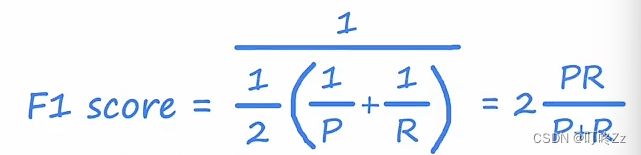02 Deep learning algorithm
Neural Networks target:
- inference(prediction)
- training my own model
- practical advice for building machine learning system
- decision Tress
application: speech(语音识别) ----> images(计算机视觉)—> text(NLP)
一、Neural Networks
1.神经元和大脑
1) Demand Prediction(需求预测)
a) some notion
-
neuron(神经元):可以将一个简单的模型例如logistic regression 看作一个简单的neuron
-
layer(层) : some neuron or single,输入equal or similar feature and out put some data together
-
activation(激活) :将 input of neuron called activation
-
activation function:激活函数是代表能够输出激活值的函数
-
hidden layer: 知道输入和输出,中间的处理neuron叫做hidden layer
2) 神经网络的网络层
a) definition
输入一组数字向量,经过一系列层的处理,输出另一组数字向量
b) notion:
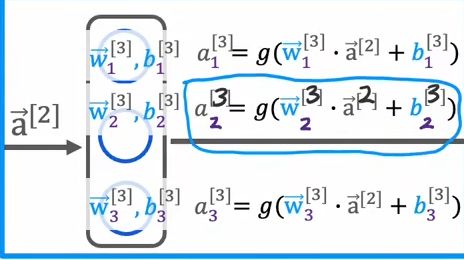 对于不同的层,w参数的角标也可以标识 通过上标标识
对于不同的层,w参数的角标也可以标识 通过上标标识
c) complex 神经网络
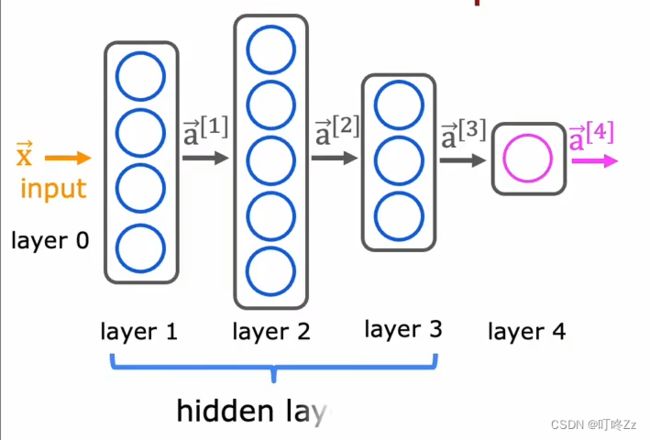
《四层的神经网络》
input等于0层,123隐藏层,4 4为输出层
计算时候从左向右的方向进行计算
d ) Tensorflow的数据表现形式
因为tensorflow基本处理很大的数据集,都用矩阵表示来让计算更加高效
- numpy表示数组方式:
- x = np.array( [ [ ] , [ ] ] ) ()内仅有一个【】代表一维数组,[ [ ] ] 代表二维数组
- tensor数组表示方式:
- tensor([ [ ] , [ ] ] , shape( , ) , dtype = )
使用: 一般自己加载和操作数据的时候使用numpy,将数据转入tensorflow 时候会转化为tensor来方便计算和处理
3) build neural network
a ) build in tensorflow
- 过程:创建dense 隐藏层,将隐藏层顺序连接,编译,输入x和y,训练模型,模型拟合

b ) dense and forward prop in numpy (传播向量化)

4 ) A G I (artificial g eneral intelligence)
definition: AI 可以做人类所做的一切事情
5 ) Martrix multiplication in numpy
definition
numpy库中中的用于两个矩阵之间的乘法,也可以等价于 AT @ W
optimization forward prop(优化传播向量)

2. use tensorflow build neuron
步骤: 1.指定模型(设置dense层) 2.compile编译模型 3.epoch 训练模型
i .模型训练细节
1)create the model
model= sequential( [ Dense() Dense() ] )
2)loss and cost function
对于分类问题使用 model.compile(loss = BinaryCrossentropy()) 二元交叉熵损失函数
对于线性回归:model.compile(loss = MeanSquareError ()) 均方差
3)gradient descent
使用反向传播 model.fit( X , y , epochs = 100 )
i i . sigmoid 替代函数
作用:有时不仅是0-1的概率,有不同的条件需要找不同的函数
1) reLU function
g(z) = max(0,z)
2)linear activation function
g(z) = z = wx + b
3 ) how to select activation function
- 可以在不同的神经元中选择不同的激活函数,根据需求选择
- output layer:如果分类 0,1 最好选择sigmoid函数,有正负的linear function 合适
- hidden layer: 主流的 relu function ,运算速度更加快,只有x负半轴平缓,梯度下降时更快
二 、multiclass classification problem
1 . Softmax
i . softmax regression (N possible outputs)
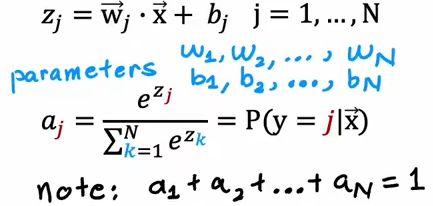
i i. cost function
如果计算y = 某个值的cost function 则只需要带入对应的成本函数
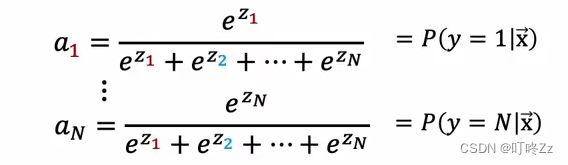
i i i . implement in tensorflow
- 只需将最后一层换为 softmax
- 将 损失函数换为:SparseCategoricalCrossentropy(密集分类交叉熵损失函数)
v i . improve softmax
当计算时,有时候式子之间有计算误差,所以在误差函数后加(from_logits = true)
2 . improve α algorithm
i . Adam algorithm
作用:如果梯度是一直稳定下降的时候就会适当的增大 α,当来一个值两边震荡时,会减小α
**使用:**

3 . Convolutional layer (卷积层)
作用: 对于前一层的feature并不是全部选取,而是选取了一部分
三、Evaluate the performance of algorithm
1 . Evaluate the model
i . use test set
取出 70% 用来作training set,其余的30%用来作 test set评估model的泛化能力
但是只是用测试集来评估几次多项式也是不准确的
i i . Training / cross validation(交叉样本) / test set
60% training set 20% cross validation 20% test set
先用training set 和 cross validation 来选择最佳的模型,然后确定好了最佳模型以后我们将在最后的 test set模型测试最终的准确度
i i i . Bias / Variance (偏差和方差)
d 代表了多项式的次数

d越大,J-train越来越小,J-cv越来越大
high-bias(欠拟合) :在training set表现不好
high-variance(过拟合):在 验证集表现 相比training set 差得多,增加training可以改善
vi . Regulartion (正则化)

当 **入** 越大最后拟合的曲线接近一条 y = b 的直线,y越小也会出现 overfit
可以使用交叉验证来选择合适的 入
v i i . how to add regularization

2 . Iterative loop of ML development
i . add data
**data augmentation **:的一个技巧:对数据所作的改变或者扭曲,例如给语音 加上噪音,给图片扭曲,但是最后得到的数据仍和测试集中得到的很相似。
i i. transfer learning(迁移学习)
作用:使用来自不同任务的数据来解决当前的任务,可以通过学习识别猫,狗,牛,人等,为前几个层学习了一些合理的参数,然后将参数transfer到新的神经网络中去
Why? 为什么通过识别其他的东西能够帮助识别类似手写数字一样的东西呢?
因为头几层的网络都在识别图像的基本特征,找到边角,曲线,基本形状等相似的特征,所以对于不同类型的图片效果都是一样的
四、倾斜数据集的误差指标
why:因为例如罕见病中,数据集很多都是不患病的,所以需要衡量一个算法好坏
1 . precision / recall(准确度和召回)
i . definition

i i . 权衡精确度和召回
设置一个高的阈值,会使精确度提高,但是召回下降,相反的话召回提高,但是精确度下降
i i i .F 1 Score ( f 1 指标 )