ptorch使用——(四)DataLoader与Dataset
一、基础知识
1、数据装载(可迭代):
1)外层设计:torch.utils.data.DataLoader
DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,collate_fn=None,pin_memory=False,drop_last=False,timeout=0,worker_init_fn=None,multiprocessing_context=None)
dataset: Dataset类,决定数据从哪读取及如何读取
batchsize : 批大小
num_works: 是否多进程读取数据
shuffle: 每个epoch是否乱序设计:
drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
2)内层设计:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写
class Dataset(object):
def __getitem__(self, index): #接收一个索引,返回一个样本,这个要自己写
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])3)数据加载思路:

4)数据加载流程:
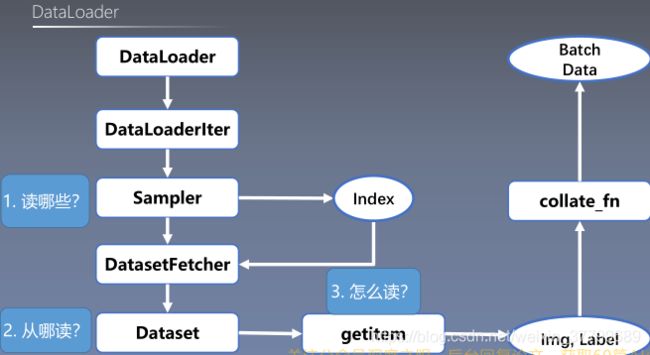
二、重点讲解
1、变量
Epoch: 所有训练样本都已输入到模型中,称为一个Epoch
Iteration:一批样本输入到模型中,称之为一个Iteration
Batchsize:批大小,决定一个Epoch有多少个Iteration
2、 数据构建过程
第一步:编辑索引
def get_img_info(data_dir): #通过遍历形式编辑图像索引
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info第二步:数据读取
def __getitem__(self, index): #在处理图像的同时编辑图像
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label3、代码参数补充
1)drop_last:假设样本数87、batchsize=8。则当drop_last=ture,有10个epoch;当drop_last=Flase,有11个epoch。
2)数据获取主干函数
def __init__(self, data_dir, transform=None): #其他功能见上面几个代码块
"""
Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform