DataLoader与Dataset
一、人民币二分类

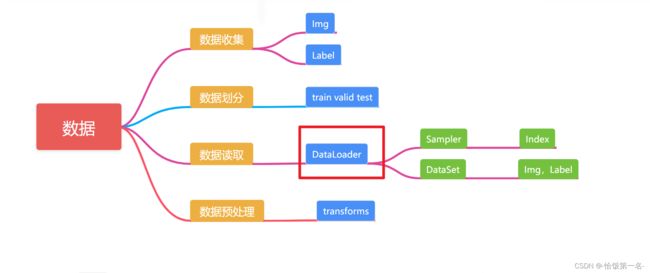
二、DataLoader 与 Dataset
DataLoader
torch.utils.data.DataLoader
功能:构建可迭代的数据装载器
(只标注了较为重要的)
• dataset: Dataset类,决定数据从哪读取及如何读取
• batchsize : 批大小
• num_works: 是否多进程读取数据
• shuffle: 每个epoch是否乱序
• drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None
)
- Epoch: 所有训练样本都已输入到模型中,称为一个Epoch
- Iteration:一批样本输入到模型中,称之为一个Iteration
- Batchsize:批大小,决定一个Epoch有多少个Iteration
样本总数:80, Batchsize:8
1 Epoch = 10 Iteration
样本总数:87, Batchsize:8
1 Epoch = 10 Iteration ? drop_last = True
1 Epoch = 11 Iteration ? drop_last = False
根据给定的样本总数和批大小,可以计算出一个Epoch中的Iteration数量。
- 样本总数为80,批大小为8:
- 一个Epoch中的Iteration数量 = 样本总数 / 批大小 = 80 / 8 = 10
- 样本总数为87,批大小为8,且设置
drop_last = True:- 一个Epoch中的Iteration数量 = 样本总数 // 批大小 = 87 // 8 = 10
- 样本总数为87,批大小为8,且设置
drop_last = False:- 一个Epoch中的Iteration数量 = (样本总数 + 批大小 - 1) // 批大小 = (87 + 8 - 1) // 8 = 11
在第3种情况下,由于样本总数无法被批大小整除,因此在最后一个Epoch中会有一个额外的Iteration来处理剩余的样本。
Dataset
torch.utils.data.Dataset
功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__()
getitem :接收一个索引,返回一个样本
class Dataset(object):
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
上述代码定义了一个名为Dataset的类,该类是一个抽象基类。它包含了两个特殊方法:
__getitem__(self, index)方法:这是一个抽象方法,需要在子类中实现。它用于根据给定的索引index返回对应的数据样本。在这里,抛出了NotImplementedError异常,表示子类必须覆盖这个方法来提供具体的实现。__add__(self, other)方法:这是一个特殊方法,用于实现对象的加法操作。在这里,它返回一个ConcatDataset对象,该对象将当前的self和另一个other数据集合并在一起。__add__方法的返回值是一个ConcatDataset对象,表示将当前数据集和另一个数据集进行连接。ConcatDataset是PyTorch中的一个类,用于将多个数据集连接在一起,以便在训练过程中一起使用。
四、模型训练
# -*- coding: utf-8 -*-
"""
# @file name : train_lenet.py
# @author : siuserjy
# @date : 2024-01-03 20:50:38
# @brief : 人民币分类模型训练
"""
import os
# 获取当前文件的目录路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
# 导入必要的库和模块
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
# 定义lenet.py和common_tools.py文件的路径并检查文件是否存在
path_lenet = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "model", "lenet.py"))
path_tools = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "tools", "common_tools.py"))
assert os.path.exists(path_lenet), "{}不存在,请将lenet.py文件放到 {}".format(path_lenet, os.path.dirname(path_lenet))
assert os.path.exists(path_tools), "{}不存在,请将common_tools.py文件放到 {}".format(path_tools, os.path.dirname(path_tools))
# 将自定义模块所在的目录添加到Python路径中
import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__) + os.path.sep + ".." + os.path.sep + "..")
sys.path.append(hello_pytorch_DIR)
# 从自定义模块导入所需内容
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed
# 设置随机种子
set_seed()
# 定义人民币数据集的标签
rmb_label = {"1": 0, "100": 1}
# 设置训练参数
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
# 设置数据集路径
split_dir = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "data", "rmb_split"))
if not os.path.exists(split_dir):
raise Exception(r"数据 {} 不存在, 回到lesson-06\1_split_dataset.py生成数据".format(split_dir))
# 设置训练集和验证集路径
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
# 设置图像的均值和标准差
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
# 设置训练集的数据预处理
train_transform = transforms.Compose([
transforms.Resize((32, 32)), # 将图像大小调整为32x32
transforms.RandomCrop(32, padding=4), # 随机裁剪32x32大小的图像
transforms.ToTensor(), # 将图像转换为Tensor格式
transforms.Normalize(norm_mean, norm_std), # 标准化图像
])
# 设置验证集的数据预处理
valid_transform = transforms.Compose([
transforms.Resize((32, 32)), # 将图像大小调整为32x32
transforms.ToTensor(), # 将图像转换为Tensor格式
transforms.Normalize(norm_mean, norm_std), # 标准化图像
])
# 构建训练集和验证集的数据集实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建训练集和验证集的DataLoader
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
# 构建LeNet模型实例
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
# 设置损失函数
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
# 设置优化器
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
# 设置学习率下降策略
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# ============================ step 5/5 训练 ============================
train_curve = list() # 记录训练集的loss值
valid_curve = list() # 记录验证集的loss值
for epoch in range(MAX_EPOCH): # 迭代训练多个epoch
loss_mean = 0. # 记录每个epoch的平均loss值
correct = 0. # 记录分类正确的样本数量
total = 0. # 记录总样本数量
net.train() # 将模型设置为训练模式
for i, data in enumerate(train_loader): # 遍历训练集数据
# forward
inputs, labels = data # 获取输入数据和标签
outputs = net(inputs) # 将输入数据输入模型,得到输出结果
# backward
optimizer.zero_grad() # 将模型参数的梯度置零
loss = criterion(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度
# update weights
optimizer.step() # 更新模型参数
# 统计分类情况
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
total += labels.size(0) # 累计总样本数量
correct += (predicted == labels).squeeze().sum().numpy() # 累计分类正确的样本数量
# 打印训练信息
loss_mean += loss.item() # 累计每个batch的loss值
train_curve.append(loss.item()) # 将每个batch的loss值记录下来
if (i+1) % log_interval == 0: # 每隔一定的batch数打印一次训练信息
loss_mean = loss_mean / log_interval # 计算平均loss值
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0. # 重置loss_mean
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0: # 每隔一定的epoch数进行一次验证
correct_val = 0. # 记录验证集分类正确的样本数量
total_val = 0. # 记录验证集总样本数量
loss_val = 0. # 记录验证集的loss值
net.eval() # 将模型设置为评估模式
with torch.no_grad(): # 不计算梯度
for j, data in enumerate(valid_loader): # 遍历验证集数据
inputs, labels = data # 获取输入数据和标签
outputs = net(inputs) # 将输入数据输入模型,得到输出结果
loss = criterion(outputs, labels) # 计算损失值
_, predicted = torch.max(outputs.data, 1) # 获取预测结果
total_val += labels.size(0) # 累计验证集总样本数量
correct_val += (predicted == labels).squeeze().sum().numpy() # 累计验证集分类正确的样本数量
loss_val += loss.item() # 累计验证集的loss值
loss_val_epoch = loss_val / len(valid_loader) # 计算验证集每个epoch的平均loss值
valid_curve.append(loss_val_epoch) # 将验证集每个epoch的平均loss值记录下来
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_epoch, correct_val / total_val))
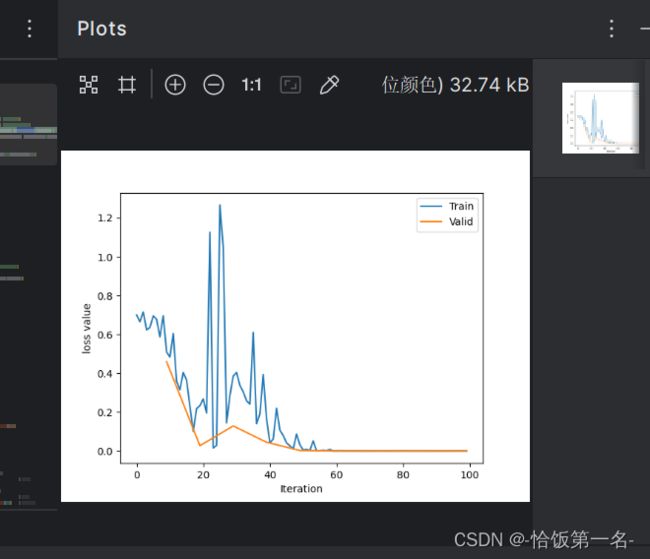
# 绘制训练曲线和验证曲线
train_x = range(len(train_curve)) # 训练曲线的x轴
train_y = train_curve # 训练曲线的y轴
train_iters = len(train_loader) # 训练集的迭代次数
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval - 1 # 验证曲线的x轴,将epoch转换为iteration
valid_y = valid_curve # 验证曲线的y轴
plt.plot(train_x, train_y, label='Train') # 绘制训练曲线
plt.plot(valid_x, valid_y, label='Valid') # 绘制验证曲线
plt.legend(loc='upper right') # 设置图例位置
plt.ylabel('loss value') # 设置y轴标签
plt.xlabel('Iteration') # 设置x轴标签
plt.show() # 显示图像
# ============================ inference ============================
# 设置基本路径
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
# 创建测试数据集
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
# 创建验证数据加载器
valid_loader = DataLoader(dataset=test_data, batch_size=1)
# 遍历验证数据集
for i, data in enumerate(valid_loader):
# 前向传播
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
# 判断预测结果是1元还是100元
rmb = 1 if predicted.numpy()[0] == 0 else 100
# 打印模型获得的金额
print("模型获得{}元".format(rmb))