数字化转型必备:数睿通 2.0 数据中台升级详解
引言
转眼又过了一个月的时间,数睿通 2.0 数据中台也迎来了本月的更新,本次更新主要包括:
- 数据资产完善(资源评价)
- 数据集市完善,打通审批流程
- 修复数据生产由于 Druid SQLUtils 不支持 Doris 导致无法建表的问题
- 优化贴源数据模块,改为读取数据库的元数据,与同步的数据做关联匹配
此外,数据生产模块很多朋友对于 Hadoop 模式下的生产任务用不明白,所以本篇文章会讲解一下数据生产模块 Hadoop Yarn Per-Job 模式和 Yarn Application 模式的使用方式,希望可以对大家有所启发。对数睿通 2.0 数据中台感兴趣的朋友,如果想要获取源码,部署文档等资料,下拉至文末查看。
数据集市完善
该版本对数据资产和数据集市做了进一步完善优化,数据资产完善了资源评价模块,在数据资产模块可以查看评价,数据集市模块则可以评价资源。

在数据集市可以申请数据资产上挂载的资源,管理员通过服务审批模块对用户提交的申请进行审批和授权,对于 API 资源,如果多次申请同一资源,调用次数会在原来的基础上进行累加处理。


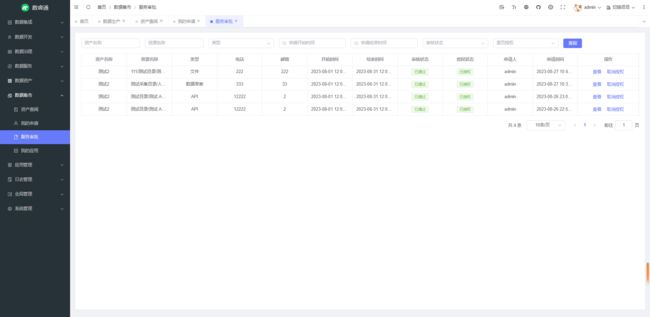
数据集市新增了我的应用子模块,用于获取调用 API 所需的 token,具体逻辑跟数据服务的权限模块基本一致。

数据集市具体的流程流转会在使用视频中进行讲解,在这里就不过多赘述了。
问题处理优化
该版本修复了数据生产由于 Druid SQLUtils 不支持 Doris 导致无法建表的问题,现在数据生产已经可以正常进行 Doris 数据库的DDL 建表操作,后续建表会提供可视化建表,方便对数据模型进行更加直观的梳理。
贴源数据(ODS)模块的数据之前是执行数据接入任务产生的,比如同步了一张 A 表,贴源数据模块就会添加一张 A 表,但是如果人为向中台库中添加 ods 表,这里并不会显示,又或者删除了 A 表,这里也不会同步删除,这就导致实际数据跟库中不一致,所以本次更新改为直接查询中台库的表元数据信息,同时与同步的数据做关联匹配,跟库中实际的表保持一致。
Hadoop 模式讲解
下面我们着重讲解一下数据生产模块 Hadoop Yarn Per-Job 模式和 Yarn Application 模式的使用方式,Local(本地测试用),Standalone,Yarn Session 模式大家都可以轻松驾驭,这三种模式本质其实都是一样的,都是事先启动好一个 Flink 集群实例,然后提交任务,而 Yarn Per-Job 和 Yarn Application 模式则是在任务提交的时候去动态创建 Flink 实例,任务执行完毕后销毁 Flink 实例,不会一直占用服务器资源。
耗时短且密集的任务可以采用 Standalone 和 Yarn Session 模式,避免资源来回释放造成的性能损耗,反之则可以考虑使用 Yarn Per-Job 和 Yarn Application 模式。
Yarn Per-Job 模式在执行前需要获取作业所需的依赖项,通过执行环境分析并取得逻辑计划,将依赖项和 JobGraph 上传到集群中,只有在这些都完成之后,才会触发Flink运行,真正地开始执行作业。试想,如果所有用户同时提交作业,较大的依赖会消耗更多的带宽,而较复杂的作业逻辑翻译成 JobGraph 也需要吃掉更多的CPU和内存,客户端的资源反而会成为瓶颈,为了解决它,社区在传统部署模式的基础上实现了 Application 模式。
在 Yarn Application 模式下,客户端只需要发送部署请求,其他剩余的工作转移到了JobManager 里,执行我们封装好的 Jar 包中的 main 方法,如果一个 main() 方法中有多个 env.execute()/executeAsync() 调用,在Application模式下,这些作业会被视为属于同一个应用,在同一个集群中执行(如果在Per-Job模式下,就会启动多个集群)。
通过上述讲解,大家对执行模式应该有了更加深刻的理解,接下来我们具体讲解一下在数睿通2.0中应该如何正确提交运行 Yarn Per-Job 和 Yarn Application 模式的任务,注意:数据生产微服务必须在 linux 上执行才可以正常提交任务,具体原因是由于 hadoop 本身没有对 windows 平台做兼容,导致在 window 向 hadoop 提交任务的时候会报类找不到的异常。
启动 Hadoop 集群(hdfs,yarn,jobhistory)
Yarn Per-Job 和 Yarn Application 模式任务的运行需要依赖 Hadoop 集群,Hadoop(版本3.3.2) 集群的安装这里不再赘述,产品快速部署指南中有具体的安装教程,安装完毕,配置完环境变量后,通过以下命令启动 Hadoop 集群
# 启动 hdfs
start-dfs.sh
# 启动 yarn
start-yarn.sh
# 启动 jobhistory
mr-jobhistory-daemon.sh start historyserver
启动完毕后,访问 http://ip:9870 查看 hdfs 集群,访问 http://ip:8088/ 查看 yarn 集群,若均访问正常,则启动成功,否则查看日志排查。
上传 flink 运行所需 jar 包
在 hdfs 新建以下几个文件夹:/flink-jar/lib (存放相关依赖包),/flink-app (存放 application模式下的 app 包),/checkpoints,/savepoints。
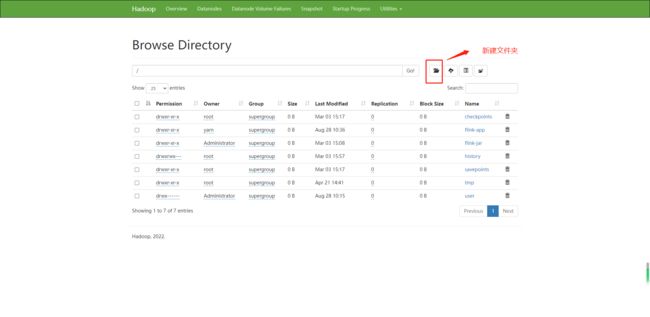
把 flink1.14.3 安装包下的 lib 文件夹下的 jar 包上传到 /flink-jar/lib 下,如果需要程序运行需要依赖其他 jar 包 可以自行添加。

如果是 yarn-application 运行模式,上传代码中的 srt-cloud-framework/srt-cloud-flink/build/app/flink-app.jar 到 hdfs 的 flink-app 目录下。

系统添加 hadoop 集群实例
打开系统的数据开发/资源中心/Hadoop 集群配置模块,添加刚刚部署的 Hadoop 集群实例,ip 改为自己部署的实际 ip

配置 app 路径
如果是 yarn-application 运行模式,还需要配置 flink-app.jar 的路径,打开系统的数据开发/配置中心模块,修改 application 模式的 flink-app.jar 文件路径,改为自己实际配置的路径:
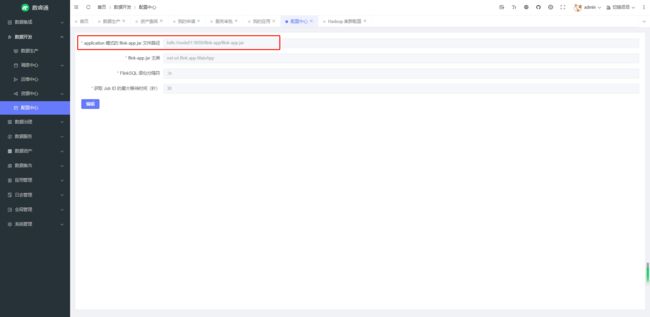
准备工作完毕后,就可以在数据生产模块选择 yarn-per-job 或 yarn-application 模式向 hadoop 集群提交任务了,在 yarn 管理界面可以查看提交的任务以及运行日志(点击 ID -> Logs)。

执行任务的时候,如果是本地搭建的 hadoop,可能会有 yarn 资源不够用的情况,这个时候任务便会执行失败,报内存不足的错误,日志如下:


以上就是 Hadoop 模式的具体使用方式以及注意事项,没有玩明白的小伙伴可以根据以上步骤自行尝试。
git 私服托管代码
数睿通 2.0 的源码目前是加入知识星球获取的,之前的代码都是通过网盘的方式分享给大家,每次都需要重新下载并且不方便比对合并,此次更新搭建了一个 git 私服,星球内的成员可以通过加入私服来查阅代码文件。
结语
本次中台的新功能介绍就到此结束了,目前系统大体的模块该有都有了,剩下的就是不断完善打磨了,希望大家可以继续支持。
目前源码,部署指南,讲解视频等相关资料是付费获取的,价格相比其他同系列的产品连个零头都不到,可以说是非常良心了。我创建了一个知识星球,星球内可以获取到数睿通 2.0 的最新源码资料等,功能发布之后也会第一时间分享。
感兴趣的朋友请关注公众号 螺旋编程极客 加入星球,我们一起成长,一起进步。