Hadoop集群环境下HDFS实践编程过滤出所有后缀名不为“.abc”的文件时运行报错:Path is not a file: /user/hadoop/input
一、问题描述
搭建完Hadoop集群后,在Hadoop集群环境下运行HDFS实践编程使用Eclipse开发调试HDFS Java程序(文末有源码):
假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,这里需要从该目录中过滤出所有后缀名不为“.abc”的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件“hdfs://localhost:9000/user/hadoop/merge.txt”中。
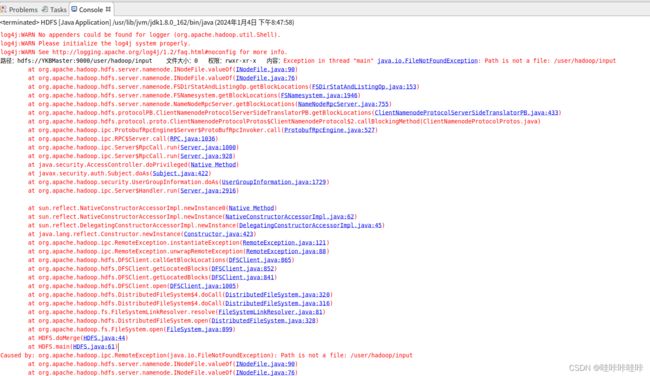
在执行上述任务时,运行代码后报错:
Exception in thread "main" java.io.FileNotFoundException: Path is not a file: /user/hadoop/input
二、解决办法
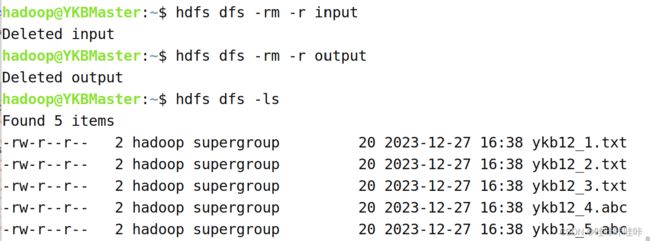
将HDFS上/user/hadoop目录下(即你所想要过滤的文件所在目录,此处是在/user/hadoop目录下)的目录式文件删除
查看HDFS家目录下的内容:
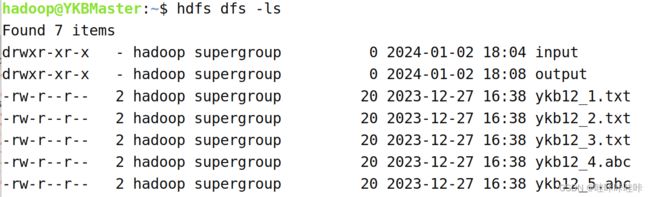
删除HDFS上的input目录和output目录(根据自己实际代码所检索的目录,此处是在HDFS上的家目录即/user/hadoop目录下进行删除):
删除完成后再次运行程序即可成功运行:
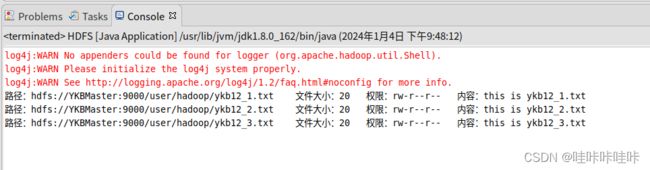
至此,问题解决!!!
三、问题分析及可能出现的问题
1.问题分析
出现 "Exception in thread "main" java.io.FileNotFoundException: Path is not a file: /user/hadoop/input" 错误是因为您指定的输入路径 "/user/hadoop/input" 不是一个文件,而是一个目录。
在代码中使用 fsSource.listStatus(inputPath, new MyPathFilter(".*\\.abc")); 获取了输入目录中所有后缀为 ".abc" 的文件,然后尝试打开每个文件并将其内容写入输出文件。但是,传递给 listStatus() 方法的 inputPath 是一个目录,而不是一个文件。
要解决这个问题,需要将 inputPath 更改为指向一个具体的文件路径,而不是目录路径。请确保您的输入路径是一个文件路径,或者根据您的需求更改代码来处理目录中的所有文件或者删除指定输入路径中的目录式文件。
在此处,我所选择的是最简单粗暴的删除指定输入路径中的目录式文件这一方式。
2.可能出现的问题
若出现“java.net.ConnectException: 拒绝连接;”的问题可参考:
https://blog.csdn.net/qq_67822268/article/details/135396537 https://blog.csdn.net/qq_67822268/article/details/135396537
https://blog.csdn.net/qq_67822268/article/details/135396537
四、源码
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
/**
* 过滤掉文件名满足特定条件的文件
*/
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
/***
* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件
*/
public class MergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
//下面过滤掉输入目录中后缀为.abc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath,
new MyPathFilter(".*\\.abc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (FileStatus sta : sourceStatus) {
//下面打印后缀不为.abc的文件的路径、文件大小
System.out.print("路径:" + sta.getPath() + " 文件大小:" + sta.getLen()
+ " 权限:" + sta.getPermission() + " 内容:");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile(
"hdfs://localhost:9000/user/hadoop/",
"hdfs://localhost:9000/user/hadoop/merge.txt");
merge.doMerge();
}
}