【Python可视化实战】钻石数据可视化
一、项目引言
1.背景和目标
钻石作为一种珍贵的宝石,其价格受到多种因素的影响。为了深入了解钻石价格的决定因素,我们收集了大量关于钻石的数据,并希望通过数据可视化来揭示钻石特征与价格之间的关系。
2.内容
- 收集钻石的各项特征数据,包括重量、颜色、刀工等。
- 利用这些数据,我们进行初步的数据清洗和整理。
- 使用Matplotlib和Seaborn进行数据可视化,探索各特征与钻石价格之间的关系。
3.技术方案和工具
- Python编程语言:用于数据处理和可视化。
- Matplotlib库:用于创建基础图表。
- Seaborn库:用于创建高级统计图形。
- Pandas库:用于数据处理和分析。
- NumPy库:用于数值计算。
二、数据准备
1.数据源
我们使用的是ggplot2提供的经典的diamonds数据集,描述了不同钻石的结构特征及其价格。
2. 数据预处理
2.1 数据导入
import pandas as pd
import numpy as np
diamonds = pd.read_csv('./data/diamonds.csv')
diamonds.head(5)删除没有意义的列
diamonds.drop(diamonds.columns[0],axis=1,inplace=True)
diamonds.head(5) 通过info()函数我们可以看所有列数据的类型信息:
diamonds.info()数据集包含53940个样本,共有10个变量,其中有6个浮点型(float)变量、1个整型(int)变量和3个对象型(object)变量,不存在缺失值,目标标量为price,每个变量对应的含义如下所示:

三、可视化分析
3.1导入库
import seaborn as sns
import matplotlib.pyplot as plt
# notebook格式,放大横纵坐标标记,显示刻度,更容易看清
sns.set_context("notebook",font_scale=1)
sns.set_style('ticks')
# 配色使用Set2
sns.set_palette('Set2')
#以内嵌方式画图
%matplotlib inline3.2 数值变量描述性统计分析
f,axarr = plt.subplots(2,4,figsize=(15,10))
sns.boxplot(y='carat',data=diamonds,ax=axarr[0,0])
sns.boxplot(y='depth',data=diamonds,ax=axarr[0,1])
sns.boxplot(y='table',data=diamonds,ax=axarr[0,2])
sns.boxplot(y='price',data=diamonds,ax=axarr[0,3])
sns.boxplot(y='x',data=diamonds,ax=axarr[1,0])
sns.boxplot(y='y',data=diamonds,ax=axarr[1,1])
sns.boxplot(y='z',data=diamonds,ax=axarr[1,2])
plt.tight_layout()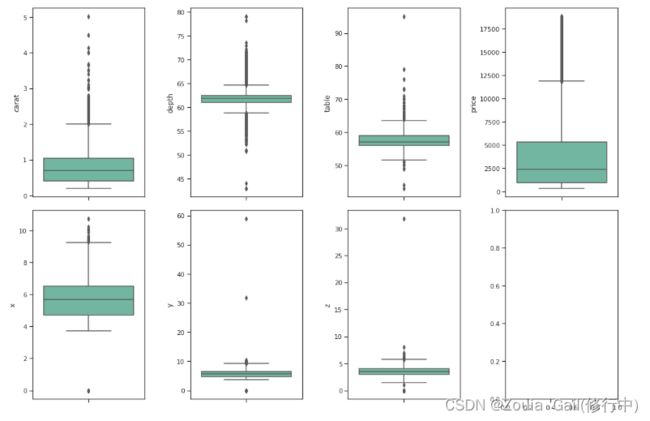
我们看到所有变量都存在许多异常值。在之后的模型构建中,某些模型的训练易受到异常值的影响。(例如第六七张图差异过大,五为正常)
3.3 非数值变量描述性统计分析
sns.countplot(x='cut',data=diamonds)
plt.tight_layout()
大部分的钻石的切工还是比较理想的。我们还可以分析不同切工的钻石的价格情况,切工似乎跟价格并不成正比关系。
sns.barplot(x='cut',y='price',data=diamonds)
sns.countplot(y='color',data=diamonds)
sns.countplot(x='clarity',data=diamonds)
3.4 相关性分析
sns.jointplot(x='carat',y='depth',height=8,alpha =.25,color='g',data=diamonds)
sns.jointplot(x='carat',y='price',height=8,alpha =.25,color='g',data=diamonds)
plt.tight_layout()第一行代码创建了一个联合分布图,展示了 carat(钻石的重量)和 depth(钻石的深度)之间的关系。该图具有8的高度,使用绿色表示,并设置了0.25的透明度,以便观察重叠部分。第二行代码创建了另一个联合分布图,展示了 carat 和 price(钻石的价格)之间的关系。同样,该图具有8的高度,使用绿色表示,并设置了0.25的透明度。使用 plt.tight_layout() 函数调整图形布局,确保所有图形元素正确地定位。目的是通过绘制联合分布图来探索和理解钻石数据集中不同变量之间的关系,从而更好地理解数据集和进行进一步的数据分析。
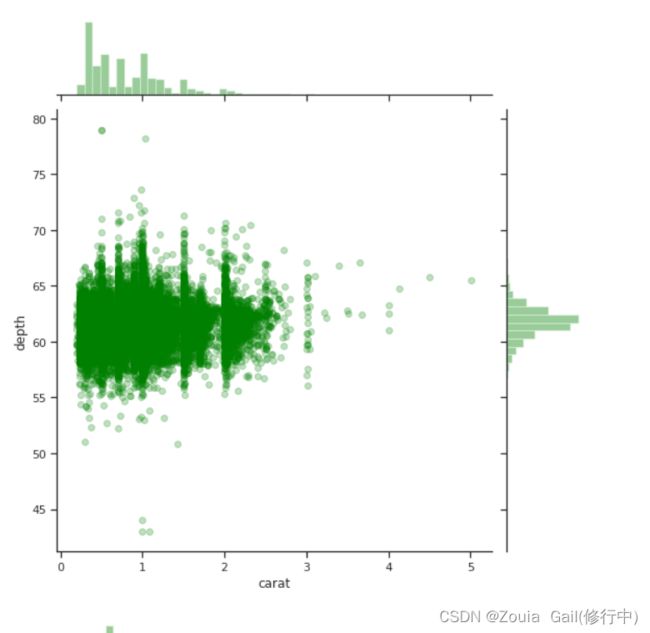
我们可以看到carat与price存在正相关关系,证明钻石价格很大程度上与钻石的克拉重量有关,这也符合我们的实际经验。
在Seaborn中,存在pairplot函数,可以将所有变量之间的相关关系一并画出并分析。pariplot是PairGrid的一个包装函数,它提供了Seaborn一个重要的抽象功能——Grid。Seaborn的Grid将Matplotlib中Figure和数据集中的变量联系起来了。
我们有两种方式可以和grids进行交互操作。其一,Seaborn提供了类似于pairplot的包装函数,它提前设置了许多常见任务的参数;其二,如果你需要更多的自定义选项,那么你可以直接利用Grid方法。
sns.pairplot(diamonds,hue='cut')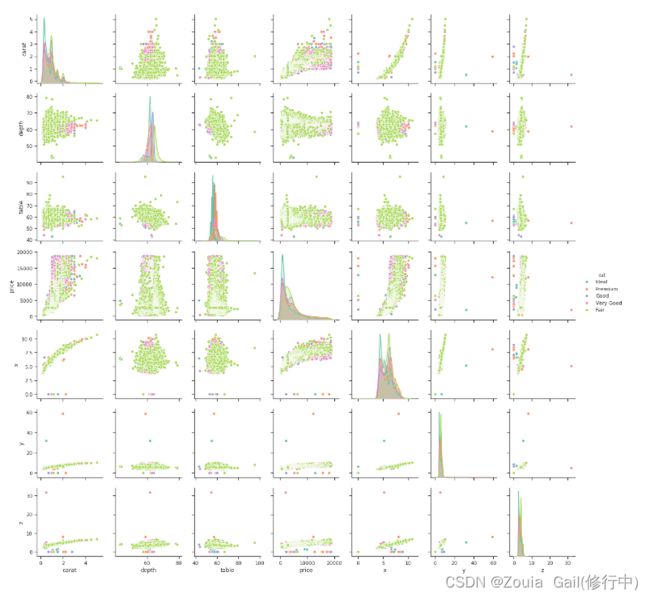 3.5 异常值处理与grids交互
3.5 异常值处理与grids交互
选取数值
diamonds_num = diamonds.select_dtypes(include=[np.number])
diamonds_num.head(5)
去掉异常值
diamonds_cl = diamonds_num[(diamonds_num > diamonds_num.quantile(.05)).all(1) & (diamonds_num < diamonds_num.quantile(.95)).all(1)]
diamonds_cl.head(5)制图
def core(diamonds, alpha=.05):
mask = (diamonds > diamonds.quantile(alpha)).all(1) & (diamonds_cl < diamonds.quantile(1 - alpha)).all(1)
return diamonds[mask]
cmap = sns.cubehelix_palette(as_cmap=True, dark=0, light=1, reverse=True)
(diamonds.select_dtypes(include=[np.number])
.pipe(core)
.pipe(sns.PairGrid)
.map_upper(plt.scatter, marker='.', alpha=.25)
.map_diag(sns.kdeplot)
.map_lower(plt.hexbin, cmap=cmap, gridsize=20)
)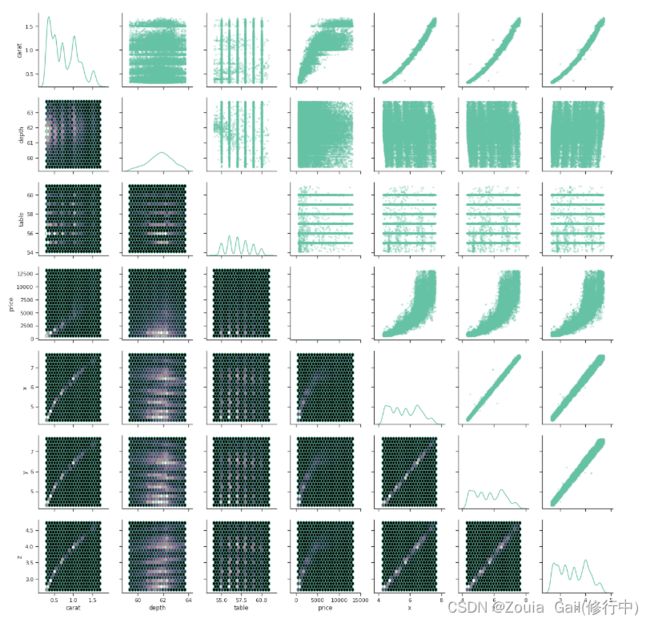
这段代码是使用Python的Seaborn库和Matplotlib库对“diamonds”数据集进行可视化的。Seaborn是基于matplotlib的高级接口,它提供了一种方便的方法来创建复杂的统计图形。让我们逐步分析代码的各个部分:(1)代码创建了一个颜色映射(colormap)对象,名为“cmap”,它使用cubehelix颜色方案。这种颜色方案在数据可视化中很常用,因为它在视觉上更吸引人,并且可以更好地表示数据的层次结构。(2)代码选择了数据框“diamonds”中所有数值型的数据列。这是为了确保我们只处理数值型数据,忽略分类数据或其他非数值型数据。(3)使用.pipe()方法将上一步的结果传递给名为“core”的函数或方法。这个“core”函数或方法的具体细节并未在代码中给出。(4)将结果传递给Seaborn的PairGrid类,创建一个网格,其中每个单元格都表示一对特征之间的联合分布。在网格的上部分,为每个单元格添加散点图,其中数据点用点(.)表示,透明度设置为0.25。在网格的对角线上,为每个单元格添加核密度估计图(KDE)。核密度估计是一种可视化单变量分布的方法。最后在网格的下部分,为每个单元格添加六边形bin图(hexbin)。这用于显示两个变量之间的联合分布。颜色映射(cmap)应用于六边形bin图,而gridsize参数定义了每个六边形的网格大小。
g = sns.FacetGrid(diamonds, row='cut', aspect=4, height=2, margin_titles=True)
g.map(sns.kdeplot, 'price', shade=True, color='g')
for ax in g.axes.flat:
ax.yaxis.set_visible(False)
sns.despine(left=True)
g.fig.subplots_adjust(hspace=0.1)
g.set(xlim=(0, 15000))
plt.tight_layout()FaceGrid可以通过控制分面变量来生成Grid图形,其中PairGrid是它的一个特例。接下来的案例中,我们将以数据集中的cut变量为分面变量来绘制图像:

最后一个案例展示了如何将Seaborn和Matplotlib结合起来。g.axes是matplotlib.Axes的一个数组,g.fig是matplotlib.Figure的一个特例。这是使用Seaborn时常见的一个模式:利用Seaborn的方法来绘制图像,然后再利用Matplotlib来调整细节部分。 我认为Seaborn之所以吸引人是因为它的绘图语法具有很强的灵活性。你不会被作者所设定的图表类型所局限住,你可以根据自己的需要创建新的图表。
agged = diamonds.groupby(['cut', 'color']).mean().sort_index().reset_index()
g = sns.PairGrid(agged, x_vars=agged.columns[2:], y_vars=['cut', 'color'],
height=5, aspect=.65)
g.map(sns.stripplot, orient="h", size=10, palette='Blues_d')
plt.tight_layout()
最后我们来画出在不同颜色的钻石中,克拉重量与价格的关系:
g = sns.FacetGrid(diamonds, col='color', hue='color', col_wrap=4)
g.map(sns.regplot, 'carat', 'price') 
四、项目总结
本次项目的目标是深入了解钻石价格的决定因素,通过收集大量关于钻石的数据,并利用数据可视化技术来揭示钻石特征与价格之间的关系。在项目实施过程中,我们首先收集了钻石的各项特征数据,包括重量、颜色、刀工等。接下来,我们对这些数据进行了初步的数据清洗和整理,以确保数据的准确性和可靠性。为了更好地探索各特征与钻石价格之间的关系,我们采用了Matplotlib和Seaborn这两个强大的数据可视化库。通过创建散点图、核密度估计图和六边形bin图等多种图形,我们能够直观地展示钻石特征与价格之间的关系。通过本次项目,我们成功地揭示了钻石特征与价格之间的潜在关系,为相关行业的从业人员提供了有价值的参考信息。同时,我们也锻炼了数据处理和分析能力,加深了对数据可视化的理解和应用。最后,本次项目达到了预期的目标,为探索钻石价格的决定因素提供了有益的视角。