索引类型-哈希索引
一. 前言
前面我们简单介绍了数据库的B-Tree索引,下面我们介绍另一种索引类型-哈希索引。
二. 哈希索引的简介
哈希索引(hash index) 基于哈希表实现,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有索引列计算一个哈希码(hash code),哈希码是一个较小的值,并且在不同键值的行计算出来的码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
在Mysql中,只有Memory引擎显示支持哈希索引。是它默认的存储引擎。值得注意的是,Memory引擎是支持非唯一哈希索引的。如果多个列的哈希值相同,索引会以链表的方式存放多个记录指针到同一个哈希条目中。
三. 案例说明
- 建表语句
CREATE TABLE testhash (
fname VARCHAR ( 50 ) NOT NULL,
Iname VARCHAR ( 50 ) NOT NULL,
KEY USING HASH ( fname )
) ENGINE = MEMORY;
- 插入语句
INSERT INTO `test`.`testhash` (`fname`, `Iname`) VALUES ('Aerjen', 'Lentz');
INSERT INTO `test`.`testhash` (`fname`, `Iname`) VALUES ('Baron', 'Schwartz');
INSERT INTO `test`.`testhash` (`fname`, `Iname`) VALUES ('Peter', 'Zaitsev');
INSERT INTO `test`.`testhash` (`fname`, `Iname`) VALUES ('Vadim', 'Tkachenko');
- 数据内容
SELECT * from testhash

假设索引使用假想的哈希函数 f(), 他返回下面的值(都是示例数据,非真实数据)
f(‘Arjen’) = 2323
f(‘Baron’) = 7437
f(‘Peter’) = 8784
f(‘Vadim’) = 2458
则哈希索引的数据结构如下:
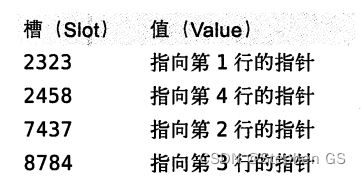
哈希查找方式
注意每个槽的编号是顺序的,但是数据行不是。
- 搜索方式
SELECT Iname FROM testhash WHERE fname = 'Peter'
Mysql 先计算 ‘Peter’的哈希值,并使用该值寻找对应的记录指针。因为 f(‘Peter’) = 8784, 所以Mysql 在索引中查找8784,可以找到指向第3行的指针,最后一步就是比较第三行的值是否为’Peter’,以确保就是要查找的行。
四. 哈希索引的优缺点
优点:
- 索引自身只需存储对应的哈希值,所以索引的结构十分紧凑,这也让哈希索引查找速度非常快。
- 访问哈希索引的数据非常快,除非有很多哈希冲突。(不同的索引列值却有相同的哈希值)。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到结果.
缺点:
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行速度很快,所以大部分情况下这一影响并不明显。
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序
- 哈希索引页不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。例如, 在数据列(A,B) 上建立哈希索引,如果查询只有数据列A,则无法使用该索引。
- 哈希索引只支持等值比较查询,包括 =, IN(), <=>。它也不支持任何范围查询,例如 WHERE price > 100
五. InnoDB中的哈希索引
1. 简介
InnoDB 引擎有一个特殊的功能叫做"自适应哈希索引"。当InnoDB 注意到某些索引值被使用得非常频繁时,它会在内存中基于 B-Tree 索引之上创建一个哈希索引,这样就让B-Tree索引也具有哈希索引的一些优点,比如快速的哈希查找。这是一个完全自动的,内部的行为,用户无法控制或者配置,不过如果有必要,完全可以关闭该功能。
2. 案例说明
如果表中存储了大量的URL,并需要根据URL 进行搜索查找。如果使用 B-Tree来存储URL,存储的内容就会很大,因为URL本身都很长。正常情况下会有如下查询:
SELECT id FROM url WHERE url = 'http://www.mysql.com';
若删除原来的URL列上的索引,而新增一个被索引的 url_crc列,使用 CRC32做哈希,就可以使用下面的方式查询:
SELECT id FROM url WHERE url = 'http://www.mysql.com'
AND url_crc=CRC32("http://www.mysql.com");
这样做的性能会非常高,因为Mysql优化器会使用这个选择性很高而体积很小的基于 url_crc 列的索引来完成查找。即使有多个记录有相同的索引值,查询仍然很快,只需要根据哈希值做快速的整数比较就能找到索引条目,然后一一比较返回对应的行。这比直接通过url做B-Tree索引要快的多。