K8s 源码剖析及debug实战之 Kube-Scheduler(五):优选算法详解
文章目录
- 0. 引言
- 1. 回顾
- 2. PrioritizeNodes
- 3. 有哪些优选算法
- 4. selectHost
- 5. 总结
- 6. 参考
0. 引言
欢迎关注本专栏,本专栏主要从 K8s 源码出发,深入理解 K8s 一些组件底层的代码逻辑,同时借助 debug Minikube 来进一步了解 K8s 底层的代码运行逻辑细节,帮助我们更好了解不为人知的运行机制,让自己学会如何调试源码,玩转 K8s。
本专栏适合于运维、开发以及希望精进 K8s 细节的同学。同时本人水平有限,尽量将本人理解的内容最大程度的展现给大家~
前情提要:
《K8s 源码剖析及debug实战(一):Minikube 安装及源码准备》
《K8s 源码剖析及debug实战(二):debug K8s 源码》
《K8s 源码剖析及debug实战之 Kube-Scheduler(一):启动流程详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(二):终于找到了调度算法的代码入口》
《K8s 源码剖析及debug实战之 Kube-Scheduler(三):debug 到预选算法门口了》
《K8s 源码剖析及debug实战之 Kube-Scheduler(四):预选算法详解》
文中采用的 K8s 版本是 v1.16。上篇介绍了预选算法的主要逻辑,本文继续介绍 K8s 的 Kube-Scheduler 源码的优选算法的具体逻辑。
1. 回顾
还记得这张图吗,目前我们在看「执行调度算法」这里,并且这里的预选算法的主要逻辑已经讲解完了。

再来看下调度的大体流程,重点关注的只剩下一个 PrioritizeNodes 方法了
func (g *genericScheduler) Schedule(pod *v1.Pod, pluginContext *framework.PluginContext) (result ScheduleResult, err error) {
// 1. 检查pvc是否存在,不是很重要
if err := podPassesBasicChecks(pod, g.pvcLister);
// 2. 运行预过滤插件,一般不需要关注
preFilterStatus := g.framework.RunPreFilterPlugins(pluginContext, pod)
// 3. 更新node的信息,以最新的node缓存信息作为后续过滤、计算优先级的基础
if err := g.snapshot(); err != nil {
return result, err
}
// 4. 重要!!!关键方法,调度预选,predicate过滤不符合的node
filteredNodes, failedPredicateMap, filteredNodesStatuses, err := g.findNodesThatFit(pluginContext, pod)
// 5. 运行后置过滤插件,一般不需要关注
postfilterStatus := g.framework.RunPostFilterPlugins(pluginContext, pod, filteredNodes, filteredNodesStatuses)
// 6. 没找到一个符合要求的node,报错!
if len(filteredNodes) == 0 {}
// 7. 只找到一个符合要求的node,直接返回!
if len(filteredNodes) == 1 {}
// 8. 重要!!!上面如果找到多个node,那需要按照priority策略筛选
priorityList, err := PrioritizeNodes(pod, g.nodeInfoSnapshot.NodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders, g.framework, pluginContext)
// 9. 好了,最终选一个node吧!
host, err := g.selectHost(priorityList)
}
注意这里在 debug 代码的时候,需要把上面的代码第7点 if len(filteredNodes) == 1 {} 注释掉,因为 Minikube 目前只创建了一个 node,在这里就返回了。如果需要 debug PrioritizeNodes 这个方法,需要注释第7点。
2. PrioritizeNodes
老规矩,我把这个方法的主要逻辑提炼一下,方便看清楚全貌:
func PrioritizeNodes(pod *v1.Pod, nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo, meta interface{}, priorityConfigs []priorities.PriorityConfig, nodes []*v1.Node, extenders []algorithm.SchedulerExtender, framework framework.Framework, pluginContext *framework.PluginContext (schedulerapi.HostPriorityList, error) {
// 用了 Map-Reduce 模式,简单来说是:分布式计算的分离+归约思想,先并行计算,然后再聚集产生最终结果
// 1. 定义了优先级打分的func,直接执行
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {...}
}
// 2. 并行执行 Map 方法,计算打分
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
for i := range priorityConfigs {
// 注意,只有没有定义func的,才用 Map-Reduce 模式
if priorityConfigs[i].Function != nil {
continue
}
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
...
}
})
// 3. 执行 Reduce 方法,聚合、归一化结果
for i := range priorityConfigs {
go func(index int) {
if err := priorityConfigs[index].Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {}
...
}(i)
}
// 4. 一般不需要关注。执行额外的打分插件,默认的K8s没有,除非自己定义
scoresMap, scoreStatus := framework.RunScorePlugins(pluginContext, pod, nodes)
// 5. 按照func的权重,计算结果
for i := range nodes {
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
...
}
// 6. 一般不需要关注。这是扩展点,允许用户通过自定义逻辑来增强或替代默认调度器功能。它主要用于满足那些需要更复杂、定制化调度策略的场景。
if len(extenders) != 0 && nodes != nil {...}
return result, nil
}
从上面的第5步可以看到,打分关注两个地方,一个是 priority-func 计算出来的 score,一个是 priority-func 本身的 weight,其中 results 是一个二维表格,如下:
| 打分函数 | Node0 | Node1 | Node2 | … |
|---|---|---|---|---|
| Priority-Func0 | s(0,0) | s(0,1) | s(0,2) | … |
| Priority-Func1 | s(1,0) | s(1,1) | s(1,2) | … |
| … | … | … | … | … |
| Priority-Funcn | s(n,0) | s(n,1) | s(n,2) | … |
其中 s(x,y) 表示,第 x 个 Priority-Func 给 第 y 个 Node 打分的结果。
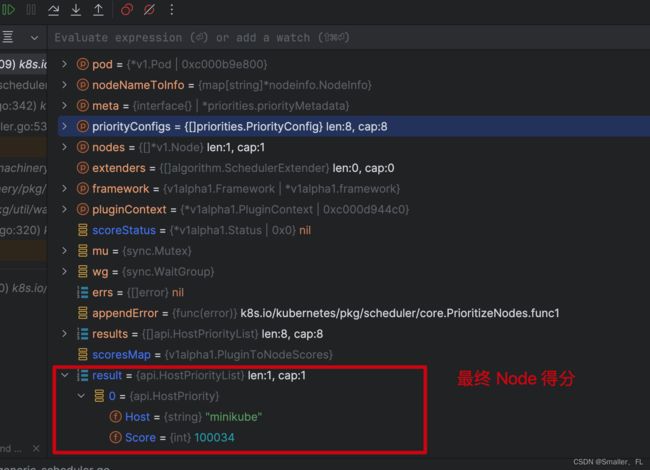
因此对于一个 Node,他的最终得分就是所有的 Priority-Func 得分 * weight 之和的结果。例如,假设,Priority-Funci 的 权重是 Wi,上表中 Node1 最终的得分如下:
finalNode1 = s(0,1)*W0 + s(1,1)*W1 + ... + s(n,1)*Wn
下面展示一下中间的 debug 的过程:

results 值:

最终得分:
3. 有哪些优选算法
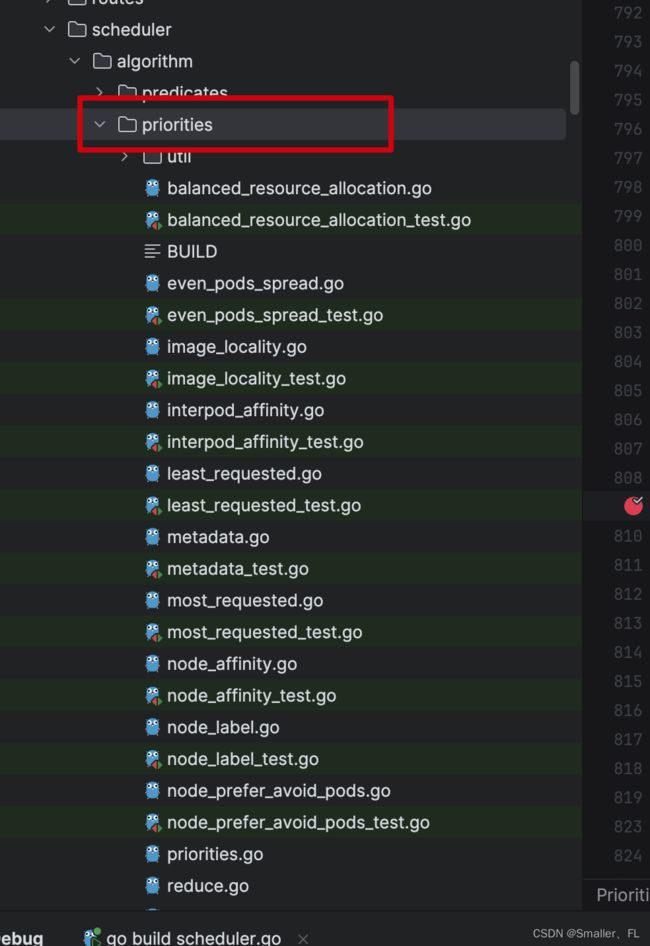
在pkg/scheduler/algorithm/priorities 目录下有优选算法的实现,当然看 pkg/scheduler/algorithm/priorities/priorities.go 有全部的定义 :
-
LeastRequestedPriority:最低请求优先级。根据 CPU
和内存的使用率来决定优先级,使用率越低优先级越高,也就是说优先调度到资源利用率低的节点,这个优先级函数能起到把负载尽量平均分到集群的节点上。默认权重为1 -
BalancedResourceAllocation:资源平衡分配。这个优先级函数会把 pod 分配到 CPU 和 memory 利用率差不多的节点(计算的时候会考虑当前 pod 一旦分配到节点的情况)。默认权重为 1
-
SelectorSpreadPriority:尽量把同一个 service、replication controller、replicaSet 的 pod 分配到不同的节点,这些资源都是通过 selector 来选择 pod 的。默认权重为 1
-
CalculateAntiAffinityPriority:尽量把同一个 service 下面 label 相同的 pod 分配到不同的节点
-
ImageLocalityPriority:根据镜像是否已经存在的节点上来决定优先级,节点上存在要使用的镜像,而且镜像越大,优先级越高。这个函数会尽量把 pod 分配到下载镜像花销最少的节点
-
NodeAffinityPriority:NodeAffinity,默认权重为 1
-
InterPodAffinityPriority:根据 pod 之间的亲和性决定 node 的优先级,默认权重为 1
-
NodePreferAvoidPodsPriority:默认权重是 10000,把这个权重设置的那么大,就以为这一旦该函数的结果不为 0,就由它决定排序结果
-
TaintTolerationPriority:默认权重是 1
4. selectHost
PrioritizeNodes 优选方法执行完成之后,会返回 node列表,在 selectHost 方法需要选择一个最终的节点作为调度的结果。这里的方法非常简单:
func (g *genericScheduler) selectHost(priorityList schedulerapi.HostPriorityList) (string, error) {
if len(priorityList) == 0 {
return "", fmt.Errorf("empty priorityList")
}
maxScore := priorityList[0].Score
selected := priorityList[0].Host
cntOfMaxScore := 1
for _, hp := range priorityList[1:] {
if hp.Score > maxScore {
maxScore = hp.Score
selected = hp.Host
cntOfMaxScore = 1
} else if hp.Score == maxScore {
cntOfMaxScore++
if rand.Intn(cntOfMaxScore) == 0 {
// Replace the candidate with probability of 1/cntOfMaxScore
selected = hp.Host
}
}
}
return selected, nil
}
简单看一下就明白,选择 score 最大的,如果存在多个 score 一样都是最大,则随机选一个作为 host 节点!
5. 总结
到目前为止,预选和优选的流程就讲解完了,我把到目前为止的整体调度流程大致展示下:

后续把调度计算后的其他流程讲解下~
6. 参考
《K8s 源码剖析及debug实战(一):Minikube 安装及源码准备》
《K8s 源码剖析及debug实战(二):debug K8s 源码》
《K8s 源码剖析及debug实战之 Kube-Scheduler(一):启动流程详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(二):终于找到了调度算法的代码入口》
《K8s 源码剖析及debug实战之 Kube-Scheduler(三):debug 到预选算法门口了》
《K8s 源码剖析及debug实战之 Kube-Scheduler(四):预选算法详解》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
也欢迎关注我的wx公众号:一个比特定乾坤