PostgreSQL 分区
由于大量数据存储在数据库同一张表中,后期性能和扩展会受到影响。所以需要进行表分区,因为它可以将大表分成较小的表,从而减少内存交换问题和表扫描,最终提高性能。庞大的数据集被分成更小的分区,更易于访问和管理。
什么是 PGSQL?
PGSQL 是一个开源关系数据库系统。它支持关系 (SQL) 和非关系 (JSON) 查询。它被用作基于 Web 、移动和分析应用程序的主要数据库。
以下是 PGSQL 的一些常见用例:
-
LAPP(Linux、Apache、PostgreSQL 和 PHP)堆栈中的强大数据库。
-
地理空间数据库。
-
通用事务数据库。
PGSQL的主要特性
-
用户定义的数据类型:PGSQL 可以扩展以创建用户定义的数据类型。
-
复杂的锁定机制:存在三种锁定机制,行级锁、表级锁和资询锁。
-
表继承:PGSQL 允许基于另一个表创建子表。
-
Foreign Key Referential Integrity:指定外键值对应于另一个表中的实际主键值。
嵌套事务(保存):这意味着子查询的结果不会在其父查询回滚时回滚。但是对于保存,若顶层事务被回滚,所有的保存点也会被回滚。
什么是 PGSQL 分区?
分区是指将一个大表拆分成更小的物理块,这些块可以根据其用途存储在不同的存储介质中。每个部分都有其特点和名称。分区有助于提高数据库服务器的性能,因为需要读取、处理和返回的行数明显减少。您还可以使用 PostgreSQL 分区来划分索引和索引表。
PGSQL 分区主要有两种类型:垂直分区和水平分区。在垂直分区中,我们按列划分,在水平分区中,我们按行划分。
水平分区涉及将不同的行放入不同的表中。例如,您将 18 岁以上学生的详细信息存储在一个分区中,将 18 岁以下的学生详细信息存储在另一个分区中。可以在两个分区上创建联合视图以显示所有学生。
垂直分区包括创建列较少的表,并使用其他表来存储剩余的列。规范化还涉及到跨表的列分割,但是垂直分区不仅限于此,甚至在已经规范化的情况下还会对列进行分区。
如何创建分区表
简单描述一下自己创建分区表的步骤(水平,按创建时间分区)
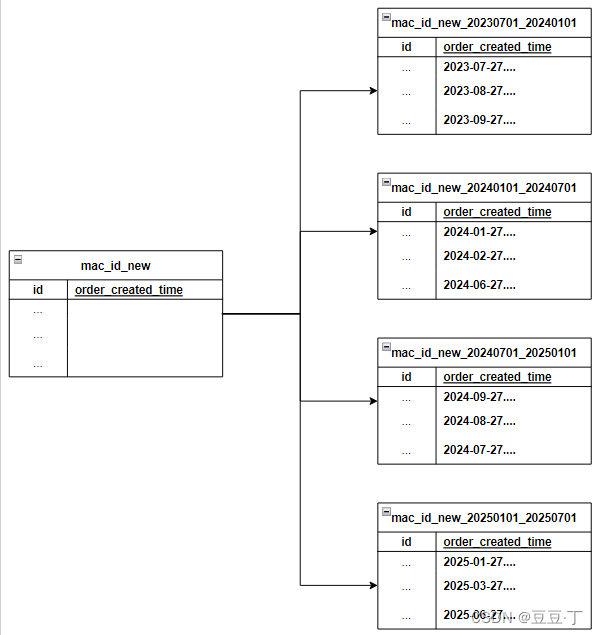
1. 创建主表 分区键:order_created_time
CREATE TABLE "mac_id_new" (
"id" int8,
"created_by" varchar(255) COLLATE "pg_catalog"."default",
"created_time" timestamp(6),
"last_modified_by" varchar(255) COLLATE "pg_catalog"."default",
"last_modified_time" timestamp(6),
"deleted" bool,
"deleted_by" varchar(255) COLLATE "pg_catalog"."default",
"deleted_time" timestamp(6),
"optimistic_locking_version" int8,
"order_id" int8,
"order_created_time" timestamp(6)
) PARTITION by range(order_created_time);2.创建分区表函数
CREATE OR REPLACE FUNCTION f_create_partition_table(t_name VARCHAR,bengin_date TIMESTAMP ,end_date TIMESTAMP)
RETURNS boolean AS $$
DECLARE
create_partition_table_sql varchar(1024);
create_table_index_sql varchar(1024);
create_table_pk_sql varchar(1024);
bengin_date_str varchar(64);
end_date_str varchar(64);
query_partition_table_sql varchar(1024);
t_row record;
begin
bengin_date_str := to_char(bengin_date,'YYYYMMDD');
end_date_str := to_char(end_date,'YYYYMMDD');
create_partition_table_sql := ' create table if not exists '|| t_name ||'_' || bengin_date_str || '_' || end_date_str ||
' partition of '||t_name ||
' for values from ('''|| bengin_date ||''') ' ||
' to ('''|| end_date ||''')';
create_table_index_sql := ' CREATE INDEX IF NOT EXISTS idx_'|| t_name ||'_'|| bengin_date_str || '_' || end_date_str ||'_business_id ON '
|| t_name ||'_'|| bengin_date_str || '_' || end_date_str || ' USING btree (business_id);';
create_table_pk_sql := 'ALTER TABLE '|| t_name ||'_' || bengin_date_str || '_' || end_date_str ||' ADD CONSTRAINT '|| t_name ||'_' || bengin_date_str || '_' || end_date_str ||'_PK PRIMARY KEY ("id");';
execute create_partition_table_sql;
execute create_table_index_sql;
execute create_table_pk_sql;
return true;
end;
$$ LANGUAGE plpgsql;3.创建分区表,执行后刷新数据库,在表mac_id_new下查看验证分区表
SELECT f_create_partition_table('mac_id_new','2023-07-01','2024-01-01');
SELECT f_create_partition_table('mac_id_new','2024-01-01','2024-07-01');
SELECT f_create_partition_table('mac_id_new','2024-07-01','2025-01-01');
SELECT f_create_partition_table('mac_id_new','2025-01-01','2025-07-01');
SELECT f_create_partition_table('mac_id_new','2025-07-01','2026-01-01'); 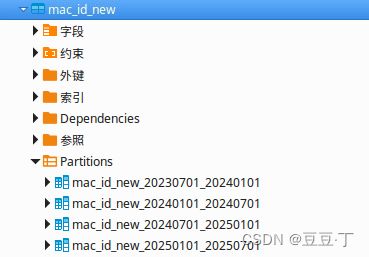
最后进行数据迁移,数据校验,至此分区表创建完成