第九章 聚类
9.1 聚类任务
聚类是试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”。通过这样的划分,每个簇可能对应于一些潜在的概念(类别)。但是这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需要由使用者来把握和命名。
- 聚类算法涉及的两个基本的问题:性能度量和距离计算
9.2 性能度量
-
聚类性能度量大致有两类。一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不是利用任何参考模型,称为“内部指标”
-
基于以下式子常用的聚类性能度量外部指标:
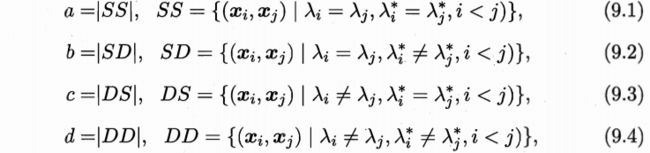
-
对于数据 D D D={ x 1 , x 2 , . . . . , x m x1,x2,....,xm x1,x2,....,xm},假定通过聚类给出的簇划分为C={ c 1 , c 2 , . . . , c k c1,c2,...,ck c1,c2,...,ck},参考模型给出的簇划分为C*={ c 1 c1 c1*, c 2 c2 c2*,…, c s cs cs*}.相应的,令 λ λ λ, λ λ λ*分别表示与C和C*对应的簇标记向量。
-
集合SS包含了在C中隶属于相同簇且在C*中也属于相同簇的样本对
-
集合SD包含了在C中隶属于相同簇且在C*中隶属于不同簇的样本对,DS,DD同理
-
其中a+b+c+d=m(m-1)/2
-
jaccard系数

-
FM指数
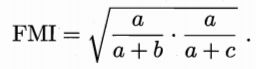
-
Randy指数

上述性能度量值范围均在[0,1]区间内,值越大越好
- 基于(9.8-9.11)可导出下面一些常用的聚类性能度量内部指标:

其中, d i s t ( . , . ) dist(.,.) dist(.,.)用于计算两个样本之间的距离; u u u代表簇C的中心点,|C|代表C中样本点的个数。
- DB指数:

- Dunn指数:
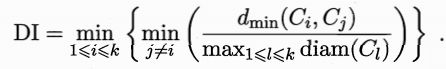
显然,DBI越小越好,DI则越大越好。
9.3 距离计算
- “距离度量”满足的一些基本特性:
(1)非负性: d i s t dist dist(xi,xj)>=0;
(2)同一性: d i s t dist dist(xi,xj)=0当且仅当xi=xj;
(3)对称性: d i s t dist dist(xi,xj)=dist(xj,xi);
(4)值递性: d i s t dist dist(xi,xj)<=dist(xi,xk)+dist(xk,xj). - 几种距离的计算方法
给定样本xi=(xi1;xi2;…;xin)与xj= (xj1;xj2;…xjn)
- 闵可夫斯基距离
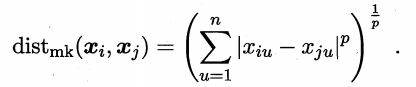
- 欧氏距离
当p=2时,闵可夫斯基距离变为欧式距离

- 曼哈顿距离
当p=1时,闵可夫斯基距离为曼哈顿距离

- 切比雪夫距离
当p->∞时为切比雪夫距离
-
有序属性和无序属性
有序属性: 能直接在属性上计算距离,如定义域为{1,2,3}的离散属性,“1”与“2”比较接近、与“3”比较远,这样的属性称为有序属性。
无序属性: 定义域为{飞机,火车,轮船},这样的离散属性则不能直接在属性上计算距离,称为无序属性。 -
无序属性的距离计算:VDM距离

其中mu,a表示在属性u上取值为a的样本数,mu,a,i表示在第i个样本簇中在属性u上取值为a的样本数,k为样本簇数。 -
混合属性的计算可利用闵可夫斯基距离和VDM结合
假设有nc个有序属性、n-nc个无序属性,不失一般性,令有序属性排列在无序属性之前,将闵可夫斯基距离和VDM结合即可处理混合属性:
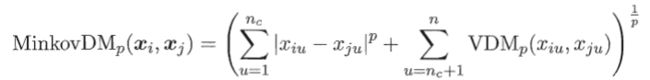
当样本空间中不同属性的重要程度不同时,可以使用加权距离,下面为加权闵可夫斯基距离:
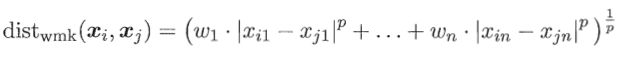
其中,权重 w w w i>=0(i=1,2,…n)表征不同属性的重要性,通常 w w wi之和等于1
9.4 原型聚类
9.4.1 k均值法(k-means)
给定样本集D={ x 1 , x 2..... , x x1,x2.....,x x1,x2.....,xm}针对聚类所得簇划分C={C1,C2,…,Ck}最小化平方差
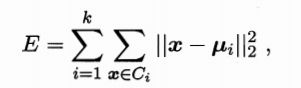
其中 u u ui是簇Ci的均值向量,即Ci中所有样本的均值
以下列数据集为例,K-means算法过程如下:
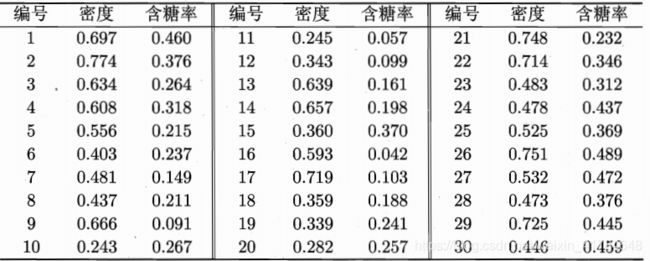
有数据集可知,聚类簇数k=3
(1)随机从三个聚类簇中选取三个样本来作为初始向量值如 x 6 , x 12 , x 27 x6,x12,x27 x6,x12,x27
![]()
(2)计算数据集中每个样本点与 u u u1, u u u2, u u u3的距离,然后判别该样本点距离哪个簇的距离最近,即将该样本划分到这个簇中,如x1距离均值向量u1, u u u2, u u u3的距离分别是0.369,0.506,0.166,因此将该点归入簇C3中。经过第一遍考察后:

(3)从新划分的簇中求出新的均值向量
![]()
(4)重复步骤(2)(3)得到新的划分簇和均值向量,直到C1,C2,C3不在变化
9.4.2 学习向量化(LVQ)
与k均值算法类似,LVQ试图找到一组原型向量来刻画聚类结构,但与一般的聚类算法不同的是,LVQ假设的数据样本带有类别标记,学习过程利用样本的这些监督信息来辅助聚类。
以上面的数据集为例,其中令9-21号样本标记为 c c c2,其他样本标记为c1。假定q=5,即学习目标是找到5个原型向量 p 1 p1 p1, p 2 p2 p2, p 3 , p 4 , p 5 p3,p4,p5 p3,p4,p5,并假定其对应的类别标记分别为 c 1 , c 2 , c 2 , c 1 , c 1 c1,c2,c2,c1,c1 c1,c2,c2,c1,c1,对第q个簇可从类别标记为tq的样本中随机选取一个作为原型向量,例如书中p1的初始化向量为x5,则是因为p1的类别分类标记是c1,初始化向量则是从c1的标记样本中随机抽取的,LVQ算法的实现过程如下:
(1)初始化原型向量及学习率
(2)计算每个样本与初始化向量之间的距离,将该样本标记该初始化向量的标记并利用公式p’=p+学习率·(x-p)来更新原型向量。
(3)重复更新过程,直到满足条件。
9.4.3 高斯混合聚类
与k均值、LVQ用原型向量来刻画聚类结构不同,高斯混合聚类采用概率模型来表达聚类原型。
高斯混合聚类算法如下:

9.5 密度聚类
9.6 层次聚类