配置环境
配置前的说明
部署伪分布式与集群式Hadoop的绝大部分操作都是一样的,细节上区别在于集群式是在两台机子上部署的,两台机子都要执行下列操作,而伪分布式都是在一台机子上操作,以下全部操作如没有特别说明,则伪分布式操作与集群式操作等同。
环境说明
伪分布式Hadoop
l 本次hadoop配置的为伪分布模式,即在一个机子上作为namenode,又作为datanode。
l 操作系统:CentOS5.5
l JDK:1.6.0_26
l Hadoop:hadoop-0.21.0
集群分布式Hadoop
l 本次hadoop配置的为集群分布模式,即在一个机子上作为namenode,另一台机子作为datanode。
l 操作系统:CentOS5.5
l JDK:1.6.0_26
l Hadoop:hadoop-0.21.0
l 网络配置:

网络配置
查看主机名
使用下面命令进行查看主机名,若要更改,请查看下一步操作。
hostname

修改主机名
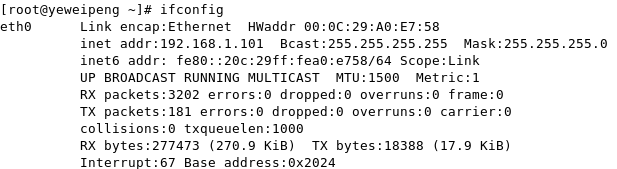
第一步,查看主机IP地址。
用下面命令即可查看,本机IP为192.168.1.101(以下操作请使用root用户方可执行)
ifconfig
第二步,若想更改主机名,则可以通过修改文件“/etc/sysconfig/network”中的HOSTNAME后面的值,即可改成我们想要的名字。
用下面命令进行修改主机名。
nano /etc/sysconfig/network
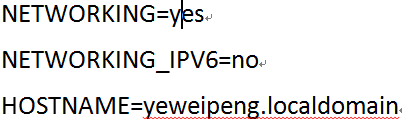
第三步,修改文件“/etc/hosts”。
使用命令打开后更改为如图所示的样子。将原有的全部注释(前面加#),namenode为第一个,datanode为第二个,因为伪分布式模式是namenode和datanode为同一个的,所以两个都是一样。
nano /etc/hosts
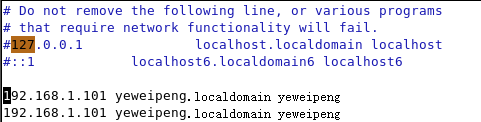
集群模式则修改为如图所示。(两个机子修改为一样的,第一个为namenode,第二个datanode)

SSH无密码验证配置
关于SSH服务

还要安装rsync,执行命令sudo yum install rsync
创建hadoop用户
使用root用户创建hadoop用户,依次执行下列命令即可。(集群模式则每台机器都需要这样操作)
useradd hadoop(新增用户)
passwd hadoop (输入两次密码,但输入期间是无任何字符显示的)

生成SSH密钥
注销,切换到用户hadoop下,执行下列命令。
cd /home/hadoop
ssh-keygen -t rsa(一路回车,选择默认的保存路径)
进入.ssh目录:cd .ssh
cp id_rsa.pub authorized_keys
ssh 你的主机名
不需要输入密码即为成功,输入exit退出,若要输入密码,则在.ssh目录下执行命令chmod 600 authorized_keys后即可。
上述为伪分布式SSH配置成功,若为集群式还需要下列一个操作方可。
将namenode上的公钥拷贝到datanode,namenode机器在hadoop用户的用户目录下(/home/hadoop)下执行命令ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@(datanode的主机名)。
执行命令SSH datanode的主机名。若不需要密码则为成功。
JDK配置
下载JDK
使用root用户登录后,执行命令yum install jdk。若找不到,则去官网下载(https://cds.sun.com/is-bin/INTERSHOP.enfinity/WFS/CDS-CDS_Developer-Site/en_US/-/USD/ViewProductDetail-Start?ProductRef=jdk-6u22-oth-JPR@CDS-CDS_Developer)
安装JDK
新建目录/usr/java,将源码包jdk-6u22-linux-i586.bin复制到该目录下,执行命令chmod a+x jdk-6u22-linux-i586.bin。
执行命令 ./jdk-6u22-linux-i586.bin进行安装。
配置环境变量
修改文件“/etc/profile”来添加环境变量。执行下面命令打开文件。
nano /etc/profile
在文件最后添加下面几行:
export JAVA_HOME=/usr/java/jdk1.6.0_26
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
source /etc/profile使变量生效。
验证安装成功
执行命令java –version可得

若不成功则查看环境变量是否设置错误。
Hadoop配置
安装hadoop
以下操作若不能执行,则使用visudo(该命令需要root权限)给hadoop用户添加最高权限,发生权限不足时,在每条命令前加sudo即可。
如图所示。该命令使用vi编辑器,若不熟悉操作则按77G后按i键
添加一行hadoop ALL=(ALL) ALL后按esc键,输入:wq即可保存退出。

注销,切换到hadoop用户下。新建目录sudo mkdir /usr/local/hadoop,
将hadoop-0.21.0.tar.gz解压缩到该目录下,在压缩包所在的文件夹下执行sudo tar -xvzf hadoop-0.21.0.tar.gz –C /usr/local/hadoop
配置环境变量
修改/etc/profile文件,在文件最后添加两行。
export HADOOP_HOME=/usr/local/hadoop/hadoop-0.21.0
export PATH=$HADOOP_HOME/bin:$PATH
配置/usr/local/hadoop/hadoop-0.21.0/conf/hadoop-env.sh文件,在文件最后添加JAVA_HOME环境变量,export JAVA_HOME=/usr/java/jdk1.6.0_26/
配置master和slave
两个文件在/usr/local/hadoop/hadoop-0.21.0/conf/下面,
master文件填写
192.168.1.101(namenode的IP)
slave文件填写
192.168.1.101(datanode的IP)
因为是伪分布,所以都一样,且只有一个。
若为集群,则为
master文件填写
192.168.1.147(namenode的IP)
slave文件填写
192.168.1.103(datanode的IP)
配置三个xml文件
三个xml文件都是在/usr/local/hadoop/hadoop-0.21.0/conf/
配置core-site.xml
创建文件夹mkdir /usr/hadoop/hadoop-0.21.0/tmp
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://yeweipeng(你的master机器名):9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-0.21.0/tmp</value>
</property>
</configuration>
配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1(datanode的数目)</value>
</property>
</configuration>
配置 mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>yeweipeng(你的master机器名):9001</value>
</property>
</configuration>
启动和测试Hadoop
准备工作
使用root权限关闭防火墙,执行/etc/init.d/iptables stop,运行命令/etc/init.d/iptables status查看防火墙状态。
使用hadoop用户,将目录切换到/usr/local/hadoop/hadoop-0.21.0/bin下,格式化目录节点,hadoop namenode –format。
集群模式,上述两个操作只需要namenode机器操作,datanode则不需要。
启动hadoop
在/usr/local/hadoop/hadoop-0.21.0/bin下执行start-all.sh启动hadoop。
用jps查看进程,如图所示有六个进程则为正确(伪分布式)
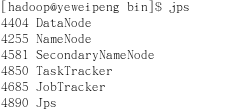
若为集群则在namenode机器上有4个进程。分别是JobTracker,NameNode,Jps,SecondaryNameNode。而datanode有3个,分别是TaskTracker,DataNode,Jps。
网页查看集群
打开http://yeweipeng(主机名):50070查看节点状况
打开http://yeweipeng(主机名):50030查看job状况 ;
测试
创建目录haoop fs -mkdir test
上传haoop fs -put 你要上传的目录
下载haoop fs -get 云端的目录 本地目录
配置中出现的错误
问题:启动成功后,发现在master查看live nodes为0
解决方案如下:
将文件/etc/hosts内原有的文件内容注释掉,添加namenode和datanode的IP地址与主机名。
问题:JAVA_HOME is not set
解决方案如下:
配置/conf/hadoop-env.sh文件时,只是修改了JAVA_HOME的值,并没有将前面的注释号#删除掉,所以导致此种问题。
问题:启动hadoop后,执行jps命令只有一个jps进程
解决方案如下:
只有一个进程的原因在于三个xml文件,master,slave的设置错误。
1. 在配置过程的xml文件我们将主机名都写为master导致错误,则将其改为namenode的主机名方可。
2. master上只能有namenode的IP地址,不得有datanode的地址。同理,slave上只能有datanode的IP地址,不得有namenode的。
问题:伪分布式配置SSH后,无论如何都需要输入密码
解决方案如下:
更改authorized_keys的权限为600
chmod 600 authorized_keys
参考资料
http://blog.csdn.net/hyclq/article/details/6095904
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
http://blog.csdn.net/zhaogezhuoyuezhao/article/details/7328313