linux 内核proc 文件系统与seq接口
由于 procfs 的默认操作函数只使用一页的缓存,在处理较大的 proc 文件时就有点麻烦,并且在输出一系列
结构体中的数据时也比较不灵活,需要自己在 read_proc 函数中实现迭代,容易出现 Bug。所以内核黑客们对一
些/proc 代码做了研究,抽象出共性,最终形成了 seq_file(Sequence file:序列文件)接口。 这个接口提供了一
套简单的函数来解决以上 proc 接口编程时存在的问题,使得编程更加容易,降低了 Bug 出现的机会。
新 版 本 内 核 中 的 struct proc_dir_entry 结 构 中 已 经 去 除 了 read_proc 和 write_proc 成 员 , 另 外
proc_file_operations 也被去除。
struct proc_dir_entry {
unsigned int low_ino;
umode_t mode;
nlink_t nlink;
kuid_t uid;
kgid_t gid;
loff_t size;
const struct inode_operations *proc_iops;
const struct file_operations *proc_fops;
struct proc_dir_entry *parent;
struct rb_root_cached subdir;
struct rb_node subdir_node;
void *data;
atomic_t count; /* use count */
atomic_t in_use; /* number of callers into module in progress; */
/* negative -> it's going away RSN */
struct completion *pde_unload_completion;
struct list_head pde_openers; /* who did ->open, but not ->release */
spinlock_t pde_unload_lock; /* proc_fops checks and pde_users bumps */
u8 namelen;
char name[];
} __randomize_layout;
在需要创建一个由一系列数据顺序组合而成的虚拟文件或一个较大的虚拟文件时,推荐使用seq_file接口。
但是我个人认为,并不是只有 procfs 才可以使用这个 seq_file 接口,因为其实 seq_file 是实现的是一个操作函数
集,这个函数集并不是与 proc 绑定的,同样可以用在其他的地方。对于一个函数接口层的学习,首先要看一个
相关的数据结构 struct seq_file:
struct seq_file
struct seq_file {
char *buf; //序列文件对应的数据缓冲区,要导出的数据是首先打印到这个缓冲区,然后才被拷贝到指定
的用户缓冲区。
size_t size; //缓冲区大小,默认为 1 个页面大小,随着需求会动态以 2 的级数倍扩张,
4k,8k,16k...
size_t from; //没有拷贝到用户空间的数据在 buf 中的起始偏移量
size_t count; //buf 中没有拷贝到用户空间的数据的字节数,调用 seq_printf()等函数向 buf 写数
据的同时相应增加 m->count
size_t pad_until;
loff_t index; //正在或即将读取的数据项索引,和 seq_operations 中的 start、next 操作中的
pos 项一致,一条记录为一个索引
loff_t read_pos; //当前读取数据(file)的偏移量,字节为单位
u64 version; //文件的版本
struct mutex lock; //序列化对这个文件的并行操作
const struct seq_operations *op; //指向 seq_operations
int poll_event;
const struct file *file; // seq_file 相关的 proc 或其他文件
void *private; //指向文件的私有数据
};
在这个结构体中,几乎所有的成员都是由 seq_file 内部实现来处理的,程序员不用去关心,除非你要去研
究 seq_file 的内部原理。对于这个结构体,程序员唯一要做的就是实现其中的 const struct seq_operations *op。为
使用 seq_file 接口对于不同数据结构体进行访问,你必须创建一组简单的对象迭代操作函数。
struct seq_operations
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos); //开始读数据项,通常需要在这个函数
中加锁,以防止并行访问数据
void (*stop) (struct seq_file *m, void *v); //停止数据项,和 start 相对,通常需要解锁
void * (*next) (struct seq_file *m, void *v, loff_t *pos); //下一个要处理的数据项
int (*show) (struct seq_file *m, void *v); //打印数据项到临时缓冲区
};
start 在*pos 为 0 时可以返回 SEQ_START_TOKEN,通过这个值传递给 show 的时候,show 会打印表格头。
start 和 next 返回一条数据记录,stop 停止打印,show 显示一条记录。
注意:要在 next 中对 pos 递增处理,但递增的单位与迭代器有关,可能不是 1。
seq_file 内部机制使用这些接口函数访问底层的实际数据结构体,并不断沿数据序列向前,同时逐个输出序
列里的数据到 seq_file 自建的缓存(大小为一页)中。也就是说 seq_file 内部机制帮你实现了对序列数据的读取
和放入缓存的机制,你只需要实现底层的迭代函数接口就好了,因为这些是和你要访问的底层数据相关的,而
seq_file 属于上层抽象。这可能看起来有点复杂,大家看了下面的图就好理解了:
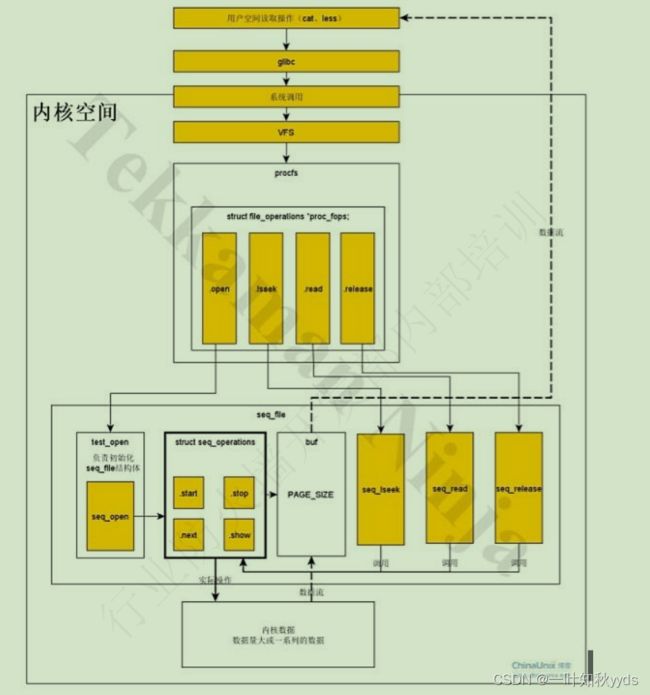
这里我们大致介绍下 struct seq_operations 中的各个函数的作用
start
void * (*start) (struct seq_file *m, loff_t *pos);
start 方法会首先被调用,它的作用是在设置访问的起始点。
m:指向的是本 seq_file 的结构体,在正常情况下无需处理。
pos:是一个整型位置值,指示开始读取的位置。对于这个位置的意义完全取决于底层实现,不一定是字
节为单位的位置,可能是一个元素的序列号。调用 start 不一定是第一次有可能是用户层循环读取,循环读取
时*pos 是有值的,切记!防止出现死循环!
返回值如果非 NULL,则是一个指向迭代器实现的私有数据结构体指针。如果访问出错则返回 NULL。
设置好了访问起始点,seq_file 内部机制可能会使用 show 方法获取 start 返回值指向的结构体中的数据到
内部缓存,并适时送往用户空间。
show
int (*show) (struct seq_file *m, void *v);
show 方法就是负责将 v 指向元素中的数据输出到 seq_file 的内部缓存,返回 0 即可,但是其中必须借助
seq_file 提供的一些类似 printf 的接口函数:
int seq_printf(struct seq_file *m, const char *f, ...)
专为 seq_file 实现的类似 printf 的函数;用于将数据常用的格式串和附加值参数.你必须将给 show 函数
的 set_file 结构指针传递给它。如果 seq_printf 返回-1,意味着缓存区已满,部分输出被丢弃。但是大部分时候
都忽略了其返回值。
int seq_putc(struct seq_file *m, char c)
int seq_puts(struct seq_file *m, const char *s)
类似 putc 和 puts 函数的功能,sfile 参数和返回值与 seq_printf 相同。
int seq_write(struct seq_file *seq, const void *data, size_t len)
直接将 data 指向的数据写入 seq_file 缓存,数据长度为 len。用于非字符串数据。
int seq_path(struct seq_file *m, struct path *path, char *esc)
这个函数能够用来输出给定目录项关联的文件名,驱动极少使用。
其他操作函数请看 seq_file.c 文件中的实现。
在 show 函数返回之后,seq_file 机制可能需要移动到下一个数据元素,那就必须使用 next 方法。
next
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
v:是之前调用 start 或 next 返回的元素指针,可能是上一个 show 已经完成输出所指向的元素。
pos:需要移动到的元素索引值。
在 next 实现中应当递增 pos 指向的值,但是具体递增的数量和迭代器的实现有关,不一定是 1。而 next 的
返回值如果非 NULL,则是下一个需要输出到缓存的元素指针,否则表明已经输出结束,将会调用 stop 方法做
清理。
stop
void (*stop) (struct seq_file *m, void *v);
在 stop 实现中,参数 m 指向本 seq_file 的结构体,在正常情况下无需处理。而 v 是指向上一个 next 或 start
返回的元素指针。在需要做退出处理的时候才需要实现具体的功能。但是许多情况下可以直接返回。
在 next 和 start 的实现中可能需要对一个序列的函数进行遍历,而在内核中,对于一个序列数据结构体的
实现一般是使用双向链表或者哈希链表,所有 seq_file 同时提供了一些对于内核双向链表和哈希链表的封装接
口函数,方便程序员实现对于通过链表链接的结构体序列的操作。这些函数名一般是seq_list_*或者seq_hlist_*,
这些函数的实现都在 fs/seq_file.c 中,有兴趣的朋友可以看看。