MySql5.7使用存储过程 批量插入数据(1条SQL语句)
Mysql5.7 使用存储过程 分段生成 亿级 测试数据_lizhou828的博客-CSDN博客s1、建表DROP TABLE IF EXISTS `t_big_table`;CREATE TABLE `t_big_table` ( `id` bigint(20) NOT NULL, `code` varchar(255) DEFAULT NULL, `username` varchar(255) DEFAULT NULL, `password` varcha...https://blog.csdn.net/lizhou828/article/details/103841040上次写完 Mysql5.7 使用存储过程 分段生成 亿级 测试数据 后,发现生成数据太慢,于是搞了个批量生成数据的存储过程:
存储过程名称:batch_gen_data
存储过程入参:IN `table_index` integer,IN `min_num` integer,IN `max_num` integer
CREATE DEFINER=`root`@`localhost` PROCEDURE `batch_gen_data`(IN `table_index` integer,IN `min_num` integer,IN `max_num` integer)
BEGIN
## 定义变量
## 参考文档 MySQL 存储过程执行动态拼接SQL :https://blog.csdn.net/after95/article/details/99699611
## 参考文档 MySQL 允许SQL最大长度(默认4M) https://blog.csdn.net/s3088529551/article/details/120531194
DECLARE min_index DECIMAL (10) DEFAULT min_num ;
DECLARE max_index DECIMAL (10) DEFAULT max_num ;
DECLARE current_index DECIMAL (10) DEFAULT min_index ;
DECLARE v_table_column TEXT DEFAULT 'INSERT INTO t_big_table_';
## 存储过程外面定义的参数table_index 无法进行充分的使用,最好赋值给在存储过程内部定义的局部变量num,然后使用num变量
DECLARE table_num DECIMAL (10) DEFAULT table_index ;
## @表示全局变量
## 拼接赋值 必须要用全局变量不然语句会报错
# 存储sql内容的变量必须是全局变量,使用 @ 符修饰
SET @sql = v_table_column;
SET @sql = CONCAT(@sql,table_num);
SET @sql = CONCAT(@sql, " (id,code,username,password,create_time,year,month,date) VALUES ");
dd:LOOP
## 循环里面动态拼接SQL
SET @sql = CONCAT(@sql, REPLACE(" (current_index,UUID(),concat('user-',current_index),password(current_index),NOW(),date_format(NOW(), '%Y' ),date_format(NOW(), '%m' ),date_format(NOW(), '%d' ))","current_index" , current_index ));
IF current_index = max_num THEN
SET @sql = CONCAT(@sql, ';');
ELSE
SET @sql = CONCAT(@sql, ',');
END IF;
SET current_index = current_index+1 ;
IF current_index > max_num THEN LEAVE dd;
END IF;
END LOOP dd ;
## 执行sql
PREPARE stmt FROM @sql;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END新建表: t_big_table_0 、t_big_table_1、t_big_table_2、........
建表语句如下:
CREATE TABLE `t_big_table_0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户id(雪花算法)',
`code` varchar(255) DEFAULT NULL,
`username` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`year` int(4) DEFAULT NULL,
`month` int(2) DEFAULT NULL,
`date` int(2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='大数据表(用于测试sql查询语句调优)';调用方式: call batch_gen_data(0,1,10000);
表示 在t_big_table_0 表中 批量生成数据,id 从1 到10000;
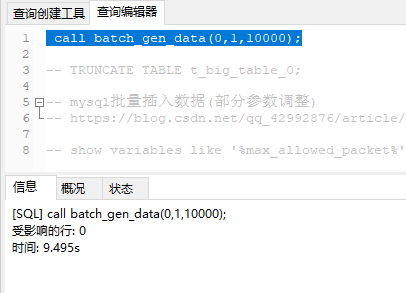
发现: call batch_gen_data(0,1,10000); 调用后,耗时9.495秒,
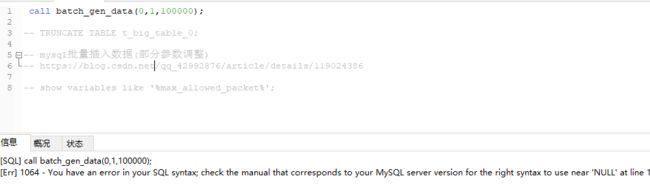
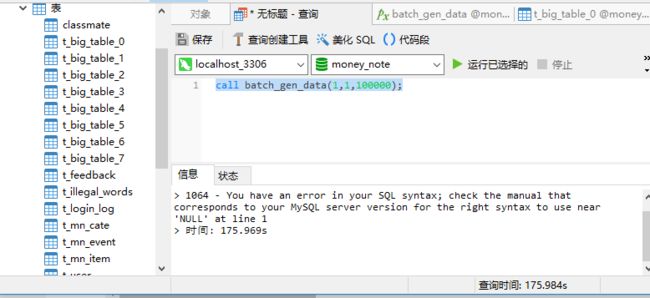
但想一次性插入10万条数据 ,调用 call batch_gen_data(0,1,100000); 后,居然报SQL语法错误? 不可理解.....
于是想调试一下,把生成的SQL 展示出来,先暂时不执行SQL,看下SQL是否有语法错误(仅在 调试阶段,否则会极大的影响性能)
SELECT @sql;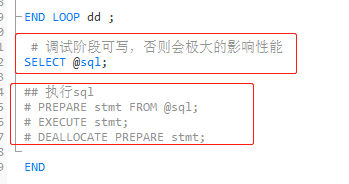
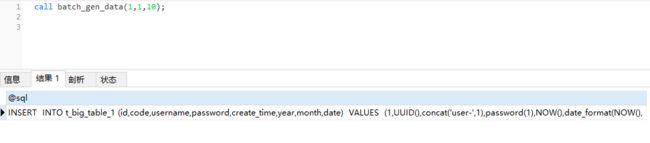

于是把这个批量插入10的SQL 语句,copy到1000行时,也就是数据量为1万时,文件打下只有1.29M。
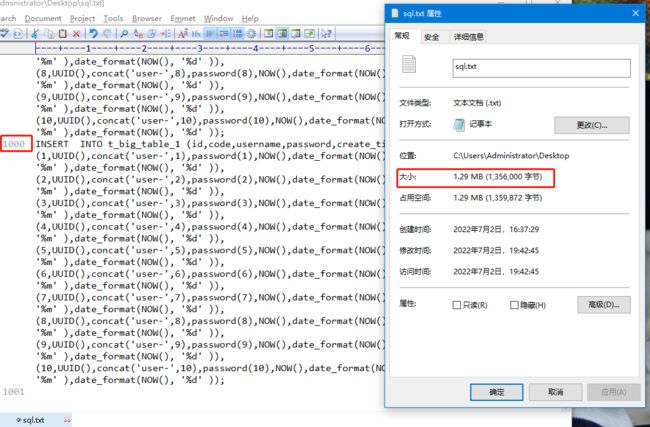
copy到10000行时,即数据量为10万,居然超过10M了,这也就超过了MySQL允许SQL最大长度(默认4M),难怪执行SQL报错。。。

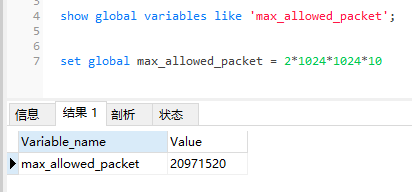
MySQL 5.7 最大接收默认值为 4M=4194304=4*1024*1024,由系统变量max_allowed_packet 控制。
show global variables like 'max_allowed_packet'; 
然后修改为20M:
set global max_allowed_packet = 2*1024*1024*10
show global variables like 'max_allowed_packet';
执行存储过程,发现生成sql就花了2351秒。。。。
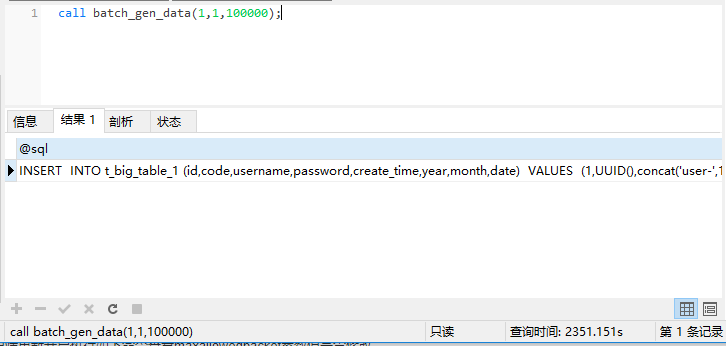
然后SQL的解析等花费448秒,执行SQL用了1.9秒
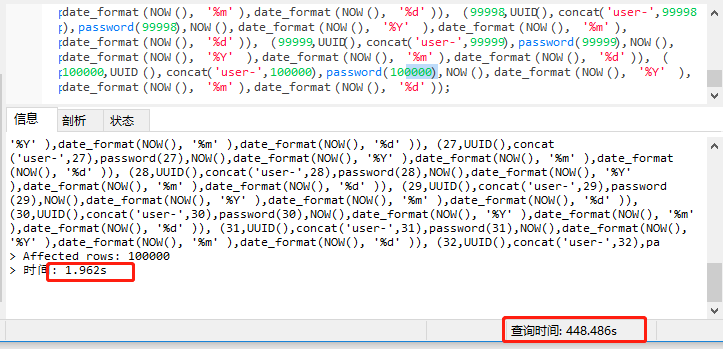
在上一边博客中,每次生成100万条数据(单条SQL语句插入),也不过2800秒(低配电脑),参考博客:
Mysql5.7 使用存储过程生成千万级数据(单条插入语)
而这次高配的电脑上,生成10万条数据(一条批量SQL插入),差不多也是2800秒。
因此 一次性插入数据在1万以上后,批量SQL不再有优势,建议使用存储过程逐次插入。
参考文档:
Mysql5.7 使用存储过程生成千万级数据(单条插入语)
mysql批量插入数据_抱猫人的博客-CSDN博客_mysql批量insert数据
MySQL 存储过程执行动态拼接SQL :https://blog.csdn.net/after95/article/details/99699611
MySQL 允许SQL最大长度(默认4M) https://blog.csdn.net/s3088529551/article/details/120531194