FPGA高端项目:纯verilog的 UDP 协议栈,提供11套工程源码和技术支持
目录
- 1、前言
-
- 免责声明
- 更新说明
- 2、相关方案推荐
-
- 我这里已有的以太网方案
- 本协议栈的千兆网UDP版本
- 1G 千兆网 TCP-->服务器 方案
- 1G 千兆网 TCP-->客户端 方案
- 10G 万兆网 TCP-->服务器+客户端 方案
- 3、该UDP协议栈性能
- 4、详细设计方案
-
- 设计架构框图
- 网络调试助手
- 网络PHY
- IDELAYE源语
- MAC层
- AXI4-Stream FIFO
- UDP协议栈
- IP地址修改
- UDP数据回环
- 总体代码架构
- 5、工程源码-1 详解
- 6、工程源码-2 详解
- 7、工程源码-3 详解
- 8、工程源码-4 详解
- 9、工程源码-5 详解
- 10、工程源码-6 详解
- 11、工程源码-7 详解
- 12、工程源码-8 详解
- 13、工程源码-9 详解
- 14、工程源码-10 详解
- 15、工程源码-11 详解
- 16、工程移植说明
-
- vivado版本不一致处理
- FPGA型号不一致处理
- 其他注意事项
- 17、上板调试验证并演示
-
- 准备工作
- 查看ARP
- UDP数据回环测试
- 18、福利:工程代码的获取
FPGA高端项目:纯verilog的 UDP 协议栈,提供11套工程源码和技术支持
1、前言
目前网上的fpga实现udp基本生态如下:
1:verilog编写的udp收发器,但中间的FIFO或者RAM等调用了IP,或者不带ping功能,这样的代码功能正常也能用,但不带ping功能基本就是废物,在实际项目中不会用这样的代码,试想,多机互联,出现了问题,你的网卡都不带ping功能,连基本的问题排查机制都不具备,这样的代码谁敢用?
2:带ping功能的udp收发器,代码优秀也好用,但基本不开源,不会提供源码给你,这样的代码也有不足,那就是出了问题不知道怎么排查,毕竟你没有源码,无可奈何;
3:使用了Xilinx的Tri Mode Ethernet MAC三速网IP实现,这样的代码也很优秀,但还是那个问题,没有源码,且三速网IP需要licence,三速网IP实现了rgmii到gmii再到axis的转换;
4:使用FPGA的GTX资源利用SFP光口实现UDP,通信,这种方案不需要外接网络变压器即可完成;
5:真正意义上的verilog实现的UDP协议栈,真正意义上的verilog实现意思是UDP协议栈全部代码均使用verilog代码,不适用任何IP核,包括FIFO、RAM等,这样的UDP协议栈移植性很强,这样的协议栈在市面上也很少,几乎很难得到,而很设计就是这样的协议栈,呵呵。。。
本设计使用纯verilog实现的UDP协议栈实现UDP回环通信测试,之所以只用到了数据回环模式,是因为本设计旨在为用户提供一个可任意移植修改的UDP协议栈架构,用户可通过此架构任意创建自己的项目,自由度和开放性极强;基于市面上主流和占有率较高的FPGA器件,创建了11套工程源码,FPGA器件适用于Xilinx和Altera,开发工具适用于Xilinx的vivado和Altera的Quartus,网络PHY芯片支持MII、GMII、RGMII、SGMII等,11套工程源码详情如下:
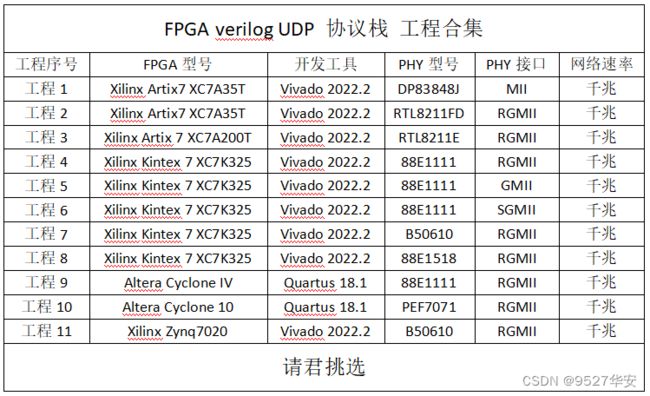
本设计经过反复大量测试稳定可靠,可在项目中直接移植使用,工程代码可综合编译上板调试,可直接项目移植,适用于在校学生、研究生项目开发,也适用于在职工程师做项目开发,可应用于医疗、军工等行业的数字通信领域;
提供完整的、跑通的工程源码和技术支持;
工程源码和技术支持的获取方式放在了文章末尾,请耐心看到最后;
免责声明
本工程及其源码即有自己写的一部分,也有网络公开渠道获取的一部分(包括CSDN、Xilinx官网、Altera官网等等),若大佬们觉得有所冒犯,请私信批评教育;基于此,本工程及其源码仅限于读者或粉丝个人学习和研究,禁止用于商业用途,若由于读者或粉丝自身原因用于商业用途所导致的法律问题,与本博客及博主无关,请谨慎使用。。。
更新说明
这个UDP协议栈是真的好用,忍不住移植了多个平台的FPGA和多种型号的PHY,代码层面并没有更新,但增加了多种移植方案,数据总计多达11个,后续还将继续更新,敬请期待;
2、相关方案推荐
我这里已有的以太网方案
目前我这里有大量UDP协议的工程源码,包括UDP数据回环,视频传输,AD采集传输等,也有TCP协议的工程,对网络通信有需求的兄弟可以去看看:直接点击前往
本协议栈的千兆网UDP版本
本UDP协议栈支持1G、10G、25G速率,本文介绍的是1G速率的应用,之前写过一篇博客介绍本协议栈10G速率的应用,在10G模式下,基于市面上主流和占有率较高的FPGA器件,创建了7套工程源码,FPGA器件适用于Xilinx,开发工具适用于Xilinx的vivado,高速接口资源使用到了GTH、GTY、10G Ethernet PCS/PMA(10GBASE-R/KR)等,对10G UDP网络通信有需求的兄弟可以去看看:
直接点击前往
1G 千兆网 TCP–>服务器 方案
TCP分为服务器和客户端,两者代码是不一样的,看具体需求,既然本博客介绍的是TCP客户端,那么肯定就有TCP服务器,本来TCP服务器之前一直都有,但一直没有调通,经过两年半的练习调试,总算是调通了;TCP服务器依然是4套工程源码,我另外写了一篇博客介绍TCP服务器,感兴趣的朋友可以去看看:直接点击前往
1G 千兆网 TCP–>客户端 方案
TCP分为服务器和客户端,两者代码是不一样的,看具体需求,既然本博客介绍的是TCP服务器,那么肯定就有TCP客户端,本来TCP客户端之前一直都有,但一直没有调通,经过两年半的练习调试,总算是调通了;TCP客户端依然是4套工程源码,我另外写了一篇博客介绍TCP客户端,感兴趣的朋友可以去看看:直接点击前往
10G 万兆网 TCP–>服务器+客户端 方案
我这里也有10G 万兆网 TCP 方案,该方案有服务器和客户端两套代码,在Xilinx KU和KUP等平台测试通过并很稳定,对10G 万兆网 TCP 方案感兴趣的朋友可以去看看:直接点击前往
3、该UDP协议栈性能
1:纯verilog实现,没有用到任何一个IP核;
2:移植性天花板,该协议栈可在Xilinx、Altera等各大FPGA型号之间任意移植,因为是没有任何IP,源语也有参数可选择;
3:适应性强,目前已在RTL8211、B50610、88E1518等多款phy上成功测试,也可以用GT资源的SFP接口实现UDP协议的以太网通信;支持MII、GMII、RGMII、SGMII等PHY接口;
4:时序收敛很到位;
5:动态ARP功能;
6:不带ping功能;
7:MAC层RGMII转GMII后由AXIS接口输出,完全可以替代Xilinx的Tri Mode Ethernet MAC IP核;
8:最高支持25G速率,本设计使用1G;
4、详细设计方案
设计架构框图
详细设计方案如下框图:

这只是一个总体架构,不同的工程可能在框图中并不一致,具体参考代码;
网络调试助手
这只是一个回环测试工具,常用的Win软件,用来测试UDP数据收发;无需多言;
网络PHY
本设计一共设计了11套工程,以适应不同的网络PHY芯片型号以及对应的接口模式,详情如下:
RTL8211E、RTL8211FD:有RGMII接口的工程;
88E1111:有RGMII、GMII、SGMII接口的工程;
88E1518:有RGMII接口的工程;
B50610:有RGMII接口的工程;
PEF7071:有RGMII接口的工程;
DP83848J:有MII接口的工程;
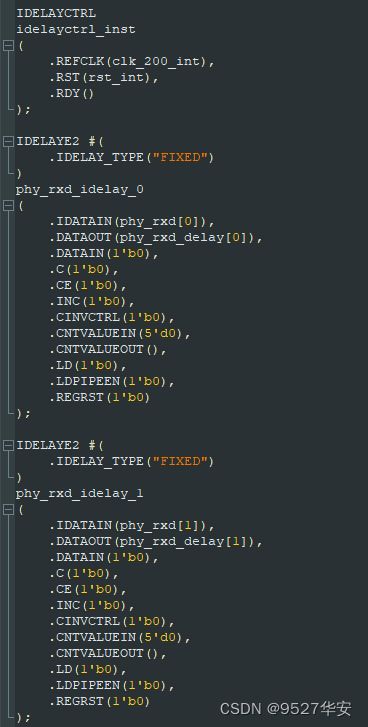
IDELAYE源语
这是Xilinx系列FPGA特有的功能模块,目的是为接收的PHY数据进行延时和对齐,采用了 IDELAYE源语,该源语在不同的FPGA器件上略有差异,本设计中的A7、K7、Zynq用的是IDELAYE2;IDELAYE2源语需要与IDELAYCTRL一起搭配使用,需要参考时钟200M;代码部分如下:例化位置在fpga.v;
MAC层
MAC层由verilog代码实现,没有使用任何IP,但是用到了相关源语,Xilinx系列FPGA为IDDR、ODDR;Altera系列FPGA为
altddio_in、altddio_out;MAC层实现的功能有两个,一是对PHY侧的数据进行处理,接收端为双时钟沿数据解为单时钟沿数据并对齐,发送则相反;二是实现PHY侧和用户侧的数据格式转换并进行CRC8校验,接收端为将PHY侧的并行数据转换为用户侧的AXI4-Stream数据流,发送则相反;代码位置如下:

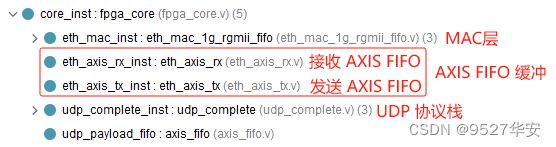
AXI4-Stream FIFO
网络数据经过MAC层以后,输出的是AXI4-Stream数据流,如果直接将数据送入UDP协议栈,有数据冲突的风险,为了降低这种风险,使用纯verilog实现的AXI4-Stream FIFO作为缓冲,在MAC层与UDP协议栈之间建立“桥梁”,MAC层解析出来的例如原MAC地址、目的MAC地址等信息也通过AXI4-Stream FIFO转发;AXI4-Stream FIFO代码位置如下:
UDP协议栈
UDP协议栈的功能就是用verilog硬件描述语言完成标准UDP协议;它由动态ARP层、IP层、UDP层构成,动态ARP层完成ARP协议内容的数据收发,对于接收端来说是数据帧解包,从以太网数据帧中提取ARP数据段的有效数据,对于发送端来说是数据帧组包,将用户端发来的有效数据封装成ARP协议的数据帧,作为以太网数据帧的ARP数据段;代码中设置了ARP动态缓存,即arp_cache,收发两端都进行crc校验;
IP层完成IP协议内容的数据收发,对于接收端来说是数据帧解包,从以太网数据帧中提取IP数据段的有效数据,对于发送端来说是数据帧组包,将用户端发来的有效数据封装成IP协议的数据帧,作为以太网数据帧的IP数据段;IP层与动态ARP层是数据交互的,模块相互包含,代码架构无法明显划分;
UDP层完成UDP协议内容的数据收发,对于接收端来说是数据帧解包,从以太网数据帧中提取UDP数据段的有效数据,对于发送端来说是数据帧组包,将用户端发来的有效数据封装成UDP协议的数据帧,作为以太网数据帧的UDP数据段;IP层与动态ARP层是数据交互的,模块相互包含,代码架构无法明显划分;UDP层会对UDP数据做前后检验;
UDP协议栈架构封装后代码位置如下:

UDP协议栈是直接与用户逻辑数据对接的接口,所以对于FPGAS开发者而言,只要知道了UDP协议栈的数据接口,就能在用户侧编写与之对接的时序来控制数据收发,UDP协议栈的接口时序为AXI4-Stream,时序如下:
发送端时序如下:
__ __ __ __ __ __ __
clk __/ \__/ \__/ \__/ \__/ \__/ \__/ \__
______________ ___________
s_eth_hdr_valid \_________________/
_____
s_eth_hdr_ready ________/ \_____________________________
_____
s_eth_dest_mac XXXXXXXXX_DMAC_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
_____
s_eth_dest_mac XXXXXXXXX_SMAC_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
___________ _____ _____
s_eth_payload_axis_tdata XXXXXXXXX_A0________X_A1__X_A2__XXXXXXXXXXXX
_______________________
s_eth_payload_axis_tvalid ________/ \___________
_________________
s_eth_payload_axis_tready ______________/ \___________
_____
s_eth_payload_axis_tlast __________________________/ \___________
s_eth_payload_axis_tuser ____________________________________________
接收端时序与发送端一样;
IP地址修改
FPGA与PC通信而言,FPGA作为UDP服务器,PC作为UDP客户端,需要在FPGA代码里设置MAC、IP等配置信息,这是UDP通信的重要信息,开发者至少需要知道该部分代码的位置,甚至根据自己的需要修改,代码的位置如下:

可以看到,我这里的配置如下:
FPGA开发板MAC地址:02-00-00-00-00-00;
FPGA开发板IP地址:192.168.1.128;
FPGA开发板网关:192.168.1.1;
FPGA开发板子网掩码:255.255.255.0;
那么PC端的IP地址应该设为多少呢?
因为在回环代码里写成了发送的目的IP=接收到的目的IP,所以只需要在PC端设置与192.168.1.128网段一样的IP地址即可,比如我在测试时设置PC端IP地址为:192.168.1.10;如下:

当然,你也可以配置为192.168.1.11、192.168.1.12、192.168.1.100等等;
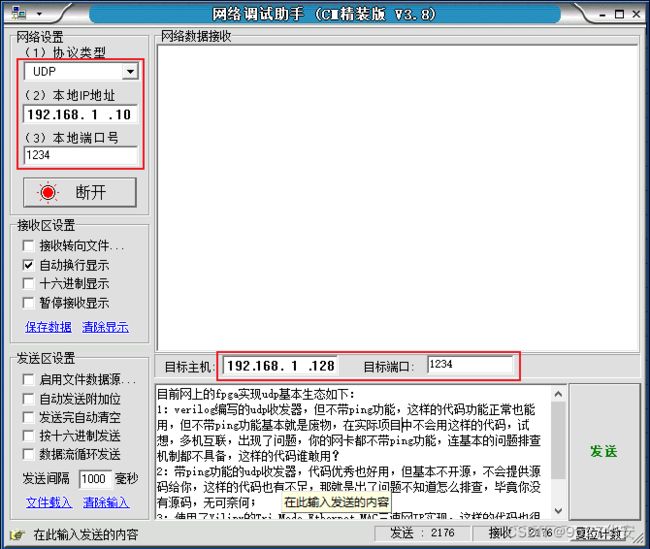
默认的FPGA开发板和PC端的端口号都是1234;代码的位置如下:

这部分代码位于fpga_core.v;
UDP数据回环
之所以只用到了数据回环模式,是因为本设计旨在为用户提供一个可任意一直修改的UDP协议栈架构,用户可通过此架构任意创建自己的项目,自由度和开放性极强;使用一个纯verilog实现的AXI4-Stream FIFO来做数据回环操作,因为UDP协议栈的用户数据接口正是AXI4-Stream数据流,代码的位置如下:
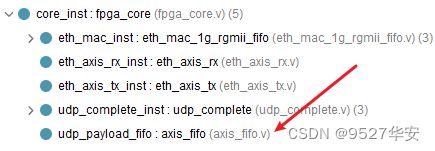
代码里直接用assign语句将AXI4-Stream FIFO的收发两端连接,如下:
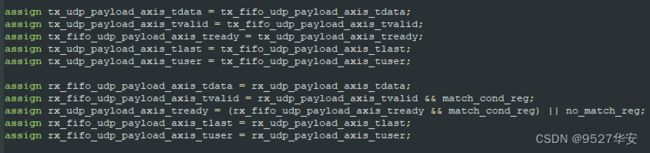
AXI4-Stream FIFO配置为了8192,如果你的FPGA逻辑资源较小,配置为1024就可以了;
这部分代码位于fpga_core.v;
总体代码架构
以XilinxFPGA的RGMII接口工程为例,代码架构如下:

不同的工程与代码架构对应时可能略有差异,但总体而言差不多,具体工程要看具体代码;
5、工程源码-1 详解
开发板FPGA型号:Xilinx Artix7 XC7A35T–xc7a35ticsg324-1L;
开发环境:Vivado 2022.2;
网络PHY:DP83848J,MII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
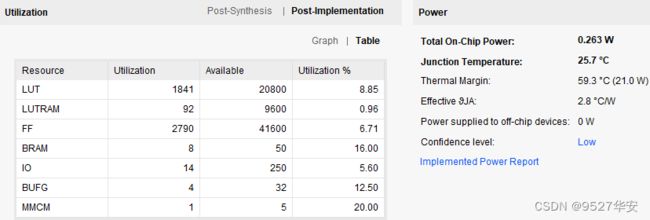
FPGA资源消耗和功耗预估如下;

6、工程源码-2 详解
开发板FPGA型号:Xilinx Artix7 XC7A35T–xc7a35tfgg484-2;
开发环境:Vivado 2022.2;
网络PHY:RTL8211FD,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
FPGA资源消耗和功耗预估如下;
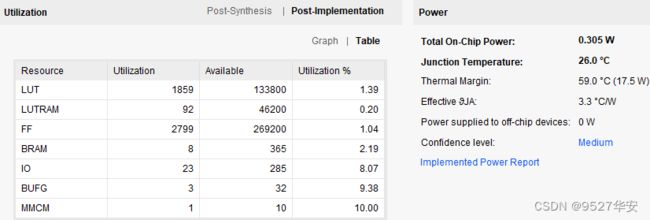
7、工程源码-3 详解
开发板FPGA型号:Xilinx Artix 7 XC7A200T–xc7a200tsbg484-1;
开发环境:Vivado 2022.2;
网络PHY:RTL8211E,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
FPGA资源消耗和功耗预估如下;
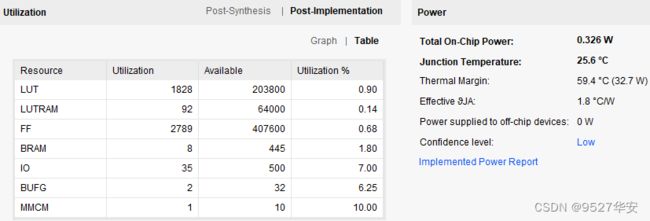
8、工程源码-4 详解
开发板FPGA型号:Xilinx Kintex 7 XC7K325–xc7k325tffg900-2;
开发环境:Vivado 2022.2;
网络PHY:88E1111,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
FPGA资源消耗和功耗预估如下;

9、工程源码-5 详解
开发板FPGA型号:Xilinx Kintex 7 XC7K325–xc7k325tffg900-2;
开发环境:Vivado 2022.2;
网络PHY:88E1111,GMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
FPGA资源消耗和功耗预估如下;
10、工程源码-6 详解
开发板FPGA型号:Xilinx Kintex 7 XC7K325–xc7k325tffg900-2;
开发环境:Vivado 2022.2;
网络PHY:88E1111,SGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
88E1111在SGMII接口模式下,已经不需要我们前面讲过的MAC层了,而是直接调用Xilinx官方的1G/2.5G Ethernet PCS/PMA or SGMII IP核当做MAC,该IP需要去Xilinx官网申请Licence才能使用,在1G线速率模式下对GTX的参考时钟固定位125M,IP配置如下:
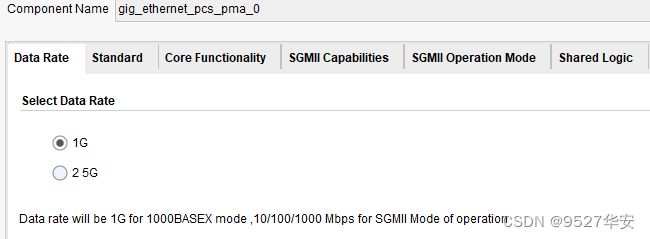

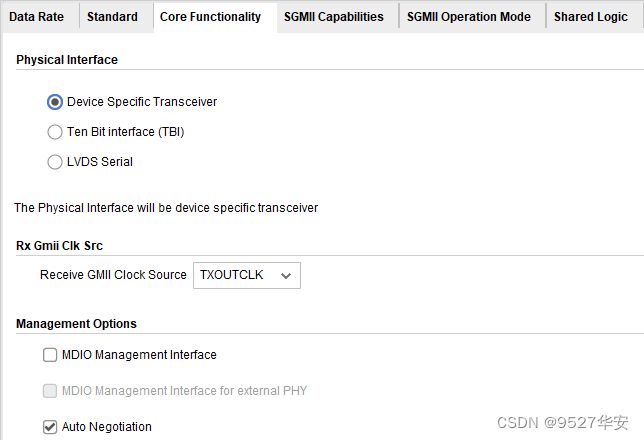
工程代码架构如下:可以参考第4章节的“总体代码架构”小节作比较;

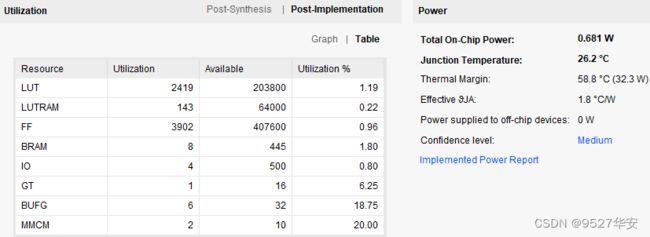
FPGA资源消耗和功耗预估如下;
11、工程源码-7 详解
开发板FPGA型号:Xilinx Kintex 7 XC7K325–xc7k325tffg676-2;
开发环境:Vivado 2022.2;
网络PHY:B50610,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
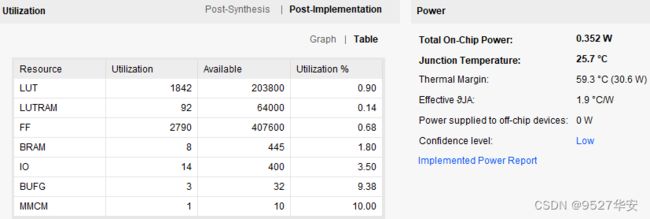
FPGA资源消耗和功耗预估如下;
12、工程源码-8 详解
开发板FPGA型号:Xilinx Kintex 7 XC7K325–xc7k325tffg676-2;
开发环境:Vivado 2022.2;
网络PHY:88E1518,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
FPGA资源消耗和功耗预估如下;
13、工程源码-9 详解
开发板FPGA型号:Altera Cyclone IV–EP4CE115F29C7;
开发环境:Quartus 18.1;
网络PHY:88E1111,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构如下:
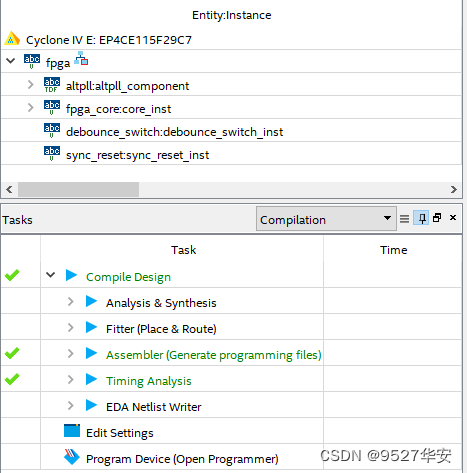
FPGA资源消耗和功耗预估如下;

14、工程源码-10 详解
开发板FPGA型号:Altera Cyclone 10–5SGXEA7N2F45C2;
开发环境:Quartus 18.1;
网络PHY:PEF7071,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
需要注意的是,Quartus 18.1标准版本不支持Cyclone 10器件,需要到Altera官网下载Cyclone 10的器件库,并在Quartus 18.1中安装库文件,然后重启Quartus 18.1后才能使用;
工程代码架构如下:
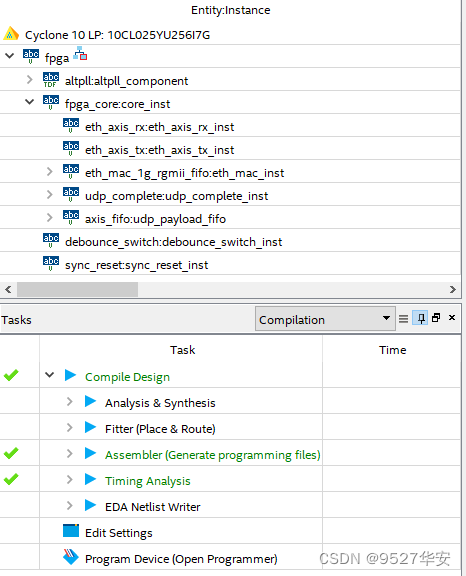
FPGA资源消耗和功耗预估如下;
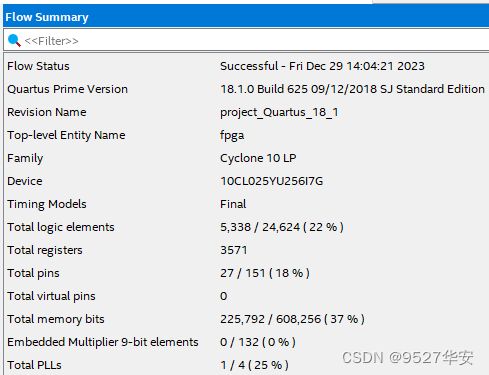
15、工程源码-11 详解
开发板FPGA型号:Xilinx Zynq7020–xc7z020clg400-2;
开发环境:Vivado 2022.2;
网络PHY:B50610,RGMII接口,千兆网;
输入\输出:UDP 网络通信;
测试项:数据回环收发;
工程代码架构参考第4章节的“总体代码架构”小节;
FPGA资源消耗和功耗预估如下;
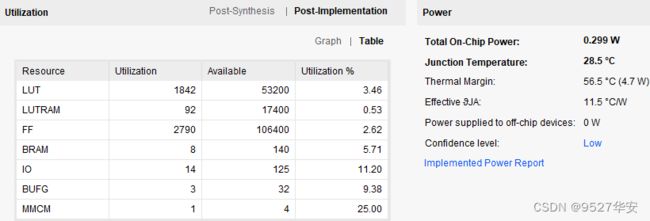
16、工程移植说明
vivado版本不一致处理
1:如果你的vivado版本与本工程vivado版本一致,则直接打开工程;
2:如果你的vivado版本低于本工程vivado版本,则需要打开工程后,点击文件–>另存为;但此方法并不保险,最保险的方法是将你的vivado版本升级到本工程vivado的版本或者更高版本;
3:如果你的vivado版本高于本工程vivado版本,解决如下:

打开工程后会发现IP都被锁住了,如下:

此时需要升级IP,操作如下:


FPGA型号不一致处理
如果你的FPGA型号与我的不一致,则需要更改FPGA型号,操作如下:



更改FPGA型号后还需要升级IP,升级IP的方法前面已经讲述了;
其他注意事项
1:由于每个板子的DDR不一定完全一样,所以MIG IP需要根据你自己的原理图进行配置,甚至可以直接删掉我这里原工程的MIG并重新添加IP,重新配置;
2:根据你自己的原理图修改引脚约束,在xdc文件中修改即可;
3:纯FPGA移植到Zynq需要在工程中添加zynq软核;
17、上板调试验证并演示
准备工作
需要准备以下物品:
1:FPGA开发板;
2:网线;
3:上位机电脑,台式或笔记本;
4:网络调试助手;
以vivado工程7为例进行上板调试;
连接如下,然后上电下载bit:
首先设置电脑端IP如下:

开发板的IP地址在代码中的设置如下,在fpga_core.v里,可以自由修改:
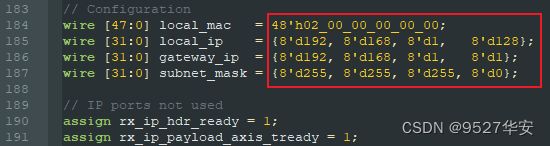
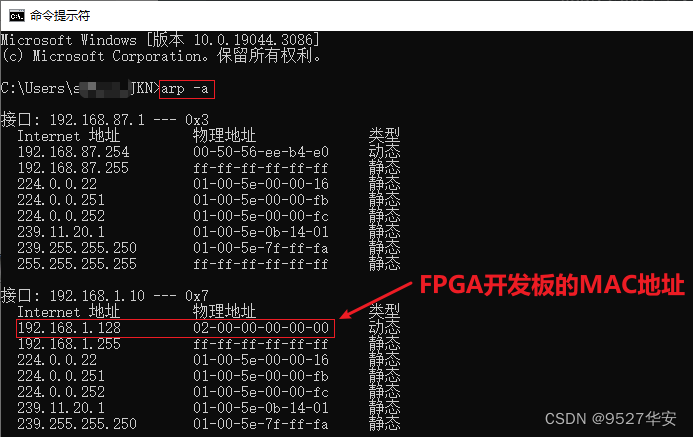
查看ARP
打开cmd,输入 arp -a查看电脑的arp缓存表,如下:
UDP数据回环测试
打开网络调试助手并配置,如下:
单次发送数据测试结果如下:

循环发送数据测试结果如下,1秒时间间隔循环:

18、福利:工程代码的获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料获取方式:私,或者文章末尾的V名片。
网盘资料如下:

Xilinx系列FPGA工程文件夹如下:

Altera系列FPGA工程文件夹如下:
