library(Hmisc)
mydataframe <- spss.get("mydata.sav", use.value.labels=TRUE)
-
mydata.sav是要导入的SPSS数据文件
-
use.value.labels=TRUE表示让函数将带有值标签的变量导入为R中水平对应相同的因子
-
mydataframe是导入后的R数据框。
2.3.5 导入 Stata 数据
library(foreign)
mydataframe <- read.dta("mydata.dta")
mydata.dta是Stata数据集,mydataframe是返回的R数据框。
2.4 数据集的标注
为了使结果更易解读,数据分析人员通常会对数据集进行标注。
这种标注包括为变量名添加描述性的标签,以及为类别型变量中的编码添加值标签。
- 例如,对于变量age,你可能想附加一个描述更详细的标签“Age at hospitalization (in years)”(入院年龄)。
对于编码为1或2的性别变量gender,你可能想将其关联到标签“male”和“female”上。
2.4.1 变量标签
R处理变量标签的能力有限。一种解决方法是将变量标签作为变量名,然后通过位置下标来访问这个变量。
考虑之前病例数据框的例子。名为age的第二列包含着个体首次入院时的年龄。代码:
names(patientdata)[2] <- "Age at hospitalization (in years)"
将age重命名为"Age at hospitalization (in years)"。
很明显,新的变量名太长,不适合重复输入。作为替代,你可以使用patientdata[2]来引用这个变量,而在本应输
出age的地方输出字符串"Age at hospitalization (in years)"。很显然,这个方法并不理想。
2.4.2 值标签
函数factor()可为类别型变量创建值标签。继续上例,假设你有一个名为gender的变量,其中1表示男性,2表示女
性。你可以使用代码:
patientdata$gender <- factor(patientdata$gender, levels = c(1,2), labels = c("male", "female"))
来创建值标签。这里levels代表变量的实际值,而labels表示包含了理想值标签的字符型向量。
2.5 处理数据对象的实用函数
length(object) #显示对象中元素/成分的数量
dim(object) #显示某个对象的维度
str(object) #显示某个对象的结构
class(object) #显示某个对象的类或类型
mode(object) #显示某个对象的模式
names(object) #显示某对象中各成分的名称
c(object, object,...) #将对象合并入一个向量
cbind(object, object, ...) #按列合并对象
rbind(object, object, ...) #按行合并对象
object #输出某个对象
head(object) #列出某个对象的开始部分
tail(object) #列出某个对象的最后部分
ls() #显示当前的对象列表
rm(object, object, ...)
#删除一个或更多个对象。语句rm(list = ls())将删除当前工作环境中的几乎所有对象
newobject <- edit(object) #编辑对象并另存为 newobject
fix(object) #直接编辑对象
函数head()和tail()对于快速浏览大数据集的结构非常有用。
例如,head(patientdata)将列出数据框的前六行,而tail(patientdata)将列出最后六行。
三、图形初阶
3.1 使用图形
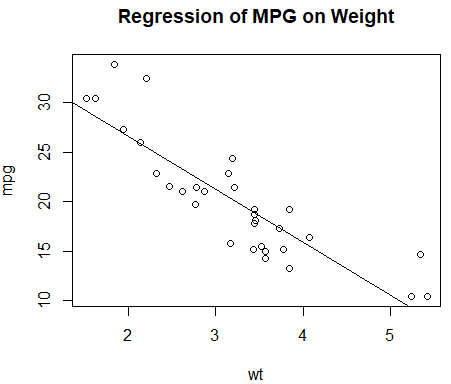
attach(mtcars)
plot(wt, mpg) #横轴表示车身重量,纵轴为每加仑汽油行驶的英里数。
abline(lm(mpg~wt)) #向图形添加了一条最优拟合曲线
title("Regression of MPG on Weight") #添加了标题
detach(mtcars)
将图形保存到当前工作目录中名为mygraph.pdf的PDF文件中:
pdf("mygraph.pdf")
attach(mtcars)
plot(wt, mpg)
abline(lm(mpg~wt))
title("Regression of MPG on Weight")
detach(mtcars)
dev.off()
除了pdf(),还可以使用函数win.metafile()、png()、jpeg()、bmp()、tiff()、xfig()和postscript()将图形保存为其他格式。
通过执行如plot()、hist()(绘制直方图)或boxplot()这样的高级绘图命令来创建一幅新图形时,通常会覆盖掉先前
的图形。如何才能创建多个图形并随时查看每一个:
- 第一种方法,可以在创建一幅新图形之前打开一个新的图形窗口:
dev.new()
statements to create graph 1
dev.new()
statements to create a graph 2
etc.
每一幅新图形将出现在最近一次打开的窗口中。
- 第二种方法,可以通过图形用户界面来查看多个图形:
在Windows上,这个过程分为两步:
在打开第一个图形窗口以后,勾选“历史”(History)→“记录”(Recording);
然后使用菜单中的“上一个”(Previous)和“下一个”(Next)来逐个查看已经绘制的图形。
3.2 绘图实例
给出的假想数据集描述了病人对两种药物五个剂量水平上的响应情况:

dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
plot(dose, drugA, type="b")
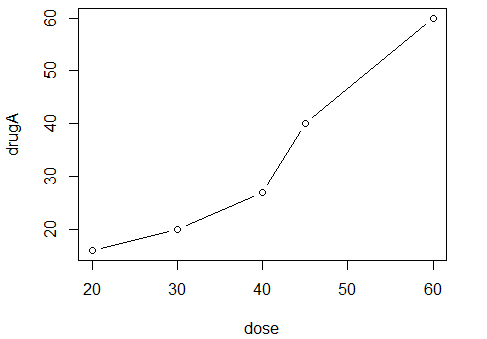
plot()是R中为对象作图的一个泛型函数(它的输出将根据所绘制对象类型的不同而变化)。
plot(x, y, type=“b”)将x置于横轴,将y置于纵轴,绘制点集(x, y),然后使用线段将其连接。
选项type="b"表示同时绘制点和线。使用help(plot)可以查看其他选项。
3.3 图形参数
可以通过修改称为图形参数的选项来自定义一幅图形的多个特征(字体、颜色、坐标轴、标签)。
- 一种方法是通过函数par()来指定这些选项。
以这种方式设定的参数值除非被再次修改,否则将在会话结束前一直有效。
其调用格式为:
par(optionname=value, optionname=name,...)
不加参数地执行par()将生成一个含有当前图形参数设置的列表。
添加参数no.readonly=TRUE可以生成一个可以修改的当前图形参数列表。
继续我们的例子,假设你想使用实心三角而不是空心圆圈作为点的符号,并且想用虚线代替实线连接这些点:
opar <- par(no.readonly=TRUE) #复制了一份当前的图形参数设置
par(lty=2, pch=17)
#将默认的线条类型修改为虚线(lty=2),并将默认的点符号改为了实心三角(pch=17)
plot(dose, drugA, type="b")
par(opar)
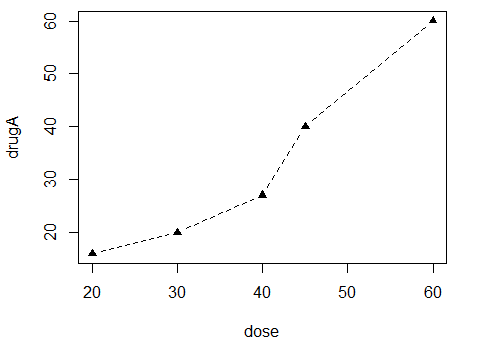
par(lty=2, pch=17)
#也可以写成:
par(lty=2)
par(pch=17)
-
第二种方法是为高级绘图函数直接提供optionname=value的键值对。这种情况下,指定的选项仅对这幅图形
本身有效:
plot(dose, drugA, type="b", lty=2, pch=17)
!!!注意:
并不是所有的高级绘图函数都允许指定全部可能的图形参数。
你需要参考每个特定绘图函数的帮助(如?plot、?hist或?boxplot)以确定哪些参数可以以这种方式设置。
3.3.1 符号和线条
可以使用图形参数来指定绘图时使用的符号和线条类型。相关参数如下所示:
pch #指定绘制点时使用的符号
cex #指定符号的大小。cex 是一个数值,表示绘图符号相对于默认大小的缩放倍数。默认大小为1,1.5表示放大为默认值的1.5倍,0.5表示缩小为默认值的50%等等
lty #指定线条类型
lwd #指定线条宽度。lwd 是以默认值的相对大小来表示的(默认值为 1)。例如,lwd=2将生成一条两倍于默认宽度的线条
选项pch=用于指定绘制点时使用的符号。可能的值如图所示:

对于符号21~25,你还可以指定边界颜色(col=)和填充色(bg=)。
选项lty=用于指定想要的线条类型。可用的值如图所示:

plot(dose, drugA, type="b", lty=4, lwd=3, pch=11, cex=2)

3.3.2 颜色
R中有若干和颜色相关的参数。常用参数如下:
col #默认的绘图颜色。某些函数(如lines和pie)可以接受一个含有颜色值的向量并自动循环使用。例如,如果设定col=c("red", "blue")并需要绘制三条线,则第一条线将为红色,第二条线为蓝色,第三条线又将为红色
col.axis #坐标轴刻度文字的颜色
col.lab #坐标轴标签(名称)的颜色
col.main #标题颜色
col.sub #副标题颜色
fg #图形的前景色
bg #图形的背景色
在R中,可以通过颜色下标、颜色名称、十六进制的颜色值、RGB值或HSV值来指定颜色:
col=1
col="white"
col="#FFFFFF"
col=rgb(1,1,1)
col=hsv(0,0,1)
函数rgb()可基于红-绿-蓝三色值生成颜色,而hsv()则基于色相-饱和度-亮度值来生成颜色。
函数colors()可以返回所有可用颜色的名称。
R中也有多种用于创建连续型颜色向量 的函数:
rainbow()
heat.colors()
terrain.colors()
topo.colors()
cm.colors()
例如:rainbow(10)可以生成10种连续的“彩虹型”颜色。
对于创建吸引人的颜色配对,RColorBrewer特别受到欢迎。
注意在第一次使用它之前先进行下载(install.packages(“RColorBrewer”))。安装之后,使用函数brewer.pal(n,
name)来创建一个颜色值的向量。比如说,以下代码:
library(RColorBrewer)
n <- 7
mycolors <- brewer.pal(n, "Set1")
barplot(rep(1,n), col=mycolors)

从Set1调色板中抽取了7种用十六进制表示的颜色并返回一个向量。
若要得到所有可选调色板的列表,输入brewer.pal.info;或者输入display.brewer.all()从而在一个显示输出中产生
每个调色板的图形。

最后,多阶灰度色可使用基础安装所自带的gray()函数生成。
这时要通过一个元素值为0和 1之间的向量来指定各颜色的灰度。gray(0:10/10)将生成10阶灰度色。
n <- 10
mycolors <- rainbow(n)
pie(rep(1, n), labels=mycolors, col=mycolors)
mygrays <- gray(0:n/n)
pie(rep(1, n), labels=mygrays, col=mygrays)

3.3.3 文本属性
图形参数同样可以用来指定字号、字体和字样。下表阐释了用于控制文本大小的参数。字体族和字样可以通过字体
选项进行控制。
cex #表示相对于默认大小缩放倍数的数值。默认大小为1,1.5表示放大为默认值的1.5倍,0.5表示缩小为默认值的 50%等等
cex.axis #坐标轴刻度文字的缩放倍数。类似于cex
cex.lab #坐标轴标签(名称)的缩放倍数。类似于cex
cex.main #标题的缩放倍数。类似于cex
cex.sub #副标题的缩放倍数。类似于cex
font #整数。用于指定绘图使用的字体样式。1=常规,2=粗体,3=斜体,4=粗斜体,5=符号字体(以Adobe符号编码表示)
font.axis #坐标轴刻度文字的字体样式
font.lab #坐标轴标签(名称)的字体样式
font.main #标题的字体样式
font.sub #副标题的字体样式
ps #字体磅值(1 磅约为 1/72 英寸)。文本的最终大小为ps*cex
family #绘制文本时使用的字体族。标准的取值为 serif(衬线)、sans(无衬线)和 mono(等宽)
par(font.lab=3, cex.lab=1.5, font.main=4, cex.main=2)
#创建的所有图形都将拥有斜体、1.5倍于默认文本大小的坐标轴标签(名称),以及粗斜体、2倍于默认文本大小的标题
我们可以轻松设置字号和字体样式,然而字体族的设置却稍显复杂。
这是因为衬线、无衬线和等宽字体的具体映射是与图形设备相关的。
举例来说,在Windows系统中,等宽字体映射为TT Courier New,衬线字体映射为TT Times New Roman,无衬
线字体则映射为TT Arial(TT代表True Type)。如果你对以上映射表示满意,就可以使用类似于family="serif"这
样的参数获得想要的结果。如果不满意,则需要创建新的映射。
在Windows中,可以通过函数windowsFont()来创建这类映射。
例如,在执行语句:
windowsFonts(
A=windowsFont("Arial Black"),
B=windowsFont("Bookman Old Style"),
C=windowsFont("Comic Sans MS")
)
之后,即可使用A、B和C作为family的取值。
在本例的情境下,par(family=“A”)将指定Arial Black作为绘图字体。
请注意,函数windowsFont()仅在Windows中有效。
如果以PDF或PostScript格式输出图形,则修改字体族会相对简单一些。
-
对于PDF格式,可以使用names(pdfFonts())找出你的系统中有哪些字体是可用的,然后使用
pdf(file= "myplot.pdf", family="fontname")来生成图形。
-
对于以PostScript格式输出的图形,则可以对应地使用names(postscriptFonts())和
postscript(file="myplot.ps", family= "fontname")
3.3.4 图形尺寸与边界尺寸
可以使用如下列出的参数来控制图形尺寸和边界大小:
pin #以英寸表示的图形尺寸(宽和高)
mai #以数值向量表示的边界大小,顺序为“下、左、上、右”,单位为英寸
mar #以数值向量表示的边界大小,顺序为“下、左、上、右”,单位为英分。默认值为c(5, 4, 4, 2) + 0.1
par(pin=c(4,3), mai=c(1,.5, 1, .2))
#可生成一幅4英寸宽、3英寸高、上下边界为1英寸、左边界为0.5英寸、右边界为0.2英寸的图形
综合强化图形:
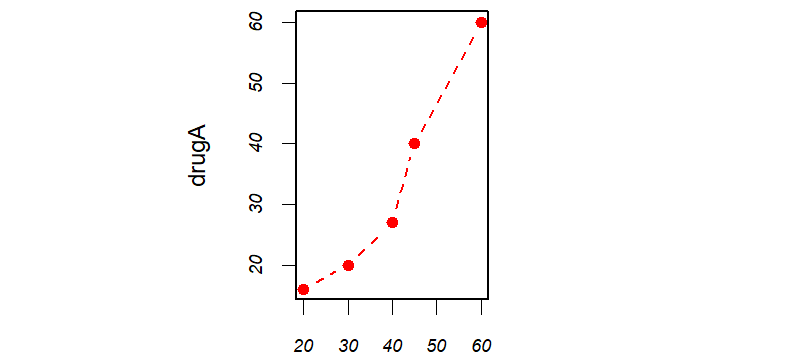
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
opar <- par(no.readonly=TRUE) #保存了当前的图形参数设置
par(pin=c(2, 3)) #修改了默认的图形参数,得到的图形将为2英寸宽、3英寸高
par(lwd=2, cex=1.5) #线条的宽度将为默认宽度的两倍,符号将为默认大小的1.5倍
par(cex.axis=.75, font.axis=3) #坐标轴刻度文本被设置为斜体、缩小为默认大小的75%
plot(dose, drugA, type="b", pch=19, lty=2, col="red")
#使用红色实心圆圈和虚线创建了第一幅图形
plot(dose, drugB, type="b", pch=23, lty=6, col="blue", bg="green")
#使用绿色填充的绿色菱形加蓝色边框和蓝色虚线创建了第二幅图形
par(opar) #还原了初始的图形参数设置
值得注意的是,通过par()设定的参数对两幅图都有效,而在plot()函数中指定的参数仅对那个特定图形有效。
3.4 添加文本、自定义坐标轴和图例
除了图形参数,许多高级绘图函数(例如plot、hist、boxplot)也允许自行设定坐标轴和文本标注选项。
举例来说,以下代码在图形上添加了标题(main)、副标题(sub)、坐标轴标签(xlab、ylab)并指定了坐标轴范围(xlim、ylim):
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
plot(dose, drugA, type="b",
col="red", lty=4, pch=8, lwd=2,
main="Clinical Trials for Drug A", #标题
sub="This is hypothetical data", #副标题
xlab="Dosage", ylab="Drug Response", #坐标轴标签
xlim=c(20, 60), ylim=c(0, 70)) #坐标轴显示范围

**注意!!!**并非所有函数都支持这些选项。
某些高级绘图函数已经包含了默认的标题和标签。
可以通过在plot()语句或单独的par()语句中添加ann=FALSE来移除它们。
3.4.1 标题
可以使用title()函数为图形添加标题和坐标轴标签。调用格式为:
windowsFonts(
A=windowsFont("Arial Black"),
B=windowsFont("Bookman Old Style"),
C=windowsFont("Comic Sans MS") ,
D=windowsFont("Calibri"),
E=windowsFont("JetBrains Mono"),
F=windowsFont("Consolas")
)
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
plot(dose, drugA,type="b",ann=FALSE) #ann=FALSE移除默认的标题和标签
title(main="Clinical Trials for Drug A", col.main="red",
sub="This is hypothetical data",col.sub="blue",
xlab="Dosage", ylab="Drug Response",
col.lab="green",cex.sub=1.25,cex.lab=0.9,family="C")

3.4.2 坐标轴
可以使用函数axis()来创建自定义的坐标轴,而非使用R中的默认坐标轴。其格式为:
axis(side, at=, labels=, pos=, lty=, col=, las=, tck=, ...)
常见参数如下:
side #一个整数,表示在图形的哪边绘制坐标轴(1=下,2=左,3=上,4=右)
at #一个数值型向量,表示需要绘制刻度线的位置
labels #一个字符型向量,表示置于刻度线旁边的文字标签(如果为 NULL,则将直接使用at中的值)
pos #坐标轴线绘制位置的坐标(即与另一条坐标轴相交位置的值)
lty #线条类型
col #线条和刻度线颜色
las #标签是否平行于(=0)或垂直于(=2)坐标轴
tck
#刻度线的长度,以相对于绘图区域大小的分数表示(负值表示在图形外侧,正值表示在图形内侧,0表示禁用刻度,1表示绘制网格线);默认值为–0.01
创建自定义坐标轴时,你应当禁用高级绘图函数自动生成的坐标轴。参数axes=FALSE将禁用全部坐标轴(包括坐
标轴框架线,除非你添加了参数frame.plot=TRUE)。参数xaxt="n"和yaxt="n"将分别禁用X轴或Y轴(会留下框架
线,只是去除了刻度)。
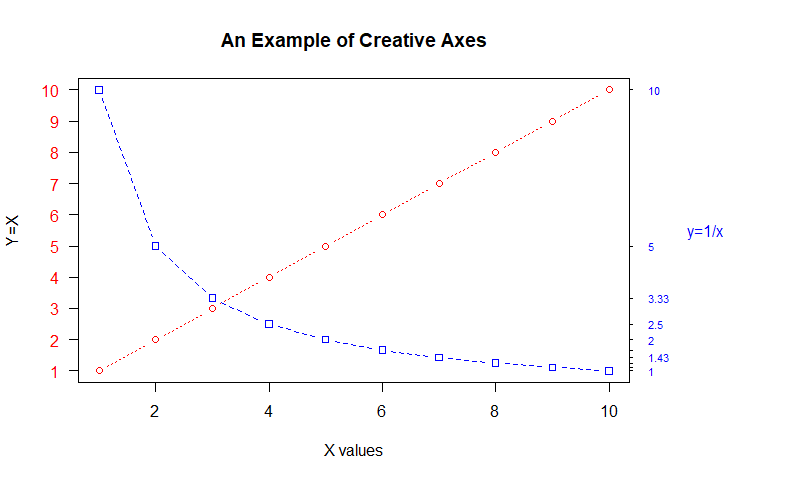
自定义坐标轴实例:
x <- c(1:10)
y <- x
z <- 10/x
opar <- par(no.readonly=TRUE) #添加参数no.readonly=TRUE可以生成一个可以修改的当前图形参数列表
par(mar=c(5, 4, 4, 8) + 0.1)
#绘制x-y关系图
#yaxt="n"Y轴(会留下框架线,只是去除了刻度)
#lty=3,指定线条类型
plot(x, y, type="b",pch=21, col="red", yaxt="n", lty=3, ann=FALSE)
#lines()语句,你可以为一幅现有图形添加新的图形元素
#绘制x-z关系图
lines(x, z, type="b", pch=22, col="blue", lty=2)
#可以使用函数axis()来创建自定义的坐标轴
#2=左,表示在图形的左边绘制坐标轴
#at=x,一个数值型向量,表示需要绘制刻度线的位置
#labels,一个字符型向量,表示置于刻度线旁边的文字标签(如果为 NULL,则将直接使用at中的值)
#las,标签垂直于(=2)坐标轴
axis(2, at=x, labels=x, col.axis="red", las=2)
#tck,刻度线的长度,以相对于绘图区域大小的分数表示(负值表示在图形外侧,正值表示在图形内侧,0表示禁用刻度,1表示绘制网格线);默认值为–0.01
axis(4, at=z, labels=round(z, digits=2), col.axis="blue", las=2, cex.axis=0.7, tck=-.01)
#函数mtext()用于在图形的边界添加文本
#side=4在图形的右边界添加"y=1/x"文本
#cex.lab,坐标轴标签(名称)的缩放倍数
mtext("y=1/x", side=4, line=3, cex.lab=1, las=2, col="blue")
title("An Example of Creative Axes",xlab="X values", ylab="Y=X")
par(opar)
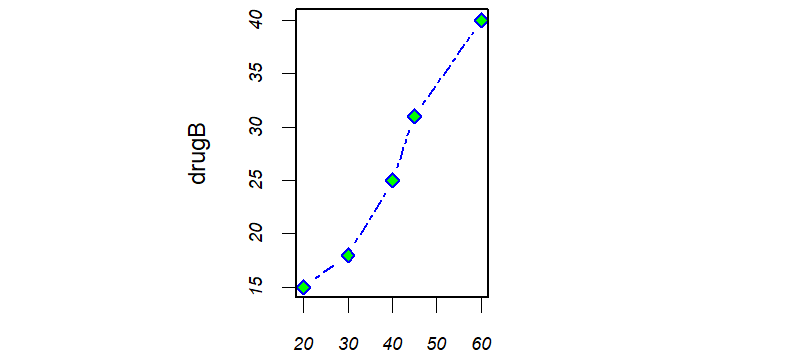
要创建次要刻度线:
你需要使用Hmisc包中的minor.tick()函数。如果你尚未安装Hmisc包,请先安装它(参考
1.4.2节)。你可以使用代码:>library(lattice) > library(survival) > library(Formula) > library(ggplot2) >library(Hmisc) >minor.tick(nx=n, ny=n, tick.ratio=n)其中nx和ny分别指定了X轴和Y轴每两条主刻度线之间通过次要刻度线划分得到的区间个数。
tick.ratio表示次要刻度线相对于主刻度线的大小比例。当前的主刻度线长度可以使用par(“tck”)获取。
举例来说,下列语句将在X轴的每两条主刻度线之间添加1条次要刻度线,并在Y轴的每两条主刻度线之间添加2条次要刻度线:
minor.tick(nx=2, ny=3, tick.ratio=0.5)次要刻度线的长度将是主刻度线的一半。
3.4.3 参考线
函数abline()可以用来为图形添加参考线。其使用格式为:
abline(h=yvalues, v=xvalues)
函数abline()中也可以指定其他图形参数(如线条类型、颜色和宽度)。举例来说:
abline(h=c(1,5,7))
在y为1、5、7的位置添加了水平实线,而代码:
abline(v=seq(1, 10, 2), lty=2, col="blue")
则在x为1、3、5、7、9的位置添加了垂直的蓝色虚线。
3.4.4 图例
当图形中包含的数据不止一组时,图例可以帮助你辨别出每个条形、扇形区域或折线各代表哪一类数据。
我们可以使用函数legend()来添加图例。其使用格式为:
legend(location, title, legend, ...)
常见参数:
location
#有许多方式可以指定图例的位置。你可以直接给定图例左上角的 x、y 坐标,也可以执行locator(1),然后通过鼠标单击给出图例的位置,还可以使用关键字bottom、bottomleft、left、topleft、top、topright、right、bottomright或center放置图例。如果你使用了以上某个关键字,那么可以同时使用参数inset=指定图例向图形内侧移动的大小(以绘图区域大小的分数表示)
title
#图例标题的字符串(可选)
legend
#图例标签组成的字符型向量
… 其他选项。
#如果图例标示的是颜色不同的线条,需要指定 col=加上颜色值组成的向量。如果图例标示的是符号不同的点,则需指定 pch=加上符号的代码组成的向量。如果图例标示的是不同的线条宽度或线条类型,请使用 lwd=或 lty=加上宽度值或类型值组成的向量。要为图例创建颜色填充的盒形(常见于条形图、箱线图或饼图),需要使用参数 fill=加上颜色值组成的向量
其他常用的图例选项包括用于指定盒子样式的bty、指定背景色的bg、指定大小的cex,以及指定文本颜色的
text.col。
指定horiz=TRUE将会水平放置图例,而不是垂直放置。
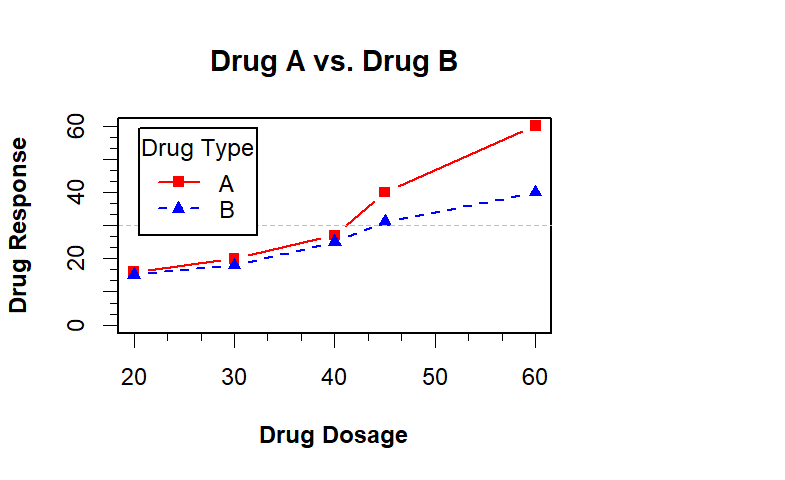
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
opar <- par(no.readonly=TRUE)
par(lwd=2, cex=1.5, font.lab=2)
#does-drugA关系线
#ylim=c(0, 60),y坐标轴范围0-60
plot(dose, drugA, type="b", pch=15, lty=1, col="red", ylim=c(0, 60),
main="Drug A vs. Drug B", xlab="Drug Dosage", ylab="Drug Response")
#does-drugB关系线
#type="b"设置为折线图
lines(dose, drugB, type="b", pch=17, lty=2, col="blue")
#添加参考线
#在y=30的位置绘制参考线
#lwd指定线条宽度
abline(h=c(30), lwd=1.5, lty=2, col="gray")
#绘制次要刻度线
library(Hmisc)
#主刻度线之间区间为3,长度为主刻度线的一半
minor.tick(nx=3, ny=3, tick.ratio=0.5)
#参数 inset=指定图例向图形内侧移动的大小
#legend设置图例,topleft图例设置在左上方,inset=.05图例在边界0.05的地方,
#title设置图例的标题,c("A","B")设置图例中标志的名字,,lty=c(1,2)设置图例一个实线,一个虚线,#pch=c(15,17)设置线中的符号标识一个是矩形,一个是三角形,col=c("red","blue")设置图例中的颜色
legend("topleft",inset=.05,title="DrugType",c("A","B"),lty=c(1,2),
pch=c(15,17),col=c("red","blue"))
par(opar) #回到最原始的默认参数
3.4.5 文本标注
可以通过函数text()和mtext()将文本添加到图形上。text()可向绘图区域内部添加
文本,而mtext()则向图形的四个边界之一添加文本。使用格式分别为:
text(location, "text to place", pos, ...)
mtext("text to place", side, line=n, ...)
常见参数:
location
#文本的位置参数。可为一对x、y坐标,也可通过指定location为locator(1)使用鼠标交互式地确定摆放位置
pos
#文本相对于位置参数的方位。1=下,2=左,3=上,4=右。如果指定了pos,就可以同时指定参数offset=作为偏移量,以相对于单个字符宽度的比例表示
side
#指定用来放置文本的边。1=下,2=左,3=上,4=右。你可以指定参数line=来内移或外移文本,随着值的增加,文本将外移。也可使用adj=0将文本向左下对齐,或使用adj=1右上对齐
其他常用的选项有cex、col和font(分别用来调整字号、颜色和字体样式)。
除了用来添加文本标注以外,text()函数也通常用来标示图形中的点。我们只需指定一系列的x、y坐标作为位置参
数,同时以向量的形式指定要放置的文本。x*、*y和文本标签向量的长度应当相同。
下面给出了一个示例:
attach(mtcars)
plot(wt, mpg, main="Mileage vs. Car Weight", xlab="Weight", ylab="Mileage", pch=18,col="blue")
#cex=0.6指定添加文字符号的大小
#pos=4,文本相对于位置参数的方位
text(wt, mpg, row.names(mtcars), cex=0.6, pos=4, col="red")
detach(mtcars)
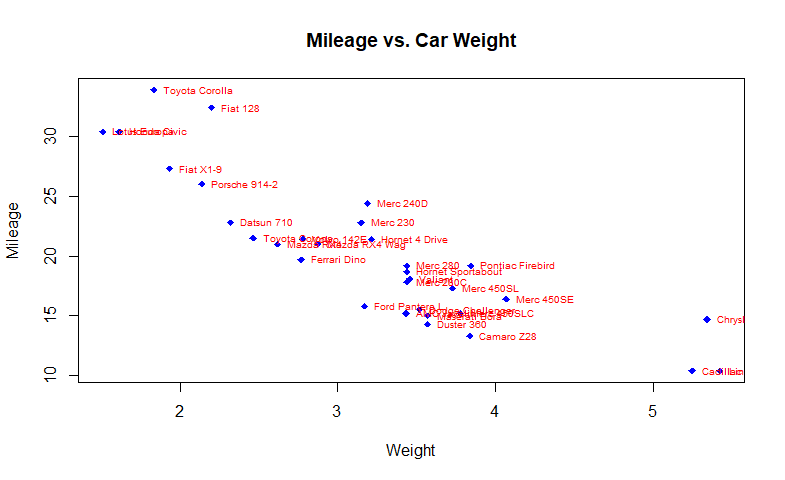
针对数据框mtcars提供的32种车型的车重和每加仑汽油行驶英里数绘制了散点图。
函数text()被用来在各个数据点右侧添加车辆型号。各点的标签大小被缩小了40%,颜色为红色。
展示不同字体族:
opar <- par(no.readonly=TRUE)
par(cex=1.5) #增大字号
plot(1:7,1:7,type="n")
text(3,3,"Example of default text")
#family="mono",字体
text(4,4,family="mono","Example of mono-spaced text")
text(5,5,family="serif","Example of serif text")
par(opar)
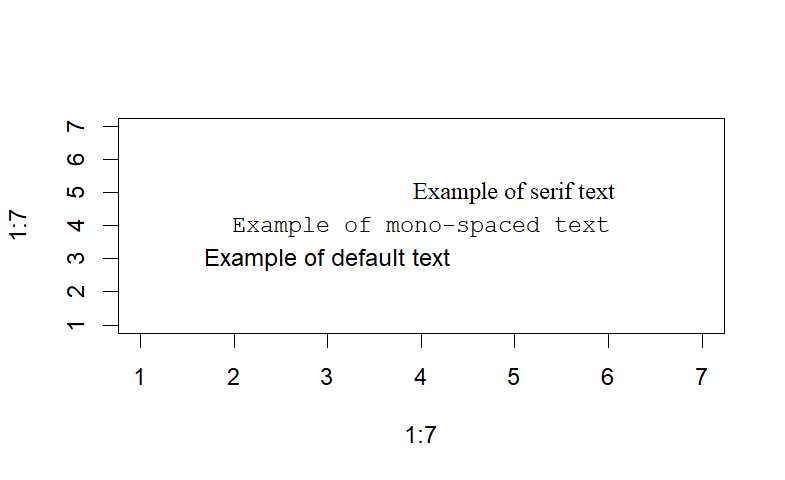
3.4.6 数学标注
参阅help(plotmath)以获得更多细节和示例。
要即时看效果,可以尝试执行demo(plotmath)。部分运行结果如图所示。
函数plotmath()可以为图形主体或边界上的标题、坐标轴名称或文本标注添加数学符号。

3.5 图形的组合
3.5.1 mfrow按行填充图形矩阵
可以在par()函数中使用图形参数mfrow=c(nrows, ncols)来创建按行填充的、行数为nrows、列数为ncols的图形矩
阵。另外,可以使用mfcol=c(nrows, ncols)按列填充矩阵。
通过par(mfrow=c(2,2))组合的四幅图形:
attach(mtcars)
opar <- par(no.readonly=TRUE)
par(mfrow=c(2,2)) #2行2列
plot(wt,mpg, main="Scatterplot of wt vs. mpg") #下一行需要enter
plot(wt,disp, main="Scatterplot of wt vs. disp")
hist(wt, main="Histogram of wt")
boxplot(wt, main="Boxplot of wt")
par(opar)
detach(mtcars)
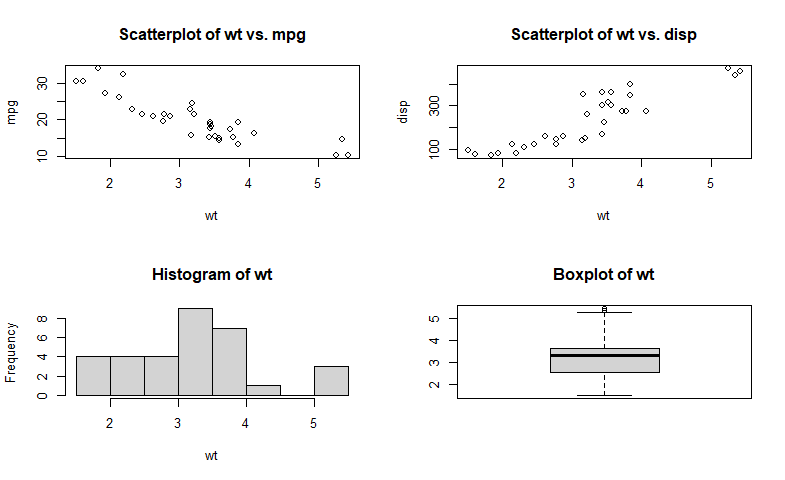
通过par(mfrow=c(3,1))组合的三幅图形:
attach(mtcars)
opar <- par(no.readonly=TRUE)
par(mfrow=c(3,1))
hist(wt)
hist(mpg)
hist(disp)
par(opar)
detach(mtcars)
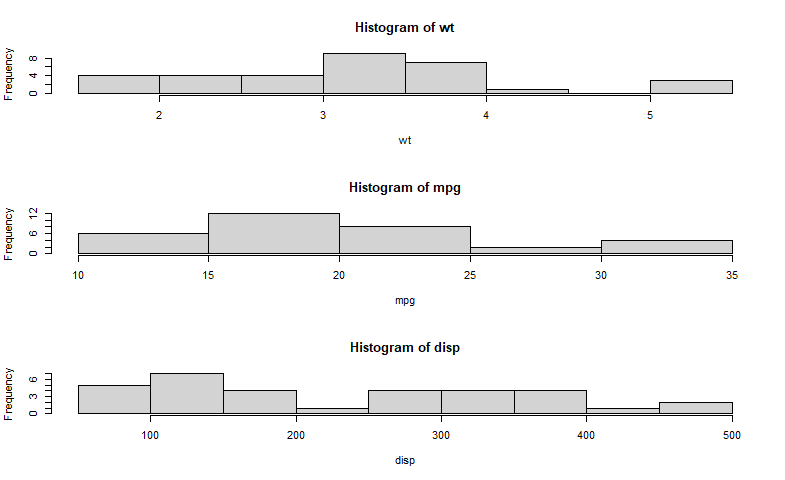
!!!注意:高级绘图函数hist()包含了一个默认的标题(使用main=""可以禁用它,抑或使用ann=FALSE来禁用所有标
题和标签)
3.5.2 layout(matrix)指定所要组合的多个图形的所在位置
函数layout()的调用形式为layout(mat),其中的mat是一个矩阵,它指定了所要组合的
多个图形的所在位置。在以下代码中,一幅图被置于第1行,另两幅图则被置于第2行:
attach(mtcars)
layout(matrix(c(1,1,2,3), 2, 2, byrow = TRUE))
hist(wt)
hist(mpg)
hist(disp)
detach(mtcars)
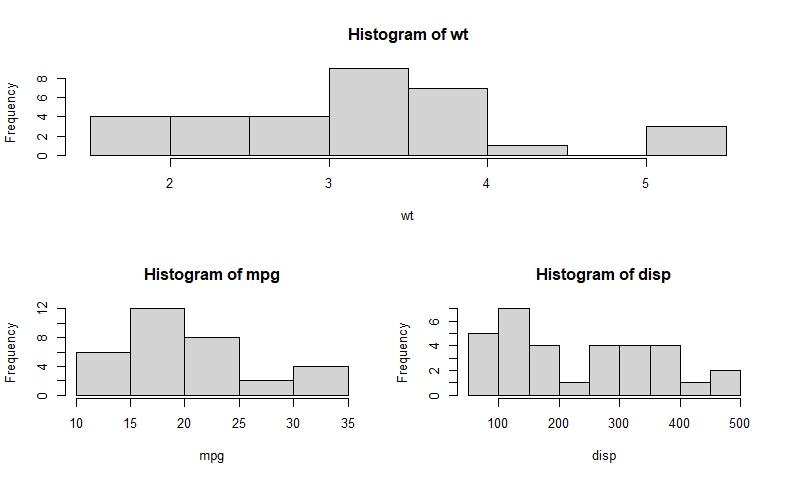
为了更精确地控制每幅图形的大小,可以有选择地在layout()函数中使用widths=和heights=两个参数。其形式
为:
-
widths = 各列宽度值组成的一个向量
-
heights = 各行高度值组成的一个向量
相对宽度可以直接通过数值指定,绝对宽度(以厘米为单位)可以通过函数lcm()来指定。
在以下代码中,我们再次将一幅图形置于第1行,两幅图形置于第2行。但第1行中图形的高度是第2行中图形高度
的二分之一。除此之外,右下角图形的宽度是左下角图形宽度的三分之一:
attach(mtcars)
layout(matrix(c(1, 1, 2, 3), 2, 2, byrow = TRUE), widths=c(3, 1), heights=c(1, 2))
hist(wt)
hist(mpg)
hist(disp)
detach(mtcars)
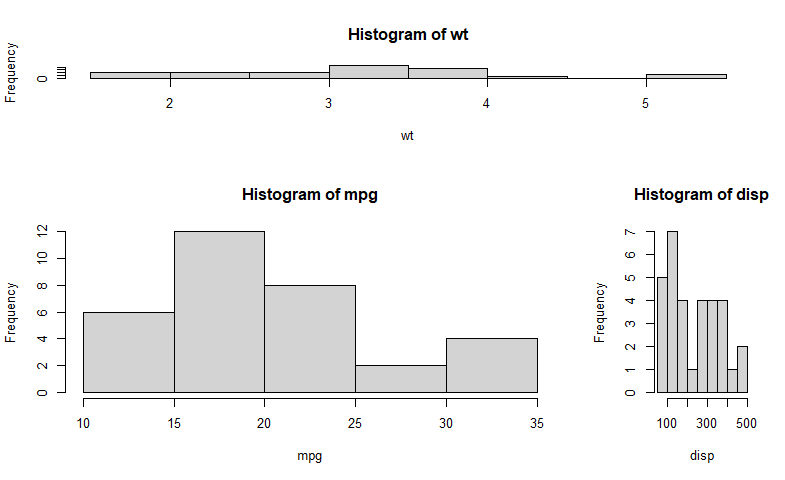
layout(matrix(c(1, 1, 2, 3), 2, 2, byrow = TRUE))
“2, 2”表示把屏幕分割成2行2列4个部分;
c(1, 1, 2, 3)中,“1, 1”代表一张图占了两格,“2”和“3”各代表一张图,最终三幅图的排列顺序为
1, 1
2, 3
即第一行一张图,第二行两张图。
3.5.3 图形布局的精细控制
可能有很多时候,你想通过排布或叠加若干图形来创建单幅的、有意义的图形,这需要有对图形布局的精细控制能
力。可以使用图形参数fig=完成这个任务。
以下代码通过在散点图上添加两幅箱线图,创建了单幅的增强型图形:
opar <- par(no.readonly=TRUE)
par(fig=c(0, 0.8, 0, 0.8)) #将散点图设定为占据横向范围0-0.8,纵向范围0-0.8
plot(mtcars$wt, mtcars$mpg, xlab="Miles Per Gallon", ylab="Car Weight")
#fig=默认会新建一幅图形,所以在添加一幅图到一幅现有图形上时,请设定参数new=TRUE
par(fig=c(0, 0.8, 0.55, 1), new=TRUE) #上方的箱线图横向占据0-0.8,纵向0.55-1
boxplot(mtcars$wt, horizontal=TRUE, axes=FALSE)
par(fig=c(0.65, 1, 0, 0.8), new=TRUE) #右方的箱线图横向占据0.65-1,纵向0-0.8
boxplot(mtcars$mpg, axes=FALSE)
mtext("Enhanced Scatterplot", side=3, outer=TRUE, line=-3)
par(opar)

要理解这幅图的绘制原理,请试想完整的绘图区域:左下角坐标为(0, 0),而右上角坐标为(1, 1)。
下图是一幅示意图。参数fig=的取值是一个形如c(x1, x2, y1, y2)的数值向量。
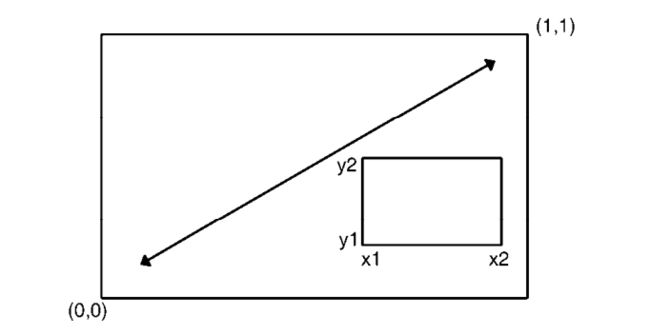
第一个fig=将散点图设定为占据横向范围0-0.8,纵向范围0-0.8。上方的箱线图横向占据0-0.8,纵向0.55-1。
右侧的箱线图横向占据0.65-1,纵向0-0.8。fig=默认会新建一幅图形,所以在添加一幅图到一幅现有图形上
时,请设定参数new=TRUE。
我将参数选择为0.55而不是0.8,这样上方的图形就不会和散点图拉得太远。类似地,我选择了参数0.65以拉
近右侧箱线图和散点图的距离。你需要不断尝试找到合适的位置参数。