Redis专题
Redis基础篇
1、nosql产生背景(访问量 性能 用户体验)
- 随着网络时代的快速发展,访问量变得越来越大
- 并且用户对性能的要求也比较明显,就像是在网络刚开始的时候使用2G网络就觉得已经很快了,但是现在4G网络都不能满足你急切的心情,那么在我们浏览一个网站的时候,要是网页的数据迟迟不能出现,最起码立刻会使得体验不好。
- 简单来看一个程序无非就是对数据的操作,那么从数据层面导致原来的程序都比较慢的情况是数据的读取,那关系型数据库如mysql、Oracle都是直接将数据存储在硬盘中的,所以程序处理时需要进行IO操作,访问量越大IO操作越频繁,并且关系型数据库还需要存储关系信息。
- 存储结构更加简洁,因此查询响应更快
因此为了减少IO操作,提升效率和性能,nosql逐渐出现
2、nosql数据库简单说明(非关系型数据库 关系型数据库的补充 高性能 )
- nosql数据库是一种非关系型数据库,不是特指某一个数据库,而且一类,同时nosql的解释是不仅仅是数据库
- nosql数据库是对关系型数据库的补充
- nosql数据库有多个,比如redis、mongoDB
- nosql存储的数据有如下特性:数据间没有关联、高性能
3、Redis数据库简单说明(持久化 多种数据类型 单线程)
基础功能
- redis数据库支持持久化,主要是为了异常情况下数据的恢复
- redis数据库的强大之处还在于支持多种数据类型的存储
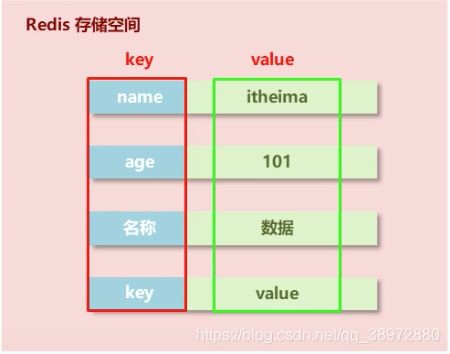
- redis是以key,value的形式存储数据,看上去和map存储结构类似,但是还是有区别,比如map存储结构,在存储数据时对于相同key数据存储,会将该key原来的值覆盖掉(map中key不能重复),但是redis在存储数据时,key可以相同,并且不会覆盖,稍后在具体的数据类型中有介绍
- redis内部处理是单线程操作,因为不用担心安全问题,同时redis指令的原子性操作也是因为是单线程处理
为什么处理速度那么快
- 完全是基于内存操作的
- 单线程处理,避免了多线程之间上下文切换和竞争资源的开销
- 基于非阻塞IO-多路复用机制
- C语言实现的,并且对存储类型结构做过大量的优化
4、Redis数据类型介绍以及相关指令(String Hash List Set Sorted_set)
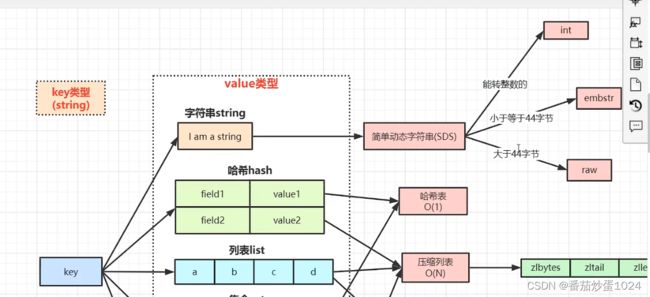
说明: 对于redis数据类型的介绍,都是对value值的说明,key永远是String类型
在redis中不管是哪种数据类型存储,要是在get时对于不存在的数据,返回的都是nil,和数据结构中线索二叉树的表示一样,线索二叉树中对于没有的子树用nil表示
String类型:
其对应的存储结构还是java中的String

说明:对于del操作,返回结果是Integer类型,0-操作失败,1-操作成功

说明:strlen返回结果也是Integer类型,代表字符串的长度

说明:1、以上两个操作不区分正负,所以要是使用incrby操作也可以做减法处理
2、incr存在数据上线,当增加时超过上线会报错(有次数限制时,可以初始设定值为最大值-限定次数,然后每次增加,当达到次数时就报错)
应用: 该方式可以对没有序列(oracle有序列,可以实现自增操作)的关系型数据库mysql,在多表中想要使用同一个变量实现Id不重复并给自增处理。

应用: 对于某些偶像养成类节目,会行使观众投票的权利,比如明日之子中对毛不易的投票是否也有你的贡献呢,他们的比赛都是分阶段的,一般都是20进10啊,10进5啊,每一阶段的投票只在本阶段有效,一般都是在进入下一阶段就会清零,那么对于票数的统计一方面实时性的要求比较高(否则影响了比赛结果咋整),另一方面在一定的时间要失效
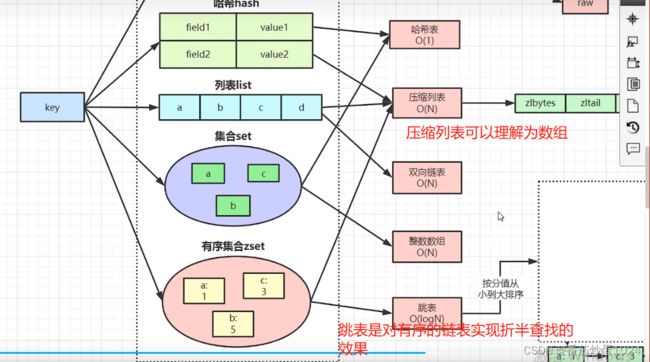
Hash类型:
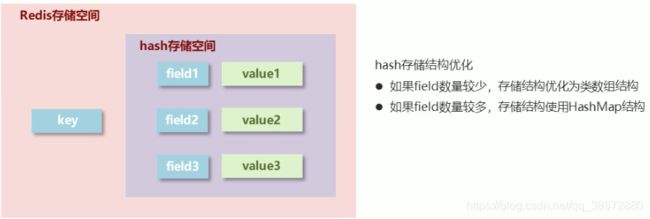
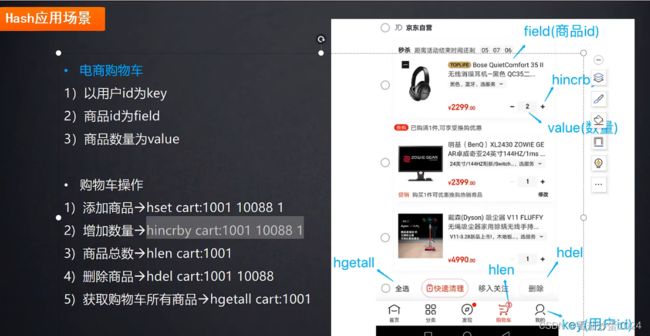
1、hash存储空间部分是对应的redis的value,key可重复,但是相同的field会覆盖原相同field的值。
2、其对应的存储结构根据field数量的多少,决定使用类数组还是hashMap
3、value值只能存放String类型的,不能是其他类型

说明:在做数据存储时,尽量不要将对象直接转换成map形式存放在value中,只存储必要数据即可,并且hgetall指令尽量少用,因为获取的是全部的数据,可能会导致效率下降


说明:hkeys操作是获取key的全部fields的值,而不是字面意思
实现场景:购物车
List类型:
该类型底层使用的是双向链表的存储结构,因此可以双向操作数据,但是链表有个共性特征就是添加方便,但是查询效率比较低

说明:1、pop操作不仅仅有获取的作用,也有删除的作用,因此要是某些数据被pop出来了,链表中就不存在了,比如git stash pop和这个是一样的道理
2、lrange操作时start和stop是索引值,索引从0开始,在不明确list中字段个数的情况下或者想要查看全部的数据,start写0,stop写-1

说明:该方法主要是阻塞的获取并移除数据,可以理解为,当前我做了一个pop操作,但是获取的链表中没有数据,那么我就等着,直到等到我指定的时间(单位为秒);同时我也可以同时等待多个链表,只要任意一个链表有数据我就pop出来
应用: 任务队列,只要有任务进来我就pop出去进行处理
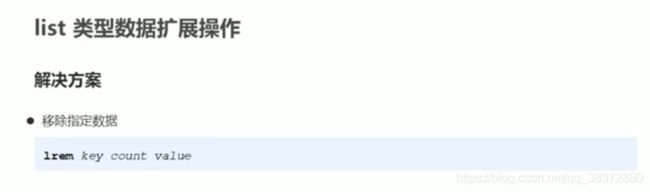
参数解释:count 参数是指的个数,由于list中是有顺序的,并且元素可以重复,所以可以指定删除某列表中指定个数的value
应用: 1、朋友圈点赞:首先有点赞的顺序,其次要是有某个人取消点赞了,那么可以使用该方式实现
2、在网站的首页数据加载的时候,一般情况下第一页的数据都从redis中获取体验会比较好
3、对于多节点部署的程序,当客户端访问时,会随机分配到不同的节点上,那么日志也会记录在不同的节点上,但是要是出现问题的情况下,对于日志的查看就比较麻烦了,因为没有一个连贯的日志记录,同时需要多台服务器之间不停的切换,此时可以使用redis作日志记录的动作,这样不管要去访问哪台服务器都会将日志记录在redis中,并且存储的是List类型的话还可以记录日志的顺序,这样查问题就比较方便了。另外我们也可以查看最新的日志信息,只是看如何操作list类型的数据(pop)
Set类型:
set类型存储一个最大的特点就是存储的数据不能重复,因此在某些网站做数据统计时,有时候会根据同一个ip啊什么的进行限制,或者比如同一个微信号啥的,此时就可以将数据存储在set中
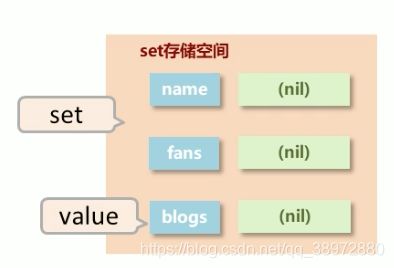
说明:set类型是hash类型的变换,只是将原本hash中存储的value放在field中了,hash类型中要求同一个key的不同field不可重复,这也使得set结构要求存储的数据不可重复,要是出现重复的field,则报错。



说明:以上两种方法都有随机获取元素的作用,但是spop会在获取元素的同时移除元素,但是srandmember不会;因此在一些随机推荐的场景中可以考虑redis的set存储

Sorted_set类型:
在list类型存储时,可以保证元素的顺序,但是这里要保证的是元素的排序,我们可以操作某些条件排序得到想要的结果,在进行添加时score就是要进行排序的条件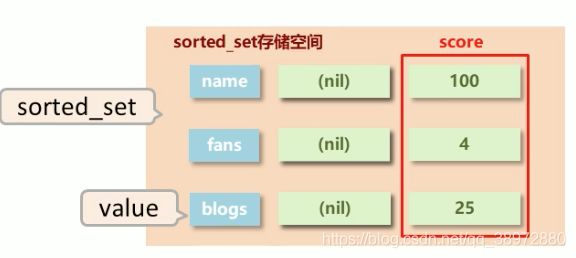

说明:1、zadd时,特别注意score要在member前面(就是存储在hash结构中field位置) 2、删除操作时是根据key和member删除的,而不是根据score删除

说明:1、min 和max都表示的是score的值,主要是想要根据score查询和删除数据
2、要是想要使用limit对查询的结果再进行过滤的话,用法和mysql一样,但是需要注意的是limit需要写在withscores前,limit 0 3 ,0表示索引,3表示个数
3、zremrangebyrank 根据索引操作数据
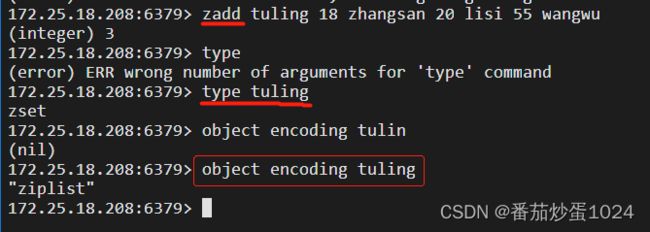
5、Redis中对key的操作
redis存储数据的方式是key-value的形式,上面讲到的数据类型都是指的value的类型,而key只能是String类型,那么对于redis中key的操作如下:
说明:一般情况下,我们提到redis的数据类型时都是说sorted-set类型为zset,主要就是因为在使用type key查看sorted-set类型时显示的是zset
说明:1、ttl操作的返回结果有3种情况,-1 key还存在但是没有设置有效期;-2 key不存在;当前有效时长 key存在且设置了有效期,默认情况下,我们要使用set str str 存储一个key,是没有设置有效期的
2、persist的返回结果是01,0表示失败,1表示成功。对于不存在的key返回0,未设置有效期的也是返回0

说明:1、rename不会判断是否重名,在操作时直接将原来名称的给覆盖了;renamenx会判断重名,在重名时会返回0表示失败
2、sort排序操作也可以使用desc 等关键字(list、set)
Redis客户端
1、Jedis java客户端简单使用
1) Jedis是什么
jedis是java语言连接redis的工具,但是java不是唯一的工具
2) Jedis如何使用
redis既然也是作为一种数据库,那么连接数据库本来有4个步骤:加载驱动(区分数据库)->连接数据库->操作->关闭连接。由于已经确定是连接redis了,所以不需要加载驱动了,只需要后面3步即可,但是使用jedis时需要导入jedis包

连接:new对象,直接添加上地址和端口
操作:和redis客户端指令完全一致
关闭:对象.close()
3) JedisPool如何使用
jedisPool相当于数据库连接池,在获取连接时直接从连接池中获取即可
- 创建连接池
new JedisPool(JedisPoolConfig,host,port)
JedisPoolConfig对象用来设置连接池大小等参数 - 从连接池中获取Jedis连接
JedisPool对象.getResource()
Redis持久化
持久化的目的是为了数据恢复,而在redis进行重启时就会进行数据恢复
1、RDB(快照)
实现方式(save指令 bgsave指令 save配置)
使用RDB进行持久化有3种方式,一、save指令(会被阻塞)二、bgsave(异步) 三、自动触发(redis操作,将save [seconds] [changes] 配置到redis.conf文件,注意:seconds单位为秒)

save指令在执行的时候会阻塞Redis服务器,直到RDB处理完成,因此不建议使用save方式
bgsave:可以解决阻塞的情况,与save不同的是指令的执行不一定是实时的,由后台处理
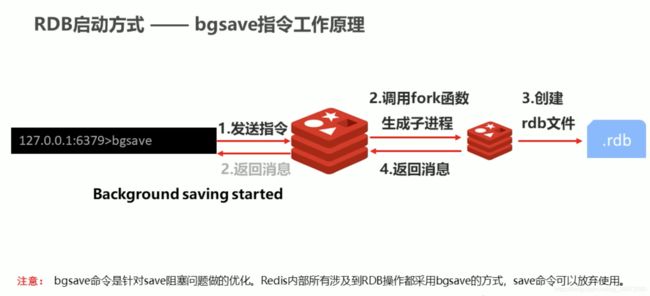
以上两种情况都是由操作redis的手动的通过指令进行持久化的,那么要是在忘记做持久化了怎么办?同时要是对没有变化的redis进行了持久化操作有点浪费资源了,所以出现了save配置的形式
save [seconds] [changes] 配置在redis.conf配置文件中,redis就可以自动的持久化了,底层使用的还是bgsave
解释说明:seconds单位为s,changes是key的变化数量,只要有变化就+1,不比对值,但是多次对同一个key修改,也只是+1

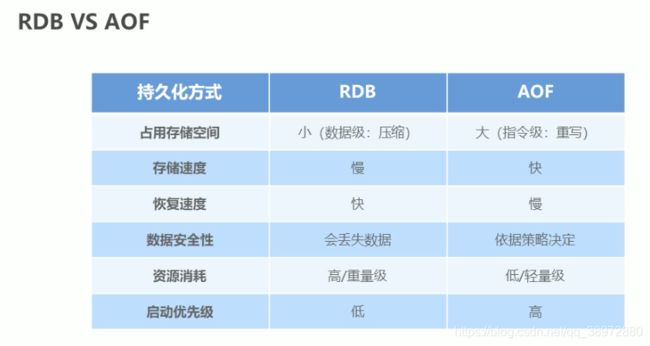
RDB的优缺点:
优点:
1)由于存储的是二进制,存储效率比较高
2)数据恢复能力比AOF高
3)由于可以在一定的时间内存储,适用于数据备份
缺点:
1)bgsave会开辟新的内存、新的线程
2)不能实时持久化,比如10点、11点持久化的,那么10点45的数据就没有持久化
3)不同版本的redis不能兼容rdb文件(dump.rdb)
2、AOF(过程|日志)

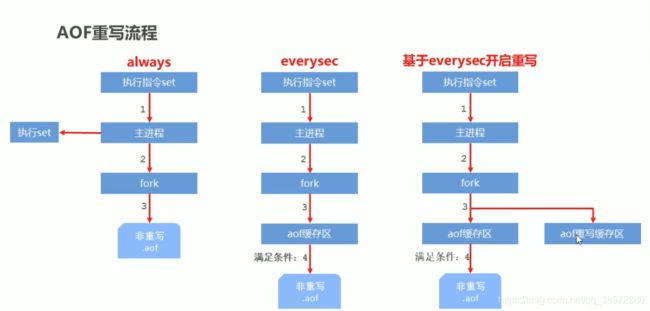
aof是redis持久化的另一种方式,其为了解决RDB方式带来的问题做了调整,因此其特点是:每次持久化都是增量数据,而不是全量数据,只把增量的指令进行存储。我们在处理时优先使用aof
AOF实现方式
要是使用aof进行持久化,需要在redis.conf配置文件中,修改两个参数,1-指明使用aof持久化appendonly yes(配置文件-修改成yes)|no 2-指明持久化的策略(配置文件 appendsync always|everysec|no)

设置好策略后,就会实时(always)|每秒(everysec)将数据进行持久化,持久化的数据存储在配置文件中dir指定的目录下默认叫appendonly.aof文件中,RDB方式生成的文件名叫dump.rdb。当然文件的名称都可以修改(appendfilename 指令),建议名称中添加上端口等明显能标识服务器的名称
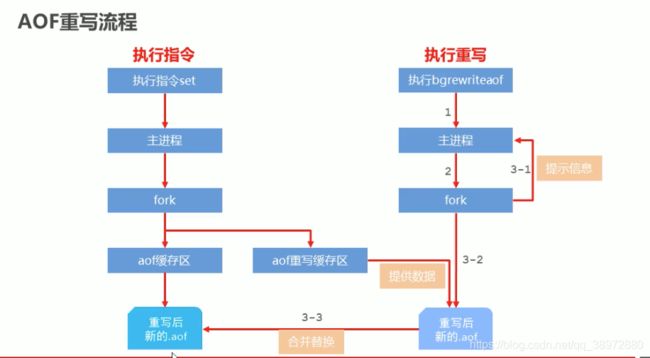
AOF重写
bgrewriteaof 指令,可以对aof的文件进行整理,把操作同一个key的操作整理成最新的数据进行存储
3、RDB VS AOF
3、redis持久化该如何选择
- 一般来说, 如果想达到足以媲美数据库的 数据安全性,应该 同时使用两种持久化功能。在这种情况下,当 Redis 重启的时候会优先载入 AOF 文件来恢复原始的数据,因为在通常情况下 AOF 文件保存的数据集要比 RDB 文件保存的数据集要完整。
- 如果可以接受数分钟以内的数据丢失,那么可以 只使用 RDB 持久化。
- 有很多用户都只使用 AOF 持久化,但并不推荐这种方式,因为定时生成 RDB 快照(snapshot)非常便于进行数据备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快,除此之外,使用 RDB 还可以避免 AOF 程序的 bug。
- 如果只需要数据在服务器运行的时候存在,也可以不使用任何持久化方式。
总之,选择哪种持久化方式还是从各自的优缺点来分析。恢复速度、是否允许数据丢失等。
4、数据恢复
redis的数据恢复主要就是加载两个持久化文件

Redis Key清理策略
1)对过期数据的删除策略
删除的数据都是对redis内存空间server.db[i].expires进行清理(expires存储的是redis的value存储地址和过期时间-有效期),根据某种删除策略要删除数据时,直接根据地址删除
定时删除(实时删除)
过期时实时删除,不考虑cpu(拿时间换空间)
惰性删除(下次访问时删除)
过期后的首次访问时删除(拿空间换时间),每次get的时候实际上都会触发expireIfNeeded()函数,判断key是否存在(是否过期)
定期删除(每秒server.hz次 每个DB随机W个)
根据服务的server.hz参数(执行info server可查看,默认时10),定期删除,每秒执行server.hz次删除操作,每次做的操作是将16个db区域循环处理,而每个db要做的处理是:
1、随机选取W(由配置决定)个key判断是否过期,要是没有过期的直接下一个db,要是有过期的,看下过期key的数量和W的对比,要是>四分之一则继续循环处理当前db,否则下一个db
2、每个db处理时间不能超过250ms/server.hz
3、current_db存储轮询时db的索引

2)内存不足时,对数据逐出策略(淘汰算法)
在向redis中存储数据时,要是遇到内存不足的情况时,redis是如何进行数据清理的。
maxmemory - 最大内存,默认是0-表示不限制,可占用cpu的全部内存
maxmemory-samples – 待删除的数量
memory-policy 一共有8种删除策略,如:memory-policy volatile-lru

说明:每条指令都会绑定freeMemoryIfNeeded()函数,用来判断是否有内存
建议使用检测易失数据策略,纠正下lru-最近最长时间未使用
Redis集群
redis集群主要分为两大部分,一个是主从,一个是cluster集群,但一般情况下都是结合使用的,主从的特征是:master和slave存储的是相同的数据(主要是为了达到高可用目的,解决单点故障问题),而cluster集群是说所有的节点存储的内容是不同的,主要是进行分治和分片(主要是为了达到高性能的目的,解决高并发情况下性能)。分治实现规则:普通hash、一致性hash(hash环)、按槽分区,普通hash存在最主要的问题是当集群进行增加或者减少服务器时,都需要重新计算每个数据的hash,重新进行分配(数据迁移比较麻烦),影响的范围也比较大,因为每个key的计算规则都变了,分母变了。一致性hash对于增加或者减少服务器时-数据迁移这个问题就处理的比较好,所以对于集群的扩展比较好,每次新增或者减少服务时,都只移动操作相邻两个服务器的数据。但是一致性hash会带来数据倾斜(数据分配不均匀,大量数据分配在一台机器上)的问题。按槽分区能很好的解决增减容的问题,也能解决数据倾斜问题,因为按槽分区可以为每个节点分配不同的槽位,所有key取余计算的时候都是16384
1、主从副本(存储相同内容-解决单点故障)
1.1 主从同步的过程(建立连接、数据同步、命令传播)
- 建立连接阶段
使slave能够连接到master
:slave主动使用slaveof masterIp masterport 指令连接master,然后master接收到slave的指令后给予响应,表示连接成功。同时slave会定时的发送ping指令,检测是否与mater进行连接,要是已经断开连接的话,再次进行连接。最终slave会将自己的端口发给master.。最终master存储slave的端口,slave存储master的Ip和端口(连接的时候也会进行数据同步)

建立连接有3种方式:
1)slave客户端主动执行指令,slaveof [masterip] [masterport]
2)启动slave服务器时,直接将slaveof指令跟在redis-server指令后
3)直接放在slave配置文件中,只正常启动服务即可(比较常用的方式)
断开连接: slaveof on one

授权访问,master设置密码后,master的客户端要设置密码,同时slave也要添加

- 数据同步阶段
数据同步主要分为两步骤:全量复制+部分复制
:slave发送psync2指令,master接收到指令后进行bgsave操作,生成rdb文件,同时要是salve第一次连接时还需要创建一个复制缓冲区,用来接收在全量复制过程中master接受的指令,当slave接收到rdb文件后,进行全量复制(全量复制的过程中,会将master的runId和offert偏移量发送给slave)。然后将缓冲区中的数据采用aof的形式进行持久化(当slave接收到aof文件后,会进行bgrewriteaof),再进行部分复制的时候,slave会将runId和偏移量给master,master会比较这两个值,要是这两个值有不同的情况,那么就会继续进行全量复制。
:部分复制的过程中会出现问题,要是缓存区中满了的情况下,会将之前入缓冲区的数据挤掉,这样当slave接收数据的时候就会检测到偏移量不一样,这样又会进行全量复制
: 尽量的避免全量复制,因为全量复制是非常耗时的,因此可以调整缓冲区的大小,也可以将master的runId进行记录,再进行重启的时候给设置上。

- 命令传播阶段
命令传播主要是为了确保数据实时一致,所以master会将部分数据周期性的发送给slave.

1.2 主从复制常见问题


1.3 主从复制作用

1.4 哨兵机制(监督协调作用-解决主从切换)
1.4.1 什么是哨兵

1.4.2 哨兵的作用

1.4.3 哨兵的搭建
主要是修改配置文件,sentinel.config,redis的主要是修改redis.config
1.4.4 哨兵的工作原理
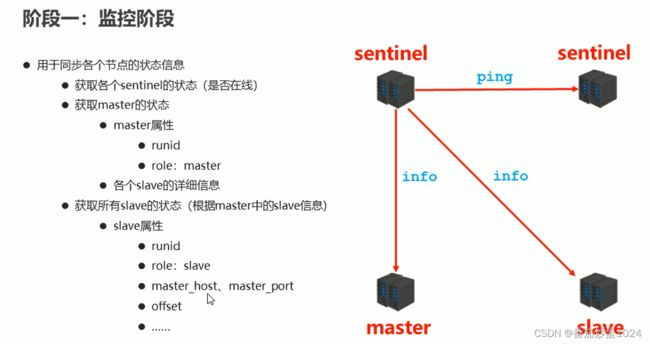
- 监控
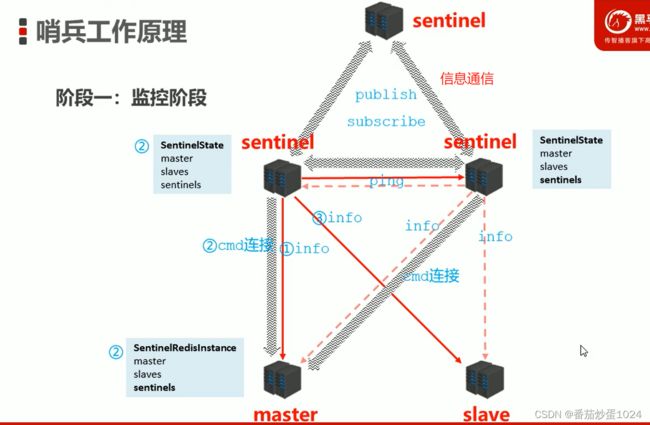
- sentinel间通信
- 自动故障转移
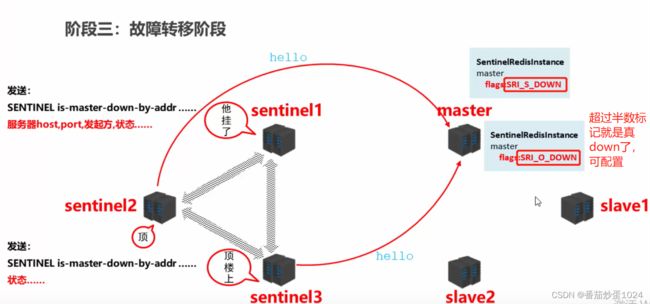
哨兵机制: 主要使用来监控,监控的内容有sentinel、master、slave,以及master与slave之间的关系。当主从复制正常的情况下,哨兵做的事情就是监控着master,然后sentinel之间进行互相通信,要是master宕机了,sentinel就发挥作用了,1)首先一台sentinel监控到master已经宕机了(sentinel.config中可配置一些时间参数,比如超过Xs未活跃,则认为就是down了),会将master的状态设定为s-down,同时将该消息同步给其他的sentinel,其他的sentinel也会去检查是否宕机了,当过半的sentinel(sentinel.config可配置,但是实际场景中也是配置的过半数)都监测到master宕机,会将master的状态更新为o-down. 2)sentinel之间进行投票(过半选举),选择出一个sentinel告知master并将master从主从机制中去除,同时选择出新的master,重新建立主从机制。对于新选择的master,需要有如下特性:活着、响应快、数据是最新的(最近一段时间和原master之间通讯的最频繁)、比较runid 3)重新告知master和slave,使其进行重新连接,就算是过后原来的master又苏醒了,也默认是作为slave

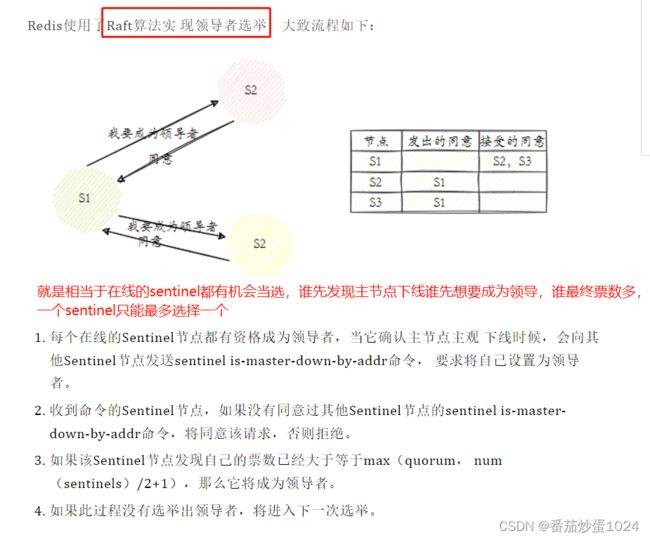
2、cluster集群(存储不同内容-大量热点数据适用)
哨兵机制可以解决主从结构自动故障转移的目的,达到高可用的效果。集群则是一种终极方案,既可以达到高可用的效果,也可以做到数据的分布式存储。
2.1 高可用
redis集群的高可用也是通过自动故障转移实现的。这里也是类似哨兵机制的。只是redis中的每一个节点都是作为监听者,采用心跳的机制(ping-pong)要是某个节点在一定的时间内位收到响应,那么就认为该节点主观下线了。这时我们可以采用虚拟节点的方式解决,将redis服务器多虚拟出n个节点放在hash环的不同位置上。
得到的结果就能找到具体存储的机器,这里的结果就是槽,一台计算机有多个槽,而分槽的目的只是为了达到负载均衡的作用。故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。
2.2 分治规则
普通hash(计算hash后再进行%redis服务器台数)
要存储的key计算完hash后,根据redis服务器的台数,进行取模运算,决定存储在哪台服务器上,这种规则会导致增加或者减少服务器时,对所有key都有影响,都需要重新计算存储位置。
一致性hash(hash环,计算hash后再进行%2的32次方个桶位)
首先将redis服务器要么按照ip要么按照服务名计算hash后取模的方式放在hash环上,然后再将数据也是按照hash后取模放在hash环上,这样数据按照顺时针的方向,找到第一个redis服务器,就是该数据的存储位置了,这样做可以更好的扩展集群,因为要是在集群中添加机器或者是删除机器时,实际上就是槽位置的更改,比如要是在集群中添加几个机器,是将原有计算机中的槽抽离出一部分放在新机器上,这样就可以对原来的机器空间做了处理,要是删除机器时,会将该机器的槽均匀的分配在其他集群机器。但是这样也会存在一个问题-数据分配不均匀,我理解其实hash取模的方式都会产生不均匀
按槽分区
按槽分区是将整个redis分为2的14次方个槽(也就是16384),然后会根据集群中服务器的台数分配槽,可以是均等分配槽,也可以指定不同的数量。
所以当增容或者兼容的时候,只是操作槽就可以了,把槽分配给不同的服务,增容时,是在原有节点上每个节点分一点给新容器,而不是全部重新打乱,所以比hash取余的方式要少移动数据,同时当某个容器数据多时,也可以分给其他节点点槽位。避免数据倾斜。
分槽的目的只是为了达到负载均衡的作用。
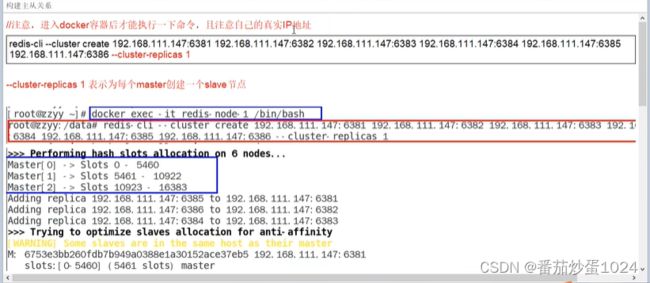
3、docker搭建3主3从集群
3.1 启动6台容器

在每次启动完容器后,都是用docker ps 查询下
3.2 将6台容器构建成一个集群(默认按槽分区)
进入其中的一台容器,建议使用exec进入,这样会启动新的进程,即使当前操作退出了,也只会影响当前线程。
在构建集群的时候,会直接将槽位划分,默认情况下是AA分配。共16384个节点
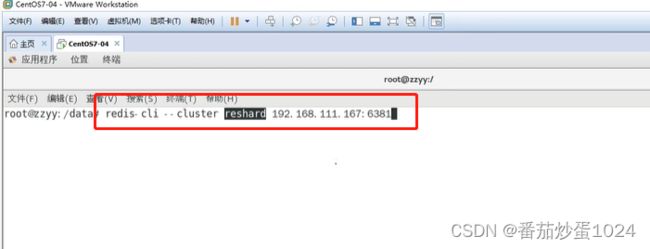
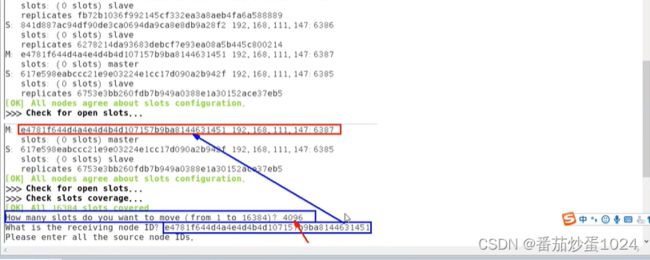
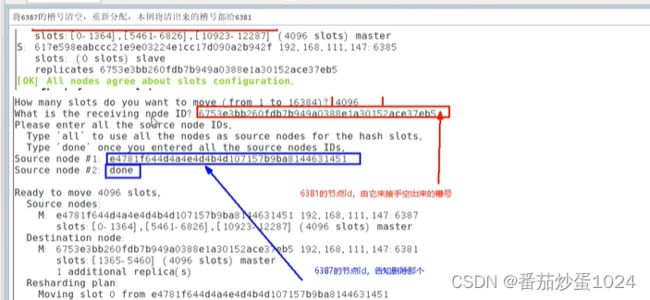
3.3 集群增容
注意:增容的时候,写入的槽位的个数是指新加入的节点想要分配到的槽位数,并且当前这些槽位会均匀的从集群中已知的节点分配,并不会所有的槽位重新打乱
- 添加主节点
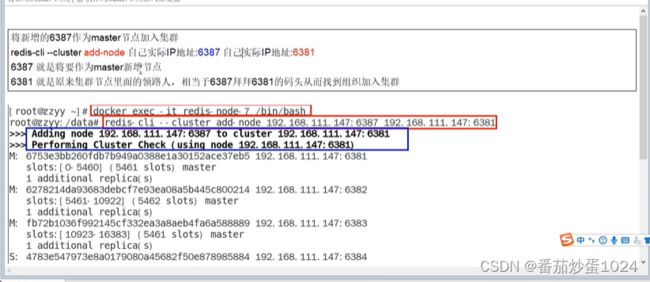
- 分配槽位
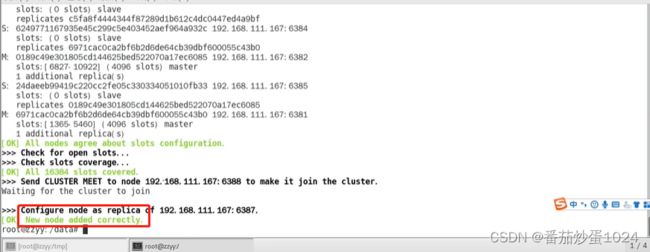
- 添加从节点

添加成功的标识
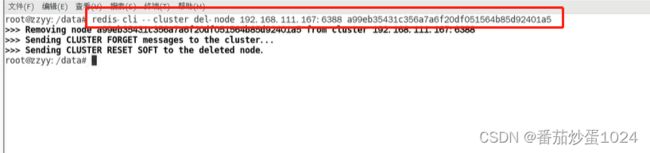
3.4 集群减容
减容的时候,先减从节点->将自己的槽位分配给集群其他节点->减主节点
-
减从节点
-
重新分配槽位(增容和兼容,均是该代码)
-
减主节点
Redis分布式缓存
不管任意一种缓存,缓存的目的一方面是为了快速,更主要的都是为了减少对数据库的访问
1、分布式缓存和本地缓存
这里主要也就是说明下,分布式缓存和本地缓存的区别,以及什么场景下要适用分布式缓存,首先使用缓存的目的指定是为了减少数据库的访问,降低数据的压力,那么要是使用本地缓存的话,对于分布式系统来说,要是访问到服务器A,有本地缓存了,那么要是访问到服务器B,本地没有缓存,就会去访问数据库了,而且在分布式系统中,要是各自缓存的话,还增加了各服务器间缓存不一致的风险。然而我们一般采用分布式缓存都使用redis。因为其速度比较快,再就是有多类型的数据结构。
2、缓存和数据库不一致
原因
- 删除缓存失败,导致不一致
- 在并发场景下,无锁的情况导致向缓存中写入脏数据
解决办法
- 对于缓存删除失败的情况,宗旨就是再删除一遍,可以1)将删除失败的缓存key放入到队列中,然后再次删除,但是这种情况下,对业务的耦合比较大 2)数据库订阅+消息队列,就是启用一个单独的任务处理监控binlog,对要是有变化的数据,随时放入队列,然后再次删除
- 对于产生脏数据的情况下,采用延迟双删策略
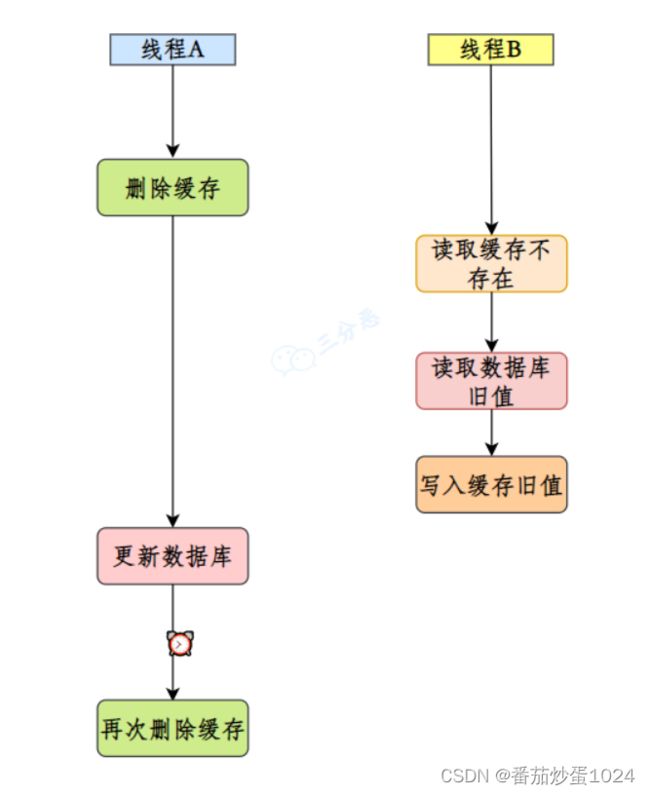
- 最兜底的一个方案就是对缓存要设置合理的过期时间,尽量减少缓存不一致的情况。
- 再就是使用cancal组件,监控binlog,将binlog的数据缓存到redis中
- 这主要看是要达到最终一致性还是强一致性,强一致性的话就得加锁。
2、分布式缓存和本地缓存不一致
由于在分布式的系统中,部署了多个节点,那么本地缓存也是针对某一个节点来说的,基于jvm内存的缓存了,所以各个分布式服务有可能保存的是不一样的数据。一般我们说的使用两级缓存解决缓存击穿(服务器宕机了,不能对外提供服务了,导致大量的key失效)问题就是说的这种情况。


Redis分布式锁
1、锁是什么
锁主要是为了在多线程操作共享变量时,避免出现异常结果,使并行变串行的一种实现方式。而在java学习中我们熟知的一些锁有synchronized还有ReententLock,这些实际上都是本地锁,也可以叫jvm锁,锁住的是一个堆里面的对象或者是方法区中的类对象Class。一般借助于第三方工具的都是分布式锁了,比如redis,mysql,zookeeper,etcd等
2、本地锁(JVM锁)与分布式锁异同
相同:锁住的是同一个对象,锁才会起作用
首先锁能生效,不管是锁住的是对象还是redis中的key,只有操作同一把锁的两个线程才会受到阻塞,不同锁的竞争者之间不会有影响。那么对于分布式系统来说,显著的一个特征就是最起码得有多个服务器部署项目,而jvm是在jdk中的,每个服务器安装了jdk,都会有独立的jvm空间,要是使用本地锁的情况下,锁住的不会是同一个对象,因此两台服务器间的线程就互相约束不了,那么对于程序中的共享变量,处理还是会有问题。
- 本地锁主要是针对单机的,分布式锁主要应用于多机
- 分布式锁由于都依赖于第三方工具,因为每次分布式锁的获取或者尝试加锁啥的操作都是IO操作,但是本地锁都是对jvm的操作。因为在使用分布式锁时要注意性能。
- 分布式锁和本地锁可以结合使用,此时本地锁的作用是从性能方面考虑的,为了减少多线程抢分布式锁时产生的没必要的IO
- 只要使用了锁,不管是本地还是分布式,都是将并行转换为串行处理了,因为要是分布式系统中抢夺的是一把锁时,性能是会非常低的,那么这样和分布式结构式相违背的,因为采用分布式的原因主要是为了提高性能,采用分治的方式将高并发的请求分发到不同的服务器处理,要是用同一把锁,那和用一台服务器多线程处理也没啥区别。
3、分布式锁的分类
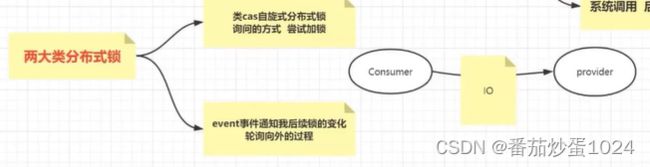
4、分布式锁的应用场景

5、分布式锁实现
(1)、redisTemplate
- pom文件中引入包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.2.11.RELEASE</version>
</dependency>
- 应用
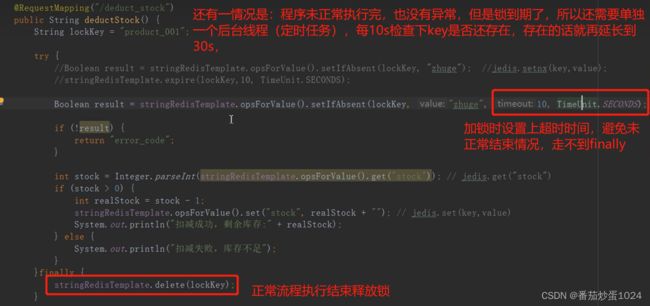
setIfAbsent的底层是使用的setnx和expire,只是单独的方法是原子性的,要是使用setnx和expire这两个方法的话,不是原子性的,要是setnx结束直接异常了,那么过期时间就没有设置成功,就会导致这个key一直存在了,锁持续被占用。
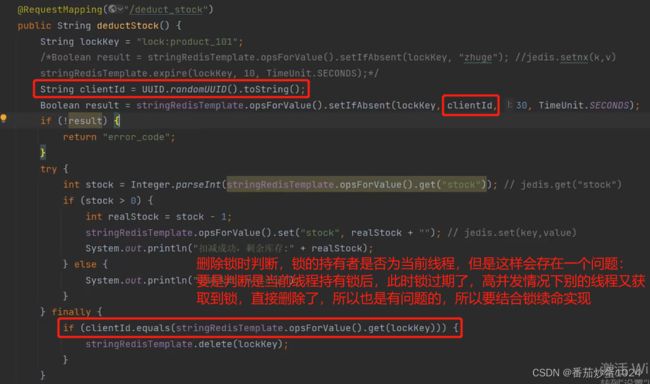
(2)、redission 客户端-主要是在分布式架构中更有优势
- pom中引用redission包
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.0</version>
</dependency>
- 将redission对象注册都Spring容器中,也可以在application.yml中配置
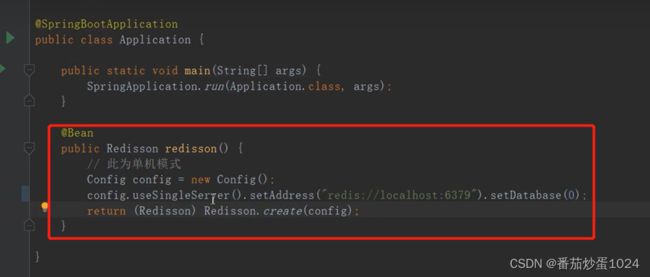
- 方法应用,此处只是一个简单的应用,也可以选择不让其他线程等待锁或者是设置过期时间
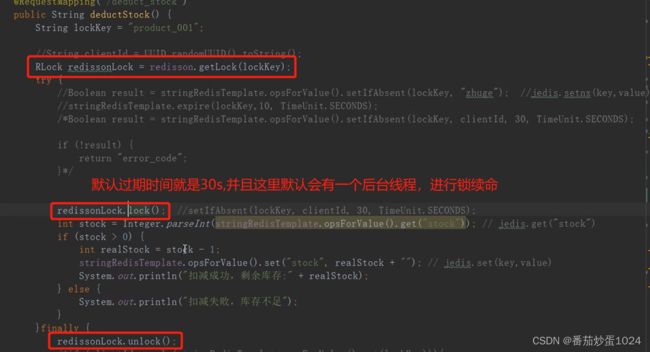
在进行lock时主要做了两件事情 - 1)主要采用lua脚本进行,做的事情就是设置key,同时设置时间,另外会将当前线程的threadId设置到value值,但是由于线程池中线程是循环利用的,所以此处线程ID前也会添加id(UUID)。
- 2)开启电子狗监控,进行锁续命,主要是采用监听器异步回调的方式,不会阻塞当前主线程的执行,但是结合递归方法,每10s就会执行一次,判断当前锁是否存在,并且是否是当前线程,要是当前线程则将时间再次续到30s(使用lock方法,默认锁的过期时间是30s)
6、分布式锁存在的常见问题
一般情况下,使用redis实现分布式锁,主要是使用的setnx+timeout方法,若c1,c2同时竞争,c1获取到锁,c2没有获取到锁。
- 1、c1正常处理完
- 2、c1处理异常了,但是没有释放锁,怎么办?
-> 一般情况下,我们都要给缓存设置时间,使用redis的时候,不管是存储数据,还是用作分布式锁,都可以设置时间。redissionClient.getLock(),默认是30s过期,所以即使没通过unlock手动的释放锁,也会自动过期的。 - 3、c1还没有处理完,锁到期了,那么再次竞争时不一定还能获取到了
-> 为了确保当前线程把任务正常完成,避免锁过期,我们要有一个定时任务来延长锁的过期时间。redission有个WatchDog,可以在每10s钟判断下是否需要延长时间。定时任务在监测的时候,判断剩余时间,要是剩余时间不到指定的阈值,那么就再次续命。 - 4、c2在等待过程中会进行自旋,如何减少自旋
- 5、在判断完当前锁获取得是自己,刚要删除时,锁到期了,这样就误删了别人的锁,所以要有电子狗进行锁续命才可以
- 6、锁丢失,导致多线程竞争。现象描述为:主从结构中,主机key获取设置成功,但是还没向从节点同步,宕机了,再有线程进来时,就可以从从节点获取成功锁,实际上此时锁并没有起到作用。
redis本身就是AP,效率比较高,所以一致性上没有那么强,我们可以使用zk作为缓存,满足过半机制才算是设置成功,这样即使主机宕机了,那么从新选择的从节点还是最新的数据,不会有问题;再就是使用redRock,多向n个redis服务器设置key,也是过半的成功才认为是成功的,只是注意一定不要存在主从的形式,因为一旦出现主从,又会出现丢锁的问题。
Redis确保原子性
1、Redis事务(注意:由于语法错误导致的失败不会使事务回滚 lpush string类型的key-之前已经设置过)
介绍:redis的事务就是为了确保一组连续的指令执行不被破坏
multi -开启事务
exec - 执行事务中指令,只要执行exec则会显示所有的执行过程
discard - 取消事务
watch [key] – 监控某一个key,当监控的key在其他客户端被修改了,则当前客户端的事务就被中断
unwatch [key] – 取消监控某一个key
setnx [key] [value] – 设置的时候要是无返回则设置成功,要是有返回则设置失败,可以通过该指令判断key是否存在,存在则添加失败,否则添加成功(分布式锁的原理-通过一个公用的变量处理)
expires [key] 时间(秒为单位)
2、Lua脚本
Lua脚本也可以确保一组指令的原子性
Redis底层数据结构
Redis缓存常见问题
https://blog.csdn.net/a898712940/article/details/116212825
缓存预热

缓存雪崩
- 短时间内key大量集中过期,从而导致所有请求都去查数据库,一般情况下要么key的失效时间设定的有问题,要么就是集群中机器宕机
- 解决思路:
- 采用加锁计数,或者使用合理的队列数量来避免缓存失效时对数据库造成太大的压力。这种办法虽然能缓解数据库的压力,但是同时又降低了系统的吞吐量。
- 分析用户行为,尽量让失效时间点均匀分布。避免缓存雪崩的出现。
- 如果是因为某台缓存服务器宕机,可以考虑做主备。比如:redis主备,但是双缓存涉及到更新事务的问题,update可能读到脏数据,需要好好解决。
设置多级缓存,并且缓存的时间不一样,但是这样的话还要考虑维护多级缓存的一致性。所以这类问题主要还是从实际业务出发,是否可以接受某种情况,强一致性还是高可用性。
缓存击穿
对于单个已过期key的频繁访问(有可能是高并发的情况下对一个热点key的访问)
解决方案:
1、使用分布式锁,对于构建缓存的只能由一个线程设置。
2、物理上设置当前缓存永不过期,其实逻辑上缓存还是会设置过期时间的,只是相当于有个定时任务,当发现剩余的时间不多时,重新更新缓存的过期时间。
缓存穿透
黑客访问,不管是数据库还是缓存中都不存在的数据,一般是模拟大量不存在的数据,目的就是搞瘫系统。大并发的缓存穿透会导致缓存雪崩。
- 1,如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。但是放在redis中的key都会有删除策略或者是淘汰策略,当清除后还是会有机会访问数据库。同时存储的value值虽然为空,不代表不占用内存空间,所以尽量要设置一个比较短的过期时间。另外可能会出现短暂的数据不一致的情况
- 2,根据缓存数据Key的规则。例如我们公司是做机顶盒的,缓存数据以Mac为Key,Mac是有规则,如果不符合规则就过滤掉,这样可以过滤一部分查询。在做缓存规划的时候,Key有一定规则的话,可以采取这种办法。这种办法只能缓解一部分的压力,过滤和系统无关的查询,但是无法根治。
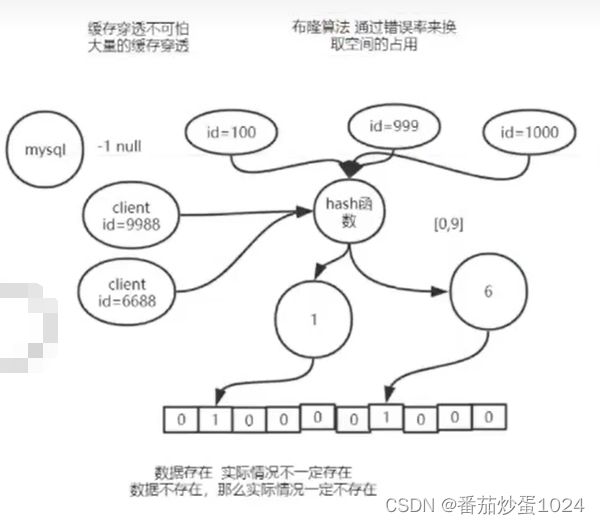
- 3,采用布隆过滤器,首先将数据库中所有的key哈希到一个足够大的BitSet中,匹配到就标记为1(不做重复标记),否则为0,那么当前端有攻击时,我们也会计算hash,若是发现不存在的数据,则表明库里一定没有,那么将会被拦截掉,从而避免了对底层存储系统的查询压力。关于布隆过滤器,详情查看:基于BitSet的布隆过滤器(Bloom Filter)
布隆算法的原则是:标识为1,不一定存在,标识为0,一定不存在
Redis监控指令
- redis-cli -h bj-crs-28x18in9.sql.tencentcdb.com -p 27390 -a hbU++1Y6N1OjkD5p2JBxj4iVX9A= -c monitor > test.log