Reids在Win下无法远程访问
1.将redis在windows上启动主要做了以下配置
1.1.在redis.windows.conf中修改一下
原:bind 127.0.0.1
改:# bind 127.0.0.1
bind 0.0.0.0
原:protected-mode yes
改:protected-mode no
去掉了127.0.0.1,加入0.0.0.0后,Redis就可以接收来自任意IP地址的请求了。
1.2.在cmd中启动redis服务
命令:
cd redis服务文件夹所在位置
redis-server redis.windows.conf
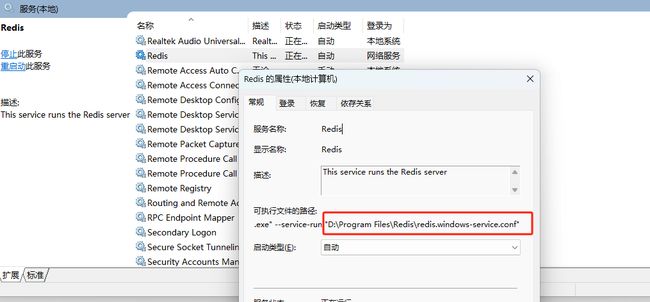
注意:修改配的时候看一下reids服务所使用的配置文件,比如我这里默认使用了
redis.windows-service.conf
2.其他配置
2.1 持久化配置
决定了是否将数据存到硬盘上,在重启redis后这些数据依旧存在
# 配置文件中如下
# 每次有数据修改发生时都会写入AOF文件:
appendfsync always
# 每秒钟同步一次,该策略为AOF的缺省策略:
appendfsync everysec
# 从不同步。高效但是数据不会被持久化:
appendfsync no
2.2.RDB持久化配置
#在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 900 1
#在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 300 10
#在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
save 60 10000
3.3最大使用内存
例如配置最大使用内存为8Gb,8*1024*1024*1024
maxmemory 8589934592
Redis内存大小的默认值
Redis内存大小的默认值取决于所使用的Redis版本。对于Redis2.4及更早的版本,内存最大值为64MB,在64位系统中可以达到3GB。但是,Redis2.6和更高版本内存默认为
最大物理内存的一半,可以根据实际情况调整。
4.配置文件全文翻译
# Redis配置文件例子.
#
# 注意:为了能读取到配置文件,Redis服务必须以配置文件的路径作为第一个参数启动
# ./redis-server /path/to/redis.conf
# 关于单位,当你需要指定内存的大小时,可以使用如下的单位来指定
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# 单位是大小写不敏感的 所以 1GB 1Gb 1gB 是一样的
################################## INCLUDES ###################################
# 如果你拥有一个标准的配置模板,并且希望在该模板之上做一些个性化的修改,你可以
# 使用include 指令来引入其他的配置文件。
#
# 注意:"include" 不会被 admin 或者 Redis Sentinel "CONFIG REWRITE" 命令覆盖。
#(译者注:"CONFIG REWRITE" 是redis 2.8 引入的新命令,用来重写配置)
# 由于redis以最终的配置作为实际配置,因此我们希望你将include命令放置在配置文件的最前面
# 以防配置被覆盖
# 如果你打算使用另外的 conf文件来覆盖当前文件的配置,那么最好将include指令放置到该文件的末尾
#
# 即最后生效原则,最后被解析的配置将作为最后的配置
#
# include /path/to/local.conf
# include /path/to/other.conf
################################## NETWORK #####################################
# 默认情况下redis会在所有的可用网络接口中进行监听,如果你想让redis在指定的网络接口中
# 监听,那么可以使用bind 命令来指定redis的监听接口
#
# 例如:
#
# bind 192.168.1.100 10.0.0.1
# bind 127.0.0.1 ::1
#
# ~~~ 警告 ~~~ 如果允许所有的网络接口访问Redis,这样做是很危险的,如果你只是需要本机访问
# 可以指定特定的127.0.0.1,如果需要外网访问,请配置防火墙策略
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
bind 127.0.0.1
# 是否开启保护模式,默认开启。要是配置里没有指定bind和密码。
# 开启该参数后,redis只会本地进行访问,拒绝外部访问。
# 要是开启了密码和bind,可以开启。否则最好关闭,设置为no。
protected-mode yes
# 在指定的端口上进行监听,默认是 6379
# 如果端口设置为0,那么redis就不会在TCP socket上进行监听
port 6379
# TCP listen() backlog.
#
# 在一个并发量高的环境中,你需要指定一个比较大的backlog值来避免慢连接的情况
# 注意,linux内核会默认 使用/proc/sys/net/core/somaxconn 的值来削减 backlog的实际值,
# 因此你需要确保提升 somaxconn 和 tcp_max_syn_backlog 这两个值来确保此处的backlog生效
tcp-backlog 511
# Unix socket.
#
# 指定unix sock的路径来进行连接监听,默认是不指定,因此redis不会在unix socket上进行监听
#
# unixsocket /tmp/redis.sock
# unixsocketperm 700
# 关闭掉空闲N秒的连接(0则是不处理空闲连接)
timeout 0
# TCP keepalive.
#
# 如果该值不为0,将使用 SO_KEEPALIVE 这一默认的做法来向客户端连接发送TCP ACKs
#
# 这样的好处有以下两个原因
# 1)检测已经死亡的对端(译者注:TCP的关闭会存在无法完成4次握手的情况,如断电,断网,数据丢失等等)
# 2)保持连接在网络环境中的存活
#
tcp-keepalive 0
################################# GENERAL #####################################
# redis默认不是以一个守护进程来运行的,使用 yes,可以让redis作为守护进程来运行
# 注意:当redis作为守护进程的时候 /var/run/redis.pid 作为 pid 文件
daemonize yes
# 3.2新增的参数,不懂
supervised no
# 当redis以守护进程运行时,将会使用/var/run/redis.pid作为 pid文件的位置
pidfile /var/run/redis.pid
# 指定日志的记录级别的
# 可以是如下的几个值之一
# debug (尽可能多的日志信息,用于开发和测试之中)
# verbose (少但是有用的信息, 没有debug级别那么混乱)
# notice (适量的信息,用于生产环境)
# warning (只有非常重要和关键的信息会被记录)
loglevel notice
# 指定日志文件的位置. 为空时将输出到标准输出设备
# 如果你在demo模式下使用标准输出的日志,日志将会输出到 /dev/null
logfile redis.log
# 当设置 'syslog-enabled'为 yes时, 允许记录日志到系统日志中。
# 以及你可以使用更多的日志参数来满足你的要求
# syslog-enabled no
# 指定在系统日志中的身份
# syslog-ident redis
# 指定系统日志的能力. 必须是 LOCAL0 到 LOCAL7 之间(闭区间).
# syslog-facility local0
# 设置数据库的数量. 默认的数据库是DB 0 使得你可以在每一个连接的基础之上使用
# SELECT 来指定另外的数据库,但是这个值必须在 0到 'database'-1之间
databases 16
################################ SNAPSHOTTING ################################
#
# 保存 DB 到硬盘:
#
# save
#
# 将会在 和 两个值同时满足时,将DB数据保存到硬盘中
# 其中 每多少秒,是改变的key的数量
#
# 在以下的例子中,将会存在如下的行为
# 当存在最少一个key 变更时,900秒(15分钟)后保存到硬盘
# 当存在最少10个key变更时,300秒后保存到硬盘
# 当存在最少1000个key变更时,60秒后保存到硬盘
#
# 提示: 你可以禁用如下的所有 save 行
#
# 你可以删除所有的save然后设置成如下这样的情况
#
# save ""
save 900 1
save 300 10
save 60 10000
# 作为默认,redis会在RDB快照开启和最近后台保存失败的时候停止接受写入(最少一个保存点)
# 这会使得用户察觉(通常比较困难)到数据不会保持在硬盘上的正确性,否则很难发现
# 这些灾难会发生,如果后台保存程序再次开始工作,reidis会再次自动允许写入
# 然而如果对redis服务器设置了合理持续的监控,那么你可以关闭掉这个选项。
# 这会导致redis将继续进行工作,无论硬盘,权限或者其他的是否有问题
stop-writes-on-bgsave-error no
# 是否在dump到 rdb 数据库的时候使用LZF来压缩字符串
# 默认是 yes,因为这是一个优良的做法
# 如果你不想耗费你的CPU处理能力,你可以设置为 no,但是这会导致你的数据会很大
rdbcompression yes
# 从RDB的版本5开始,CRC64校验值会写入到文件的末尾
# 这会使得格式化过程中,使得文件的完整性更有保障,
# 但是这会在保存和加载的时候损失不少的性能(大概在10%)
# 你可以关闭这个功能来获得最高的性能
#
# RDB文件会在校验功能关闭的时候,使用0来作为校验值,这将告诉加载代码来跳过校验步骤
rdbchecksum yes
# DB的文件名称
dbfilename dump.rdb
# 工作目录.
#
# DB将会使用上述 'dbfilename'指定的文件名写入到该目录中
#
# 追加的文件也会在该目录中创建
#
# 注意,你应该在这里输入的是一个目录而不是一个文件名
dir ./
################################# REPLICATION #################################
# 主从复制。使用 slaveof 命令来 指导redis从另一个redis服务的拷贝中来创建一个实例
#
# 注意:这个配置是主从结构的从(主从结构的从,怎么那么拗口呢)redis的本地配置
#
# 如下例子,这个配置指导 slave (从redis)
# 通过另一个redis的实例的ip和端口号来获取DB数据
#
# slaveof
# 如果主服务器开启了密码保护(使用下面的"requirepass"配置)
# 这个配置就是告诉从服务在发起向主服务器的异步复制的请求之前使用如下的密码进行认证,
# 否则主服务器会拒绝这个请求
#
# masterauth Redis执行错误问题:
一:背景
报错信息:
redis.exceptions.ResponseError: MISCONF Redis is configured to save RDB snapshots, but it's currently unable to persist to disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.
二:原因
Redis配置为保存RDB快照,但目前无法在磁盘上持久化。可能修改数据集的命令被禁用,因为此实例配置为在RDB快照失败时报告写入期间的错误。
三:解决方案
3-1:解决方案1
设置 stop-writes-on-bgsave-error值为no即可避免这种问题。
// 登录
[root@ecs-25376 root]# redis-cli -h 127.0.0.1 -p 6379
OK
127.0.0.1:6379> config set stop-writes-on-bgsave-error no
3-2:解决方案2
直接修改redis.conf配置文件,修改后需要重启redis。
(1)vim打开redis-server配置的redis.conf文件,
(2)找到stop-writes-on-bgsave-error字符串所在位置,
(3)把后面的yes设置为no。