Spark内核解析-节点启动4(六)
1、Master节点启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作
1.1脚本概览
下面是一个举例:
/opt/jdk1.7.0_79/bin/java
-cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/
-Xmx1g
-XX:MaxPermSize=256m
org.apache.spark.deploy.master.Master
--host zqh
--port 7077
1.2启动流程
Master的启动流程如下:
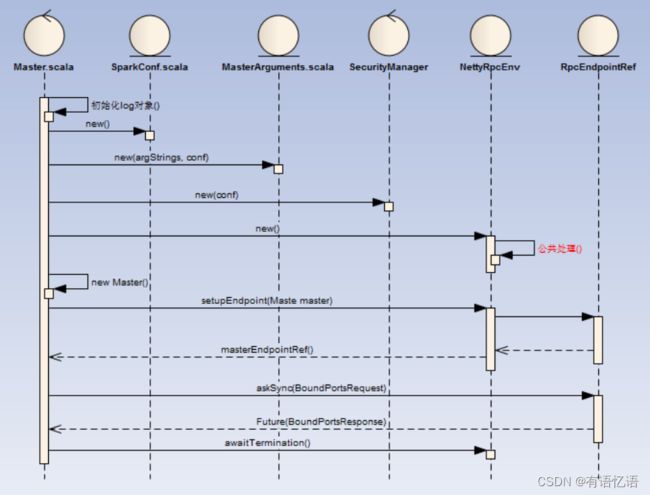
1)SparkConf:加载key以spark.开头的系统属性(Utils.getSystemProperties)
2)MasterArguments:
a)解析Master启动的参数(–ip -i --host -h --port -p --webui-port --properties-file)
b)将–properties-file(没有配置默认为conf/spark-defaults.conf)中spark.开头的配置存入SparkConf
3)NettyRpcEnv中的内部处理遵循RpcEndpoint统一处理,这里不再赘述
4)BoundPortsResponse返回rpcEndpointPort,webUIPort,restPort真实端口
5)最终守护进程会一直存在等待结束信awaitTermination
4.3OnStart监听事件
Master的启动完成后异步执行工作如下:
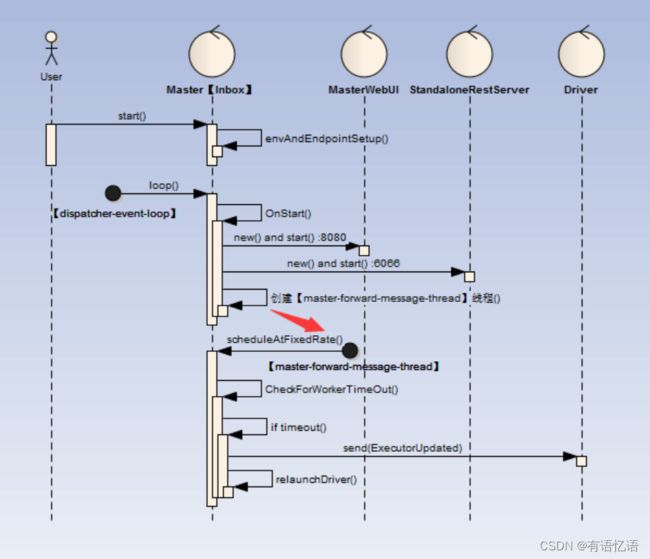
1)【dispatcher-event-loop】线程扫描到OnStart指令后会启动相关MasterWebUI(默认端口8080),根据配置选择安装ResetServer(默认端口6066)
2)另外新起【master-forward-message-thread】线程定期进行worker心跳是否超时
3)如果Worker心跳检测超时,那么对Worker下的发布的所有任务所属Driver进行ExecutorUpdated发送,同时自己在重新LaunchDriver
4.4RpcMessage处理(receiveAndReply)

OneWayMessage处理(receive)


4.5Master对RpcMessage/OneWayMessage处理逻辑
这部分对整体Master理解作用不是很大且理解比较抽象,可以先读后续内容,回头再考虑看这部分内容,或者不读

2、Work节点启动
Worker作为Endpoint的具体实例,下面我们介绍一下Worker启动以及OnStart指令后的额外工作
2.1脚本概览
/opt/jdk1.7.0_79/bin/java
-cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/
-Xmx1g
-XX:MaxPermSize=256m
org.apache.spark.deploy.worker.Worker
--webui-port 8081
spark://master01:7077
2.2启动流程
Worker的启动流程如下:

1)SparkConf:加载key以spark.开头的系统属性(Utils.getSystemProperties)
2)WorkerArguments:
a)解析Master启动的参数(–ip -i --host -h --port -p --cores -c --memory -m --work-dir --webui-port --properties-file)
b)将–properties-file(没有配置默认为conf/spark-defaults.conf)中spark.开头的配置存入SparkConf
c)在没有配置情况下,cores默认为服务器CPU核数
d)在没有配置情况下,memory默认为服务器内存减1G,如果低于1G取1G
e)webUiPort默认为8081
3)NettyRpcEnv中的内部处理遵循RpcEndpoint统一处理,这里不再赘述
4)最终守护进程会一直存在等待结束信awaitTermination
2.3OnStart监听事件
Worker的启动完成后异步执行工作如下
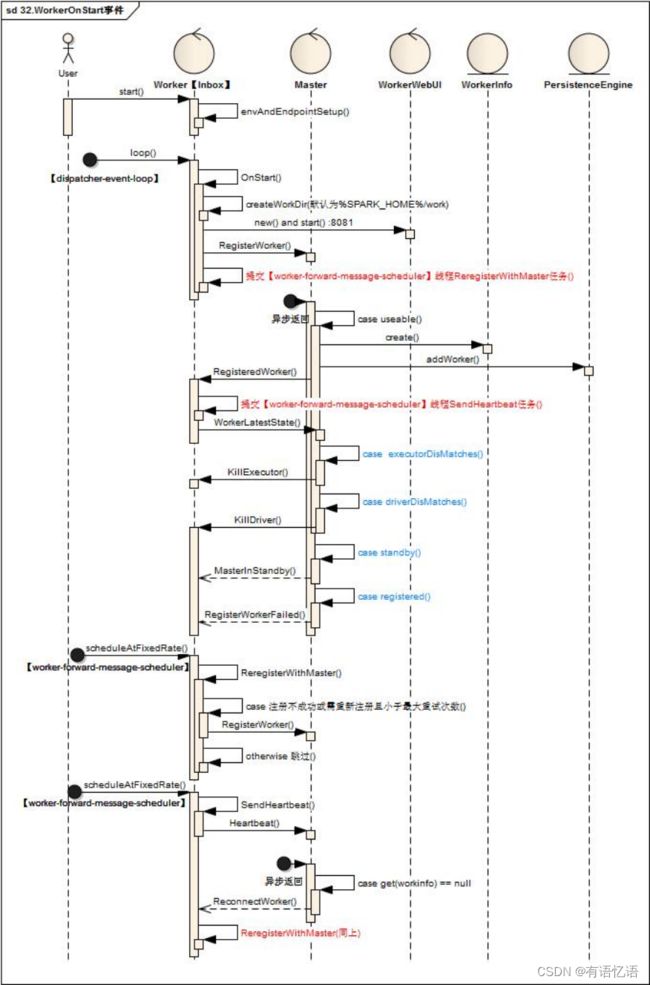
1)【dispatcher-event-loop】线程扫描到OnStart指令后会启动相关WorkerWebUI(默认端口8081)
2)Worker向Master发起一次RegisterWorker指令
3)另起【master-forward-message-thread】线程定期执行ReregisterWithMaster任务,如果注册成功(RegisteredWorker)则跳过,否则再次向Master发起RegisterWorker指令,直到超过最大次数报错(默认16次)
4)Master如果可以注册,则维护对应的WorkerInfo对象并持久化,完成后向Worker发起一条RegisteredWorker指令,如果Master为standby状态,则向Worker发起一条MasterInStandby指令
5)Worker接受RegisteredWorker后,提交【master-forward-message-thread】线程定期执行SendHeartbeat任务,,完成后向Worker发起一条WorkerLatestState指令
6)Worker发心跳检测,会触发更新Master对应WorkerInfo对象,如果Master检测到异常,则发起ReconnectWorker指令至Worker,Worker则再次执行ReregisterWithMaster工作
2.4RpcMessage处理(receiveAndReply)

2.5OneWayMessage处理(receive)
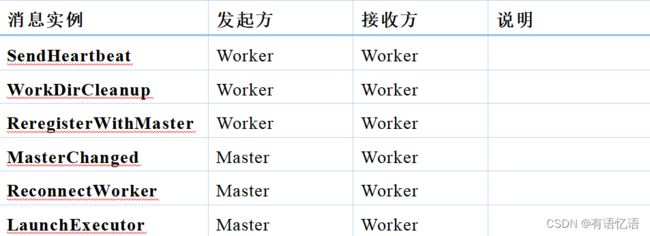

3、Client启动流程
Client作为Endpoint的具体实例,下面我们介绍一下Client启动以及OnStart指令后的额外工作
3.1脚本概览
下面是一个举例:
/opt/jdk1.7.0_79/bin/java
-cp /opt/spark-2.1.0/conf/:/opt/spark-2.1.0/jars/*:/opt/hadoop-2.6.4/etc/hadoop/
-Xmx1g
-XX:MaxPermSize=256m
org.apache.spark.deploy.SparkSubmit
--master spark://zqh:7077
--class org.apache.spark.examples.SparkPi
../examples/jars/spark-examples_2.11-2.1.0.jar 10
3.2SparkSubmit启动流程
SparkSubmit的启动流程如下:

1)SparkSubmitArguments:
a)解析Client启动的参数
i.–name --master --class --deploy-mode
ii.–num-executors --executor-cores --total-executor-cores --executor-memory
iii.–driver-memory --driver-cores --driver-class-path --driver-java-options --driver-library-path
iv.–properties-file
v.–kill --status --supervise --queue
vi.–files --py-files
vii.–archives --jars --packages --exclude-packages --repositories
viii.–conf(解析存入Map : sparkProperties中)
ix.–proxy-user --principal --keytab --help --verbose --version --usage-error
b)合并–properties-file(没有配置默认为conf/spark-defaults.conf)文件配置项(不在–conf中的配置 )至sparkProperties
c)删除sparkProperties中不以spark.开头的配置项目
d)启动参数为空的配置项从sparkProperties中合并
e)根据action(SUBMIT,KILL,REQUEST_STATUS)校验各自必须参数是否有值
2)Case Submit:
a)获取childMainClass
i.[–deploy-mode] = clent(默认):用户任务启动类mainClass(–class)
ii.[–deploy-mode] = cluster & [–master] = spark:* & useRest:org.apache.spark.deploy.rest.RestSubmissionClient
iii.[–deploy-mode] = cluster & [–master] = spark:* & !useRest : org.apache.spark.deploy.Client
iv.[–deploy-mode] = cluster & [–master] = yarn: org.apache.spark.deploy.yarn.Client
v.[–deploy-mode] = cluster & [–master] = mesos:*: org.apache.spark.deploy.rest.RestSubmissionClient
b)获取childArgs(子运行时对应命令行组装参数)
i.[–deploy-mode] = cluster & [–master] = spark:* & useRest: 包含primaryResource与mainClass
ii.[–deploy-mode] = cluster & [–master] = spark:* & !useRest : 包含–supervise --memory --cores launch 【childArgs】, primaryResource, mainClass
iii.[–deploy-mode] = cluster & [–master] = yarn:–class --arg --jar/–primary-py-file/–primary-r-file
iv.[–deploy-mode] = cluster & [–master] = mesos:*: primaryResource
c)获取childClasspath
i.[–deploy-mode] = clent:读取–jars配置,与primaryResource信息(…/examples/jars/spark-examples_2.11-2.1.0.jar)
d)获取sysProps
i.将sparkPropertie中的所有配置封装成新的sysProps对象,另外还增加了一下额外的配置项目
e)将childClasspath通过当前的类加载器加载中
f)将sysProps设置到当前jvm环境中
g)最终反射执行childMainClass,传参为childArgs
3.3Client启动流程
Client的启动流程如下:
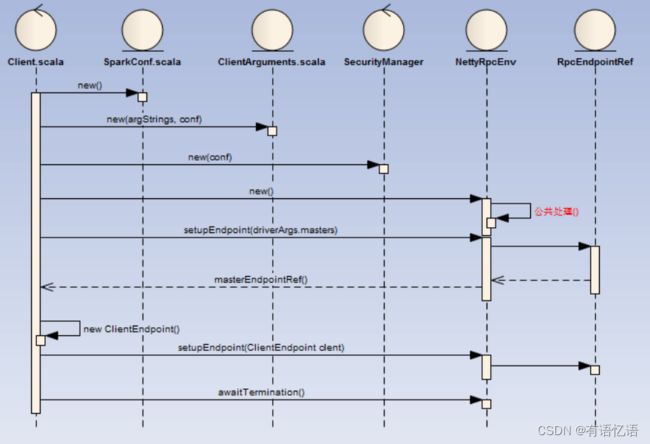
1)SparkConf:加载key以spark.开头的系统属性(Utils.getSystemProperties)
2)ClientArguments:
a)解析Client启动的参数
i.–cores -c --memory -m --supervise -s --verbose -v
ii.launch jarUrl master mainClass
iii.kill master driverId
b)将–properties-file(没有配置默认为conf/spark-defaults.conf)中spark.开头的配置存入SparkConf
c)在没有配置情况下,cores默认为1核
d)在没有配置情况下,memory默认为1G
e)NettyRpcEnv中的内部处理遵循RpcEndpoint统一处理,这里不再赘述
3)最终守护进程会一直存在等待结束信awaitTermination
3.4Client的OnStart监听事件
Client的启动完成后异步执行工作如下:

1)如果是发布任务(case launch),Client创建一个DriverDescription,并向Master发起RequestSubmitDriver请求

a)Command中的mainClass为: org.apache.spark.deploy.worker.DriverWrapper
b)Command中的arguments为: Seq(“{{WORKER_URL}}”, “{{USER_JAR}}”, driverArgs.mainClass)
2)Master接受RequestSubmitDriver请求后,将DriverDescription封装为一个DriverInfo,
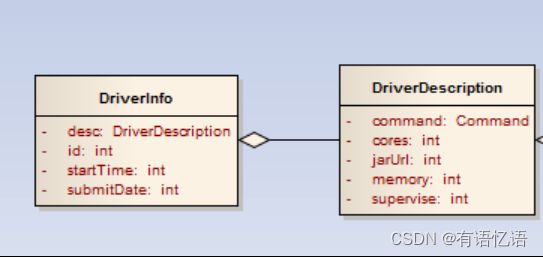
a)startTime与submitDate都为当前时间
b)driverId格式为:driver-yyyyMMddHHmmss-nextId,nextId是全局唯一的
3)Master持久化DriverInfo,并加入待调度列表中(waitingDrivers),触发公共资源调度逻辑。
4)Master公共资源调度结束后,返回SubmitDriverResponse给Client
3.5RpcMessage处理(receiveAndReply)
3.6OneWayMessage处理(receive)

4、Driver和DriverRunner
Client向Master发起RequestSubmitDriver请求,Master将DriverInfo添加待调度列表中(waitingDrivers),下面针对于Driver进一步梳理
4.1Master对Driver资源分配
大致流程如下:

waitingDrivers与aliveWorkers进行资源匹配,
1)在waitingDrivers循环内,轮询所有aliveWorker
2)如果aliveWorker满足当前waitingDriver资源要求,给Worker发送LaunchDriver指令并将 waitingDriver移除waitingDrivers,则进行下一次waitingDriver的轮询工作
3)如果轮询完所有aliveWorker都不满足waitingDriver资源要求,则进行下一次waitingDriver的轮询工作
4)所有发起的轮询开始点都上次轮询结束点的下一个点位开始
4.2Worker运行DriverRunner
Driver的启动,流程如下:
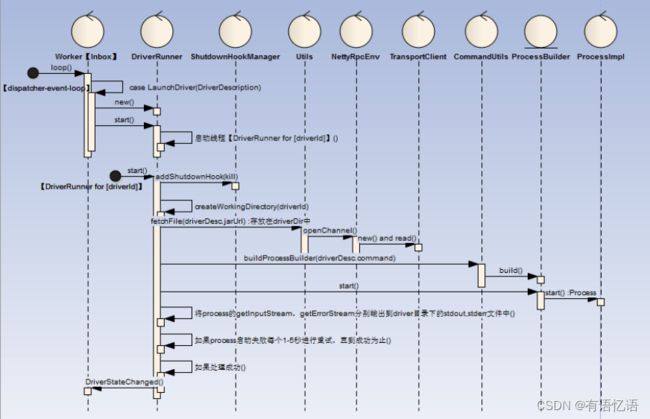
1)当Worker遇到LaunchDriver指令时,创建并启动一个DriverRunner
2)DriverRunner启动一个线程【DriverRunner for [driverId]】处理Driver启动工作
3)【DriverRunner for [driverId]】:
a)添加JVM钩子,针对于每个diriverId创建一个临时目录
b)将DriverDesc.jarUrl通过Netty从Driver机器远程拷贝过来
c)根据DriverDesc.command模板构建本地执行的command命令,并启动该command对应的Process进程
d)将Process的输出流输出到文件stdout/stderror,如果Process启动失败,进行1-5的秒的反复启动工作,直到启动成功,在释放Worker节点的DriverRunner的资源
4.3DriverRunner创建并运行DriverWrapper
DriverWrapper的运行,流程如下:

1)DriverWapper创建了一个RpcEndpoint与RpcEnv
2)RpcEndpoint为WorkerWatcher,主要目的为监控Worker节点是否正常,如果出现异常就直接退出
3)然后当前的ClassLoader加载userJar,同时执行userMainClass
4)执行用户的main方法后关闭workerWatcher
5、SparkContext解析
5.1SparkContext解析
SparkContext是用户通往Spark集群的唯一入口,任何需要使用Spark的地方都需要先创建SparkContext,那么SparkContext做了什么?
首先SparkContext是在Driver程序里面启动的,可以看做Driver程序和Spark集群的一个连接,SparkContext在初始化的时候,创建了很多对象:

上图列出了SparkContext在初始化创建的时候的一些主要组件的构建。
5.2SparkContext创建过程
创建过程如下

SparkContext在新建时
1)内部创建一个SparkEnv,SparkEnv内部创建一个RpcEnv
a)RpcEnv内部创建并注册一个MapOutputTrackerMasterEndpoint(该Endpoint暂不介绍)
2)接着创建DAGScheduler,TaskSchedulerImpl,SchedulerBackend
a)TaskSchedulerImpl创建时创建SchedulableBuilder,SchedulableBuilder根据类型分为FIFOSchedulableBuilder,FairSchedulableBuilder两类
3)最后启动TaskSchedulerImpl,TaskSchedulerImpl启动SchedulerBackend
a)SchedulerBackend启动时创建ApplicationDescription,DriverEndpoint, StandloneAppClient
b)StandloneAppClient内部包括一个ClientEndpoint
5.3SparkContext简易结构与交互关系
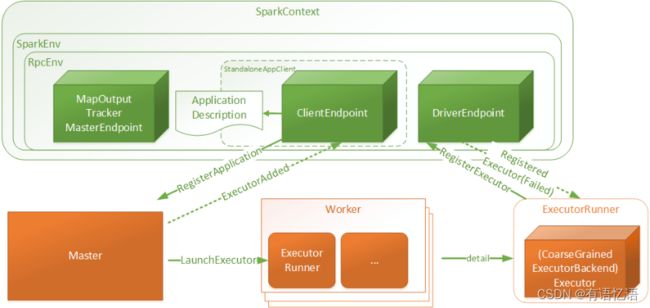
1)SparkContext:是用户Spark执行任务的上下文,用户程序内部使用Spark提供的Api直接或间接创建一个SparkContext
2)SparkEnv:用户执行的环境信息,包括通信相关的端点
3)RpcEnv:SparkContext中远程通信环境
4)ApplicationDescription:应用程序描述信息,主要包含appName, maxCores, memoryPerExecutorMB, coresPerExecutor, Command(
CoarseGrainedExecutorBackend), appUiUrl等
5)ClientEndpoint:客户端端点,启动后向Master发起注册RegisterApplication请求
6)Master:接受RegisterApplication请求后,进行Worker资源分配,并向分配的资源发起LaunchExecutor指令
7)Worker:接受LaunchExecutor指令后,运行ExecutorRunner
8)ExecutorRunner:运行applicationDescription的Command命令,最终Executor,同时向DriverEndpoint注册Executor信息
5.4Master对Application资源分配
当Master接受Driver的RegisterApplication请求后,放入waitingDrivers队列中,在同一调度中进行资源分配,分配过程如下:
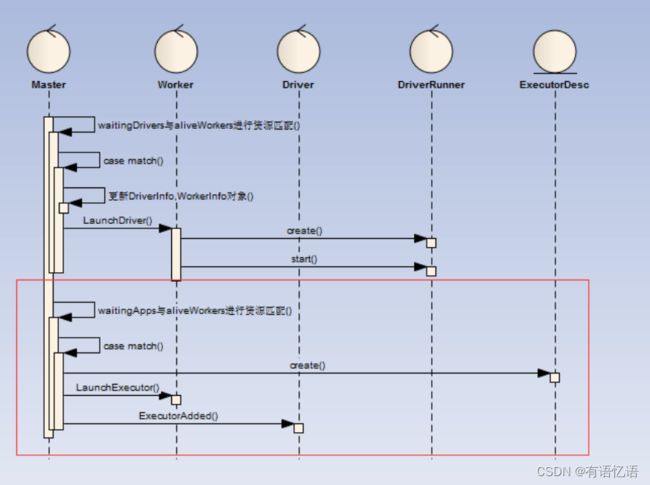
waitingApps与aliveWorkers进行资源匹配
1)如果waitingApp配置了app.desc.coresPerExecutor:
a)轮询所有有效可分配的worker,每次分配一个executor,executor的核数为minCoresPerExecutor(app.desc.coresPerExecutor),直到不存在有效可分配资源或者app依赖的资源已全部被分配
2)如果waitingApp没有配置app.desc.coresPerExecutor:
a)轮询所有有效可分配的worker,每个worker分配一个executor,executor的核数为从minCoresPerExecutor(为固定值1)开始递增,直到不存在有效可分配资源或者app依赖的资源已全部被分配
3)其中有效可分配worker定义为满足一次资源分配的worker:
a)cores满足:usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor,
b)memory满足(如果是新的Executor):usableWorkers(pos).memoryFree - assignedExecutors(pos) * memoryPerExecutor >= memoryPerExecutor
注意:Master针对于applicationInfo进行资源分配时,只有存在有效可用的资源就直接分配,而分配剩余的app.coresLeft则等下一次再进行分配
5.5Worker创建Executor

(图解:橙色组件是Endpoint组件)
Worker启动Executor
1)在Worker的tempDir下面创建application以及executor的目录,并chmod700操作权限
2)创建并启动ExecutorRunner进行Executor的创建
3)向master发送Executor的状态情况
ExecutorRnner
1)新线程【ExecutorRunner for [executorId]】读取ApplicationDescription将其中Command转化为本地的Command命令
2)调用Command并将日志输出至executor目录下的stdout,stderr日志文件中,Command对应的java类为CoarseGrainedExecutorBackend
CoarseGrainedExecutorBackend
1)创建一个SparkEnv,创建ExecutorEndpoint(CoarseGrainedExecutorBackend),以及WorkerWatcher
2)ExecutorEndpoint创建并启动后,向DriverEndpoint发送RegisterExecutor请求并等待返回
3)DriverEndpoint处理RegisterExecutor请求,返回ExecutorEndpointRegister的结果
4)如果注册成功,ExecutorEndpoint内部再创建Executor的处理对象
至此,Spark运行任务的容器框架就搭建完成。
6、Job提交和Task的拆分
在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用户任务类(或者任务代码)进行分析
6.1整体预览
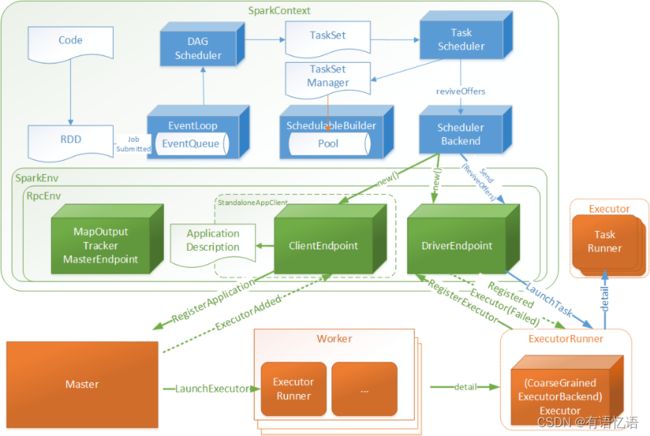
1)Code:指的用户编写的代码
2)RDD:弹性分布式数据集,用户编码根据SparkContext与RDD的api能够很好的将Code转化为RDD数据结构(下文将做转化细节介绍)
3)DAGScheduler:有向无环图调度器,将RDD封装为JobSubmitted对象存入EventLoop(实现类DAGSchedulerEventProcessLoop)队列中
4)EventLoop: 定时扫描未处理JobSubmitted对象,将JobSubmitted对象提交给DAGScheduler
5)DAGScheduler:针对于JobSubmitted进行处理,最终将RDD转化为执行TaskSet,并将TaskSet提交至TaskScheduler
6)TaskScheduler: 根据TaskSet创建TaskSetManager对象存入SchedulableBuilder的数据池(Pool)中,并调用DriverEndpoint唤起消费(ReviveOffers)操作
7)DriverEndpoint:接受ReviveOffers指令后将TaskSet中的Tasks根据相关规则均匀分配给Executor
8)Executor:启动一个TaskRunner执行一个Task
6.2Code转化为初始RDDs
我们的用户代码通过调用Spark的Api(比如:SparkSession.builder.appName(“Spark Pi”).getOrCreate()),该Api会创建Spark的上下文(SparkContext),当我们调用transform类方法 (如:parallelize(),map())都会创建(或者装饰已有的) Spark数据结构(RDD), 如果是action类操作(如:reduce()),那么将最后封装的RDD作为一次Job提交,存入待调度队列中(DAGSchedulerEventProcessLoop )待后续异步处理。
如果多次调用action类操作,那么封装的多个RDD作为多个Job提交。
流程如下:
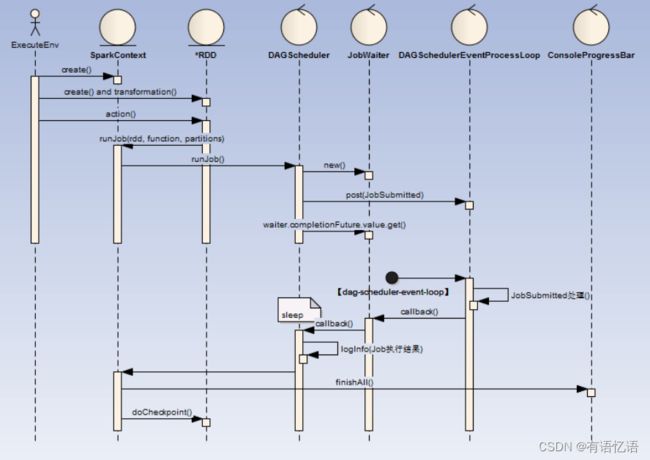
ExecuteEnv(执行环境 )
1)这里可以是通过spark-submit提交的MainClass,也可以是spark-shell脚本
2)MainClass : 代码中必定会创建或者获取一个SparkContext
3)spark-shell:默认会创建一个SparkContext
RDD(弹性分布式数据集)
1)create:可以直接创建(如:sc.parallelize(1 until n, slices) ),也可以在其他地方读取(如:sc.textFile(“README.md”))等
2)transformation:rdd提供了一组api可以进行对已有RDD进行反复封装成为新的RDD,这里采用的是装饰者设计模式,下面为部分装饰器类图

3)action:当调用RDD的action类操作方法时(collect、reduce、lookup、save ),这触发DAGScheduler的Job提交
4)DAGScheduler:创建一个名为JobSubmitted的消息至DAGSchedulerEventProcessLoop阻塞消息队列(LinkedBlockingDeque)中
5)DAGSchedulerEventProcessLoop:启动名为【dag-scheduler-event-loop】的线程实时消费消息队列
6)【dag-scheduler-event-loop】处理完成后回调JobWaiter
7)DAGScheduler:打印Job执行结果
8)JobSubmitted:相关代码如下(其中jobId为DAGScheduler全局递增Id):
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))

最终转化的RDD分为四层,每层都依赖于上层RDD,将ShffleRDD封装为一个Job存入DAGSchedulerEventProcessLoop待处理,如果我们的代码中存在几段上面示例代码,那么就会创建对应对的几个ShffleRDD分别存入DAGSchedulerEventProcessLoop
6.3RDD分解为待执行任务集合(TaskSet)
Job提交后,DAGScheduler根据RDD层次关系解析为对应的Stages,同时维护Job与Stage的关系。
将最上层的Stage根据并发关系(findMissingPartitions )分解为多个Task,将这个多个Task封装为TaskSet提交给TaskScheduler。非最上层的Stage的存入处理的列表中(waitingStages += stage)
流程如下:
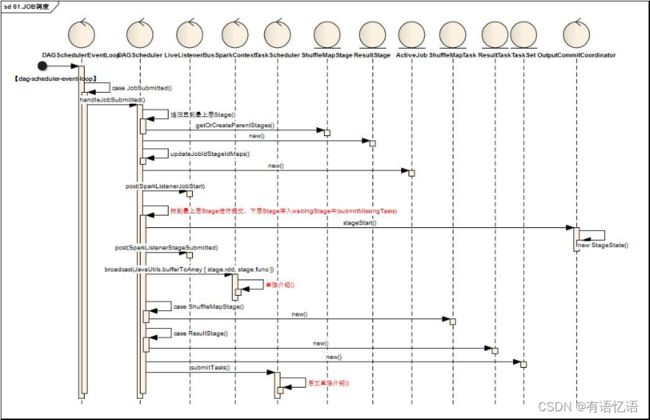
1)DAGSchedulerEventProcessLoop中,线程【dag-scheduler-event-loop】处理到JobSubmitted
2)调用DAGScheduler进行handleJobSubmitted
a)首先根据RDD依赖关系依次创建Stage族,Stage分为ShuffleMapStage,ResultStage两类

b)更新jobId与StageId关系Map
c)创建ActiveJob,调用LiveListenerBug,发送SparkListenerJobStart指令
d)找到最上层Stage进行提交,下层Stage存入waitingStage中待后续处理
i.调用OutputCommitCoordinator进行stageStart()处理
ii.调用LiveListenerBug, 发送 SparkListenerStageSubmitted指令
调用SparkContext的broadcast方法获取Broadcast对象

根据Stage类型创建对应多个Task,一个Stage根据findMissingPartitions分为多个对应的Task,Task分为ShuffleMapTask,ResultTask
iv.将Task封装为TaskSet,调用TaskScheduler.submitTasks(taskSet)进行Task调度,关键代码如下:
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
6.4TaskSet封装为TaskSetManager并提交至Driver
TaskScheduler将TaskSet封装为TaskSetManager(new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)),存入待处理任务池(Pool)中,发送DriverEndpoint唤起消费(ReviveOffers)指令

1)DAGSheduler将TaskSet提交给TaskScheduler的实现类,这里是TaskChedulerImpl
2)TaskSchedulerImpl创建一个TaskSetManager管理TaskSet,关键代码如下:
new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)
3)同时将TaskSetManager添加SchedduableBuilder的任务池Poll中
4)调用SchedulerBackend的实现类进行reviveOffers,这里是standlone模式的实现类StandaloneSchedulerBackend
5)SchedulerBackend发送ReviveOffers指令至DriverEndpoint
6.5Driver将TaskSetManager分解为TaskDescriptions并发布任务到Executor
Driver接受唤起消费指令后,将所有待处理的TaskSetManager与Driver中注册的Executor资源进行匹配,最终一个TaskSetManager得到多个TaskDescription对象,按照TaskDescription想对应的Executor发送LaunchTask指令
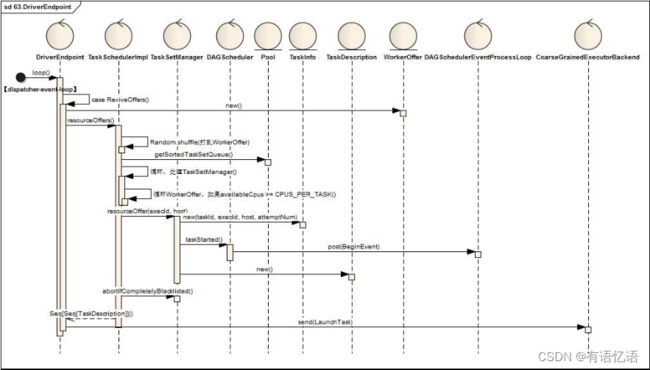
当Driver获取到ReviveOffers(请求消费)指令时
1)首先根据executorDataMap缓存信息得到可用的Executor资源信息(WorkerOffer),关键代码如下
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
2)接着调用TaskScheduler进行资源匹配,方法定义如下:
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {…}
a)将WorkerOffer资源打乱(val shuffledOffers = Random.shuffle(offers))
b)将Poo中待处理的TaskSetManager取出(val sortedTaskSets = rootPool.getSortedTaskSetQueue),
c)并循环处理sortedTaskSets并与shuffledOffers循环匹配,如果shuffledOffers(i)有足够的Cpu资源( if (availableCpus(i) >= CPUS_PER_TASK) ),调用TaskSetManager创建TaskDescription对象(taskSet.resourceOffer(execId, host, maxLocality)),最终创建了多个TaskDescription,TaskDescription定义如下:
new TaskDescription(
taskId,
attemptNum,
execId,
taskName,
index,
sched.sc.addedFiles,
sched.sc.addedJars,
task.localProperties,
serializedTask)
3)如果TaskDescriptions不为空,循环TaskDescriptions,序列化TaskDescription对象,并向ExecutorEndpoint发送LaunchTask指令,关键代码如下:
for (task <- taskDescriptions.flatten) {
val serializedTask = TaskDescription.encode(task)
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
7、Task执行和回执
DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注ExecutorEndpoint如何处理LaunchTask指令,处理完成后如何回馈给DriverEndpoint,以及整个job最终如何多次调度直至结束。
7.1Task的执行流程
Executor接受LaunchTask指令后,开启一个新线程TaskRunner解析RDD,并调用RDD的compute方法,归并函数得到最终任务执行结果

1)ExecutorEndpoint接受到LaunchTask指令后,解码出TaskDescription,调用Executor的launchTask方法
Executor创建一个TaskRunner线程,并启动线程,同时将改线程添加到Executor的成员对象中,代码如下:
private val runningTasks = new ConcurrentHashMap[Long, TaskRunner]
runningTasks.put(taskDescription.taskId, taskRunner)
TaskRunner
1)首先向DriverEndpoint发送任务最新状态为RUNNING
2)从TaskDescription解析出Task,并调用Task的run方法
Task
1)创建TaskContext以及CallerContext(与HDFS交互的上下文对象)
2)执行Task的runTask方法
a)如果Task实例为ShuffleMapTask:解析出RDD以及ShuffleDependency信息,调用RDD的compute()方法将结果写Writer中(Writer这里不介绍,可以作为黑盒理解,比如写入一个文件中),返回MapStatus对象
b)如果Task实例为ResultTask:解析出RDD以及合并函数信息,调用函数将调用后的结果返回
TaskRunner将Task执行的结果序列化,再次向DriverEndpoint发送任务最新状态为FINISHED
7.2Task的回馈流程
TaskRunner执行结束后,都将执行状态发送至DriverEndpoint,DriverEndpoint最终反馈指令CompletionEvent至DAGSchedulerEventProcessLoop中
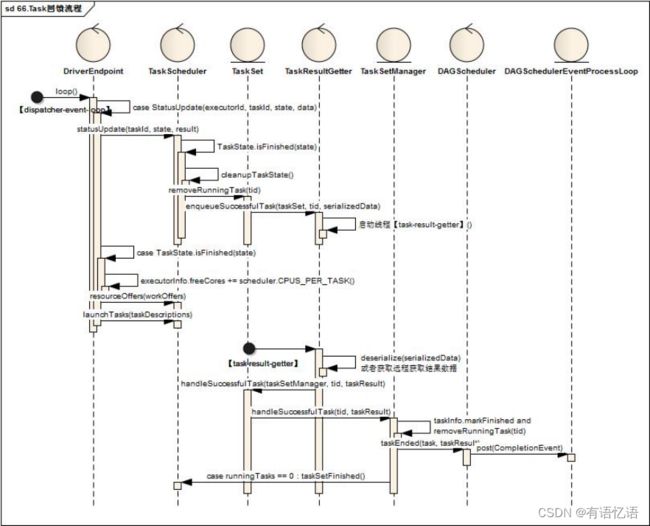
1)DriverEndpoint接受到StatusUpdate消息后,调用TaskScheduler的statusUpdate(taskId, state, result)方法
2)TaskScheduler如果任务结果是完成,那么清除该任务处理中的状态,并调动TaskResultGetter相关方法,关键代码如下:
val taskSet = taskIdToTaskSetManager.get(tid)
taskIdToTaskSetManager.remove(tid)
taskIdToExecutorId.remove(tid).foreach { executorId =>
executorIdToRunningTaskIds.get(executorId).foreach { _.remove(tid) }
}
taskSet.removeRunningTask(tid)
if (state == TaskState.FINISHED) {
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
TaskResultGetter启动线程启动线程【task-result-getter】进行相关处理
1)通过解析或者远程获取得到Task的TaskResult对象
2)调用TaskSet的handleSuccessfulTask方法,TaskSet的handleSuccessfulTask方法直接调用TaskSetManager的handleSuccessfulTask方法
TaskSetManager
1)更新内部TaskInfo对象状态,并将该Task从运行中Task的集合删除,代码如下:
val info = taskInfos(tid)
info.markFinished(TaskState.FINISHED, clock.getTimeMillis())
removeRunningTask(tid)
2)调用DAGScheduler的taskEnded方法,关键代码如下:
sched.dagScheduler.taskEnded(tasks(index), Success, result.value(), result.accumUpdates, info)
DAGScheduler向DAGSchedulerEventProcessLoop存入CompletionEvent指令,CompletionEvent对象定义如下:
private[scheduler] case class CompletionEvent(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Seq[AccumulatorV2[_, _]],
taskInfo: TaskInfo) extends DAGSchedulerEvent
7.3Task的迭代流程
DAGSchedulerEventProcessLoop中针对于CompletionEvent指令,调用DAGScheduler进行处理,DAGScheduler更新Stage与该Task的关系状态,如果Stage下Task都返回,则做下一层Stage的任务拆解与运算工作,直至Job被执行完毕:

1)DAGSchedulerEventProcessLoop接收到CompletionEvent指令后,调用DAGScheduler的handleTaskCompletion方法
2)DAGScheduler根据Task的类型分别处理
3)如果Task为ShuffleMapTask
a)待回馈的Partitions减取当前partitionId
b)如果所有task都返回,则markStageAsFinished(shuffleStage),同时向MapOutputTrackerMaster注册MapOutputs信息,且markMapStageJobAsFinished
c)调用submitWaitingChildStages(shuffleStage)进行下层Stages的处理,从而迭代处理最终处理到ResultTask,job结束,关键代码如下:
private def submitWaitingChildStages(parent: Stage) {
...
val childStages = waitingStages.filter(_.parents.contains(parent)).toArray
waitingStages --= childStages
for (stage <- childStages.sortBy(_.firstJobId)) {
submitStage(stage)
}
}
4)如果Task为ResultTask
a)改job的partitions都已返回,则markStageAsFinished(resultStage),并cleanupStateForJobAndIndependentStages(job),关键代码如下
for (stage <- stageIdToStage.get(stageId)) {
if (runningStages.contains(stage)) {
logDebug("Removing running stage %d".format(stageId))
runningStages -= stage
}
for ((k, v) <- shuffleIdToMapStage.find(_._2 == stage)) {
shuffleIdToMapStage.remove(k)
}
if (waitingStages.contains(stage)) {
logDebug("Removing stage %d from waiting set.".format(stageId))
waitingStages -= stage
}
if (failedStages.contains(stage)) {
logDebug("Removing stage %d from failed set.".format(stageId))
failedStages -= stage
}
}
// data structures based on StageId
stageIdToStage -= stageId
jobIdToStageIds -= job.jobId
jobIdToActiveJob -= job.jobId
activeJobs -= job
至此,用户编写的代码最终调用Spark分布式计算完毕。