机器学习-深度学习入门CV-手写数字识别实验
机器学习-深度学习入门CV-手写数字识别
实验要求
本实践使用多层感知器训练(DNN)模型,用于预测手写数字图片。

实践总体过程和步骤
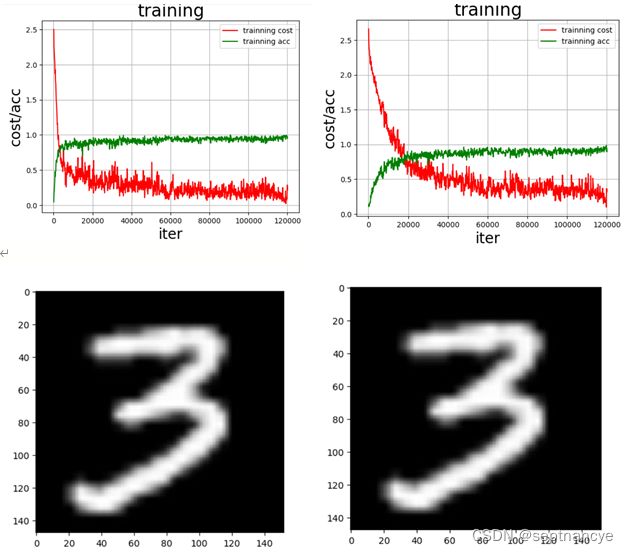
如下图

实验结果展示
learning_rate 是学习率(它的大小与网络的训练收敛速度有关系)
实验代码
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
import os
BUF_SIZE=512
BATCH_SIZE=128
#用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.train(),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
#用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
test_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.test(),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
#用于打印,查看mnist数据
train_data=paddle.dataset.mnist.train();
sampledata=next(train_data())
print(sampledata)
# 定义多层感知器
def multilayer_perceptron(input):
# 第一个全连接层,激活函数为ReLU
hidden1 = fluid.layers.fc(input=input, size=100, act='relu')
# 第二个全连接层,激活函数为ReLU
hidden2 = fluid.layers.fc(input=hidden1, size=100, act='relu')
# 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
prediction = fluid.layers.fc(input=hidden2, size=10, act='softmax')
return prediction
# 输入的原始图像数据,大小为1*28*28
image = fluid.layers.data(name='image', shape=[1, 28, 28], dtype='float32')#单通道,28*28像素值
# 标签,名称为label,对应输入图片的类别标签
label = fluid.layers.data(name='label', shape=[1], dtype='int64') #图片标签
# 获取分类器
predict = multilayer_perceptron(image)
#使用交叉熵损失函数,描述真实样本标签和预测概率之间的差值
cost = fluid.layers.cross_entropy(input=predict, label=label)
# 使用类交叉熵函数计算predict和label之间的损失函数
avg_cost = fluid.layers.mean(cost)
# 计算分类准确率
acc = fluid.layers.accuracy(input=predict, label=label)
#使用Adam算法进行优化, learning_rate 是学习率(它的大小与网络的训练收敛速度有关系)
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.001)
opts = optimizer.minimize(avg_cost)
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 获取测试程序
test_program = fluid.default_main_program().clone(for_test=True)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
EPOCH_NUM=2
model_save_dir = "/home/aistudio/work/hand.inference.model"
for pass_id in range(EPOCH_NUM):
# 进行训练
for batch_id, data in enumerate(train_reader()): #遍历train_reader
train_cost, train_acc = exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #给模型喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
all_train_iter=all_train_iter+BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
# 每200个batch打印一次信息 误差、准确率
if batch_id % 200 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
plt.show()
# 进行测试
test_accs = []
test_costs = []
#每训练一轮 进行一次测试
for batch_id, data in enumerate(test_reader()): #遍历test_reader
test_cost, test_acc = exe.run(program=test_program, #执行训练程序
feed=feeder.feed(data), #喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
test_accs.append(test_acc[0]) #每个batch的准确率
test_costs.append(test_cost[0]) #每个batch的误差
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs)) #每轮的平均误差
test_acc = (sum(test_accs) / len(test_accs)) #每轮的平均准确率
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
#保存模型
# 如果保存路径不存在就创建
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print ('save models to %s' % (model_save_dir))
fluid.io.save_inference_model(model_save_dir, #保存推理model的路径
['image'], #推理(inference)需要 feed 的数据
[predict], #保存推理(inference)结果的 Variables
exe) #executor 保存 inference model
print('训练模型保存完成!')
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
def load_image(file):
im = Image.open(file).convert('L') #将RGB转化为灰度图像,L代表灰度图像,像素值在0~255之间
im = im.resize((28, 28), Image.ANTIALIAS) #resize image with high-quality 图像大小为28*28
im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)#返回新形状的数组,把它变成一个 numpy 数组以匹配数据馈送格式。
# print(im)
im = im / 255.0 * 2.0 - 1.0 #归一化到【-1~1】之间
return im
infer_path='/home/aistudio/data/data1910/infer_3.png'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
# 加载数据并开始预测
with fluid.scope_guard(inference_scope):
#获取训练好的模型
#从指定目录中加载 推理model(inference model)
[inference_program, #推理Program
feed_target_names, #是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(model_save_dir,#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。model_save_dir:模型保存的路径
infer_exe) #infer_exe: 运行 inference model的 executor
img = load_image(infer_path)
results = infer_exe.run(program=inference_program, #运行推测程序
feed={feed_target_names[0]: img}, #喂入要预测的img
fetch_list=fetch_targets) #得到推测结果,
# 获取概率最大的label
lab = np.argsort(results) #argsort函数返回的是result数组值从小到大的索引值
#print(lab)
print("该图片的预测结果的label为: %d" % lab[0][0][-1]) #-1代表读取数组中倒数第一列
实验感想
学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,数据并行的方式与众人拾柴火焰高的道理类似,如果把训练数据比喻为砖头,把一个设备(GPU)比喻为一个人,那单GPU训练就是一个人在搬砖,多GPU训练就是多个人同时搬砖,每次搬砖的数量倍数增加,效率呈倍数提升。值得注意的是,每个设备的模型是完全相同的,但是输入数据不同,因此每个设备的模型计算出的梯度是不同的。如果每个设备的梯度只更新当前设备的模型,就会导致下次训练时,每个模型的参数都不相同。因此我们还需要一个梯度同步机制,保证每个设备的梯度是完全相同的。