Hive基本使用(2)
hive DML数据操作
一、数据导入
1.向表中装载数据(Load)
语法:
hive> load data [local] inpath ‘数据的path’ [overwrite] into table student [partition (partcol1=val1,…)];
注:
1.中括号括起来的是可以选择的
2.关键字含义:
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
准备表和数据
-- 数据
[atdyh@hadoop102 datas]$ cat student1.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
[atdyh@hadoop102 datas]$ cat student1.txt
1001 ss1
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
-- 创建表
hive (dyhtest)> create table student(id string, name string) row format delimited fields terminated by '\t';
OK
Time taken: 0.136 seconds
-- load加载数据
hive (dyhtest)> load data local inpath '/opt/module/hive-3.1.2/datas/student1.txt' into table student;
Loading data to table dyhtest.student
OK
Time taken: 0.265 seconds
hive (dyhtest)> load data local inpath '/opt/module/hive-3.1.2/datas/student2.txt' into table student;
Loading data to table dyhtest.student
OK
Time taken: 0.187 seconds
hive (dyhtest)> select * from student;
OK
student.id student.name
1001 ss1 NULL
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
Time taken: 0.155 seconds, Fetched: 16 row(s)
-- 使用override into替换into
hive (dyhtest)> load data local inpath '/opt/module/hive-3.1.2/datas/student2.txt' overwrite into table student;
Loading data to table dyhtest.student
OK
Time taken: 0.313 seconds
hive (dyhtest)> select * from student;
OK
student.id student.name
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
Time taken: 0.122 seconds, Fetched: 8 row(s)
2.Insert into
语法1: insert into 表名 values(字段值1,字段值2…)
语法2: insert into 表名 values(字段值1,字段值2…),(字段值1,字段值2…)
注意:
1.语法1每次插进去一条数据,会执行多个mr,创建多个hdfs目录。语法二只会执行一个mr,创建一个hdfs目录
hive (dyhtest)> insert into student values(1017,'ss17'),(1018,'ss18'),(1019,'ss19');
Query ID = atdyh_20220626225810_d15b2f6a-0027-45ff-9543-0a61216819b7
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1656254332818_0001, Tracking URL = http://hadoop103:8088/proxy/application_1656254332818_0001/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1656254332818_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2022-06-26 22:58:23,891 Stage-1 map = 0%, reduce = 0%
2022-06-26 22:58:35,045 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.92 sec
2022-06-26 22:58:42,311 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.8 sec
MapReduce Total cumulative CPU time: 10 seconds 800 msec
Ended Job = job_1656254332818_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop102:9820/user/hive/warehouse/dyhtest.db/student/.hive-staging_hive_2022-06-26_22-58-10_481_389170119456264139-1/-ext-10000
Loading data to table dyhtest.student
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 10.8 sec HDFS Read: 14989 HDFS Write: 292 SUCCESS
Total MapReduce CPU Time Spent: 10 seconds 800 msec
OK
_col0 _col1
Time taken: 35.595 seconds
如果发现查询的顺序不对,是正常的,hive在select数据的时候,是扫描hdfs文件,哪个在前面哪个先展示找到:
第一个文件是刚刚insert进来的,下面是我们之前存在的,查询结果如下:
--- 插入的数据
hive (dyhtest)> insert into student values(1017,'ss17'),(1018,'ss18'),(1019,'ss19');
--- 查询出来的
hive (dyhtest)> select * from student;
OK
student.id student.name
1017 ss17
1018 ss18
1019 ss19
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
Time taken: 0.242 seconds, Fetched: 11 row(s)
注意:一般同步全量表的时候一般使用insert overwrite table 表名
hive (dyhtest)> insert overwrite table student2 select id, name from student ;
Query ID = atdyh_20220626232407_2b76a88a-1ffb-4b45-bf7d-54ac930f0013
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1656254332818_0004, Tracking URL = http://hadoop103:8088/proxy/application_1656254332818_0004/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1656254332818_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2022-06-26 23:24:13,724 Stage-1 map = 0%, reduce = 0%
2022-06-26 23:24:18,853 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.96 sec
2022-06-26 23:24:23,961 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.11 sec
MapReduce Total cumulative CPU time: 4 seconds 110 msec
Ended Job = job_1656254332818_0004
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop102:9820/user/hive/warehouse/dyhtest.db/student2/.hive-staging_hive_2022-06-26_23-24-07_679_2919795235412649998-1/-ext-10000
Loading data to table dyhtest.student2
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.11 sec HDFS Read: 13447 HDFS Write: 477 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 110 msec
OK
id name
Time taken: 17.597 seconds
- insert into 新表名 select 字段名 from 旧表
hive (dyhtest)> insert into student2 select id, name from student ;
Query ID = atdyh_20220626231658_f215e897-13ff-4490-bb26-036736da7d8d
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1656254332818_0002, Tracking URL = http://hadoop103:8088/proxy/application_1656254332818_0002/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1656254332818_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2022-06-26 23:17:06,071 Stage-1 map = 0%, reduce = 0%
2022-06-26 23:17:12,265 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.64 sec
2022-06-26 23:17:21,488 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.41 sec
MapReduce Total cumulative CPU time: 7 seconds 410 msec
Ended Job = job_1656254332818_0002
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop102:9820/user/hive/warehouse/dyhtest.db/student2/.hive-staging_hive_2022-06-26_23-16-58_787_3228523954450303062-1/-ext-10000
Loading data to table dyhtest.student2
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.41 sec HDFS Read: 13358 HDFS Write: 477 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 410 msec
OK
id name
Time taken: 24.156 seconds
hive (dyhtest)> select * from student2;
OK
student2.id student2.name
1017 ss17
1018 ss18
1019 ss19
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
Time taken: 0.149 seconds, Fetched: 11 row(s)
- as select
语法: create table 新表名 as select 字段名 from 旧表名 ;
hive (dyhtest)> create table student3 as select id, name from student ;
Query ID = atdyh_20220626231949_6e94c969-34a3-4880-9b88-f8c11c9f3800
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1656254332818_0003, Tracking URL = http://hadoop103:8088/proxy/application_1656254332818_0003/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1656254332818_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2022-06-26 23:19:57,126 Stage-1 map = 0%, reduce = 0%
2022-06-26 23:20:03,320 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.2 sec
MapReduce Total cumulative CPU time: 2 seconds 200 msec
Ended Job = job_1656254332818_0003
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop102:9820/user/hive/warehouse/dyhtest.db/.hive-staging_hive_2022-06-26_23-19-49_298_8591537450064111884-1/-ext-10002
Moving data to directory hdfs://hadoop102:9820/user/hive/warehouse/dyhtest.db/student3
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.2 sec HDFS Read: 5051 HDFS Write: 181 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 200 msec
OK
id name
Time taken: 15.666 seconds
hive (dyhtest)> select * from student3;
OK
student3.id student3.name
1017 ss17
1018 ss18
1019 ss19
1009 ss9
1010 ss10
1011 ss11
1012 ss12
1013 ss13
1014 ss14
1015 ss15
1016 ss16
Time taken: 0.135 seconds, Fetched: 11 row(s)
5.location
在hadfs上创建/student4目录,把数据放到对应的目录下
[atdyh@hadoop102 ~]$ hadoop fs -mkdir /student4
[atdyh@hadoop102 datas]$ hadoop fs -put student1.txt /student4
2022-06-26 23:27:05,379 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
创建表的时候指定数据所在的目录,不需要到文件
hive (dyhtest)> create table student4(id string, name string)
> row format delimited fields terminated by '\t'
> location '/student4' ;
OK
Time taken: 0.101 seconds
hive (dyhtest)> select * from student4;
OK
student4.id student4.name
1001 ss1 NULL
1002 ss2
1003 ss3
1004 ss4
1005 ss5
1006 ss6
1007 ss7
1008 ss8
Time taken: 0.135 seconds, Fetched: 8 row(s)
二、数据导出
1.insert overwrite [local] directory ‘目标文件目录’
**注意:**带local的话是指定本地服务器目录,不带local可指定hdfs目录
hive (dyhtest)> insert overwrite local directory '/opt/module/hive-3.1.2/datas/insert_res' select * from emptest;
Query ID = atdyh_20220627115928_f4be29af-9aae-43eb-b43f-a44a56e5901b
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1656254332818_0005, Tracking URL = http://hadoop103:8088/proxy/application_1656254332818_0005/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1656254332818_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2022-06-27 11:59:38,666 Stage-1 map = 0%, reduce = 0%
2022-06-27 11:59:45,879 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.29 sec
MapReduce Total cumulative CPU time: 2 seconds 290 msec
Ended Job = job_1656254332818_0005
Moving data to local directory /opt/module/hive-3.1.2/datas/insert_res
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.29 sec HDFS Read: 4838 HDFS Write: 33 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 290 msec
OK
emptest.empid emptest.empname
Time taken: 18.175 seconds
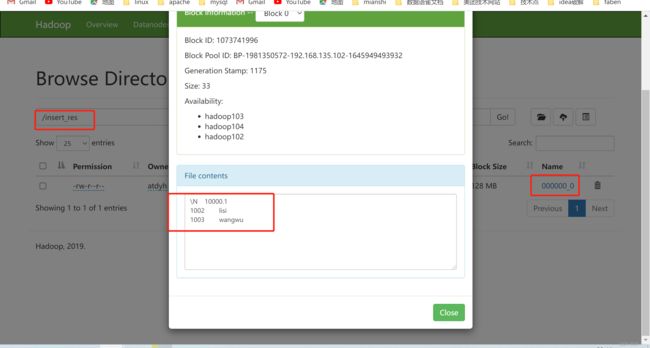
[atdyh@hadoop102 insert_res]$ ll
总用量 4
-rw-r--r--. 1 atdyh atdyh 33 6月 27 11:59 000000_0
[atdyh@hadoop102 insert_res]$ cat 000000_0
\N10000.1
1002lisi
1003wangwu
可以发现,导出来的数据没带格式,接下来将查询的结果格式化导出到本地,方便之后使用:
hive (dyhtest)> insert overwrite local directory '/opt/module/hive-3.1.2/datas/insert_res' row format delimited fields terminated by'\t' select * from emptest;
Query ID = atdyh_20220627121231_90f6f21b-0a81-41e3-9345-ccb3acd98002
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1656254332818_0006, Tracking URL = http://hadoop103:8088/proxy/application_1656254332818_0006/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1656254332818_0006
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2022-06-27 12:12:37,682 Stage-1 map = 0%, reduce = 0%
2022-06-27 12:12:43,851 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.22 sec
MapReduce Total cumulative CPU time: 2 seconds 220 msec
Ended Job = job_1656254332818_0006
Moving data to local directory /opt/module/hive-3.1.2/datas/insert_res
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.22 sec HDFS Read: 4967 HDFS Write: 33 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 220 msec
OK
emptest.empid emptest.empname
Time taken: 14.124 seconds
[atdyh@hadoop102 insert_res]$ ll
总用量 4
-rw-r--r--. 1 atdyh atdyh 33 6月 27 12:12 000000_0
[atdyh@hadoop102 insert_res]$ cat 000000_0
\N 10000.1
1002 lisi
1003 wangwu
如果表中的列的值为null,导出到文件中以后通过\N来表示.
把数据上传到hdfs目录下:
在hdfs上创建对应的目录:

hive (dyhtest)> insert overwrite directory '/insert_res' row format delimited fields terminated by'\t' select * from emptest;
Query ID = atdyh_20220627122109_b1ffbc45-c89a-4fe9-8019-4df436cdbd0a
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1656254332818_0007, Tracking URL = http://hadoop103:8088/proxy/application_1656254332818_0007/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1656254332818_0007
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2022-06-27 12:21:15,216 Stage-1 map = 0%, reduce = 0%
2022-06-27 12:21:22,387 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.09 sec
MapReduce Total cumulative CPU time: 2 seconds 90 msec
Ended Job = job_1656254332818_0007
Stage-3 is selected by condition resolver.
Stage-2 is filtered out by condition resolver.
Stage-4 is filtered out by condition resolver.
Moving data to directory hdfs://hadoop102:9820/insert_res/.hive-staging_hive_2022-06-27_12-21-09_366_6901344285579764225-1/-ext-10000
Moving data to directory /insert_res
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.09 sec HDFS Read: 4859 HDFS Write: 33 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 90 msec
OK
emptest.empid emptest.empname
Time taken: 14.155 seconds
2.Export导出到HDFS上
可以把数据和表的元数据都导出,export和import主要用于两个Hadoop平台集群之间Hive表迁移。只能导出到hdfs不能导出到本地。
语法:export table 表名 to ‘要导入的hdfs路径’
hive (dyhtest)> export table emptest to '/emptest' ;
OK
Time taken: 0.287 seconds
hdfs 如下:
这里插播一下import的用法:
语法:import tables 表名 from ‘export的hdfs路径’
hive (dyhtest)> import table emptest2 from '/emptest';
Copying data from hdfs://hadoop102:9820/emptest/data
Copying file: hdfs://hadoop102:9820/emptest/data/emptest.txt
Loading data to table dyhtest.emptest2
OK
Time taken: 1.779 seconds
hive (dyhtest)> select * from emptest2;
OK
emptest2.empid emptest2.empname
NULL 10000.1
1002 lisi
1003 wangwu
Time taken: 0.173 seconds, Fetched: 3 row(s)
三、清除数据
语法: truncate table 表名
注意: Truncate只能删除管理表,不能删除外部表中数据
--- 内部表
hive (dyhtest)> desc formatted emptest2;
OK
col_name data_type comment
# col_name data_type comment
empid int
empname string
# Detailed Table Information
Database: dyhtest
OwnerType: USER
Owner: atdyh
CreateTime: Mon Jun 27 12:36:14 CST 2022
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://hadoop102:9820/user/hive/warehouse/dyhtest.db/emptest2
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
bucketing_version 2
last_modified_by atdyh
last_modified_time 1655646133
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1656304575
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.136 seconds, Fetched: 35 row(s)
--- 可清空
hive (dyhtest)> truncate table emptest2;
OK
Time taken: 0.48 seconds
hive (dyhtest)> select * from emptest2;
OK
emptest2.empid emptest2.empname
Time taken: 0.105 seconds
--- 外部表
hive (dyhtest)> desc formatted mytbl;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: dyhtest
OwnerType: USER
Owner: atdyh
CreateTime: Sun Jun 05 16:00:53 CST 2022
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://hadoop102:9820/user/hive/warehouse/dyhtest.db/mytbl
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"id\":\"true\",\"name\":\"true\"}}
EXTERNAL TRUE
bucketing_version 2
last_modified_by atdyh
last_modified_time 1656305295
numFiles 1
numRows 1
rawDataSize 10
totalSize 11
transient_lastDdlTime 1656305295
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.063 seconds, Fetched: 35 row(s)
--- 不能清空
hive (dyhtest)> truncate table mytbl;
FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table mytbl.
hive (dyhtest)>