【kettle】pdi/data-integration 集成kerberos认证连接hive或spark thriftserver
一、背景
kerberos认证是比较底层的认证,掌握好了用起来比较简单。
kettle当前任务的jvm任务完成kerberos认证后会存储认证信息,之后直接连接hive就可以了无需提供额外的用户信息。
spark thriftserver本质就是通过hive jdbc协议连接并运行spark sql任务。
二、思路
kettle中可以使用js调用java类的方法。编写一个jar放到kettle的lib目录下并。在启动kettle后会自动加载此jar中的类。编写一个javascript转换完成kerbero即可。
二、kerberos认证模块开发
准备使用scala语言完成此项目。
2.1 生成kerberos工具jar包
2.1.1 创建maven项目并编写pom
创建maven项目,这里依赖比较多觉得没用的删掉即可:
注意:这里为了便于管理很多包都是provided,最后不会打到包内,自己测试可以都改为 compile,避免缺少包再一个一个排查!!!
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<scala.version>2.11.12scala.version>
<scala.major.version>2.11scala.major.version>
<target.java.version>1.8target.java.version>
<spark.version>2.4.0spark.version>
<hive.version>2.1.1hive.version>
<hadoop.version>3.0.0-cdh6.2.0hadoop.version>
<zookeeper.version>3.4.5-cdh6.2.0zookeeper.version>
<jackson.version>2.14.2jackson.version>
<httpclient5.version>5.2.1httpclient5.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-reflectartifactId>
<version>${scala.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-compilerartifactId>
<version>${scala.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>1.7.28version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-slf4j-implartifactId>
<version>2.9.1version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-apiartifactId>
<version>2.11.1version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.11.1version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>${hadoop.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>${hive.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>${hive.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hive.shimsgroupId>
<artifactId>hive-shims-0.23artifactId>
<version>${hive.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.hive.shimsgroupId>
<artifactId>hive-shims-commonartifactId>
<version>${hive.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive-thriftserver_${scala.major.version}artifactId>
<version>${spark.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>${zookeeper.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.junit.jupitergroupId>
<artifactId>junit-jupiter-apiartifactId>
<version>5.6.2version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.scalatestgroupId>
<artifactId>scalatest_2.11artifactId>
<version>3.2.8version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.scalacticgroupId>
<artifactId>scalactic_2.12artifactId>
<version>3.2.8version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.14version>
<scope>providedscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>4.5.6version>
<configuration>
configuration>
<executions>
<execution>
<id>scala-compilerid>
<phase>process-resourcesphase>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
<execution>
<id>scala-test-compilerid>
<phase>process-test-resourcesphase>
<goals>
<goal>add-sourcegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.7version>
<configuration>
<skipTests>trueskipTests>
configuration>
plugin>
<plugin>
<groupId>org.scalatestgroupId>
<artifactId>scalatest-maven-pluginartifactId>
<version>2.2.0version>
<configuration>
<reportsDirectory>${project.build.directory}/surefire-reportsreportsDirectory>
<junitxml>.junitxml>
<filereports>WDF TestSuite.txtfilereports>
configuration>
<executions>
<execution>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.0.0version>
<configuration>
<appendAssemblyId>falseappendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
<repositories>
<repository>
<id>clouderaid>
<name>clouderaname>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
repositories>
project>
2.1.2 编写类
KerberosConf 暂时没啥用。
case class KerberosConf(principal: String, keyTabPath: String, conf: String="/etc/krb5.conf")
ConfigUtils 类用于生成hadoop 的Configuration,kerberos认证的时候会用到。
import org.apache.hadoop.conf.Configuration
import java.io.FileInputStream
import java.nio.file.{Files, Paths}
object ConfigUtils {
val LOGGER = org.slf4j.LoggerFactory.getLogger(KerberosUtils.getClass)
var hadoopConfiguration: Configuration = null
var hiveConfiguration: Configuration = null
private var hadoopConfDir: String = null
private var hiveConfDir: String = null
def setHadoopConfDir(dir: String): Configuration = {
hadoopConfDir = dir
refreshHadoopConfig
}
def getHadoopConfDir: String = {
if (hadoopConfDir.isEmpty) {
val tmpConfDir = System.getenv("HADOOP_CONF_DIR")
if (tmpConfDir.nonEmpty && Files.exists(Paths.get(tmpConfDir))) {
hadoopConfDir = tmpConfDir
} else {
val tmpHomeDir = System.getenv("HADOOP_HOME")
if (tmpHomeDir.nonEmpty && Files.exists(Paths.get(tmpHomeDir))) {
val tmpConfDirLong = s"${tmpHomeDir}/etc/hadoop"
val tmpConfDirShort = s"${tmpHomeDir}/conf"
if (Files.exists((Paths.get(tmpConfDirLong)))) {
hadoopConfDir = tmpConfDirLong
} else if (Files.exists(Paths.get(tmpConfDirShort))) {
hadoopConfDir = tmpConfDirShort
}
}
}
}
LOGGER.info(s"discover hadoop conf from : ${hadoopConfDir}")
hadoopConfDir
}
def getHadoopConfig: Configuration = {
if (hadoopConfiguration == null) {
hadoopConfiguration = new Configuration()
configHadoop()
}
hadoopConfiguration
}
def refreshHadoopConfig: Configuration = {
hadoopConfiguration = new Configuration()
configHadoop()
}
def configHadoop(): Configuration = {
var coreXml = ""
var hdfsXml = ""
val hadoopConfDir = getHadoopConfDir
if (hadoopConfDir.nonEmpty) {
val coreXmlTmp = s"${hadoopConfDir}/core-site.xml"
val hdfsXmlTmp = s"${hadoopConfDir}/hdfs-site.xml"
val coreExists = Files.exists(Paths.get(coreXmlTmp))
val hdfsExists = Files.exists(Paths.get(hdfsXmlTmp))
if (coreExists && hdfsExists) {
LOGGER.info(s"discover hadoop conf from hadoop conf dir: ${hadoopConfDir}")
coreXml = coreXmlTmp
hdfsXml = hdfsXmlTmp
hadoopAddSource(coreXml, hadoopConfiguration)
hadoopAddSource(hdfsXml, hadoopConfiguration)
}
}
LOGGER.info(s"core-site path : ${coreXml}, hdfs-site path : ${hdfsXml}")
hadoopConfiguration
}
def getHiveConfDir: String = {
if (hiveConfDir.isEmpty) {
val tmpConfDir = System.getenv("HIVE_CONF_DIR")
if (tmpConfDir.nonEmpty && Files.exists(Paths.get(tmpConfDir))) {
hiveConfDir = tmpConfDir
} else {
val tmpHomeDir = System.getenv("HIVE_HOME")
if (tmpHomeDir.nonEmpty && Files.exists(Paths.get(tmpHomeDir))) {
val tmpConfDirShort = s"${tmpHomeDir}/conf}"
if (Files.exists(Paths.get(tmpConfDir))) {
hiveConfDir = tmpConfDirShort
}
}
}
}
LOGGER.info(s"discover hive conf from : ${hiveConfDir}")
hiveConfDir
}
def configHive(): Configuration = {
if (hiveConfiguration != null) {
return hiveConfiguration
} else {
hiveConfiguration = new Configuration()
}
var hiveXml = ""
val hiveConfDir = getHiveConfDir
if (hiveConfDir.nonEmpty) {
val hiveXmlTmp = s"${hiveConfDir}/hive-site.xml"
val hiveExist = Files.exists(Paths.get(hiveXml))
if (hiveExist) {
LOGGER.info(s"discover hive conf from : ${hiveConfDir}")
hiveXml = hiveXmlTmp
hadoopAddSource(hiveXml, hiveConfiguration)
}
}
LOGGER.info(s"hive-site path : ${hiveXml}")
hiveConfiguration
}
def getHiveConfig: Configuration = {
if (hiveConfiguration == null) {
hiveConfiguration = new Configuration()
configHive()
}
hiveConfiguration
}
def refreshHiveConfig: Configuration = {
hiveConfiguration = new Configuration()
configHive()
}
def hadoopAddSource(confPath: String, conf: Configuration): Unit = {
val exists = Files.exists(Paths.get(confPath))
if (exists) {
LOGGER.warn(s"add [${confPath} to hadoop conf]")
var fi: FileInputStream = null
try {
fi = new FileInputStream(confPath)
conf.addResource(fi)
conf.get("$$")
} finally {
if (fi != null) fi.close()
}
} else {
LOGGER.error(s"[${confPath}] file does not exists!")
}
}
def toUnixStyleSeparator(path: String): String = {
path.replaceAll("\\\\", "/")
}
def fileOrDirExists(path: String): Boolean = {
Files.exists(Paths.get(path))
}
}
KerberosUtils 就是用于认证的类。
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.security.UserGroupInformation
import org.apache.kerby.kerberos.kerb.keytab.Keytab
import org.slf4j.Logger
import java.io.{File}
import java.net.URL
import java.nio.file.{Files, Paths}
import scala.collection.JavaConversions._
import scala.collection.JavaConverters._
object KerberosUtils {
val LOGGER: Logger = org.slf4j.LoggerFactory.getLogger(KerberosUtils.getClass)
def loginKerberos(krb5Principal: String, krb5KeytabPath: String, krb5ConfPath: String, hadoopConf: Configuration): Boolean = {
val authType = hadoopConf.get("hadoop.security.authentication")
if (!"kerberos".equalsIgnoreCase(authType)) {
LOGGER.error(s"kerberos utils get hadoop authentication type [${authType}] ,not kerberos!")
} else {
LOGGER.info(s"kerberos utils get hadoop authentication type [${authType}]!")
}
UserGroupInformation.setConfiguration(hadoopConf)
System.setProperty("java.security.krb5.conf", krb5ConfPath)
System.setProperty("javax.security.auth.useSubjectCredsOnly", "false")
UserGroupInformation.loginUserFromKeytab(krb5Principal, krb5KeytabPath)
val user = UserGroupInformation.getLoginUser
if (user.getAuthenticationMethod == UserGroupInformation.AuthenticationMethod.KERBEROS) {
val usnm: String = user.getShortUserName
LOGGER.info(s"kerberos utils login success, curr user: ${usnm}")
true
} else {
LOGGER.info("kerberos utils login failed")
false
}
}
def loginKerberos(krb5Principal: String, krb5KeytabPath: String, krb5ConfPath: String): Boolean = {
val hadoopConf = ConfigUtils.getHadoopConfig
loginKerberos(krb5Principal, krb5KeytabPath, krb5ConfPath, hadoopConf)
}
def loginKerberos(kerberosConf: KerberosConf): Boolean = {
loginKerberos(kerberosConf.principal, kerberosConf.keyTabPath, kerberosConf.conf)
}
def loginKerberos(krb5Principal: String, krb5KeytabPath: String, krb5ConfPath: String,hadoopConfDir:String):Boolean={
ConfigUtils.setHadoopConfDir(hadoopConfDir)
loginKerberos(krb5Principal,krb5KeytabPath,krb5ConfPath)
}
def loginKerberos(): Boolean = {
var principal: String = null
var keytabPath: String = null
var krb5ConfPath: String = null
val classPath: URL = this.getClass.getResource("/")
val classPathObj = Paths.get(classPath.toURI)
var keytabPathList = Files.list(classPathObj).iterator().asScala.toList
keytabPathList = keytabPathList.filter(p => p.toString.toLowerCase().endsWith(".keytab")).toList
val krb5ConfPathList = keytabPathList.filter(p => p.toString.toLowerCase().endsWith("krb5.conf")).toList
if (keytabPathList.nonEmpty) {
val ktPath = keytabPathList.get(0)
val absPath = ktPath.toAbsolutePath
val keytab = Keytab.loadKeytab(new File(absPath.toString))
val pri = keytab.getPrincipals.get(0).getName
if (pri.nonEmpty) {
principal = pri
keytabPath = ktPath.toString
}
}
if (krb5ConfPathList.nonEmpty) {
val confPath = krb5ConfPathList.get(0)
krb5ConfPath = confPath.toAbsolutePath.toString
}
if (principal.nonEmpty && keytabPath.nonEmpty && krb5ConfPath.nonEmpty) {
ConfigUtils.configHadoop()
// ConfigUtils.configHive()
val hadoopConf = ConfigUtils.hadoopConfiguration
loginKerberos(principal, keytabPath, krb5ConfPath, hadoopConf)
} else {
false
}
}
}
2.1.3 编译打包
mvn package 并将打包好的jar包放到 kettle 的lib目录下。
核心的依赖包如下:
hadoop-auth-3.0.0-cdh6.2.0.jar
hadoop-client-3.0.0-cdh6.2.0.jar
hadoop-common-3.0.0-cdh6.2.0.jar
scala-compiler-2.11.12.jar
scala-library-2.11.12.jar
zookeeper-3.4.5.jar
2.2 启动kettle和类加载说明
debug模式启动:SpoonDebug.bat
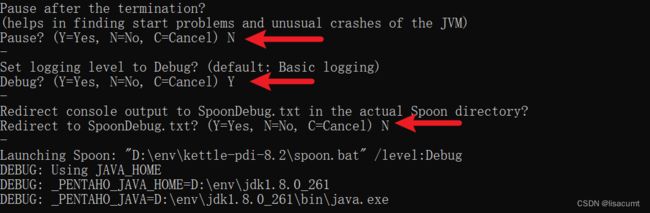 如果还想看类加载路径可以在
如果还想看类加载路径可以在Spoon.bat中的set OPT= 行尾添加jvm选项 "-verbose:class" 。
如果cmd黑窗口中文乱码可以把SpoonDebug.bat中的 "-Dfile.encoding=UTF-8" 删除即可。
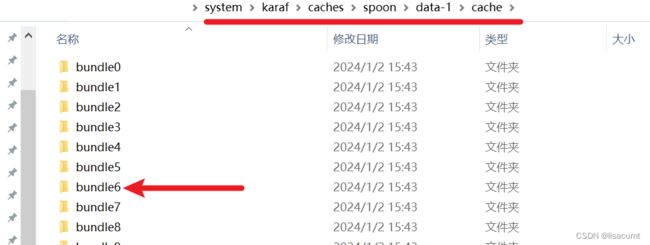
kettle会把所有jar包都缓存,都存储在kettle-home\system\karaf\caches目录下。
日志里打印的所有 bundle数字目录下得jar包都是在缓存目录下。
 如果kettle在运行过程中卡掉了,不反应了,八成是因为操作过程中点击了cmd黑窗口,此时在cmd黑窗口内敲击回车,cmd日志就会继续打印,窗口也会恢复响应。
如果kettle在运行过程中卡掉了,不反应了,八成是因为操作过程中点击了cmd黑窗口,此时在cmd黑窗口内敲击回车,cmd日志就会继续打印,窗口也会恢复响应。
2.3 编写js通过kerberos认证
 配置信息就是填写kerberos的配置。
配置信息就是填写kerberos的配置。
javascript代码完成kerberos认证。
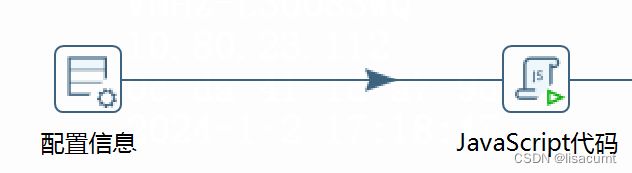
配置信息内填写如下:

javascript代码内容如下:

// 给类起个别名
var utils = Packages.全类路径.KerberosUtils;
// 使用 HADOOP_CONF_DIR 或 HADOOP_HOME 环境变量,配置登录Kerberos
var loginRes = utils.loginKerberos(krb5_principal,krb5_keytab,krb5_conf);
// 使用用户提供的 hadoop_conf_dir 登录kerberos
// var loginRes = utils.loginKerberos(krb5_principal,krb5_keytab,krb5_conf,hadoop_conf_dir);
添加一个写结果的模块!

好了,执行启动!

如果报如下错误,说明kettle没有找到java类,检查类路径和包是否错误!
TypeError: Cannot call property loginKerberos in object [JavaPackage utils]. It is not a function, it is "object". (script#6)
如果打印如下内容,说明执行认证成功了。

2024/01/02 18:18:04 - 写日志.0 -
2024/01/02 18:18:04 - 写日志.0 - ------------> 行号 1------------------------------
2024/01/02 18:18:04 - 写日志.0 - loginRes = Y
三、包装模块开发
keberos认证会在jvm存储信息,这些信息如果想使用必须前于hive或hadoop任务一个job
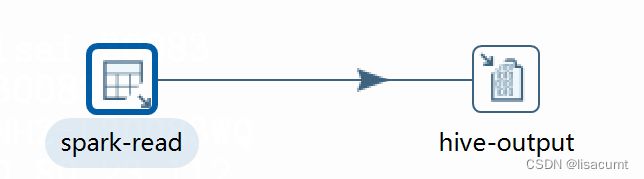
结构如下:

kerberos-login 就是刚刚写的转换。
必须如上包装,层数少了,认证不过去!!!
四、连接hive或者spark thriftserver
连接hive和spark thriftserver是一样的。以下以spark举例说明。

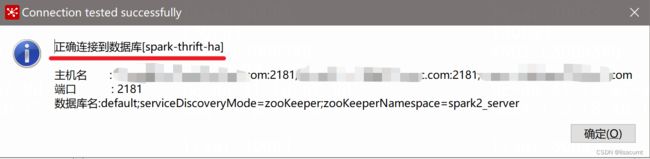
4.1 zookeeper的ha方式连接
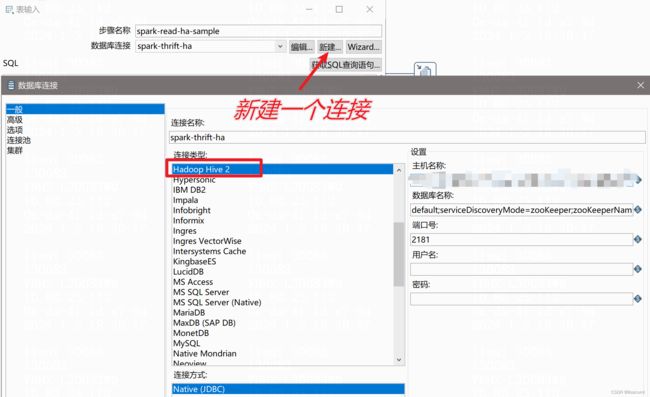
# 主机名称:
# 注意这里主机名会后少写一个:2181
zk-01.com:2181,zk-02.com:2181,zk-03.com
# 数据库名称:
# 后边把kerberos连接参数也加上。zooKeeperNamespace 参数从SPARK_HOME/conf/hive-site.xml文件获取即可。而serviceDiscoveryMode=zooKeeper是固定写法。
default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=spark2_server
# 端口号:
# 主机名故意少写一个,就在这里补上了。
2181
最终的连接url如下:
jdbc:hive2://zk-01.com:2181,zk-01.com:2181,zk-01.com:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=spark2_server
点击下边的
 先手动运行下kerberos认证模块,再测试连接下:
先手动运行下kerberos认证模块,再测试连接下:
4.2 单点连接方式

# 主机名称
# 就是hive server2 的主机 host,不要写IP
# 数据库名称:
# SPARK_HOME/conf/hive-site.xml中找到配置 hive.server2.authentication.kerberos.principal
# 比如spark/[email protected]
# 本质也是在default数据库后边拼接连接字符串
default;principal=spark/[email protected]
# 端口号也在SPARK_HOME/conf/hive-site.xml中找到配置hive.server2.thrift.port有
10016

参考文章:
hive 高可用详解: Hive MetaStore HA、hive server HA原理详解;hive高可用实现
kettle开发篇-JavaScript脚本-Day31
kettle组件javaScript脚本案例1