【NLP论文】02 TF-IDF 关键词权值计算
之前写了一篇关于关键词词库构建的文章,没想到反响还不错,最近有空把接下来的两篇补完,也继续使用物流关键词词库举例,本篇文章承接关键词词库构建并以其为基础,将计算各关键词的 TF-IDF 权值,TF-IDF 权值主要用于表达各关键词的重要程度,最后展示一个实际应用的例子—构建物流评价体系并结合TF-IDF 关键词权值,希望能给大家启发。
目录
1 TF-IDF 关键词权值计算
1.1 为什么使用 TF-IDF ?
1.2 TF-IDF 介绍
1.3 TF-IDF 关键词权值计算
① 语料
② TF-IDF 计算
③ xx 关键词匹配
2 构建XX评价体系
2.1 构建物流评价体系
2.2 TF-IDF 权值结合评价体系
代码地址:nlp_yinyu
1 TF-IDF 关键词权值计算
1.1 为什么使用 TF-IDF ?
上一篇文章有统计关键词的词频数,简单来说,某语料中某关键词的词频数越大,那么该关键词在该语料中的重要程度越大,这是比较容易理解的。
那么有没有一种更加直观并且可量化的方式表示某关键词在语料中的重要程度呢,那这就是本篇文章介绍的 TF-IDF,它将计算出一个数值来表示关键词对于预料的重要程度,数值越大,重要程度越大。
1.2 TF-IDF 介绍
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取方法,用于评估一个词语对于一个文档集合中的某个文档的重要程度。
TF(Term Frequency)表示某个词在文档中出现的频率,即词频,TF值越大表示该词在文档中的重要性越高。
IDF(Inverse Document Frequency)表示逆文档频率,它衡量词语在文档集合中的普遍重要性,IDF值越大表示该词对于区分不同文档的能力越强。
TF-IDF的计算公式为: TF-IDF(t,d) = TF(t,d) * IDF(t)
其中,t表示词语,d表示文档。TF(t,d)表示词语t在文档d中的词频(出现的次数),IDF(t)表示词语t的逆文档频率。
1.3 TF-IDF 关键词权值计算
① 语料
语料还是以之前爬取的京东网站上的 5000 条评论数据为例,可以在文章顶部的代码仓库中下载!

② TF-IDF 计算
和分词步骤类似,主要分为以下三步:
- 引入语料 excel 数据
- 加载自定义词典
- 权值计算,生成【TF-IDF关键词权值计算表.xlsx】文件
代码如下:
import jieba.analyse
import pandas as pd
from base_handle import BaseHandle # 引入工具类
baseHandle = BaseHandle() #实例化
'''
2.1 word2vec 拓展关键词词库
'''
def words_weight(url):
'''TF-IDF关键词权值计算'''
text = baseHandle.read_col_merge_file(url) #引入语料 excel 数据
diy_dict=(baseHandle.get_file_abspath('物流词汇大全.txt')) #引入自定义词典
jieba.load_userdict(diy_dict) #加载自定义字典
# 第一个参数:待提取关键词的文本
# 第二个参数:返回关键词的数量,重要性从高到低排序!!
# 第三个参数:是否同时返回每个关键词的权重
# 第四个参数:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词
keywords_list = jieba.analyse.extract_tags(text, topK=None, withWeight=True, allowPOS=())
#print(keywords_list)#以列表形式
df = pd.DataFrame(keywords_list,columns=['keyword', 'weight'])# list转dataframe
df.to_excel("TF-IDF关键词权值计算表.xlsx", index=False)# 保存到本地excel
#jieba自己本来就拥有的一个比较大众化的语料库。因此对于相对来说比较大众化的文本数据处理,jieba自带的TF-IDF语料库可以完美契合我们的诉求。
if __name__ == "__main__":
words_weight(baseHandle.get_file_abspath('语料库_京东_5000条评论.xlsx'))最终输出【TF-IDF关键词权值计算表.xlsx】文件如下:
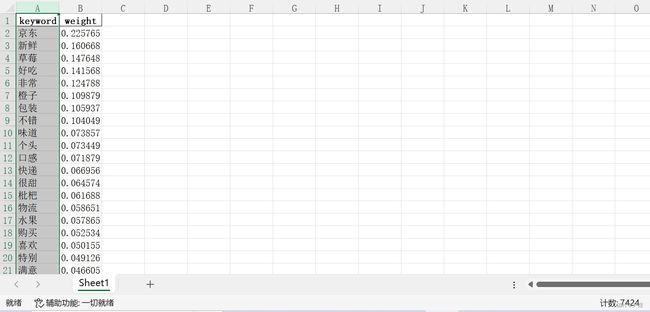
可以看到这是统计了所有词汇的权值结果,足足有7424个单词,那么接下来就需要进行筛选匹配。
③ xx 关键词匹配
以物流关键词词库为例,然后我们在上一篇文章中统计出来的物流关键词词库就派上用场了
class BaseHandle(object):
def __init__(self):
# 物流关键词词库:目前30个物流关键词
self.logistics_list = ['京东', '新鲜', '包装', '物流', '很快', '快递', '收到', '速度', '送货', '推荐',
'小哥', '服务', '发货', '配送', '送到', '到货', '第二天', '冷链', '完好', '送货上门'
# 使用word2vec加的关键词
'严谨','保障', '效率', '方便快捷', '客服', '省心', '快捷', '严实']
主要分为以下三步:
- 读取TF-IDF关键词权值计算表
- 遍历匹配
- 生成【物流关键词词库权值计算表.xlsx】文件
代码如下:
import jieba.analyse
import pandas as pd
from base_handle import BaseHandle # 引入工具类
baseHandle = BaseHandle() #实例化
def words_ididf_match(keywords_list):
'''关键词批量匹配权重'''
df = pd.read_excel('TF-IDF关键词权值计算表.xlsx', sheet_name='Sheet1')
b1 = []
b2 = []
for i in range(len(df)):
keyword = df.loc[i,'keyword']
if any(word if word == keyword else False for word in keywords_list): #判断列表(list)内一个或多个元素是否与关键词相同
a1 = df.loc[i,'keyword']
a2 = df.loc[i,'weight']
b1.append(a1)
b2.append(a2)
else:
continue
f1 = pd.DataFrame(columns=['关键词', '权重'])
f1['关键词'] = b1
f1['权重'] = b2
f1.to_excel("物流关键词词库权值计算表.xlsx", index=False)# 保存到本地excel
if __name__ == "__main__":
words_ididf_match(baseHandle.logistics_list)最终输出【物流关键词词库权值计算表.xlsx】文件如下:
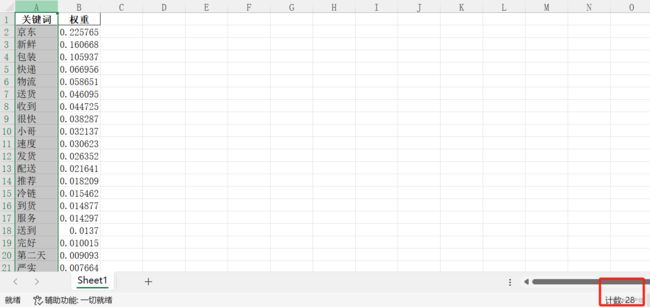
如此一来,可以看到物流关键词词库中各关键词的权重了,各关键词对于语料的重要程度也就很直观了!
2 构建XX评价体系
2.1 构建物流评价体系
以物流为例,前文已经存在物流关键词词库和 TF-IDF 权值数据了,那么我们该如何利用呢,在此我提供一个思路:可利用这些数据来服务一个评价体系,分为几个维度,各维度下分几个指标,或者直接简单地分为几个维度即可,本文以此为例。
构建评价体系的方法见仁见智,可以说是文献统计,问卷统计等等,我将物流评价体系分为六大维度:货物完好度、物流响应能力、人员沟通质量、误差处理、物流服务费用和信息质量。
然后将物流关键词词库中的关键词匹配到这几个维度下,这就需要人工进行操作了,如下:
| 维度 | 关键词 |
| 货物完好度 | 京东,新鲜,包装,配送,冷链,到货,完好,严实 |
| 物流响应能力 | 快递,物流,送货,收到,很快,速度,发货,送到,第二天,快捷 |
| 人员沟通质量 | 小哥,服务,客服 |
| 误差处理 | 保障 |
| 物流服务费用 | 方便快捷,严谨 |
| 信息质量 | 推荐,省心,效率 |
我简单地归类了下,不一定准确,算是举个例子~
2.2 TF-IDF 权值结合评价体系
接下来就是利用 TF-IDF 权值数据了,将每个关键词的权值标上去,如下图:
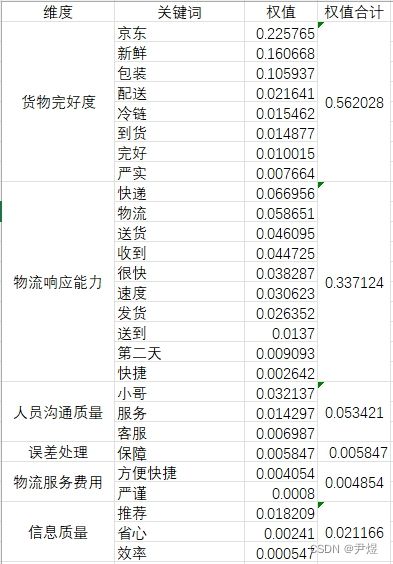
如此,可以清晰地看到各维度的重要程度,而且由于它提供的是量化数据,所以也会显得比较可靠。
为了显得研究更加丰富,下一篇文章将结合情感分析进行统计!