各类Java对象
- 相关概念的混淆
- 在某一时间段,人们对某种编程困境感到烦恼,不少人脑中产生了一种新开发方式的概念
- 一些代表人物提出了他们的意见,而同一时期可能又不少人对同一问题,用自己的不同语言提出不同概念
- 如果又官方组织维护概念,概念就会清晰;
- 不同的视频教程、其他程序员,看到这一概念的描述或是案例后,人脑会去抽象、提取其特征,然后用自己的语言去描述;这一过程可能造成语义扩散、概念扭曲。这是一个盲人摸象的过程,从读者的视角去自己抽象的概念,可能偏离原型
- 当然,原型也可能不完美或者不顺应时代(如架构方式)的转变,导致概念的转变
以最令人疑惑的javaBean和pojo为例:
- 有人说pojo是一个javabean
- 有人说javabean是一个只有getter和setter的类
- 有人说pojo是一个只有getter和setter的类
- 有人说javabean要序列化
- 有人说pojo要序列化
- 有人说javabean是一个只有getter和setter的类
- 有人说pojo不含有业务逻辑(阿里开发规范)
- 但是Martin Fowler提出pojo概念时希望将业务逻辑写入pojo
- 。。。
本文会探讨这些概念,遵循唯物史观,尽力找出其时代背景、相对概念、演化过程,并标明材料出处。
组件模型
javaBean、EJB是以“组件”概念为基础提出的
根据Ian Sommerville《软件工程》第十版的总结,
书中提到了两种先人关于组件的定义。如今“组件”没有权威的组织去定义它,作为一个程序单元是它公认的基础概念。
面向对象、面向组件、面向服务是不同的软件工程思想。组件和服务可以兼容,组件可以是嵌入式的组件(嵌入程序而不是说嵌入式开发),也可以以服务的形式被其他应用使用。
基于构件的软件工程作为一种基于复用软件构件的软件系统开发方法,是在20世纪90年代末期出现的。它的产生是由于设计者们在使用面向对象的开发过程中所受到的挫折,这种挫折缘于面向对象开发不能够像人们最初所期待的那样完成广泛的复用。
容器:
对于充当程序单元而不是外部服务的构件来说,构件模型规定了必须由支持构件执行的中间件所提供的服务。Weinreich和Sametinger利用操作系统来类比解释构件模型:操作系统为应用提供一组通用服务(系统调用),组件模型也提供通用服务给组件。
因此可以认为组件处于提供基础服务的“容器”中
而javaBean就是一种组件。最初的javaBean指前端GUI中的组件,如一个小窗口、按钮;还有一种Enterprise JavaBean,是JavaEE规范中的分布式(多用于服务端)组件。
前端GUI组件代表:VB(Visual Basic),javabean,现代的web组件库
服务端组件与容器:EJB与javaEE平台;COM与.net平台;
- javabean项目
- 这篇文章应该以解释、论证定义为主
- com组件
- 组件 相关里理论
- 与领域模型理论的关系
- JavaBeans™ architecture -看来组件是一种架构?
- 也许我的网站应该把目前学的知识在图中的位置展现出来,以好让我明白那是一种架构
- and 个人理论同全局理论的矛盾-也许追求统一是一种哲学?
- 组件在GUI有“行为”,但行为是业务逻辑吗?组件为了复用,复用的逻辑哪里都用,还算业务吗
- 当初想问的这个行为应该是类似js吧
- 三层架构业务层统一了逻辑,分层架构似乎和领域、组件时不一样的方向处理业务,类似AOP和三层架构一个横一个纵。那么有分层架构的单体GUI应用吗
- 容器与bean也在控件有类似的概念吗?还是说组件模型里的?EE有容器,servlet不是bean,docker也不是
- 说起来js也有监听器之类的东西,GUI架构里也提到早期的表单也有数据监听,,,是不是前端或者组件模型都有这个。也许也是前端的共性呢
为什么都不用构造函数了?明明mybatis的sqlsessionFactory工厂也用了。感觉一直在set,重复的set
JavaBean
java是咖啡,bean是豆子。
JavaBean规范是由Sun公司定义的。JavaBean是遵守JavaBean API1规范的Java类,它是一个可以重复使用的组件。
JavaBeans™使组件复用变得容易. 开发者们使用其他人开发的组件时不需要了解其内部实现。
这个面向对象是不是也说过。果然一个抽象一个具体
容易复用是因为遵循统一且合理的规范:无参构造
- 那么这个前端的javabean有没有逻辑就要看前端组件架构的理论要不要业务逻辑了?那现在的后端,之前后端的ejb有业务逻辑,但pojo和三层架构取代了这个“业务逻辑生态位”,所以后端bean。,去哪里了?作为后端组件?那有逻辑吗?如果有的话,是不是意味着前端bean其实也有业务逻辑,也即一开始没有限制?
- 我猜测组件架构应该是有业务逻辑的,因为ejb也是bean也是组件(?)或许是通用业务逻辑?
- 看看mvvm这种纯前端模式吧业务逻辑放哪里
官方教程说了:只要让你的类长得像bean,工具们自己会认得
JavaBean主要规范:
- bean组件具有属性(property);通过提供getter/setter方法来实现属性;
- 同类的成员变量相比,“属性”是组件中的概念,对内封装变量、对外暴露给调用方。这是面向对象开发的“封装”概念的具体应用
- 要可以持久化(@Since jdk1.4)
上述描述经常出现在各大教程中。官网教程还介绍了bean的其他部分的称呼(确实比起实现接口那种必须填写的规范,更像是对可有可无部分的称呼):
- 方法:“bean的方法”是设计bean能做什么。
- 前端组件库的控件
JavaAPI文档中Bean包的描述:
包含和开发Bean相关的类 – beans 是基于JavaBeans™ 架构的组件.
但是,此包中的大多数类都是由bean编辑器使用的(即,用于自定义和组合bean以创建应用程序的开发环境,如eclipse的bean编辑器)。 特别是,这些类有助于bean编辑器创建可以自定义bean的可视化界面。 例如,bean可能包含bean编辑器可能不知道如何处理的特殊类型的属性。 通过使用PropertyEditor接口,bean开发人员可以为此特殊类型提供编辑器。
However, most of the classes in this package are meant to be used by a bean editor (that is, a development environment for customizing and putting together beans to create an application). In particular, these classes help the bean editor create a user interface that the user can use to customize the bean. For example, a bean may contain a property of a special type that a bean editor may not know how to handle. By using the PropertyEditor interface, a bean developer can provide an editor for this special type.
官网教程中使用netbeans的bean编辑器,可视化编辑属性:
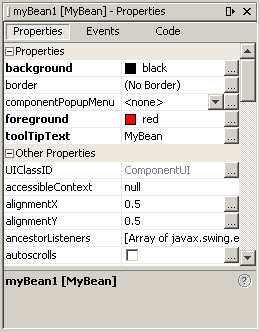 可以看到该案例中的bean被编写了background等属性
可以看到该案例中的bean被编写了background等属性
java11的desktop模块中(9开始引入模块化系统):
定义AWT和Swing用户界面工具包,以及用于辅助功能,音频,图像,打印和JavaBeans的API。
- 事件是一开始给swing设计后来给其他设计了吗
- 和spring事件的关系
- BeanInfo和springbeaninfo如果有的话
- DesignMode
- 长期持久性:xml可能那个时候xml比较流行吧
内省(Introspector)是Java语言对Bean类属性、事件的一种缺省处理方法。
Java中提供的一套API,专门用于访问某个属性的get,set方法,
通常的操作: 通过Introspector获取某个对象的BeanInfo信息,然后通过BeanInfo来获取属性的描述器PropertyDescriptor,
通过这个属性描述器就可以获取某个属性对应的getter/setter方法,最后运用反射技术执行方法
import java.beans.BeanInfo;
import java.beans.IntrospectionException;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Test {
public static void main(String[] args) {
User user = new User();
user.setName("Tina");
user.setAge(100);
try {
BeanInfo beanInfo = Introspector.getBeanInfo(User.class);
// 获取bean的属性(描述符)数组。将属性及其读写方法包装成描述符PropertyDescriptor,以数组形式返回
PropertyDescriptor[] descriptors = beanInfo.getPropertyDescriptors();
// 遍历bean的属性数组
for (PropertyDescriptor descriptor : descriptors) {
if (descriptor.getName().equals("name")) {
Method writeMethod = descriptor.getWriteMethod();
writeMethod.invoke(user, "Yoke");
Method readMethod = descriptor.getReadMethod();
Object o = readMethod.invoke(user);
System.out.println("修改之后的名字是: " + o);
}
}
} catch(Exception e) {
e.printStackTrace();
}
}
}
mybatis、spring也是基于javabean规范解析java类的。在使用mybatis配置映射关系时,可以看到同数据库"列"对应的是“属性”
<id property="id" column="author_id"/>fastjson等框架通过识别get/set开头的方法来识别属性。曾经使用eclipse自动生成的getter/setter方法有bug:有些方法没有严格按get/set+驼峰式命名生成,导致fastjson无法识别属性,产生bug。
因此,get/set方法才是判断属性的依据,属性 != 成员变量。一个成员变量没有getter/setter,就不会被遵循bean规范的工具识别为属性;而反过来,有时想要实现一个属性,不一定要定义成员变量:只要有“set属性名/get属性名”这样的方法,就足以被基于bean的工具识别为属性了。
- 写一个没变量的例子试试
规范的getter/setter是面向对象编程中“封装”这一抽象概念的具体案例,使组件具有更高的可重用性和安全性。
而序列化是为了:持久化是为了保存组件的属性状态,以及通过网络传输在其他地方复现组件的状态等。
比起让调用方直接更改某个public属性,get/set方法封装好正确的使用方式,或是使属性只读。曾经很多人学习面向对象开发时,只学到了抽象的“封装”与隐藏概念,而javabean就是封装的一个具体实现方式:调用方知道属性(公有的方法),却不知道有什么变量。一些内部仅用于计算的私有成员变量没必要作为属性暴露给外边。
现在的javaBean似乎逐渐演变成了是只有属性,没有业务逻辑的。原来的应该是没提吧
<jsp:useBean id="students" class="com.runoob.StudentsBean">
<jsp:setProperty name="students" property="firstName" value="小强"/>
<jsp:setProperty name="students" property="lastName" value="王"/>
<jsp:setProperty name="students" property="age" value="10"/>
jsp:useBean>
补充
- boolean类型字段的读方法(getter)一般命名为isXyz():
阿里开发规范中专门提到,一些以javaBean为规范来解析类的框架/模板引擎(如FastJson,读取方法名来匹配生成的JSON对象的键名),会将isXXX()方法的对应属性解析成XXX而不是isXXX;因此boolean属性的属性名名不能以is开头,其setter可以以is开头并且会被框架正确解析;
咱总不能属性名为isXXX,然后方法名为isIsXXX吧哈哈哈
- 只有getter的属性称为只读属性(read-only)。在甲骨文的官网教程中,还有一些现在不怎么提到的属性类型,比如带属性更改监听Listener的绑定属性。
- JavaBean的命名和设计理念在很大程度上受到了Smalltalk编程语言的对象的影响。
- @过时: Javabean不是JAVAEE规范之一,企业级的EJB Enterprise JavaBeans 才是。 JavaBean作为一种组件模型,可以和其他组件模型(如EJB)一起使用,被广泛地应用于各种Java应用程序的开发中。
- java标准包中beans包。其中的一些方法是GUI时代使用的,比如属性更改监听器。类似MVVM的思想?
javabean的历史
最初在1996年由Sun Microsystems提出。JavaBeans的目的是为了方便Java程序员编写可重用的组件,这些组件可以在不同的环境中移植和使用。
JavaBeans是许多Java开发平台的GUI的核心,如Eclipse、NetBeans和JBoss等。它们使用JavaBeans模型来让开发人员创建可重用的组件,可以通过组件容器来部署和使用。在JavaBeans规范中,使用了一些新的关键字和注释来标记组件的属性、事件和方法,这使得Java平台上的组件化开发变得更加简单和标准化。
如上文所述,javaBean最早主要作为GUI组件,类似于现在的前端组件或者桌面开发中的"控件"。
- Com
待定
mvc中的model可以用javabean,那里似乎(?)说javabean是要包含数据和行为;在三层架构中,被拆成了service;那么看来,本来的javabean带业务,所以也有用setter/getter里写写东西搞控制的说法?但是后来被拆分了?
Spring bean
概念2
在Spring中,构成你的应用程序的骨干并由Spring IoC容器管理的对象被称为Bean。Bean是一个由Spring IoC容器实例化、组装和管理的对象。否则,Bean只是你的应用程序中众多对象中的一个。Bean以及它们之间的依赖关系都反映在容器使用的配置元数据中。
org.springframework.beans 包遵守 JavaBeans 标准。JavaBean是一个具有默认无参数构造函数的类,它遵循一个命名惯例(getters/setters)
具有默认无参构造函数可方便Spring等使用者新建一个对象,而不用去记忆应当如何向构造函数中传参数。如果想设置某个属性,应使用set方法
SpringBean除了遵循JavaBean规范,在容器本身中,这些Bean定义被表示为 BeanDefinition 对象,还具有一些Spring要用到的元数据:
- 一个全路径类名:通常,被定义的Bean的实际实现类。
- Bean的行为配置元素,它说明了Bean在容器中的行为方式(scope、生命周期回调,等等)。
- 对其他Bean的引用,这些Bean需要做它的工作。这些引用也被称为合作者或依赖。
- 要在新创建的对象中设置的其他配置设置—例如,pool的大小限制或在管理连接池的Bean中使用的连接数。
Bean定义:用xml或注解(@Configuration, @Bean, @Import等)来配置一个SpringBean。
*组件定义(创建类)定义了组件有哪些属性等;Spring的Bean定义xml或注解关联了对应的类、注入的依赖等 *
当你创建一个Bean定义(definition)时,你创建了一个“配方”,用于创建该Bean定义(definition)是所定义的类的实际实例。Bean定义是一个“配方”的想法很重要,因为它意味着,就像一个类一样,你可以从一个“配方”中创建许多对象实例。
JavaEE JakartaEE开发
1999年,jdk1.2年代,java分出三个版本,其中企业平台(主要用于服务端)的J2EE后来演变为javaEE->jakartaEE(由eclipse基金会接手)
javaEE需要EE环境,如eclipse基金会的GlassFish。完整的JavaEE环境的实现集web容器、EJB容器、依赖注入等于一身,十分重量级。
对现在的程序员来说,其用法类似spring(依赖注入、控制反转、组件容器)和tomcat(web服务器、servlet容器),但其实是spring以更好的方法实现功能,javaEE也互相学习的结果。spring由公司Pivotal支持(该公司也参与过12年左右的12306研发),且改进和提升新功能更快,现在也实现了一些EE规范,如SpringJPA;但spring不实现EE的组件容器,spring使用tomcat\jboss或者他们的servletAPI等来实现javaEE应用。
现在EE甚至提供了类似spingboot起始页的脚手架网站:https://start.jakarta.ee/。下载后可以打包成War包运行在JavaEE容器如Eclipse GlassFish中,或是直接打包运行在docker中。
如果添加Embedded Eclipse GlassFish依赖来使用嵌入式的GlassFish,可以像springboot使用嵌入式tomcat一样,不用在本地单独安装GlassFish环境。
当然就算不使用一套EE,我们也经常单独引入其部分环境,如serveltAPI,javaMail。这种使用部分依赖的方式是最常见的,也可以同spring结合使用。
问:VO called View Object, and also called as Value Object. what is the difference between they, or they just are two names for the same thing.
答:Yes, you are correct. VO is short for View Object and Value Object. They are two names for the same thing. A View Object is an object that represents the data that will be displayed in the user interface. A Value Object is an object that represents a descriptive aspect of the domain with no conceptual identity. Its identity is based on its state rather than on its object identity and is immutable.
answer from New Bing.
Value Object翻译: "Value Object”是指代表领域中的描述性方面的对象,没有概念上的身份。它的身份基于其状态而不是其对象身份,并且是不可变的。
EJB
早期EJB和现在的有很大区别;根据百度百科,从EJB 3.0规范(JSR 220)开始为了迎合这个趋势相比于其前辈进行了一次激进的大跳跃。受到Spring 影响,EJB 3.0也使用所谓的“传统简单Java对象(POJO)”;同时,支持依赖注入来简化全异系统的集成与配置。Hibernate的创始人Gavin King参与了这一新版规范的制订,并对EJB大加提倡。Hibernate的许多特性也被引入到Java持久化API当中,从而取代原来的实体bean。EJB 3.0规范大幅采用Java注释(annotation)来对代码进行元数据修饰,从而消减了此前EJB编程的冗杂性。
相应地,EJB 3.0几乎成为了一个全新的API,与此前的数版可谓毫无相似度可言 3。
- 为什么spring想到用pojo?
- 这只是注解模式的胜利吗?
EJB是一个封装了业务逻辑的服务端组件
EJB 容器提供了 为企业 Bean 提供系统级服务,Bean 开发人员可以 专注于解决业务问题。EJB 容器,而不是 Bean 开发人员负责系统级服务,例如 事务管理和安全授权。
这么看来,EJB相当于一个大而全的框架。
- 单EJB就相当于重量级spring或者py中的django?那EE呢?
同客户端的javaBean相比(平常说的javaBean?),EJB包含业务逻辑(这么说javaBean又不包含了?) - business logic 与 service
两种EJB
| session 会话 | 为客户端执行任务;也可以实现web服务 |
| Message-driven | 充当特定消息传递类型的侦听器, 例如 Java Message Service API |
Session 会话bean
会话 Bean 封装了可以调用的业务逻辑,可以被远程调用。
客户端调用会话 Bean 的方法,然后服务器上的(Session Bean?应用程序?)为本地执行复杂的业务逻辑
看起来像是员远程程序在本地的接口、句柄之类的。dubbo等微服务也是代码实现在远程,本地调用某个组件的方法来通知服务(service)运行;
使用上也类似本地客户端MVC案例中,controller把view和model当作自己的成员直接调用他们的方法。也许我应该把他们仨放一个视图里
这有些view和service分离的意思
Session Bean不持久化。
三种类型:
- 有状态 Stateful Session Beans
- 无状态 Stateless Session Beans
- 单例 Singleton Session Beans
Message-driven Bean
消息驱动的 Bean 是 用于异步处理消息的应用程序。通常充当 JMS 消息侦听器,类似于事件 侦听器,但接收的是 JMS 消息而不是Event。可以处理 JMS 消息或其他类型的消息。
消息驱动的 Bean 和会话之间最明显的区别 Bean 是客户端不通过 接口。
当消息到达时,容器会调用消息驱动的 Bean 的onMessage方法来处理消息。JavaEE?为其封装了事务和回滚机制。
客户端访问 Session Bean
客户端通过buiness Interface或者无接口视图( no-interface views)访问Session Bean
Message-driven Bean没有这俩东西
业务接口buiness Interface方式就是标准的java Interface。(像微服务那种通过接口调用(写好对应方法的?我记得也有光名字的。另外这种方式是不是形成了两边共同以来service包的项目结构?))
企业bean的无接口视图只暴露公有方法的方式让客户端调用。
看到这儿反而理解什么是接口了,是不是对使用者来说是接口。话说真有先定接口一起开发的么
封装与隐藏,,哈。虽然对OOP初学者来讲可能用spring案例更好些,毕竟EJB用家少
然后原文就是分层/CS架构隔离的那种布拉布拉,隔离客户端和企业bean什么的好处之云
在客户机中使用企业 Bean
客户端获取一个企业bean的实例的方法:
- 依赖注入
- Java注解
- JNDI lookup, using the Java Naming and Directory Interface Java命名和目录接口语法
- 注解和依赖注入是两种?
依赖注入是获取企业 Bean 的最简单方法 参考。在 Java EE 服务器管理的环境中运行的客户机, JavaServer Faces Web 应用程序、JAX-RS Web Service、其他企业 Bean 或 Java EE 应用程序客户机支持通过注解@EJB实现依赖注入
在 Java EE 服务器管理的环境之外运行的应用程序,例如 作为 Java SE 应用程序,必须执行显式查找。JNDI 支持 用于标识 Java EE 组件的全局语法,以简化此操作 显式查找。
Create an enterprise bean implementation class that does not implement a business interface, indicating that the bean exposes a no-interface view to clients. For example:
@Session
public class MyBean { … }
Annotate the business interface of the enterprise bean as a interface. For example:@Local
@Local
public interface InterfaceName { … }
Specify the interface by decorating the bean class with and specify the interface name. For example:@Local
@Local(InterfaceName.class)
public class BeanName implements InterfaceName { … }
远程:
@Remote
public interface InterfaceName { … }
POJO
Plain Old Java Object是一种使用最简单的Java对象来表达轻量级域模型的编程风格。
POJO是MartinFowler等人发明的一个术语,用来表示普通的Java对象。
在那次谈话中我们指出将业务逻辑(business logic)写进常规(regular)Java对象而不是使用Entity Beans的好处。我们疑惑为什么人们不喜欢在他们的系统中使用普通的对象,得到的结论是——普通的对象缺少一个响亮的名字。因此我们起了一个名字,并且取得了很好的效果。——Martin Fowler,20004
此句中的POJO特征:相对于JavaEE中EJB相关概念Entity Beans诞生,与EJB一样负责业务逻辑,
但是不用像EJB一样需要强制实现接口、重写方法等麻烦事。
纯粹(pure,plain)、普通、常规(ordinary,regular)、老式(old):相对于EJB1、2之流一定要实现接口而言(2000年只需要注解的EJB3还没有出现,但spring已经出现,需考察早期spring与pojo)。因此有人说“POJO是不强制实现任何特殊的Java框架的接口的类”,但这只是对pojo特征之一的抽象描述,而没有考虑到pojo的提出背景。这些做减法的概念做下来,我们发现只要用JavaSE的基础语法写个实现业务逻辑的类就是pojo了。起名为“POJO”只是为了强调这一点
POJO一词的考证和演化极为困难,同javabean不同,没有官方下场维护POJO定义,POJO的意思意思又经历了演变。可以说这个词被“污染”的极其严重。
其他类似的描述都是这个意思:
POJO包含业务逻辑或持久逻辑等,但不是JavaBean, EntityBean 或者 企业Bean(这些都指java官方定义的规范)。POJO不担当任何特殊的角色,也不实现任何特殊的Java框架的接口如,EJB, JDBC等等。(一说为不强制要求继承,而且也不要求注解)
但是如果说“pojo与数据库一一对应被orm使用”,我们发现orm如hibernate需要添加注解
而另一些描述:pojo只有getter/setter,pojo 和orm对应,应该是后来pojo概念演化后,又再次被抽象某些特征描述。
- 提出的时候是不是没想到注解,注解不用实现方法,即使生命周期方法?
- 同前端javabean都要考虑的一个问题:为什么业务逻辑在后端,这应该就是“有没有业务逻辑”的讨论,因为前端javabean在前端,pojo提出时可以又业务逻辑,所以在后端
看起来MF最初的意思可能是写业务逻辑的,是作为服务端bean让前端直接调用吗?那他怎么解决远程调用问题?还是说存在大量本地用EJB的,管理不如直接调用?,,,怎么后来又变了
- 那这段时间的Spring怎么想到的用pojo?hibernate怎么定义领域对象?
- servelt也是这么麻烦,我记得Web在EE是EJB2.X支持的?但web不用applet、javaclient的话,怎么用浏览器调用远程业务逻辑?两个EJB中又是怎么调用的远程逻辑?不是现在的微服务
- 领域这种思想范围比pojo这种只有java的概念大
- spring比起buiniss logic,似乎用了@Service。是面向服务,还是为了包装业务逻辑?
- EJB是为了什么让业务逻辑放服务器?前端javaBean组件不用业务逻辑是为了视图层方便通用吗?
- 进一步想,是不是COA的思想组件就不应有专业的业务逻辑?业务逻辑一定专业话吗?毕竟事务之类的框架支持了
- 为什么高级语言的se版本都不直接把企业给支持了?什么是高级语言的最低标准,调用计算机?
- pojo分类哪里提出的?
- 充血模型与贫血模型与pojo运动
但相处久了就不爱了,程序员们渐渐发现,EJB虽然非常强大,但是使用起来太麻烦,编程的过程很重,并不轻量级。比如:

再比如:在实例等的继承上并不便捷,很多已经有的实例需要重新定义 等等。
程序员们说:我就想更多的focus on业务逻辑,这些开发环境和开发过程的问题能不能不要烦我。
于是大家发起了一场名为POJO的运动(Plain Ordinary Java Object / Pure Old Java Object即“普通Java对象”),这种精简、纯粹的Java对象编写方式称为POJO。
2005年一个叫 Rod Johnson的大牛(他实际上是音乐学博士,牛人一般可能都“不务正业”),推出了一个叫做spring的开发框架,在这套框架下,编写Java程序是满足POJO的极简风格的,所以大受欢迎。
他出过一本书《Expert one on one J2EE development without EJB》,要开发企业级程序without EJB,可以看出他的野心。
另外,spring可以方便的对接很多其他处理框架,比如对接更为方便的数据库处理框架:Hiberate(想起了自己当年的本科毕设)等等。
总之,这样一个spring框架真的帮助程序员们又一次脱离了苦海。虽然后来EJB也在简化开发风格,但是被spring框架拉走的程序员越来越多。
阿里Java开发手册中,也不建议在POJO的setter中添加业务逻辑,主要是为了方便debug,不需要操心setter的内部逻辑了,把业务逻辑限制在业务层范围内。(这里是结合了分层架构的思想)
那么这里就混淆了似乎,不让pojo写业务逻辑了
博主们常说POJO可分为DO / DTO / BO / VO 等。但如果早期pojo运动提到过拓展的话,更严谨的说法不是“分为了”各种对象,而是pojo因其简单而方便“拓展为”各类对象。
阿里Java开发规范:
-
DO(Data Object)/PO(Persistent Object):和数据库表一 一对应,通过数据层(DAO)向上传输数据源对象。
-
DTO(Data Transfer Object ):数据传输对象,Service或Manager向外传输的对象。
- Data Transfer Object(数据传输对象):在进程间进行数据传递的对象,目的是减少进程间方法调用的次数。《企业应用架构模式》
-
BO(Business Object):业务对象,可以由Service层输出的封装业务逻辑的对象。
-
Query:数据查询对象,各层接收上层的查询请求。注意超过2个参数的查询封装,禁止使用Map类来传输。
-
VO(View Object):显示层对象,通常是Web向模板渲染引擎层传输的对象。??输出这玩意儿?业务逻辑?怎么不直接service服务做业务逻辑
-
Value Object,有的也称为View Object,即值对象或页面对象。一般用于web层向view层封装并提供需要展现的数据。
PO是由Hibernate纳入其实体容器(Entity Map)的对象,它代表了与数据库中某条记录对应的Hibernate实体,PO的变化在事务提交时将反应到实际数据库中。如果一个PO与Session对应的实体容器中分离(如Session关闭后的PO),那么此时,它又会变成一个VO。
由Hibernate VO和Hibernate PO的概念,又引申出一些系统层次设计方面的问题。如在传统的MVC架构中,位于Model层的PO,是否允许被传递到其他层面。由于PO的更新最终将被映射到实际数据库中,如果PO在其他层面(如View层)发生了变动,那么可能会对Model 层造成意想不到的破坏。
因此,一般而言,应该避免直接PO传递到系统中的其他层面,一种解决办法是,通过一个VO,通过属性复制使其具备与PO相同属性值,并以其为传输媒质(实际上,这个VO被用作Data Transfer Object,即所谓的DTO),将此VO传递给其他层面以实现必须的数据传送。
————————————————
版权声明:本文为CSDN博主「true…」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhanxxiao/article/details/109349444
具体怎么使用,公司约定大于其定义,这里仅供参考。比如,在列表页中的VO要被EasyExcel导出成excel,那么这个导出类要直接复用VO吗?看公司习惯如何来决定。
一个是阿里巴巴的开发手册中的定义
DO( Data Object)这个等同于上面的PO
另一个是在DDD(Domain-Driven Design)领域驱动设计中
DO(Domain Object)这个等同于上面的BO
- idea连接数据库后标记的persistence对象
POJO—单数据库实体类5
EJB–多数据库,远程实体,复杂应用
POJO 简单理解为 不包含业务逻辑的单纯用来存储数据的 java类即可。
实际就是普通JavaBeans,是为了避免和EJB混淆所创造的简称
当然,如果你有一个简单的运算属性也是可以的,但不允许有业务方法,也不能携带有connection之类的方法。
POJO是Plain Ordinary Java Objects的缩写不错,但是它通指没有使用Entity Beans的普通java对象,可以把POJO作为支持业务逻辑的协助类。
POJO对象有时也被称为Data对象,大量应用于表现现实中的对象。
个人总结:
同javabean类似,pojo是一种规范,而不是编译器语法检查;
同javabean不同,pojo没有任何官方组织下场维护规范,并证明自己的权威,导致如今溯源麻烦
so DTO转VO这种pojo之间的转换,,最佳实践是什么,,或者好一些的实践
vo只留前端用的字段
有的字段太大会导致报文too large
上次说的那种,数据库里int表示状态,前端用字符串的,转换成String这一步你们是是转VO时干,还是字典也发到前端让前端干
后端干
比如长的数据long直接给前端
数字类型的json
会丢精度
问:VO called View Object, and also called as Value Object. what is the difference between they, or they just are two names for the same thing.
答:Yes, you are correct. VO is short for View Object and Value Object. They are two names for the same thing. A View Object is an object that represents the data that will be displayed in the user interface. A Value Object is an object that represents a descriptive aspect of the domain with no conceptual identity. Its identity is based on its state rather than on its object identity and is immutable.
answer from New Bing.
Value Object翻译: "Value Object”是指代表领域中的描述性方面的对象,没有概念上的身份。它的身份基于其状态而不是其对象身份,并且是不可变的。
MVC中的Model
数据库概念
控件
学习顺序:
mvvm:view和数据直接关联
query:业务层直接传到数据层查询
DTO:查完了直接传回去
COM
面向对象语言方便创建com?rust go python?
Microsoft 组件对象模型 (COM) 是一个独立于平台的分布式面向对象的系统,用于创建可以交互的二进制软件组件。 COM 是 Microsoft 的 OLE (复合文档的基础技术,) 、ActiveX (支持 Internet 的组件) 以及其他组件。
- 这是CBA在分布式上的实践?类似EJB?
- 微服务怎么就更合适分布式了感觉,服务直接成了分布式。组件分布式就这里这俩
- 通过使用 CoCreateGuid 函数或 COM 创作工具(例如在内部调用此函数的 Visual Studio)获取新的 CLSID。 这个有些像SerialID?
DDD
Domain Model(领域模型):既包含行为,又包含数据的领域的对象模型。
领域模型创建了一张由互联对象组成的网,其中的每一个对象都代表某个有意义的个体,可能大到一个公司或者小到订单中的一行。
领域模型衍生出两种风格。简单领域模型看起来与数据库设计很类似,这种设计中几乎每一个数据库表都与一个领域对象对应。而复杂领域模型则与数据库设计不同,它使用继承、策略和其他设计模式,是一张由互联的细粒度对象组成的复杂网络。复杂领域模型更适合于复杂的逻辑,但它到数据库的映射比较困难。简单领域模型可以使用活动记录,而复杂领域模型需要使用数据映射器。
— 《企业应用架构模式》
- domain的常量放在那里?pojo?
贫血模型
1.介绍
贫血模型是指领域对象里只有get和set方法(POJO),所有的业务逻辑都不包含在内而是放在Business Logic层。
2.优点
各层单向依赖,结构清楚,易于实现和维护。
设计简单易行,底层模型非常稳定。
3.缺点
domain object的部分比较紧密依赖的持久化domain logic被分离到Service层,显得不够OO。
应该是说数据 逻辑没封装所以不够OO把
Service层过于厚重。
4.代码样例
我们一般使用三层架构进行业务开发:
Repository + Entity
Service + BO(Business Object)
Controller + VO(View Object)
在三层架构业务开发中,大家经常使用基于贫血模型的开发模式。贫血模型是指业务逻辑全部放在service层,业务对象只包含数据不包含业务逻辑。
充血模型
1.介绍
充血模型是指数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格。
2.优点
面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重
3.缺点
缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。
那么切分的原则是什么呢:Rod Johnson提出原则是“case by case”,可重用度高的,和domain object状态密切关联的放在Domain Object中,可重用度低的,和domain object状态没有密切关联的放在Business Logic中。
经过上面的讨论,如何区分domain logic和business logic,我想提出一个改进的区分原则:domain logic只应该和这一个domain object的实例状态有关,而不应该和一批domain object的状态有关。
当你把一个logic放到domain object中以后,这个domain object应该仍然独立于持久层框架之外(Hibernate, JDO),这个domain object仍然可以脱离持久层框架进行单元测试,这个domain object仍然是一个完备的,自包含的,不依赖于外部环境的领域对象,这种情况下,这个logic才是domain logic。
4.代码样例
在基于充血模型DDD开发模式中我们引入了Domain层。Domain层包含了业务对象BO,但并不是仅仅包含数据,这一层也包含业务逻辑,我们来看代码实例。
三、对比分析
1.为什么基于贫血模型的传统开发模式如此受欢迎?
基于贫血模型的传统开发模式,将数据与业务逻辑分离,违反了 OOP 的封装特性,实际上是一种面向过程的编程风格。但是,现在几乎所有的 Web 项目,都是基于这种贫血模型的开发模式,甚至连 Java Spring 框架的官方 demo,都是按照这种开发模式来编写的。
面向过程编程风格有种种弊端,比如,数据和操作分离之后,数据本身的操作就不受限制了。任何代码都可以随意修改数据。既然基于贫血模型的这种传统开发模式是面向过程编程风格的,那它又为什么会被广大程序员所接受呢?关于这个问题,主要是有下面三点原因。
第一点原因是,大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于 SQL 的 CRUD 操作,所以,我们根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。除此之外,因为业务比较简单,即便我们使用充血模型,那模型本身包含的业务逻辑也并不会很多,设计出来的领域模型也会比较单薄,跟贫血模型差不多,没有太大意义。
第二点原因是,充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,我们只需要定义数据,之后有什么功能开发需求,我们就在 Service 层定义什么操作,不需要事先做太多设计。
第三点原因是,思维已固化,转型有成本。基于贫血模型的传统开发模式经历了这么多年,已经深得人心、习以为常。你随便问一个旁边的大龄同事,基本上他过往参与的所有 Web 项目应该都是基于这个开发模式的,而且也没有出过啥大问题。如果转向用充血模型、领域驱动设计,那势必有一定的学习成本、转型成本。很多人在没有遇到开发痛点的情况下,是不愿意做这件事情的。
2.什么项目应该考虑使用基于充血模型的 DDD 开发模式?
相对应的,基于充血模型的 DDD 开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统。
你可能会有一些疑问,这两种开发模式,落实到代码层面,区别不就是一个将业务逻辑放到 Service 类中,一个将业务逻辑放到 Domain 领域模型中吗?为什么基于贫血模型的传统开发模式,就不能应对复杂业务系统的开发?而基于充血模型的 DDD 开发模式就可以呢?
实际上,除了我们能看到的代码层面的区别之外(一个业务逻辑放到 Service 层,一个放到领域模型中),还有一个非常重要的区别,那就是两种不同的开发模式会导致不同的开发流程。基于充血模型的 DDD 开发模式的开发流程,在应对复杂业务系统的开发的时候更加有优势。为什么这么说呢?我们先来回忆一下,我们平时基于贫血模型的传统的开发模式,都是怎么实现一个功能需求的。
不夸张地讲,我们平时的开发,大部分都是 SQL 驱动(SQL-Driven)的开发模式。我们接到一个后端接口的开发需求的时候,就去看接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写 SQL 语句来获取数据。之后就是定义 Entity、BO、VO,然后模板式地往对应的 Repository、Service、Controller 类中添加代码。
业务逻辑包裹在一个大的 SQL 语句中,而 Service 层可以做的事情很少。SQL 都是针对特定的业务功能编写的,复用性差。当我要开发另一个业务功能的时候,只能重新写个满足新需求的 SQL 语句,这就可能导致各种长得差不多、区别很小的 SQL 语句满天飞。
所以,在这个过程中,很少有人会应用领域模型、OOP 的概念,也很少有代码复用意识。对于简单业务系统来说,这种开发方式问题不大。但对于复杂业务系统的开发来说,这样的开发方式会让代码越来越混乱,最终导致无法维护。
如果我们在项目中,应用基于充血模型的 DDD 的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,我们需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成。
————————————————
版权声明:本文为CSDN博主「、Dong」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
领域驱动模型中的domain
- 话说这样的分层考虑到程序员工作量分配了么?工作中的pm是怎么管pm分配的呢?还是说单纯假设会分开不同人?这个想法来自知乎评论区
- 事实上一个人实现一个小功能的话全部层都要实现,分层也可以被其他人复用,,,考虑这点,似乎不是为了分人而分层。
实体
package com.b2b.entity.admin.pms;
/**
* Entity基类
*
* @author ruoyi
*/
public class BaseEntity implements Serializable {
这个有起止时间,这是实体该干的事吗?
应该是数据库的概念,实体关系
DTO模式
使用 DTO 工厂
DTO 工厂可用于以一致且高效的方式创建 DTO。工厂也可用于在创建 DTO 之前验证数据。
参考
- EJB学习资源
- javaEE8API文档_EJB3.0
- javaEE8官网教程_创建EJB3.0
- Jakarta EE 教程_EJB 甚至这个访问更快
- EJB JSR规范:https://jcp.org/en/jsr/detail?id=220 更老版本的虽然sun公司网站已经不存在了,但可以从JSR上下载到文档
- @Component
- POJO对象有时也被称为Data对象,大量应用于表现现实中的对象。如果项目中使用了Hibernate框架,有一个关联的xml文件,使对象与数据库中的表对应,对象的属性与表中的字段相对应。–博客园
- rust python 组件模型
- 设计接口的时候想着大家按框架规矩走生命周期,没想到注解标注更方便?
- 那多态使用是接口的优势了?
oracle的JAVA Bean教程该教程基于GUI和开发工具NetBeans。这种GUI组件的概念类似“控件”,如Visual Basic中的控件。在现在专注于服务端、更抽象的服务端组件的应用场景下,该教程中的GUI案例仅作理解,明白bean就是容易复用的组件规范即可。 ↩︎
Spring中文网对于bean的介绍 ↩︎
王博, 陈莉君. JAVA BEAN的分析和应用[J]. 西安文理学院学报(自然科学版), 2008, 11(1):92-96. ↩︎
Martin Fowler在领域驱动设计、架构模式、敏捷开发和持续交付等领域享有盛誉。曾出版图书《重构:改善既有代码的设计》、《领域特定语言》、《企业应用架构模式》等。
“GUI Architectures” ↩︎https://bbs.csdn.net/topics/360238939 处大佬们的讨论 ↩︎