李宏毅机器学习第十八周周报GAN2
文章目录
- week 18 GAN2
- 摘要
- Abstract
- 一、Theory behind GAN
-
- 1. 训练目的
- 2. Wasserstein distance
- 二、文献阅读
-
- 1. 题目
- 2. abstract
- 3. 网络架构
-
- 3.1 Wasserstein Distance
- 3.2 Wassertein GANs
- 3.3 Gradient penalty
- 4. 文献解读
-
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
-
- 4.3.1 Difficulties with weight constraint
- 4.3.2 单一数据集上训练随机架构
- 4.3.3 LSUN上训练多种框架
- 4.3.4 改进权重裁剪的性能
- 4.3.5 CIFAR-10和LSUN的样本质量
- 4.3.6 使用连续的生成器对离散数据进行建模
- 4.4 结论
- 三、WGAN
-
- 小结
- 参考文献
week 18 GAN2
注:关于wasserstein的详细解释见第二部分3.1
摘要
本文主要讨论了生成式对抗神经网络。首先,本文介绍了Original GAN的缺点。在此基础下,本文阐述了多种改进GAN的方案。例如,以Wasserstein distance为评价标准构建WGAN。其次本文展示了题为Improved training of wasserstein GANs的论文主要内容。这篇论文探讨了WGAN的结构,并给出了其在训练过程中难以收敛,或者收敛后效果不佳的原因。在此基础上,该文提出了基于gradient penalty的新框架,该框架能够充分利用网络容量以及降低梯度爆炸以及消失。最后,本文基于pytorch以及MNIST数据集实现了WGAN绘制手写数字。
Abstract
This article mainly discusses Generative Adversarial Networks (GANs). Firstly, this article introduces disadvantage of Generative Adversarial Networks. Building upon this foundation, the article elucidates the improvement scenarios of GANs. For example, WGAN’s evaluation criterion is the Wasserstein distance. Next, the article presents the key contents of the paper titled “Improved training of wasserstein GANs”. This paper explores the structure of WGAN and gives the reasons why it is difficult to converge during training, or does not work well after convergence. On this basis, this paper proposes a new framework based on gradient penalty, which can make full use of network capacity and reduce gradient explosion and disappearance. Finally, based on PyTorch and the MNIST dataset, this article implements WGAN to generate hand-written digits.
一、Theory behind GAN
1. 训练目的
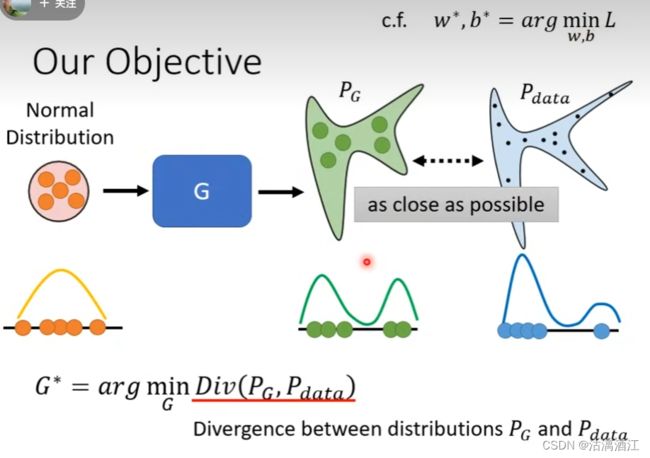
生成器的目标是使得生成数据分布 P G P_G PG尽可能逼近真实数据分布 P d a t a P_{data} Pdata
使用公式表达,即 G ∗ = a r g min G D i v ( P G , P d a t a ) G^*=arg\min_GDiv(P_G,P_{data}) G∗=argminGDiv(PG,Pdata),
或称使得真实分布与生成分布之间的差异尽可能小
在其他模型中,难以对生成式目标的数据分布进行拟合,但在GAN中提供了计算了拟合分布与真实分布之间差异的方案
该方案依赖于生成式对抗网络的结构。首先数据获取,从数据库采样一部分真实数据,然后将简单向量取样并输入生成器,生成器会根据输入向量以及当前的拟合分布输出样本。其次是下文讲解的辨别器部分

以下按照原文中二元分类器的思路进行讲解辨别器
训练目标 D ∗ = a r g max D V ( D , G ) D^*=arg\max_DV(D,G) D∗=argmaxDV(D,G),即该值与JS差异相近(具体推导详见week17)
由此设计对应的目标函数 V ( G , D ) = E y ∼ P d a t a [ l o g D ( y ) ] + E y ∼ P G [ l o g ( 1 − D ( y ) ) ] V(G,D)=E_{y\sim P_{data}}[logD(y)]+E_{y\sim P_G}[log(1-D(y))] V(G,D)=Ey∼Pdata[logD(y)]+Ey∼PG[log(1−D(y))]
上述函数的目的是增强分辨器识别真实分布的能力,从而当取真实数据时D(y)越大,当取生成数据时D(y)越小
也可以将其理解为负的交叉熵,而训练的目的是使得两个分布之间的交叉熵尽可能小
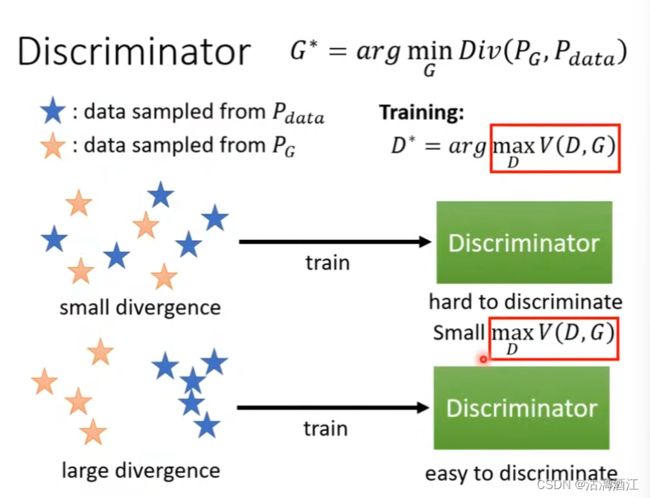
简单来说,在初始阶段两个分布的差异较大,分类器能够很简单的分辨出两个分布。因此生成器能够趋近真实分布,即缩小两者的差异。此时,分类器难以分辨出真实分布与生成分布。(具体推导详见week17)
综上, G ∗ = a r g min G max D V ( G , D ) G^*=arg\min_G\max_DV(G,D) G∗=argminGmaxDV(G,D),从而可以按照week17第一部分中阐述的训练过程训练模型
且 D ∗ = a r g max D V ( D , G ) D^*=arg\max_DV(D,G) D∗=argmaxDV(D,G),该最大目标值与JS差异相关
当然也可以使用其他的目标函数,详见divergence。该文针对目标函数的选取对GAN训练难度的影响进行了研究。
根据该文的研究,GAN并不能通过更换目标函数变得特别容易训练,GAN难以训练
2. Wasserstein distance

在大部分情况下,二者均未重叠。首先,从数据的本质来看,两个分布均是高维空间的低维流形。这使得两个分布的重叠部分极少。其次,通过采样的方式来训练网络,但通常采样仅占分布的极小部分,这使得模型无法通过样本感知两个分布已经重叠的部分。

若从损失函数的角度来解释,JS差异在两个分布没有重叠的时候通常是log2,因此训练并不一定能使得模型变得越来越好,相反通常模型并不会有改进
更进一步的,在两个分布并未重叠的情况下,二元分类器仍然可能达到100%准确率。例如上文中阐述的情况,二维平面中两个线相交,但相交的部分仅占分布的极小部分。此时两个分布并没有实质重叠,但对于分类器而言,其仅能感知到两条线的重叠部分,故此时分类器收敛。
上述部分分别从数据特征以及损失函数角度,阐述了JS差异在该类模型上难以取得较好效果的原因。接下来,给出wasserstein distance的解释以及该损失函数能够通过怎样的操作提高模型的效果
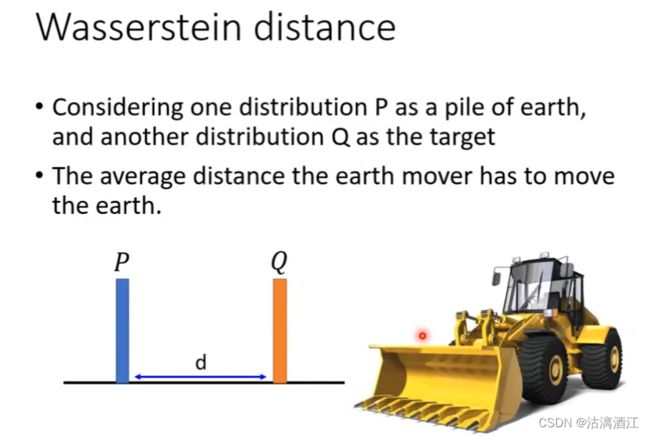
简单来说,该类损失函数计算将生成分布还原为真实分布的距离均值。但对于高维的情况,可能存在多种解决方案,此时需要遍历所有的解决方案,选取其中距离均值最小的一个方案执行。
该损失函数相较于JS divergence能够更好的表达两个分布之间的差异,从而能够趋势两个分布从距离上的接近,而非直接判断两个分布是否重合。
下面给出评估真实部分与生成分布之间wassertein distance的公式
max D ∈ 1 − L i p s c h i t z { E y ∼ P d a t a [ D ( y ) ] − E y ∼ P G [ D ( y ) ] } \max_{D\in 1-Lipschitz}\{E_{y\sim P_{data}}[D(y)]-E_{y\sim P_G}[D(y)]\} D∈1−Lipschitzmax{Ey∼Pdata[D(y)]−Ey∼PG[D(y)]}
分辨器的训练目标是当数据来自真实分布时D(y)取值更大,当数据来自生成分布时D(y)取值更小
分辨器的函数 D ( y ) D(y) D(y)选取也是有要求的,该函数应当足够平滑。
若函数不满足上述要求,例如在真实分布区域无穷大,生成分布区域无穷小,则模型无论怎么控制其学习率都难以收敛。相反当满足要求时,当两个分布距离较近时,算出的wassertein distance较小。
以下给出几种实现上述目标函数的方案

在原文中(Original WGAN),主要针对 1 − L i p s c h i t z 1-Lipschitz 1−Lipschitz给出了方程,但相对粗糙
即将参数w强制设置在 [ c , − c ] [c,-c] [c,−c], i f w > c , w = c ; i f w < − c , w = − c if\ w>c,\ w=c;\ if\ w<-c,\ w=-c if w>c, w=c; if w<−c, w=−c
而在improved WGAN中,使用了gradient penalty的策略,将真实分布与生成分布之间的梯度保持在1附近
Spectral Normalization中实现了上述要求,且达到了较好的效果
二、文献阅读
1. 题目
题目:Improved training of wasserstein GANs
作者:Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron Courville
期刊:NIPS’17(In Proceedings of the 31st International Conference on Neural Information Processing Systems)
2. abstract
作者发现WGAN的问题是由其在权重修正过程中判别器强制实施的Lipschitz约束导致的。从而进一步提出权重修正的替代方案,通过输入的梯度范数来控制判别器。该文证明了其方法相较于WGAN的优越性。该方法能够在不经过超参数调整的情况下稳定训练各种GAN框架。
The authors found that the Lipschitz constraints imposed by the discriminator during weight correction causes the problem with WGAN. Therefore, this article proposes an alternative to weight correction, which controls the discriminator by the input gradient norm. This paper proves the superiority of the proposed method over WGAN. This method can stably train various GAN frameworks without hyperparameter adjustment.
3. 网络架构
该文的分辨器并没有分类行为,因此其在文中将其称为criticz批评器,但本文依然采用分辨器的说法。
GAN网络的目标为
min G max D E x ∼ P r [ log ( D ( x ) ) ] + E x ~ ∼ P g [ log ( 1 − D ( x ~ ) ) ] , (1) \min_G\max_D \mathbb E_{\mathcal x\sim\mathbb P_r}[\log(D(\mathcal x))]+\mathbb E_{\tilde {\mathcal x}\sim \mathbb P_g}[\log(1-D(\tilde {\mathcal x}))], \tag{1} GminDmaxEx∼Pr[log(D(x))]+Ex~∼Pg[log(1−D(x~))],(1)
前文以及上周周报中已经多次给出详细解释,因此不再解释
3.1 Wasserstein Distance
Total Variation: sup A ∣ P ( A ) − Q ( A ) ∣ = 1 2 ∫ ∣ p − q ∣ Hellinger: ∫ ( p − q ) 2 L 2 : ∫ ( p − q ) 2 χ 2 : ∫ ( p − q ) 2 q \text{Total Variation:}\ \sup_A|P(A)-Q(A)|=\frac12\int|p-q|\\ \text{Hellinger:}\ \sqrt{\int(\sqrt p-\sqrt q)^2}\\ L_2:\int(p-q)^2\\ \chi^2:\ \int{\frac{(p-q)^2}{q}} Total Variation: Asup∣P(A)−Q(A)∣=21∫∣p−q∣Hellinger: ∫(p−q)2L2:∫(p−q)2χ2: ∫q(p−q)2
上述距离度量忽略了概率分布之间的几何特性,均是对应点的概率密度函数相比较。但Wasserstein距离具备这种能力
Wasserstein距离不仅告诉两个分布之间的距离,而且能够告诉我们它们具体如何不一样,即如何从一个分布转化为另一个分布
下图对Wassertein Distance给出了较为详细的介绍,接下来给出WGAN对于GAN的修正

3.2 Wassertein GANs
使用 Kantorovich-Rubinstein对偶性构造WGAN值函数
min G max D ∈ D E x ∼ P r [ D ( x ) ] − E x ~ ∼ P g [ D ( x ~ ) ] (2) \min_G\max_{D\in \mathcal D}\mathbb E_{\mathcal x\sim \mathbb P_r}[D(\mathcal x)]-\mathbb E_{\tilde{\mathcal x}\sim \mathbb P_g}[D(\tilde{\mathcal x})] \tag{2} GminD∈DmaxEx∼Pr[D(x)]−Ex~∼Pg[D(x~)](2)
其中 D \mathcal D D是1-Lipschitz函数的集合, P g \mathbb P_g Pg是由 x ~ = G ( z ) , z ← p ( z ) \tilde x=G(z),z\leftarrow p(z) x~=G(z),z←p(z)隐式定义的模型分布
在最优判别器下,最小化相对于生成器参数的价值函数可以最小化 W ( P r , P y ) W(\mathbb P_r,\mathbb P_y) W(Pr,Py)
WGAN 值函数产生一个损失函数,其相对于其输入的梯度比GAN的损失函数表现得更好,从而使生成器的优化变得更加容易。
为了对辨别器实施 Lipschitz 约束,原文建议将辨别器的权重限制在一个紧凑的空间内 [-c, c]。满足此约束的函数集是某些 k 的 k-Lipschitz 函数的子集,这取决于 c 和辨别器的架构。
在了解了WHGAN辨别器的属性之后,该文提出了如下假设,并推出

3.3 Gradient penalty

该文提出了一种WGAN的惩罚函数的替代方案,直接约束分辨器的输出相对于其输入的梯度范数。对随机样本 x ^ ∼ P x ^ \hat x\sim \mathbb P_{\hat x} x^∼Px^的梯度范数进行惩罚。有新目标函数
L = E x ~ ∼ P y [ D ( x ~ ) ] − E x ∼ P r [ D ( x ) ] + λ E x ^ ∼ P x ^ [ ( ∣ ∣ ∇ x ^ D ( x ^ ) ∣ ∣ 2 − 1 ) 2 ] (3) L=\mathbb E_{\tilde x\sim \mathbb P_y}[D(\tilde x)]-\mathbb E_{x\sim \mathbb P_r}[D(x)]+\lambda\mathbb E_{\hat x\sim \mathbb P_{\hat x}}[(||\nabla_{\hat x}D(\hat x)||_2-1)^2] \tag{3} L=Ex~∼Py[D(x~)]−Ex∼Pr[D(x)]+λEx^∼Px^[(∣∣∇x^D(x^)∣∣2−1)2](3)
第一项为原分辨器损失,第二项为梯度惩罚
Sampling distribution 隐式定义 P x ^ P_{\hat x} Px^ 沿从数据分布 Pr 和生成器分布 Pg 采样的点对之间的直线均匀采样。沿着直线强制执行单位梯度范数约束。
Penalty coefficient 本文中的所有实验都使用 λ \lambda λ = 10,它在从玩具任务到大型 ImageNet CNN 的各种架构和数据集上都能很好地工作。
No critic batch normalization 批量归一化改变了判别器问题的形式,从将单个输入映射到单个输出到从整个数据映射一批输入到一批输出。原惩罚训练目标在这种情况下不再有效,因为独立地对每个输入而不是整个批次的分辨器梯度范数进行惩罚。为了解决这个问题,只需在模型的分辨器中省略批量归一化。特别地,将层归一化作为批量归一化的直接替代品
Two-sided penalty 梯度范数趋向于 1(两侧惩罚),而不是仅仅保持在 1 以下(一侧惩罚)。从经验上看,这似乎不会对分辨器造成太大限制,可能是因为无论如何,最优 WGAN 批评家在 Pr 和 Pg 下以及之间的大部分区域中几乎到处都具有范数 1 的梯度。
4. 文献解读
4.1 Introduction
GAN网络能够生成视觉效果经验的结果,但缺乏稳定的训练方法。而WGAN要求判别器必须位于1-Lipschitz函数的空间内,该约束通过权重修正强制执行
该文展示了判别器权重修正的弊端,并提出梯度惩罚(WGAN-GP),从而避免了发现的弊端。在此基础上,该文展示了各种GAN框架的稳定训练、权重裁剪的性能改进、高质量图像生成以及无需任何离散采样的字符级GAN语言模型
4.2 创新点
- 研究并展示了WGAN中的权重裁剪问题
- 在分辨器损失中引入了新的惩罚项
4.3 实验过程
4.3.1 Difficulties with weight constraint
本节主要介绍该文在验证WGAN的权重裁剪方面的研究,该文发现WGAN中的权重裁剪会导致优化困难,且既是成功,所获得的辨别其也可能由病态的value surface。但以下提及的容量未充分利用以及梯度爆炸和消失可以采用该文文中提出的方法解决
实验使用[2]中的特定形式的权重约束(每个权重大小的强制裁剪),也包括其他权重约束(L2范数裁剪、权重归一化)以及软约束(L1和L2权重衰减)并发现它们表现出类似的问题。
在某种程度上,这些问题可以通过分辨器中的批量归一化来缓解,[2]的所有实验中都使用了批量归一化。然而,即使使用批量归一化也观察到深层的 WGAN 辨别器常常无法收敛。
Capacity underuse

通过权重修正达到k-Lipshitz约束会使得分辨器倾向于更简单的函数。为了证明这一点,通过权重裁剪来训练 WGAN分辨器,使其在几个玩具分布上达到最优,将生成器分布 Pg 固定在真实分布加上单位方差高斯噪声。在上图为分辨器的价值面。在分辨器中省略了批量归一化。在每种情况下,经过权重裁剪训练的分辨器都会忽略数据分布的更高矩,而是对最优函数进行非常简单的近似建模。
Exploding and vanishing gradients
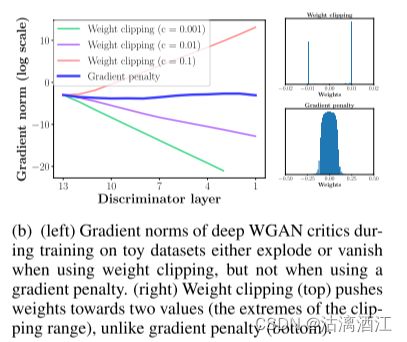
不合适的阈值c很容易导致梯度爆炸或者消失。为了证明这一点,在 Swiss Roll 玩具数据集上训练 WGAN,改变 [ 1 0 − 1 , 1 0 − 2 , 1 0 − 3 ] [10^{-1}, 10^{-2}, 10^{-3}] [10−1,10−2,10−3] 中的裁剪阈值 c,并绘制分辨损失相对于连续层的梯度范数的激活。生成器和分辨器都是没有批量归一化的 12 层 ReLU MLPs。上图显示,对于每个值,当网络中进一步向后移动时,梯度要么呈指数增长,要么呈指数衰减。
上图左侧为分辨器层的梯度范数,而右上角为WGAN的生成分布,右下角为gradient penalty的生成分布。显然gradient penalty在充分利用网络容量的同时降低了梯度爆炸与消失发生的概率。
4.3.2 单一数据集上训练随机架构
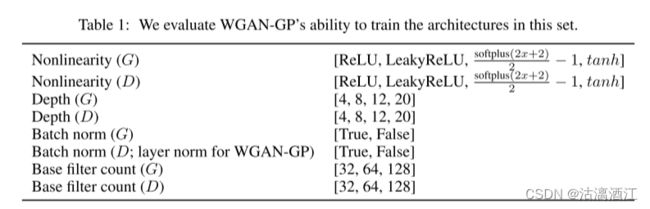
通过实验证明了模型训练大量架构的能力。从 DCGAN 架构开始,将模型设置更改为上表中的随机对应值来定义一组架构变体。

从这个集合中,对 200 个架构进行了采样,并使用 WGAN-GP 和标准 GAN 目标在 32$\times$32 ImageNet 上对每个架构进行训练。上表列出了其中以下任一情况的实例数量:仅标准 GAN 成功、仅 WGAN-GP 成功、两者均成功或均失败,其中成功定义为初始分数 > 最低分数。
4.3.3 LSUN上训练多种框架
为了展示模型使用默认设置训练多种框架的能力,在LSUN数据集上训练了六种不同的GAN框架,此外,还训练了基础模型DCGAN。框架如下:
- 生成器中没有BN和恒定数量的滤波器
- 4层512维ReLU MLP生成器
- 分辨器或生成器中均不进行归一化
- 门控乘法非线性
- tanh非线性
- 101ResNet生成器和分辨器
对于每种架构,使用四种不同的 GAN 方法训练模型:WGAN-GP、带权重裁剪的 WGAN、DCGAN 和最小二乘 GAN。对于每个目标,使用该工作中推荐的默认优化器超参数集(LSGAN 除外,在其中搜索学习率)。
对于 WGAN-GP,用层归一化替换判别器中的任何批量归一化。对每个模型进行 20 万次迭代训练。使用 WGAN-GP 使用一组共享超参数训练每个架构。
下图展示了训练效果

4.3.4 改进权重裁剪的性能
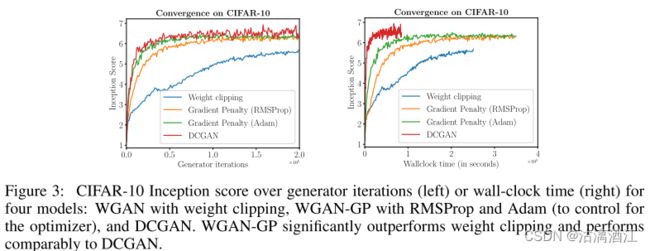
在CIFAR 10上使用权重裁剪和梯度惩罚训练WGAN,并在上图中绘制训练过程中的Inception分数。对于WGAN-GP,使用与WGAN相同的优化器(RMSProp)和学习率训练一个模型,并使用权重裁剪,另一个模型使用Adam和更高的学习率。在使用相同的优化器的情况下,文中方法也比权重裁剪收敛得更快,得分更高。使用Adam可以进一步提高性能。此外,还绘制了DCGAN的性能。该方法最终分数低于DCGAN,但收敛过程更稳定。
上图左侧,横轴为生成器迭代次数,上图右侧,横轴为时间刻(以秒为单位)
4.3.5 CIFAR-10和LSUN的样本质量
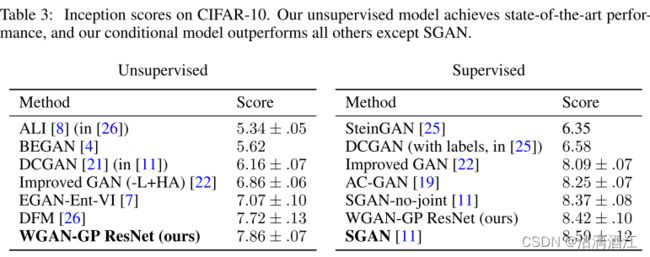
对于等效架构,该方法实现了与标准 GAN 目标相当的样本质量。因为更高的稳定性,所以可以使用该方法训练更为复杂的模型。为了证明这一点,架构在无监督的 CIFAR-10 上建立了新的最先进的 Inception 分数。当添加标签信息时,相同的架构优于除 SGAN 之外的所有其他已发布模型。上表为CIFAR-10上使用监督学习模式以及无监督学习模式的各个框架的Inception分数
此外,还 128 × 128 128\times 128 128×128在LSUN上训练深度ResNet,样本如下图所示。

4.3.6 使用连续的生成器对离散数据进行建模
使用GAN建模复杂离散分布的问题,GAN的生成器是在连续空间上定义的。在Google Billion Word数据集上训练字符集GAN语言模型。生成器和分辨器是一个简单的一维CNN,通过一维卷积确定性将潜在向量转换为32个one-hot字符向量的序列。输出使用softmax非线性输出,不适用采样步骤,直接将输出传递到分辨器。解码样本时,只取每个输出向量的argmax
在该实验中,模型经常出现拼写错误(可能是因为它必须独立输出每个字符),但仍然设法学习了很多有关语言统计的知识。无法产生与标准 GAN 目标相当的结果。
4.4 结论
该文研究并展示了WGAN中的权重裁剪问题,并在分辨器损失中引入了新的惩罚项。在各种框架上展示了强大的建模性能和稳定性。在大规模图像数据集和与数据集上进行了实验,验证了该方法可以激励分辨器学习更平滑的决策边界来稳定训练。
三、WGAN
在MNIST数据上训练WGAN网络,本文基于WGAN论文中的代码
以下几点改进:
- 判别器最后一层去掉sigmoid。sigmoid函数容易出现梯度消失的情况。
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
下图为下载数据集过程
以下为上周使用GAN的训练结果

以下为最后几个批次生成的图片

import argparse
import os
import numpy as np
import math
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)#方法是递归目录创建功能。如果exists_ok为False(默认值),则如果目标目录已存在,则引发OSError错误,True则不会
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=100, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.00005, help="learning rate")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),#np.prod(img_shape)连乘操作,长*宽*深度
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),#改进1、判别器最后一层去掉sigmoid。sigmoid函数容易出现梯度消失的情况。
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.RMSprop(generator.parameters(), lr=opt.lr)#改进4、不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
optimizer_D = torch.optim.RMSprop(discriminator.parameters(), lr=opt.lr)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
batches_done = 0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z).detach()#detach 的意思是,这个数据和生成它的计算图“脱钩”了,即梯度传到它那个地方就停了,不再继续往前传播
#要少计算一次 generator 的所有参数的梯度,同时,也不必刻意保存一次计算图,占用不必要的内存。
# Adversarial loss
loss_D = -torch.mean(discriminator(real_imgs)) + torch.mean(discriminator(fake_imgs))#改进2、生成器和判别器的loss不取log
loss_D.backward()
optimizer_D.step()#只更新discriminator的参数
# Clip weights of discriminator
for p in discriminator.parameters():
p.data.clamp_(-opt.clip_value, opt.clip_value)
# Train the generator every n_critic iterations
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Generate a batch of images
gen_imgs = generator(z)
# Adversarial loss
loss_G = -torch.mean(discriminator(gen_imgs))
loss_G.backward()
optimizer_G.step()#只更新 generator 的参数
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, batches_done % len(dataloader), len(dataloader), loss_D.item(), loss_G.item())
)
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
batches_done += 1
小结
本周继续学习了GAN并拓展阅读了相关文章,文章提出了WGAN,因此本文还介绍了Wassertain Distance。此外,还实现了wgan。
下周计划继续学习GAN网络,侧重于训练方法以及评估权重方面,还会学习CGAN的基础理论。
参考文献
[1] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron Courville. 2017. Improved training of wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 5769–5779.
[2] M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. arXiv preprint arXiv:1701.07875,
2017.