JavaScript算法——快速排序
一、概念
快速排序算法由 C. A. R. Hoare 在 1960 年提出。它的时间复杂度也是 O(nlogn),但它在时间复杂度为 O(nlogn) 级的几种排序算法中,大多数情况下效率更高,所以快速排序的应用非常广泛。
注意: 快速排序不一定是最快的排序方法,这取决于需要排序的数据结构、数据量。不过,大多数情况下,面试官和工作场所用它的概率也是相对较高的,所以我们应该花时间把它学透彻。
二、工作原理
-
首先设定一个分界值,通过该分界值将数组分成左右两部分。
-
将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
-
然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
-
重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
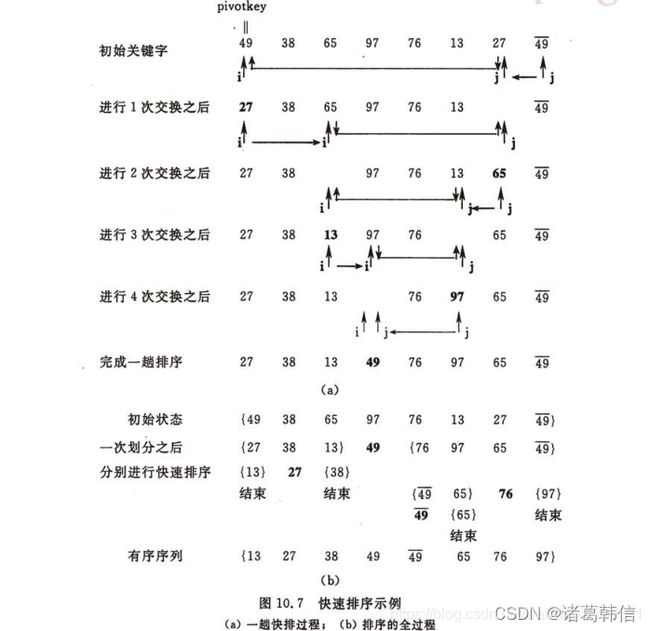
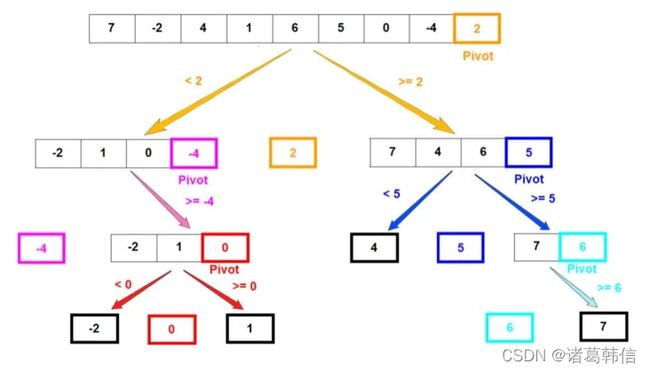
接下来通过一个例子理解这些步骤。假设有一个含有未排序元素 [7, -2, 4, 1, 6, 5, 0, -4, 2] 的数组。选择最后一个元素作为基准。数组的分解步骤如下图所示:
三、动图演示
四、算法分析
a. 复杂度:
快速排序的方法复杂度有时间复杂度和空间复杂度。
时间复杂度往往是决定一个算法优劣的最重要出发点,空间复杂度在当今的计算机上已经没有那么大的影响力了。
快速排序的一次划分算法从两头交替搜索,直到low和high重合,因此其时间 复杂度是O(n) ; 而整个快速排序算法的时间复杂度与划分的趟数有关。
理想的情况:每次划分所选择的中间数恰好将当前序列儿平等分,经过log2n趟划分,便可得到长度为1的子表。这样,整个算法的时间复杂度为O(nlog2n)。
最坏的情况:每次所选的中间数是当前序列中的最大或最小元素,这使得每次划分所得的子表中一个为空表,另一子表的长度为原表的长度-1。这样,长度为n的数据表的快速排序需要经过n趟划分,使得整个排序算法的时间复杂度为O(n2)。
如果需要优化,那么我们希望每次区分的时候都取到中间数。为改善最坏情况下的时间性能,可采用其他方法选取中间数。通常采用“三者值取中”方法,即比较H->r[low].key、H->r[high].key与H->r[(10w+high)/2].key,取三者中关键字为中值的元素为中间数。
空间复杂度在快速排序中平均也是O(log2n))。
从空间性能上看,尽管快速排序只需要一个元素的辅助空间,但快速排序需要一个栈空间来实现递归。最好的情况下,即快速排序的每一趟排序都将元素序列均匀地分割成长度相近的两个子表,所需栈的最大深度为log(n+1);但最坏的情况下,栈的最大深度为n。这样,快速排序的空间复杂度为O(log2n))。
b. 稳定性:
不稳定性的含义:不稳定性是指在原始序列中相等的如果元素按照a1 a2 a3…的顺序排列时,排序之后相等元素的原相对位置改变,比如a3跑到a1前面去了。
举个例子就知道了。假定初始序列为:
[49,27,65,97,30,27*,49*]
运用快速排序算法,得到的有序序列为:
[27*,27,30,49,49*,65,97]
五、 JavaScript 实现快速排序
我们先编写一下操作的主要部分,就是选出一个基准,这个基准的左边的数值比基准值小,而右边的值比基准值大或者相等。因为它操作次数需要重复,一般来说,我们可以用递归方式。不过,也可以写成一般循环方式,但是不建议这么写。
编写为数组分区的代码 partition():
function partition(arr, start, end){
// 以最后一个元素为基准
const pivotValue = arr[end];
let pivotIndex = start;
for (let i = start; i < end; i++) {
if (arr[i] < pivotValue) {
// 交换元素
[arr[i], arr[pivotIndex]] = [arr[pivotIndex], arr[i]];
// 移动到下一个元素
pivotIndex++;
}
}
// 把基准值放在中间
[arr[pivotIndex], arr[end]] = [arr[end], arr[pivotIndex]]
return pivotIndex;
};
代码以最后一个元素为基准,用变量 pivotIndex 来跟踪“中间”位置,这个位置左侧的所有元素都比 pivotValue 小,而右侧的元素都比 pivotValue 大。
最后一步把基准(最后一个元素)与 pivotIndex 交换。
递归实现
function quickSortRecursive(arr, start, end) {
// 终止条件
if (start >= end) {
return;
}
// 返回 pivotIndex
let index = partition(arr, start, end);
// 将相同的逻辑递归地用于左右子数组
quickSortRecursive(arr, start, index - 1);
quickSortRecursive(arr, index + 1, end);
}
在这个函数中首先对数组进行分区,之后对左右两个子数组进行分区。只要这个函数收到一个不为空或有多个元素的数组,则将重复该过程。下面写一个数组验证一下
var arr = [99, 32, 323, 1, -89, 33, 21, 5, 992, -932, 22, 100]
quickSortRecursive(arr, 0, arr.length - 1)
console.log('arr', arr)
输出:
[-932, -89, 1, 5, 21, 22, 32, 33, 99, 100, 323, 992]
循环实现
function quickSortIterative(arr) {
// 用push()和pop()函数创建一个将作为栈使用的数组
stack = [];
// 将整个初始数组做为“未排序的子数组”
stack.push(0);
stack.push(arr.length - 1);
// 没有显式的peek()函数
// 只要存在未排序的子数组,就重复循环
while(stack[stack.length - 1] >= 0){
// 提取顶部未排序的子数组
end = stack.pop();
start = stack.pop();
pivotIndex = partition(arr, start, end);
// 如果基准的左侧有未排序的元素,
// 则将该子数组添加到栈中,以便稍后对其进行排序
if (pivotIndex - 1 > start){
stack.push(start);
stack.push(pivotIndex - 1);
}
// 如果基准的右侧有未排序的元素,
// 则将该子数组添加到栈中,以便稍后对其进行排序
if (pivotIndex + 1 < end){
stack.push(pivotIndex + 1);
stack.push(end);
}
}
}
来一个测试数组
ourArray = [7, -2, 4, 1, 6, 5, 0, -4, 2]
quickSortIterative(ourArray)
console.log(ourArray)
输出:
-4,-2,0,1,2,4,5,6,7
参考文章:
用 JavaScript 实现快速排序
JavaScript实现五种排序算法
关于快速排序的不稳定性说明
JavaScript实现十大排序算法(附有更好理解的GIF动态图)