LeetCode207之课程表(相关话题:图的遍历,拓扑排序)
目录
LeetCode207之课程表
方法一
解题思路
代码实现
方法二
解题思路
代码实现
题目拓展
图相关问题
代码实现
时间复杂度
空间复杂度
参考文章
LeetCode207之课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:numCourses = 2, prerequisites = [[1,0]]
输出:true
解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
示例 2:
输入:numCourses = 2, prerequisites = [[1,0],[0,1]]
输出:false
解释:总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0 ;并且学习课程 0 之前,你还应先完成课程 1 。这是不可能的。
提示:
1 <= numCourses <= 105
0 <= prerequisites.length <= 5000
prerequisites[i].length == 2
0 <= ai, bi < numCourses
prerequisites[i] 中的所有课程对 互不相同
方法一
解题思路
邻接表构建图
List[] buildGraph(int numCourses, int[][] prerequisites) {
// 图中共有 numCourses 个节点
List[] graph = new LinkedList[numCourses];
for (int i = 0; i < numCourses; i++) {
graph[i] = new LinkedList<>();
}
for (int[] edge : prerequisites) {
int from = edge[1];
int to = edge[0];
// 修完课程 from 才能修课程 to
// 在图中添加一条从 from 指向 to 的有向边
graph[from].add(to);
}
return graph;
} 定义三个变量
// 深度遍历经过的节点,用于在DFS过程中检测环
boolean[] onPath;
// 记录遍历过的节点,防止走回头路提高效率
boolean[] visited;
// 记录图中是否有环
boolean hasCycle = false;
利用深度遍历图中的所有节点 ,同时用onPath回溯经过的节点路径
思考:为什么visited不需要回溯?
因为 以某个节点为起点,visited[i]记录访问过的节点如果无法成环。那么以另一个节点为起点并且经过visited[i]也一定无法成环
代码实现
class Solution {
// 记录一次 dfs 递归经过的节点
boolean[] onPath;
// 记录遍历过的节点,防止走回头路
boolean[] visited;
// 记录图中是否有环
boolean hasCycle = false;
boolean canFinish(int numCourses, int[][] prerequisites) {
List[] graph = buildGraph(numCourses, prerequisites);
visited = new boolean[numCourses];
onPath = new boolean[numCourses];
for (int i = 0; i < numCourses; i++) {
// 遍历图中的所有节点
dfs(graph, i);
}
// 只要没有循环依赖可以完成所有课程
return !hasCycle;
}
List[] buildGraph(int numCourses, int[][] prerequisites) {
// 图中共有 numCourses 个节点
List[] graph = new LinkedList[numCourses];
for (int i = 0; i < numCourses; i++) {
graph[i] = new LinkedList<>();
}
for (int[] edge : prerequisites) {
int from = edge[1];
int to = edge[0];
// 修完课程 from 才能修课程 to
// 在图中添加一条从 from 指向 to 的有向边
graph[from].add(to);
}
return graph;
}
void dfs(List[] graph, int s) {
if (onPath[s]) {
// 出现环
hasCycle = true;
}
if (visited[s] || hasCycle) {
// visited[s] == true 表示经过s的相关节点已经遍历无需重复校验
//可以理解为把一个可以遍历所有节点的路径分为两次traverse完成
return;
}
// 前序遍历代码位置
visited[s] = true;
onPath[s] = true;
for (int t : graph[s]) {
dfs(graph, t);
}
// 后序遍历代码位置
onPath[s] = false;
}
} 方法二
解题思路
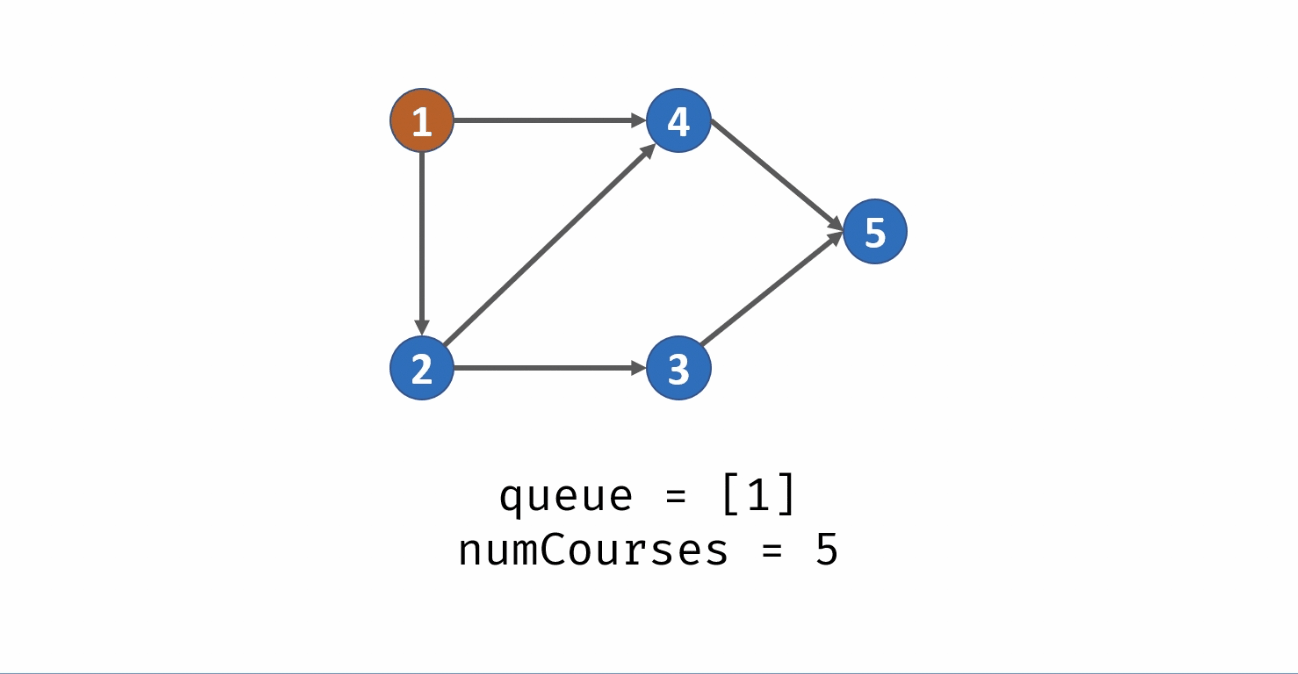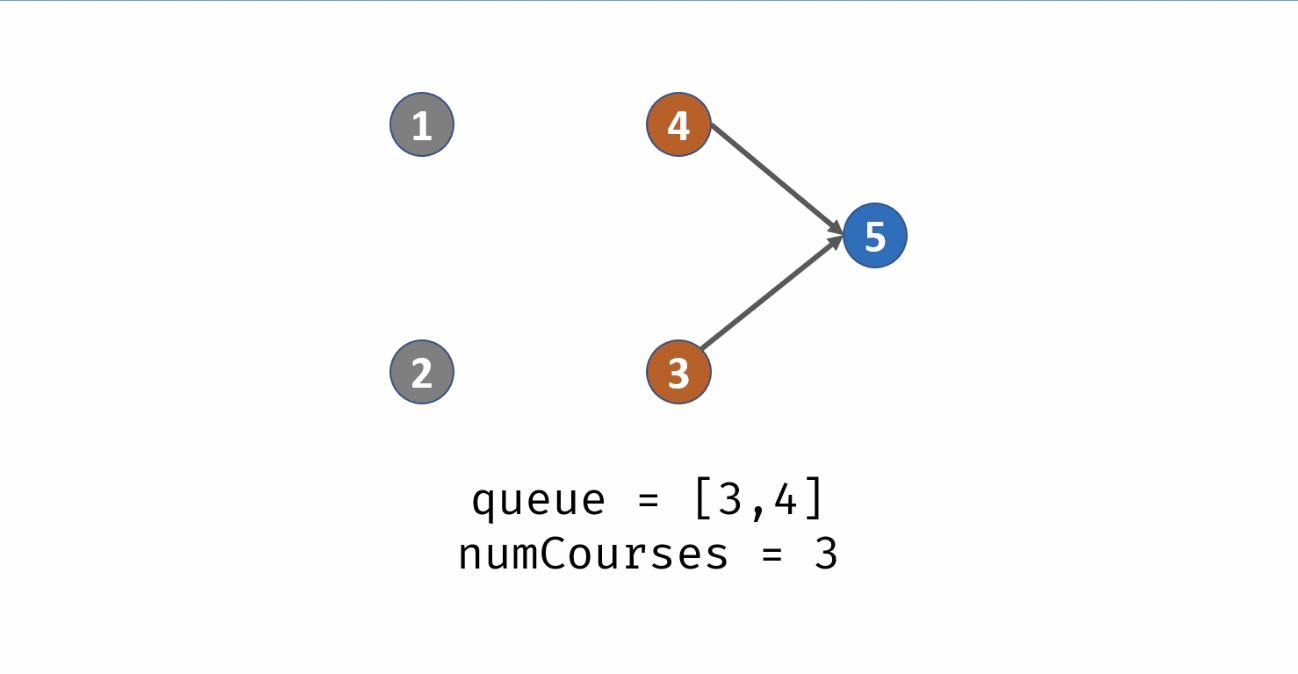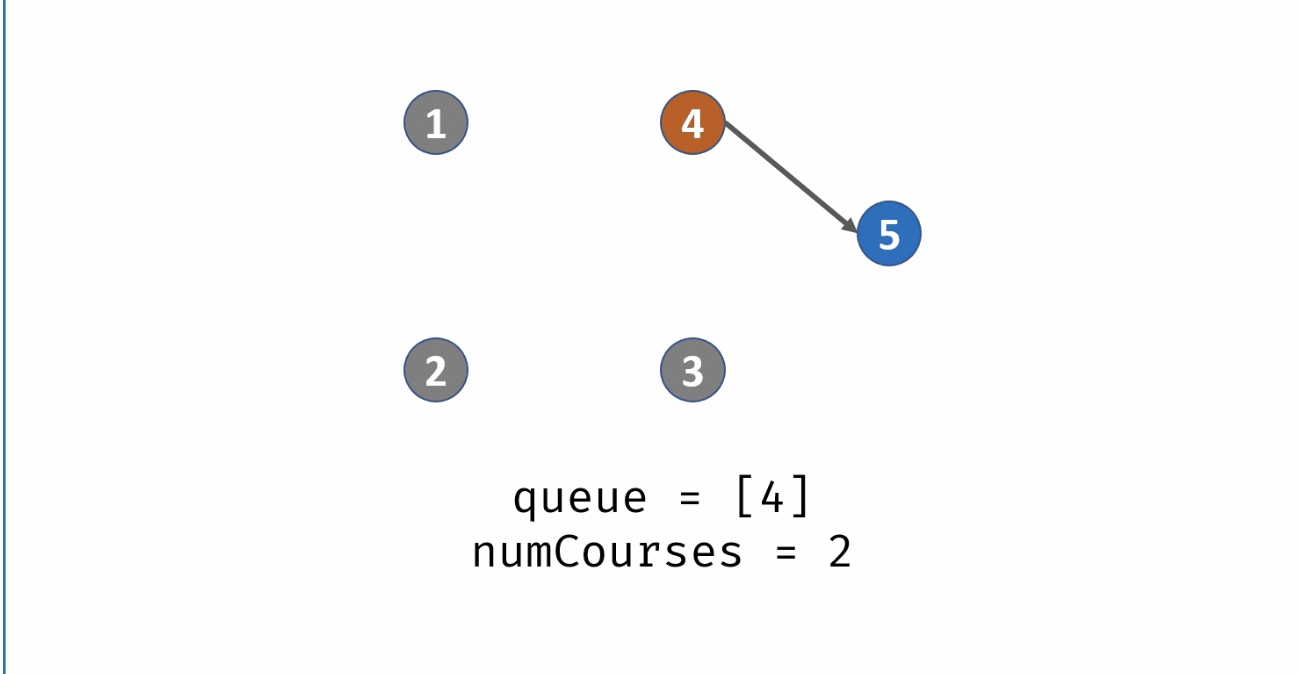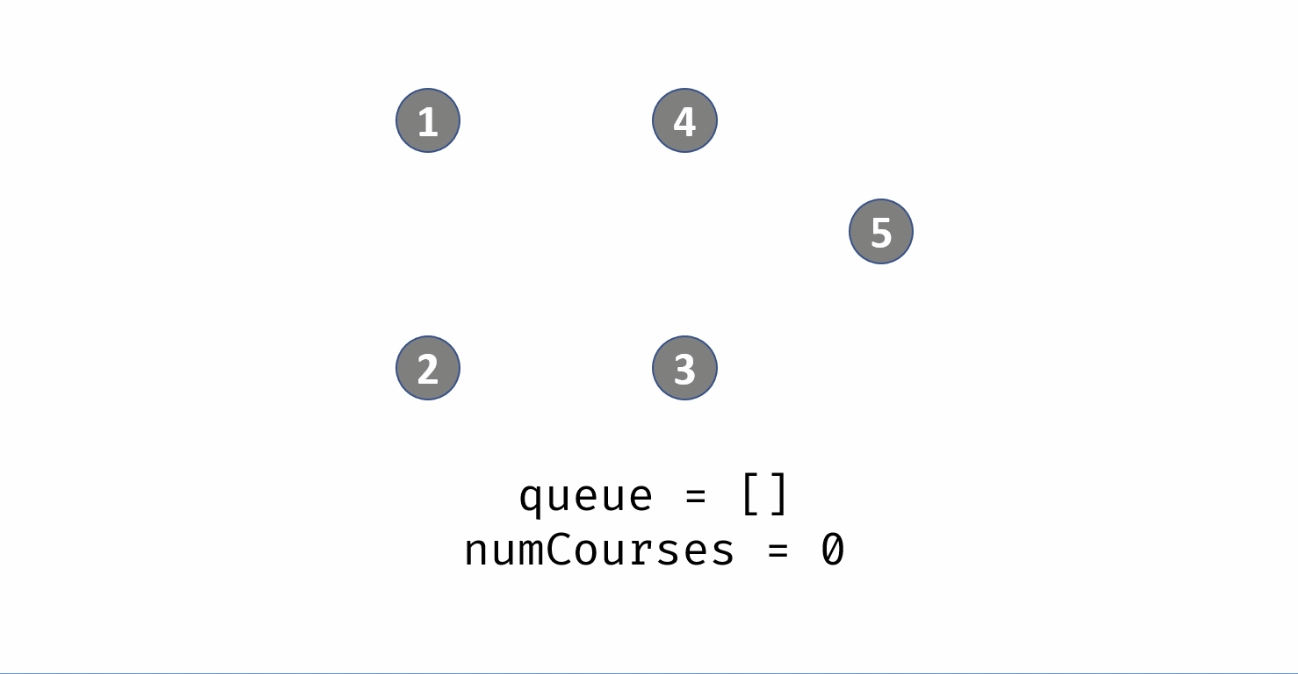
统计课程安排图中每个节点的入度,生成 入度表 indegrees。
借助一个队列 queue,将所有入度为 0 的节点入队。
当 queue 非空时,依次将队首节点出队,在课程安排图中删除此节点 pre,并不是真正从邻接表中删除此节点 pre,而是将此节点对应所有邻接节点 cur 的入度 −1,即 indegrees[cur] -= 1。
当入度 −1后邻接节点 cur 的入度为 0,说明 cur 所有的前驱节点已经被 “删除”,此时将 cur 入队。在每次 pre 出队时,执行 numCourses--;
若整个课程安排图是有向无环图(即可以安排),则所有节点一定都入队并出队过,即完成拓扑排序。换个角度说,若课程安排图中存在环,一定有节点的入度始终不为 0。
因此,拓扑排序出队次数等于课程个数,返回 numCourses == 0 判断课程是否可以成功安排。
代码实现
class Solution {
public boolean canFinish(int numCourses, int[][] prerequisites) {
//入度表
int[] indegrees = new int[numCourses];
//邻接表
List> adjacency = new ArrayList<>();
Queue queue = new LinkedList<>();
for(int i = 0; i < numCourses; i++)
adjacency.add(new ArrayList<>());
// Get the indegree and adjacency of every course.
for(int[] cp : prerequisites) {
indegrees[cp[0]]++;
adjacency.get(cp[1]).add(cp[0]);
}
// Get all the courses with the indegree of 0.
for(int i = 0; i < numCourses; i++)
if(indegrees[i] == 0) queue.add(i);
// BFS TopSort.
while(!queue.isEmpty()) {
int pre = queue.poll();
numCourses--;
for(int cur : adjacency.get(pre))
if(--indegrees[cur] == 0) queue.add(cur);
}
return numCourses == 0;
}
} 题目拓展
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
LeetCode210课程表 II
这种记录某个符合条件的结果的题目,只要在原来的代码上加上数组记录每一层的结果即可
// 记录一次 traverse 递归经过的节点
boolean[] onPath;
// 记录遍历过的节点,防止走回头路
boolean[] visited;
// 记录图中是否有环
boolean hasCycle = false;
Integer index = 0;
int[] onPathDetail;
public int[] findOrder(int numCourses, int[][] prerequisites) {
onPathDetail =new int[numCourses];
index = numCourses-1;
if (!canFinish(numCourses, prerequisites)) {
return new int[0];
} else {
return onPathDetail;
}
}
private boolean canFinish(int numCourses, int[][] prerequisites) {
List[] graph = buildGraph(numCourses, prerequisites);
visited = new boolean[numCourses];
onPath = new boolean[numCourses];
for (int i = 0; i < numCourses; i++) {
// 遍历图中的所有节点
traverse(prerequisites, graph, i);
}
// 只要没有循环依赖可以完成所有课程
return !hasCycle;
}
private List[] buildGraph(int numCourses, int[][] prerequisites) {
// 图中共有 numCourses 个节点
List[] graph = new LinkedList[numCourses];
for (int i = 0; i < numCourses; i++) {
graph[i] = new LinkedList<>();
}
for (int[] edge : prerequisites) {
int from = edge[1];
int to = edge[0];
// 修完课程 from 才能修课程 to
// 在图中添加一条从 from 指向 to 的有向边
graph[from].add(to);
}
return graph;
}
private void traverse(int[][] prerequisites, List[] graph, int s) {
if (onPath[s]) {
// 出现环
hasCycle = true;
}
if (visited[s] || hasCycle) {
// visited[s] == true 表示经过s的相关节点已经遍历无需重复校验
//可以理解为把一个可以遍历所有节点的路径分为两次traverse完成
return;
}
// 前序遍历代码位置
visited[s] = true;
onPath[s] = true;
for (int t : graph[s]) {
traverse(prerequisites, graph, t);
}
onPathDetail[index]=s;
index--;
// 后序遍历代码位置
onPath[s] = false;
} 图相关问题
题目: 给你一个所有节点的列表和一个描述路径的列表, 路径的起始节点和终止节点都在节点列表的范围内, 请你找出所有的节点可以通过路径到达的其它节点列表, 路径有可能是双向的.
示例1: 输入: allNodes: [A,B,C] relationships: A -> B <-> C [relationship1(A, B, false), relationship2(B, C, true)] 输出: A : [B, C] , B : [C], C : [B]
示例2: 输入: allNodes: [A,B,C,D] relationships: A <-> B <-> C [relationship1(A, B, true), relationship2(B, C, true)] 输出: A : [B, C] , B : [A, C], C : [A, B], D: []
代码实现
import java.util.*;
class Relationship {
String fromNode;
String toNode;
boolean bidirectional;
Relationship(String fromNode, String toNode, boolean bidirectional) {
this.fromNode = fromNode;
this.toNode = toNode;
this.bidirectional = bidirectional;
}
}
class Solution {
public Map> allReachablePaths(List allNodes, List relationships) {
Map> graph = new HashMap<>();
Map> result = new HashMap<>();
// 构建图的邻接表
for (String node : allNodes) {
graph.put(node, new ArrayList<>());
result.put(node, new ArrayList<>());
}
for (Relationship relationship : relationships) {
graph.get(relationship.fromNode).add(relationship.toNode);
if (relationship.bidirectional) {
graph.get(relationship.toNode).add(relationship.fromNode);
}
}
// 对于每个节点,找出所有可达的节点
for (String node : allNodes) {
Set visited = new HashSet<>();
dfs(graph, node, visited);
visited.remove(node); // 移除自身
result.get(node).addAll(visited);
}
return result;
}
private void dfs(Map> graph, String node, Set visited) {
if (visited.contains(node)) {
return;
}
visited.add(node);
for (String neighbor : graph.get(node)) {
dfs(graph, neighbor, visited);
}
}
}
在您的代码中,时间复杂度和空间复杂度的计算取决于两个主要因素:图的结构(邻接表的构建)和图的遍历(深度优先搜索)。
时间复杂度
-
构建图:遍历所有的关系(
relationships)来构建邻接表。如果关系的数量是R,这部分的时间复杂度是O(R)。 -
图的遍历:对于每个节点,执行一次深度优先搜索(DFS)。在最坏的情况下,即图是完全连通的,每次 DFS 都会遍历所有的节点和边。如果有
N个节点,这部分的时间复杂度是O(N^2)。
因此,总的时间复杂度大致是 O(R + N^2)。
空间复杂度
-
邻接表:存储图的邻接表。如果有
N个节点,且每个节点都与其他节点相连,则空间复杂度为O(N^2)。 -
DFS 的递归调用栈:在 DFS 过程中,最坏的情况是递归调用的深度可以达到
N,因此空间复杂度为O(N)。 -
结果存储:存储最终结果的
resultMap,它包含每个节点可达的所有其他节点。在最坏情况下,这也将占用O(N^2)的空间。
综上所述,总的空间复杂度大致是 O(N^2)。
上述算法每个节点都执行了一次 DFS,即使这个节点可能已经在之前的 DFS 中被访问过。如果题目是个无向图,为了减少重复工作,可以在全局级别维护一个已访问节点集合,以跳过那些已经访问过的节点。
参考文章
拓扑排序,YYDS!