【数据结构】手撕排序(排序的概念及意义、直接插入和希尔排序的实现及分析)
目录
一、排序的概念及其运用
1.1排序的概念
1.2排序运用
1.3 常见的排序算法
二、插入排序
2.1基本思想:
2.2直接插入排序:
2.3步骤:
2.4直接插入排序的实现
三、希尔排序( 缩小增量排序 )
3.1希尔排序的发展历史
3.2 希尔排序的思路
编辑
gap = 3的思路讲解
3.3 如何选择希尔增量
四、希尔排序的代码实现
一、排序的概念及其运用
1.1排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起
来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记
录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍
在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据
的排序。
1.2排序运用
1.3 常见的排序算法

// 排序实现的接口
// 插入排序
void InsertSort(int* a, int n);
// 希尔排序
void ShellSort(int* a, int n);
// 选择排序
void SelectSort(int* a, int n);
// 堆排序
void AdjustDwon(int* a, int n, int root);
void HeapSort(int* a, int n);
// 冒泡排序
void BubbleSort(int* a, int n)
// 快速排序
void QuickSort(int* a, int left, int right);
// 归并排序
void MergeSort(int* a, int n)
二、插入排序
2.1基本思想:
直接插入排序是一种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐
个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
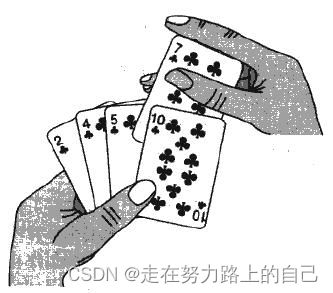
实际中我们玩扑克牌时,就用了插入排序的思想 。
2.2直接插入排序:
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排
序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置
上的元素顺序后移 直接插入排序的特性总结:
1. 元素集合越接近有序,直接插入排序算法的时间效率越高
2. 时间复杂度是多少?O(N^2)
什么情况下最坏?逆序 1+2+3+...+n-1
什么情况下最好?顺序有序 O(N)
3. 空间复杂度:O(1),它是一种稳定的排序算法
4. 稳定性:稳定

2.3步骤:
- 确定已排序和未排序部分:
初始时,认为数组的第一个元素(索引为0)是已排序部分,其余元素是未排序部分。
从数组的第二个元素开始(索引为1),逐步将未排序部分的元素插入到已排序部分。 - 选择待插入元素:
从未排序部分中选择第一个元素作为待插入元素(开始时是第二个元素)。
在后续的迭代中,逐步选择未排序部分的下一个元素。 - 查找插入位置:
从已排序部分的最后一个元素开始,逐个与待插入元素比较。
如果已排序部分的当前元素大于待插入元素,则将当前元素后移一位,为待插入元素腾出空间。
如果已排序部分的当前元素小于或等于待插入元素,或者已到达已排序部分的开头(即索引为0),则停止比较。 - 插入元素:
将待插入元素插入到已排序部分中找到的正确位置。
插入位置是通过前面步骤中元素的后移操作确定的。 - 重复过程:
重复步骤2到步骤4,直到未排序部分没有元素为止。
每次迭代后,已排序部分会增加一个元素,而未排序部分会减少一个元素。
2.4直接插入排序的实现
void InsertSort(int* a, int n)
{
// [0, end] 有序 把end + 1位置的值插入[0,end],让[0, end+1]有序
for (int i = 0; i < n - 1; ++i)
//控制前n个数字有序
{
int end = i;//从第i+1个数开始排序
//每一次排序要经i次循环比较
int tmp = a[end + 1];
//tmp保存要排序的下一个数据(end 后一个值)
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];// 将该元素向后移动一位
--end;// 继续向前查找插入位置
}
else {
break;
}
}
a[end + 1] = tmp;
//保留的数比end都小,把保留的数放到end前面
//保留的数比所有数小,end = -1,把保留的数放到所有数前面
//这两种情况的操作一样,所以可以写在最外面
}
}三、希尔排序( 缩小增量排序 )
3.1希尔排序的发展历史
希尔排序,也被称为“缩小增量排序”或“Shell's Sort”,是插入排序的一种更高效的改进版本。该算法由D·L·Shell于1959年提出,并以他的名字命名。希尔排序是非稳定排序算法。
希尔排序的思想是将待排序的数组看作是一个矩阵,然后按一定的增量(步长)分组进行排序。通常,这个增量序列会从一个大的数值开始,然后逐渐减小到1。在增量逐渐减少的过程中,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。在这个过程中,算法会对每一组使用直接插入排序算法进行排序。
希尔排序的诞生打破了人们普遍认为排序算法的时间复杂度无法突破O(N^2)的观念。尽管希尔排序在最坏的情况下时间复杂度仍然为O(N^2),但是在实际情况中,它的性能通常要好于这个时间复杂度。这使得希尔排序成为第一个突破平方量级瓶颈的排序算法。
希尔排序的提出在计算机科学领域引起了广泛的关注和研究。许多研究者开始寻找各种优秀的增量序列以证明这个算法的优越性。然而,直到现在,关于希尔排序的复杂度证明仍然是一个难题。目前被大部分认可的Hibbard增量在最糟糕的情况下可以把复杂度稳定在O(N^(3/2))左右,而猜想的平均复杂度大概在O(N^(5/4))。尽管这些猜想的平均复杂度都未被确切证明,但是值得肯定的是,希尔排序在实际应用中的性能通常要好于直接插入排序。
3.2 希尔排序的思路
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有
记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重
复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。
希尔排序原理是每一对分组进行排序后,整个数据就会更接近有序,当增量缩小为1时,就是插入排序,但是现在的数组非常接近有序,移动的数据很少,所以效率非常高,所以希尔排序又叫缩小增量排序。
每次排序让数组接近有序的过程叫做预排序,最后一次插入是直接插入排序。

gap = 3的思路讲解
1、以3作为增量(gap)对数组进行分组,以下数组被分成3组,每组之间都是以3的等差数列

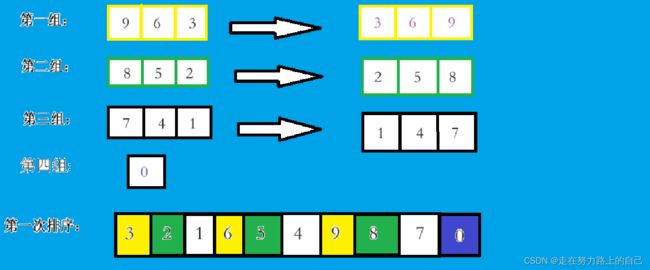
2、(gap = 2)此时gap缩小,以2为增量对数组进行分组,数组被分成2份,每组之间都是2的等差数列

3、对每一组进行插入排序,得到如下数组
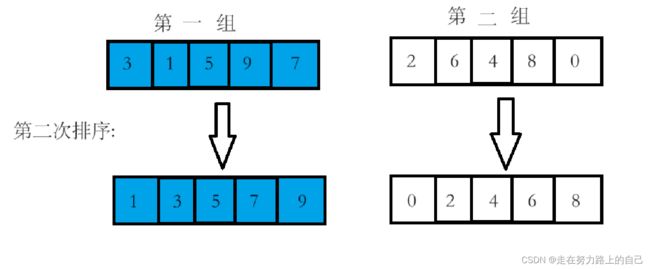
4、对每一组进行插入排序,得到如下数组

3.3 如何选择希尔增量
希尔排序的分析是一个复杂的问题,它的时间是一个关于增量序列的函数,这涉及到一些数学上未能攻克的难题,所以目前为止对于希尔增量到底怎么取也没有一个最优的值,但是经过大量研究已经有一些局部的结论,在这里并不展开叙述。
最初希尔提出的增量是 gap = n / 2,每一次排序完让增量减少一半gap = gap / 2,直到gap = 1时排序变成了直接插入排序。后面也有人提出的gap = [gap / 3] + 1,每次排序让增量成为原来的三分之一,加一是防止gap <= 3时gap = gap / 3 = 0的发生,导致希尔增量最后不为1。这二者思路都可以。
四、希尔排序的代码实现
直接插入排序的基础上的优化
1、先进行预排序,让数组接近有序
2、直接插入排序
时间复杂度:O(N*![]() ) 或者 O(N*
) 或者 O(N*![]() )
)
平均的时间复杂度是O(N^1.3)
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
//gap = gap / 2; // logN
gap = gap / 3 + 1; // log3 N 以3为底数的对数
// gap > 1时都是预排序 接近有序
// gap == 1时就是直接插入排序 有序
// gap很大时,下面预排序时间复杂度O(N)
// gap很小时,数组已经很接近有序了,这时差不多也是(N)
// 把间隔为gap的多组数据同时排
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}祝大家新年快乐!!!
看到这里了还不给博主扣个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
你们的点赞就是博主更新最大的动力!
有问题可以评论或者私信呢秒回哦。