StarRocks 在小红书自助分析场景的应用与实践
作者:小红书 OLAP 研发负责人 王成
近两年 StarRocks 一直是小红书 OLAP 引擎体系里非常重要的部分,过去一年,小红书的 StarRocks 使用规模呈现出翻倍的增长速度,目前整体规模已经达到 30 个集群,CPU 规模已经达到了 3 万。
在 11 月 17 日举行的 StarRocks Summit 2023 上,小红书 OLAP 研发负责人王成介绍了最近一年小红书的 StarRocks 的应用新进展,并重点分享了 StarRocks 在小红书自助分析场景下的应用与实践经验。据王成介绍,StarRocks 3.0 在湖上分析能力的增强促使小红书自助分析场景的主力查询引擎通过灰度迁移机制从 Presto 平滑迁移到 StarRocks,已迁移部分的平均查询性能提升了 6~7 倍。
我们将王成的精彩演讲整理出来,希望小红书的实践经验对大家能有所启发。
背景 数据平台架构

图中是小红书数据平台的整体架构,从下往上分别为存储层、表格式层、数据加工层、查询层、应用层。
- 存储层,小红书的所有的存储都架构在各家云厂商的对象存储之上;
- 表格式层,以 Hive 和 Iceberg 为主;
- 数据加工层,包括离线跟实时两个链路,离线同步链路主要使用 Spark ,实时则主要使用 Flink ;
- 查询层,目前主要有4款查询引擎,在这些引擎的基础上,我们构建了非常丰富的数据产品以及分析产品;
- 应用层,包括各类的实时报表平台、自助分析平台以及一些即席分析平台。
基于 StarRocks 的实时分析场景
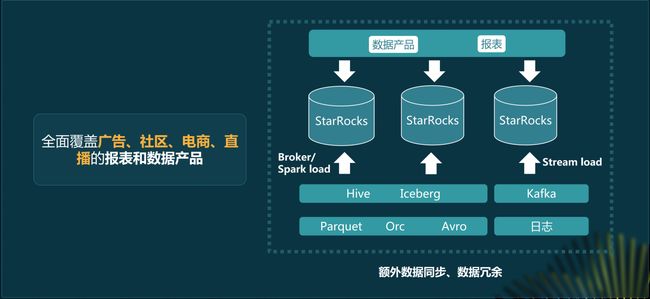
近两年,StarRocks 的存算一体的模式,一直支撑着小红书实时分析场景发展,我们已经全面覆盖了广告、社区、电商直播等等各个核心领域的报表以及数据产品。
StarRocks 在实时分析场景的规模

过去一年,小红书的 StarRocks 使用规模翻倍增长,目前整体规模已经达到 30 个集群,总 CPU 核数达到 3 万,每天数据写入量达到千亿级别,查询达到上亿次,单个集群的查询峰值 QPS 能够达到 2000 甚至 3000,并且整体的平均查询延迟能够控制在 200 毫秒,这些数字都充分说明了 StarRocks 小红书内部起的关键作用。
Adhoc 场景遇到的问题

但是这种存算一体的模式也存在一定缺陷,最核心的问题是存在额外的数据同步过程,数据必须同步到 StarRocks 内部才能对外提供服务,这就引入了数据同步以及数据冗余,带来了额外的资源消耗。此外,数据同步以及数据校验方面的工作,也给我们带来了很大的运维压力。
在自助分析场景下,查询的 QPS 以及延迟时间要求会稍微低一些,但是数据规模非常大,底层数据是整个数仓的基础数据,包括上万张表、 EB 级别的数据,如果想把这么多数据都同步到 StarRocks 里明显不现实。在这个场景下,我们之前选择了采用 Presto 来优化整体的查询性能,Presto 因其在交互式分析以及复杂查询上面的优势,过去几年帮助我们在很好地提升了查询性能、提高用户体验。但是随着小红书自助分析场景需求的不断增长,Presto 已不能满足我们日益增长的降本增效方面的需求。 在 Adhoc 场景下,Presto 上遇到了几个问题:
- 技术架构复杂化,公司内部同时有 Clickhouse、Presto 及StarRocks 三个核心查询引擎需要维护,大大增加了我们开发以及运维上面的难度。
- Presto 的性能优化困难。
- Presto 的主从模式还存在单点故障的问题,有潜在的稳定性的风险。
升级选型与真实场景测试

StarRocks 湖仓新范式
StarRocks 3.0 提出了湖仓分析的新范式,在湖上分析能力的增强,给我们带来了曙光。根据官方的一个Benchmarks,相比于 Trino, StarRocks 直接分析湖仓数据的能够有 3~5 倍的性能提升,因此我们也是选择从 Presto 迁移到 StarRocks 上。
迁移的理由包括:
- StarRocks 性能的优化代表它能够提供更高的性价比,能够给我们在降本增效上带来收益。
- StarRocks 能够简化我们的技术体系,降低运维难度。现在 StarRocks 实际上在小红书内部已经是最重要的一款查询引擎,我们对 StarRocks 的运维以及技术方面的积累更为深厚的。在这种情况下,如果能把 Presto 替换成 StarRocks,我们的整体的运维压力以及运维难度会大大降低。
- 从 Presto 到 StarRocks 的迁移非常方便,我们在 StarRocks 里面如果要查询外部数据,只需要简单定义一个 catalog 就可以了,同时 StarRocks 能够支持一些 Java 的 udf,这就方便我们去迁移在 Presto 上开发的一些定制化的功能。更重要的是,StarRocks 3.0 支持了 Trino 的方言模式。对我们来说用户是我们的分析师,他们的常用习惯是很难改变的,在这种情况下,兼容 Trino查询语义,可以让我们的整个迁移过程变得更平滑,用户体验也会更好。
***基于实际业务验证的四个方向(((
我们基于实际业务验证的 4 个方向分别是正确性、稳定性、性能以及兼容性。正确性和稳定性是查询引擎的生命基线;性能决定着我们在迁移之后能够拿到多大的业务价值;兼容性则代表着迁移的步伐,以及迁移的难度。
-
正确性方面,我们整体的验证过程起始于 3.0 版本,收敛于 3.1 版本。在 3.0 版本上,我们在测试过程中其实也是遇到了一些问题,但是在跟社区合作过程中,社区非常活跃,及时地解决了这些问题,在 3.1 版本基本上不再存在正确性方面的问题了。
-
在稳定性方面,3.1 版本已经能够达到非常高的稳定性,在我们的高压的测试当中,可以稳定运行一周以上。我们做了不同并发下的一个压力测试,分别是 10 并发、20 并发以及 30 并发,使用了 StarRocks 3.1.4 和线上稳定的 Presto 版本进行对比。随着查询并发数的增加,StarRocks 在稳定性方面的表现明显优于 Presto。

- 在性能方面,我们从过去的线上的实际查询中抽取了 3000 个查询,分别进行了串行 10 并发、20 并发、30 并发的压力测试。对比 Presto 3000 个查询里面有 96% 的查询都有非常明显性能优化效果。同时在所有的并发度下,StarRocks 的查询性能相比于 Presto 而言都会有 4 倍以上的提升。

- 在兼容性上,3.1 版本在对很多的语法兼容能力进行补全之后,目前对 Presto 相关语法兼容性能够达到 90%,还差了少量特殊语法,例如 CTAS。目前我们线上的整体覆盖度能够达到60%。
目前我们线上稳定版本已经升级到 3.2 ,该版本不仅提供了 CTAS 语法的支持,并通过jni接口帮助我们去扩展更多的 table format,以及还有很多 Iceberg 相关的兼容性优化。基于这些优化,我们的整体覆盖度已经提高到 85%左右,我们还在持续地扩展部分自定义功能,预计整体覆盖度可以提升到 90% 以上,达到新的里程碑。

从上述 4 个维度上来说,StarRocks 都已经达到了生产准入的标准。
迁移过程
在后续的迁移过程中,我们希望整个迁移过程尽可能的平稳以及稳定,因此采取了动态灰度策略。
原查询服务整体架构

如图所示是引入 StarRocks 之前小红书自助分析的整体架构,在这里面的 Kyuubi 是具有分布式以及多租户特性的网关服务,也是我们查询服务 SQL 查询的入口。在 Kyuubi 上我们也做了深度定制化开发,在这个场景里面,我们用到的核心功能是查询的路由功能和灰度功能。查询路由功能就是 Kyuubi 在接收到用户的查询之后,会根据用户查询的语法特性以及负载情况,将其动态路由到合适的计算引擎进行查询。
在这个场景下,我们是以 Presto 的查询引擎为主,当用户的查询涉及到一些比较特殊的语法或者数据的扫描量特别大的时候,会将这些查询路由到 Spark 去执行。
灰度迁移机制

在引入 StarRocks 之后,我们对原有的 Presto 集群进行了切割,搭建了一个 StarRocks 集群,同时在路由规则里面增加 StarRocks 目前还不兼容的语法判断条件。当用户的查询过来之后,会首先判断用户的查询是否在 StarRocks 上能兼容,如果不能兼容,就会直接路由到 Presto 去执行。如果能够兼容,就会根据我们的灰度规则来动态决定它是发到 StarRocks 还是 Presto。这里的灰度规则主要是指动态的灰度比例,可以进行实时调整。
实际业务效果

在整个灰度调整过程中,我们会进行持续的正确性验证,会利用每天闲时,也就是集群使用量较低的低峰期时间段,去对 StarRocks 上的查询结果跟 Presto 查询结果进行动态比对。只有当天的查询性能、稳定性以及正确性都满足目标的时候,我们才会进一步增加动态灰度比例。这样的灰度调整大概持续了一个月,StarRocks 的灰度比例从 0% 提升到了100%,在这个过程中,我们切实享受到了 StarRocks 带来的性能提升效果。就已经迁移的部分而言,整体的平均查询性能提升了 6~7 倍,查询的 p90 降低了 90%,对于用户来说,查询体验得到了非常大的优化。并且我们整个迁移过程非常平稳,没有出现任何事故,也没有遇到用户吐槽。
弹性伸缩降本增效
集群架构

基于以上已经灰度的 StarRocks 湖上分析集群,我们拿到了很多的性能上的收益。同时我们希望能够在保持这部分性能不变的情况下,进一步达到降本增效的效果,因此我们在弹性伸缩上做了一些尝试。我们的 StarRocks 湖上分析集群整体架构分为 FE、CN 两部分,其中 CN 作为计算节点,本身就没有状态,非常符合弹性伸缩的理念。
基于 AWS Spot 的弹性伸缩方案
通常可以通过 CN 的容器化来进行弹性伸缩,我们的场景会更特殊一点,因为我们目前的数仓架构体系核心还是构建在 AWS 之上的,而 AWS 提供的 Spot 实例的服务,可以让我们以竞价的方式来获取空闲的机器,这个竞价相比于包年包月的方式能够最高享受到 90% 的折扣,并且可以随起随用,在低峰期可以直接把机器还给 AWS,不收取任何费用。
为了适配弹性伸缩,我们主要实现了两块内容,一个是 CN 的自动化部署的脚本,还有一个是 CN 会自动的向 FE 进行注册跟注销。在扩容的时候,我们会自动向 AWS 去申请 Spot 实例机器,当这些实体机器就位之后,会通过我们的自动化部署脚本进行部署,然后注册到我们的 FE上,这时候就可以对外提供服务了。缩容的时候,会自动的从 FE 进行注销,注销完之后再向 AWS 归还我们的 Spot 实例。这两个自动化脚本让我们整体的扩缩容的流程变得更加的丝滑,扩缩容操作可以在 2 分钟内完成。
在整体架构上,我们所有的 FE 以及少量的 CN 上,使用的是包年包月方式,少量常驻的机器能保证我们能够提供最基础的服务能力,另外有 90% 的 CN 节点是通过 Spot 来申请的,可以在低峰期将这部分机器完全还掉。
成本优化效果

目前我们采取的还是一种固定时间进行弹性扩展的方式。比如现在定义的低峰期就是 00:00~8:00,高峰期是9:00~23:00。高峰期机器比较抢手,竞价价格会比较高,我们也不希望我们的机器经常被其他用户所抢占,因此高峰期的成本基本持平。在低峰期我们可以将 90% 的 CN 机器全部还掉,这能够节约大量的成本。总体而言,在目前查询性能不变的前提下,总体的成本能够降低 35%。
未来规划
短期目标:进一步拓展 StarRocks 的湖上分析能力
未来我们的短期目标还是继续在 StarRocks 的湖上分析上进行更多拓展。StarRocks 湖上分析是我们走向湖仓一体的第一步,这一块目前还有一些欠缺。
-
我们目前最关注的指标就是整体查询的覆盖度,3.2 的版本的发布给我们带来很大的覆盖度提升。剩下一部分主要是 udf 功能持续的丰富,StarRocks 目前的 udf 相比于 Hive 而言灵活性稍差,比如支持的类型有限,不能支持动态返回类型等,我们未来会和社区一起在这方面进行持续的功能拓展。
-
数据湖 Iceberg 的集成优化,这一块目前也有很多亟需优化的点,我们会持续的跟社区一起去合作打磨。
-
我们目前完全没有开启缓存,上述的那些测试数据都是不包括缓存的,我们未来也希望能够去对本地缓存以及分布式缓存进行持续的探索,看看能不能基于缓存去进一步优化我们整体的查询性能。
长期目标:实践存算分离与湖仓一体

长期来看,我们的两个方向,一个是存算分离模式的实践,另外一个还是湖仓一体的建设。
存算分离模式的引入能够帮助我们去替换掉更多的 OLAP 分析场景,帮助我们进一步降低整体技术栈的复杂度。
在湖仓一体方面,我们希望能将存算分离模式和湖上分析场景融合到一起,通过湖仓一体架构带来更强的数据开发和数据分析能力,包括但不止于以下两个关键特性:
1 ,打破湖和仓之间的隔阂,降低架构复杂度
存算分离模式,StarRocks 私有的数据格式也会放到云上,实际上成为了整个湖仓体系中一个普通的数据 format。用户在基于湖数据进行自助分析时,如果对查询性能有了更高的要求,可以通过物化视图的方式,将数据聚合成更高维度的 StarRocks 私有格式数据,提供查询加速。物化视图的构建也可以根据查询历史自动化构建,更为智能和高效。
2 ,数据的流转更加方便高效
社区目前也在尝试通过 Spark 直接生成 StarRocks 自由格式数据,这项功能可以进一步实现读写分离,优化湖仓一体场景下数据同步的性能和便利性。
本文由 mdnice 多平台发布