RPC通信原理解析
一、什么是RPC框架?
RPC,全称为Remote Procedure Call,即远程过程调用,是一种计算机通信协议。
比如现在有两台机器:A机器和B机器,并且分别部署了应用A和应用B。假设此时位于A机器上的A应用想要调用位于B机器上的B应用提供的函数或是方法,由于A应用和B应用不在一个内存空间里面,所以不能直接调用,此时就需要通过网络来表达调用的方式和传输调用的数据。也即所谓的远程调用。
二、RPC框架的实现原理?
主要有以下几个步骤:
1、建立通信
首先要解决通讯的问题:即A机器想要调用B机器,首先得建立起通信连接。主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有相关的数据都在这个连接里面进行传输交换。
通常这个连接可以是按需连接(需要调用的时候就先建立连接,调用结束后就立马断掉),也可以是长连接(客户端和服务器建立起连接之后保持长期持有,不管此时有无数据包的发送,可以配合心跳检测机制定期检测建立的连接是否存活有效),多个远程过程调用共享同一个连接。
2、服务寻址
解决寻址的问题:即A机器上的应用A要调用B机器上的应用B,那么此时对于A来说如何告知底层的RPC框架所要调用的服务具体在哪里呢?
通常情况下我们需要提供B机器(主机名或IP地址)以及特定的端口,然后指定调用的方法或者函数的名称以及入参出参等信息,这样才能完成服务的一个调用。比如基于Web服务协议栈的RPC,就需要提供一个endpoint URI,或者是从UDDI服务上进行查找。如果是RMI调用的话,还需要一个RMI Registry来注册服务的地址。
3、网络传输
3.1、序列化
当A机器上的应用发起一个RPC调用时,调用方法和其入参等信息需要通过底层的网络协议如TCP传输到B机器,由于网络协议是基于二进制的,所有我们传输的参数数据都需要先进行序列化(Serialize)或者编组(marshal)成二进制的形式才能在网络中进行传输。然后通过寻址操作和网络传输将序列化或者编组之后的二进制数据发送给B机器。
3.2、反序列化
当B机器接收到A机器的应用发来的请求之后,又需要对接收到的参数等信息进行反序列化操作(序列化的逆操作),即将二进制信息恢复为内存中的表达方式,然后再找到对应的方法(寻址的一部分)进行本地调用(一般是通过生成代理Proxy去调用, 通常会有JDK动态代理、CGLIB动态代理、Javassist生成字节码技术等),之后得到调用的返回值。
4、服务调用
B机器进行本地调用(通过代理Proxy)之后得到了返回值,此时还需要再把返回值发送回A机器,同样也需要经过序列化操作,然后再经过网络传输将二进制数据发送回A机器,而当A机器接收到这些返回值之后,则再次进行反序列化操作,恢复为内存中的表达方式,最后再交给A机器上的应用进行相关处理(一般是业务逻辑处理操作)。
通常,经过以上四个步骤之后,一次完整的RPC调用算是完成了,另外可能因为网络抖动等原因需要重试等。
三、为什么需要RPC?
主要就是因为在几个进程内(应用分布在不同的机器上),无法共用内存空间,或者在一台机器内通过本地调用无法完成相关的需求,比如不同的系统之间的通讯,甚至不同组织之间的通讯。此外由于机器的横向扩展,需要在多台机器组成的集群上部署应用等等。
四、RPC支持哪些协议?
最早的CORBA、Java RMI, WebService方式的RPC风格, Hessian, Thrift甚至Rest API。
五、RPC的实现基础?
1、需要有非常高效的网络通信,比如一般选择Netty作为网络通信框架
2、需要有比较高效的序列化框架,比如谷歌的Protobuf序列化框架
3、可靠的寻址方式(主要是提供服务的发现),比如可以使用Zookeeper来注册服务等等
4、如果是带会话(状态)的RPC调用,还需要有会话和状态保持的功能
六、RPC调用过程?
6.1 一个基本的RPC架构里面应该至少包含以下4个组件:
1、客户端(Client):服务调用方(服务消费者)
2、客户端存根(Client Stub):存放服务端地址信息,将客户端的请求参数数据信息打包成网络消息,再通过网络传输发送给服务端
3、服务端存根(Server Stub):接收客户端发送过来的请求消息并进行解包,然后再调用本地服务进行处理
4、服务端(Server):服务的真正提供者
6.2 具体的调用过程如下:
1、服务消费者(client客户端)通过本地调用的方式调用服务
2、客户端存根(client stub)接收到调用请求后负责将方法、入参等信息序列化(组装)成能够进行网络传输的消息体
3、客户端存根(client stub)找到远程的服务地址,并且将消息通过网络发送给服务端
4、服务端存根(server stub)收到消息后进行解码(反序列化操作)
5、服务端存根(server stub)根据解码结果调用本地的服务进行相关处理
6、本地服务执行具体业务逻辑并将处理结果返回给服务端存根(server stub)
7、服务端存根(server stub)将返回结果重新打包成消息(序列化)并通过网络发送至消费方
8、客户端存根(client stub)接收到消息,并进行解码(反序列化)
9、服务消费方得到最终结果

而RPC框架的实现目标则是将上面的第2-10步完好地封装起来,也就是把调用、编码/解码的过程给封装起来,让用户感觉上像调用本地服务一样的调用远程服务。
七、RPC框架需要解决的问题?
1、如何确定客户端和服务端之间的通信协议?
2、如何更高效地进行网络通信?
3、服务端提供的服务如何暴露给客户端?
4、客户端如何发现这些暴露的服务?
5、如何更高效地对请求对象和响应结果进行序列化和反序列化操作?
八、使用了哪些技术?
8.1、动态代理
生成Client Stub(客户端存根)和Server Stub(服务端存根)的时候需要用到java动态代理技术,可以使用jdk提供的原生的动态代理机制,也可以使用开源的:Cglib代理,Javassist字节码生成技术。
8.2、序列化
在网络中,所有的数据都将会被转化为字节进行传送,所以为了能够使参数对象在网络中进行传输,需要对这些参数进行序列化和反序列化操作。
序列化:把对象转换为字节序列的过程称为对象的序列化,也就是编码的过程。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程。
目前比较高效的开源序列化框架:如Kryo、fastjson和Protobuf等。
8.3、NIO通信
出于并发性能的考虑,传统的阻塞式 IO 显然不太合适,因此我们需要异步的 IO,即 NIO。
Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的 NIO.2 支持。可以选择Netty或者mina来解决NIO数据传输的问题。
8.4、服务注册中心
可选:Redis、Zookeeper、Consul 、Etcd。
一般使用ZooKeeper提供服务注册与发现功能,解决单点故障以及分布式部署的问题(注册中心)。
九. 模拟RPC的客户端、服务端、通信协议三者如何工作的
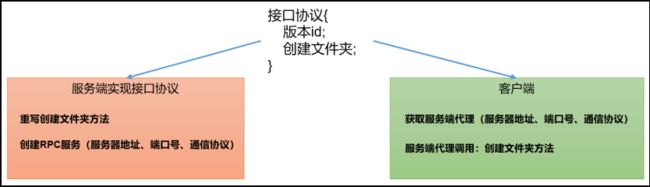
9.1 代码编写:
(1)在HDFSClient项目基础上创建包名com.hadoop.rpc
(2)创建RPC协议
package com.hadoop.rpc;
public interface RPCProtocol {
long versionID = 666;
void mkdirs(String Path);
void delete(String Path);
}
(3)创建RPC服务端
package com.hadoop.rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.Server;
import java.io.IOException;
import java.io.*;
public class NNServer implements RPCProtocol{
@Override
public void mkdirs(String Path){
//System.out.println("服务端,创建路径" + Path);
File f = new File(Path);
final boolean mkdirs = f.mkdirs();
if (mkdirs)
{
System.out.println("服务端,创建路径" + Path);
}
}
public void delete(String Path){
//System.out.println("服务端,创建路径" + Path);
File f = new File(Path);
final boolean delete = f.delete();
if (delete)
{
System.out.println("服务端,删除" + Path);
}
}
public static void main(String[] args) throws IOException {
Server server = new RPC.Builder(new Configuration())
.setBindAddress("localhost")
.setPort(8888)
.setProtocol(RPCProtocol.class)
.setInstance(new NNServer())
.build();
System.out.println("服务器开始工作");
server.start();
}
}
(4)创建RPC客户端
package com.hadoop.rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
public class HDFSClient {
public static void main(String[] args) throws IOException {
RPCProtocol client = RPC.getProxy(
RPCProtocol.class,
RPCProtocol.versionID,
new InetSocketAddress("localhost",8888),
new Configuration());
System.out.println("我是客户端");
System.out.println("开始创建文件夹");
client.mkdirs("./input");
int j = 0;
while (j < 10){
j++;
client.mkdirs("./hadoop/hadoop100/hadoop"+j);
}
System.out.println("开始删除前五个文件夹");
int i = 0;
while (i < 5){
i++;
client.delete("./hadoop/hadoop100/hadoop"+i);
}
}
}
pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoopartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<hadoop.version>2.7.5hadoop.version>
<hive.version>1.1.0hive.version>
<hbase.version>1.2.0hbase.version>
<scala.version>2.11.8scala.version>
<spark.version>2.4.4spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-graphx_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.11version>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.11.0.2version>
dependency>
dependencies>
project>
3)测试
(1)启动服务端
观察控制台打印:服务器开始工作
在控制台Terminal窗口输入,jps,查看到NNServer服务
(2)启动客户端
观察客户端控制台打印:我是客户端
观察服务端控制台打印:服务端,创建路径/input
4)总结
RPC的客户端调用通信协议方法,方法的执行在服务端;
通信协议就是接口规范。
参考https://my.oschina.net/huangyong/blog/361751实现了RPC框架
github代码:https://github.com/hu1991die/netty-rpc
原文参考:
1、https://www.zhihu.com/question/25536695
2、http://www.importnew.com/22003.html
3、http://blog.jobbole.com/92290/
4、https://mp.weixin.qq.com/s?__biz=MzAxMjY5NDU2Ng==&mid=2651856984&idx=1&sn=3896636d2d2907b5b7157bec14c58088&chksm=80496511b73eec072a10c2465e229683789432b31232016ce064036988d8a75a1d0de5dccc48&scene=27