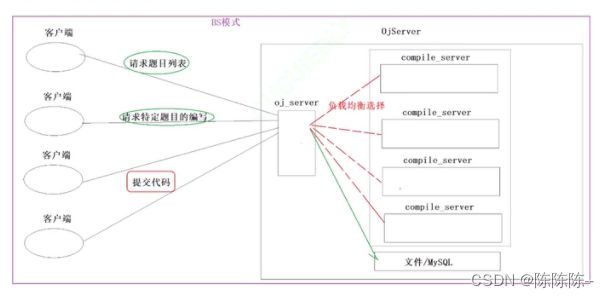
【负载均衡式在线OJ】负载均衡模块
文章目录
- 具体实现
-
- 20.引入httplib第三方库
-
- 安装cpp-httplib
- 21.将cr打包成为网络服务
- 22.使用postman进行综合测试:模拟用户输入的json串
- 23.oj_server准备工作
-
- > 1. 获取首页,用题目列表充当
- > 2. 编辑区域页面
- > 3. 提交判题功能(编译并运行)
- 采用MVC设计模式
- 24.编写oj_server的服务路由功能
- 25.建立文件版题库
-
- 设计题库:
- 26.构建model代码结构
- 27.编写model代码1(获取所有题目和获取1个题目)
- 28.编写model代码2(加载配置文件)
- 29.model添加日志
- 30.使用boost split字符串切分
-
- 安装boost库
- 31.编写control模块整体结构
- 32.引入ctemplate测试基本功能
-
- 数据渲染:
- 33.编写view模块整体代码结构
- 35.编写view获取指定题目功能
- 36.编写负载均衡模块代码整体结构
- 37.编写负载均衡器代码
- 38.编写judge功能1
-
- 0. 根据题目编号,直接拿到对应的题目细节
- 1. in_json进行反序列化,得到题目的id,得到用户提交源代码,input
- 2. 重新拼接用户代码+测试用例代码,形成新的代码
- 39.编写judge功能2
-
- 3.选择负载最低的主机(差错处理)
- 4. 然后发起http请求,得到结果
- 40.编写judge功能3
- 总结:
具体实现
20.引入httplib第三方库
接入网络服务,自己写套接字太慢了,所以使用一个第三方库、
安装cpp-httplib


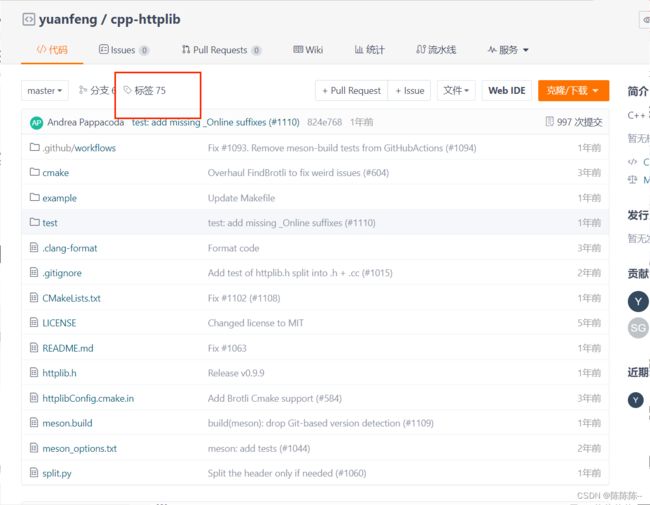


当把第三方库下载好之后
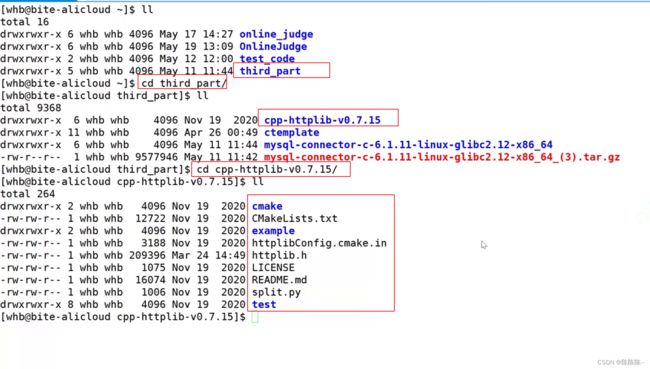
用XFTP将cpp-httplib库导入即可

将库中的httplib.h拷贝到项目中,即可直接使用

需要升级GCC版本到高版本,建议 gcc 7,需要使用高版本的gcc,建议是gcc 7,8,9 [如果没有升级,cpp-httplib:要么就是编译报错,要么就是运行出错。
百度搜索:scl gcc devsettool升级gcc
//安装scl
$ sudo yum install centos-release-scl scl-utils-build
//安装新版本gcc,这里也可以把7换成8或者9,我用的是9,也可以都安装
$ sudo yum install -y devtoolset-7-gcc devtoolset-7-gcc-c++
$ ls /opt/rh/
//启动: 细节,命令行启动只能在本会话有效
$ scl enable devtoolset-7 bash
$ gcc -v

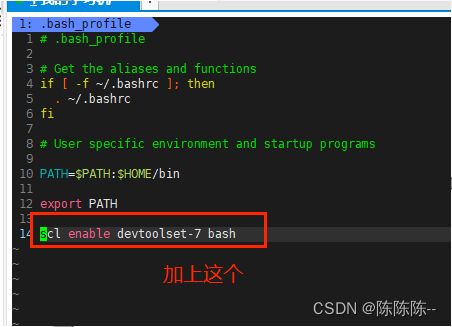
准备工作准备完毕,下面正式开始

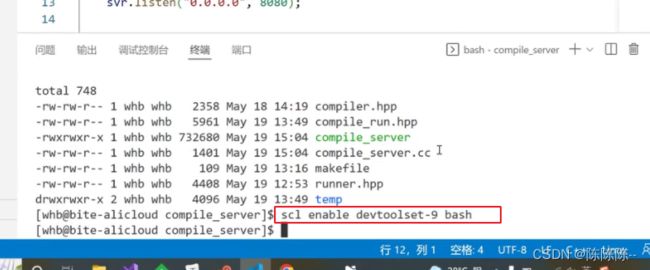
环境没更新,在vscode里面更新一下gcc版本

如果想让这个库在自己的项目中使用,直接包含库的定义,然后Server svr , svr.listen( )即可正常使用,启动http服务;但是现在启动之后什么内容也没有,所以需要绑定一些服务。
当用户请求(&req里面的json串)到来时,请求svr.Get里面的服务(第一个参数)时,就返回&resp里面的内容
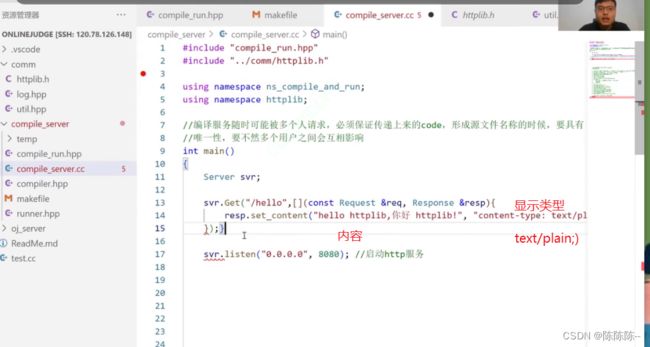
报错:偶发性错误,把vscode关掉重新打开

在我们这个项目里面:当用户请求(&req里面的json串)到来时,请求svr.Get里面的服务(第一个参数)时,通过我们的compile_run生成一个json串,再返回这个json串里面的内容
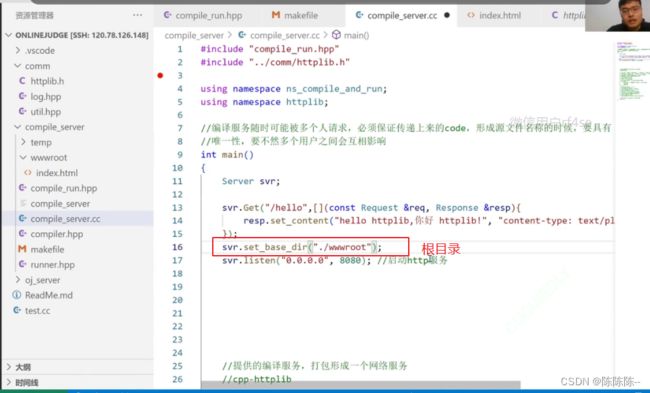
新建一个wwwroot文件夹(仅仅做测试,相当于compile_server的根目录 ),在里面建一个index.html文件
有了根目录之后再调用surver就有了明显的效果
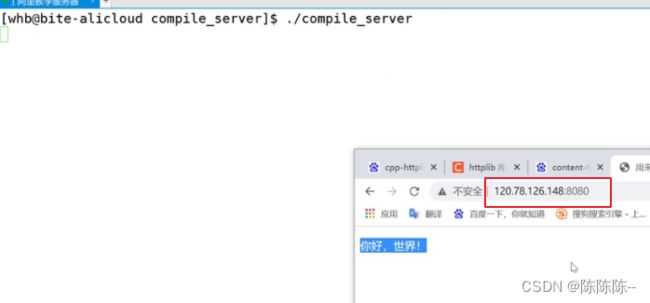
上面只是一个测试,我们这个项目不需要显示页面,只需要把用户输入的json串编译并运行,然后输出json串
21.将cr打包成为网络服务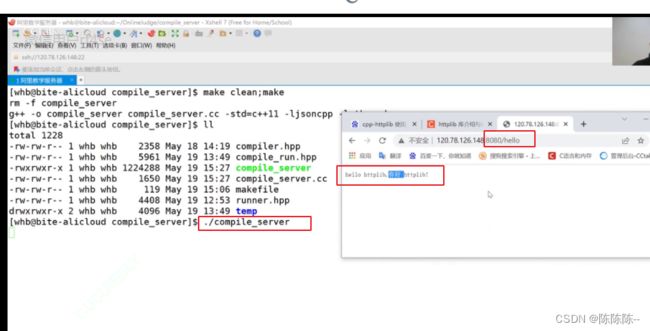
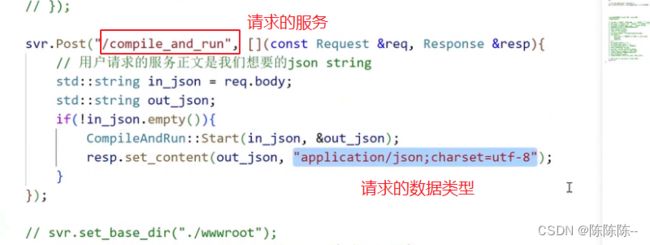
打包一个服务:用户请求的服务是compile_and_run
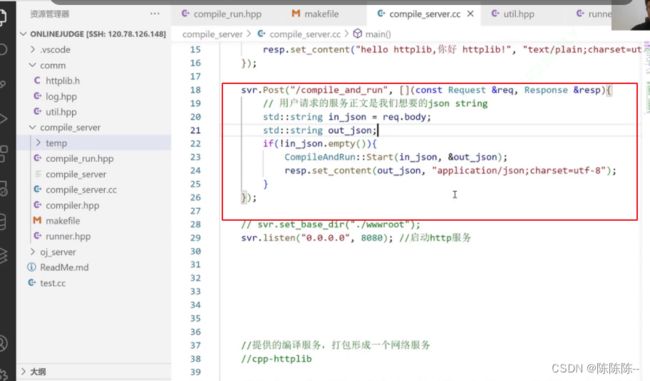
22.使用postman进行综合测试:模拟用户输入的json串
目前没有用户请求json串,因此先用postman可以模拟一个用户请求json串

把测试跑起来
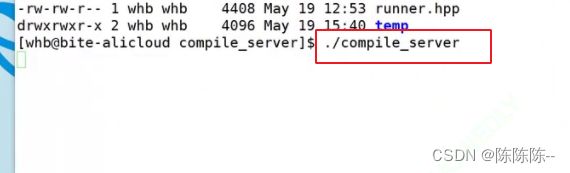
然后启动postman

然后就可以输入json串了
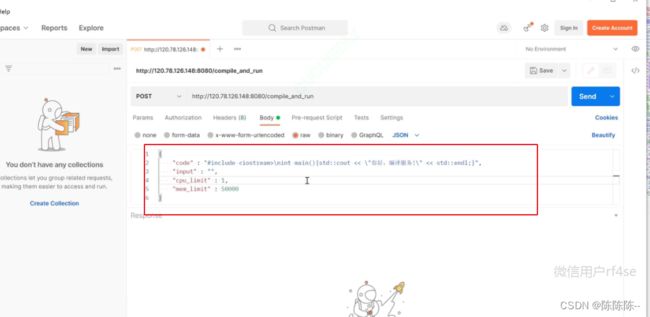
send之后

继续测试:死循环

我们的compile_server需要多主机部署,所以要暴露其端口号

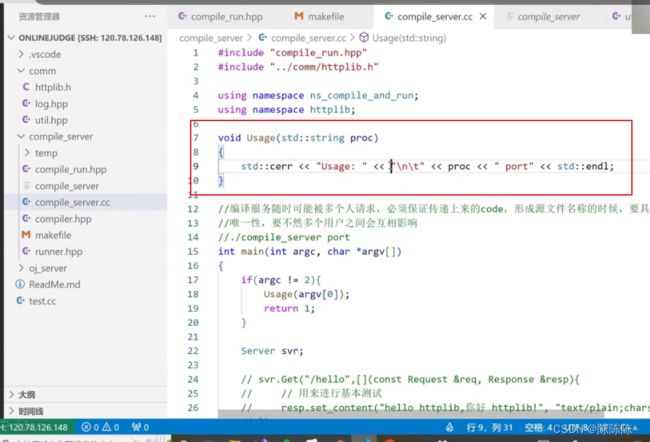
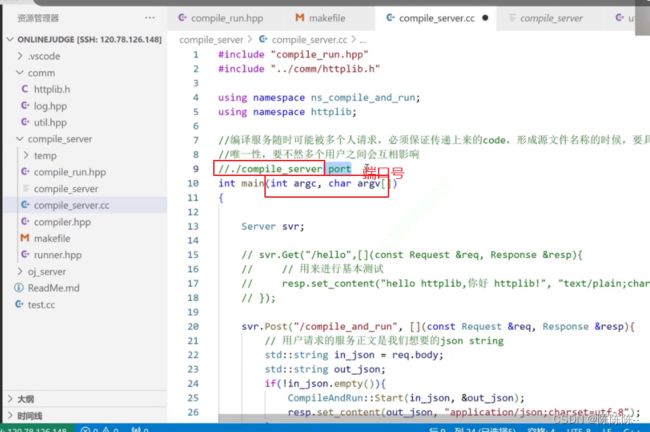 atoi(argv[1])是将argv[1]转为整数
atoi(argv[1])是将argv[1]转为整数

以上就完成了编译服务,下面是建立一个小型的网站
23.oj_server准备工作
本质:建立一个小型网站
> 1. 获取首页,用题目列表充当
> 2. 编辑区域页面
> 3. 提交判题功能(编译并运行)
采用MVC设计模式
M: Model,通常是和数据交互的模块,比如,对题库进行增删改查(文件版,MySQL)
V: view,视图,通常是拿到数据之后,要进行构建网页,渲染网页内容,展示给用户的(浏览器)
C: control, 控制器,就是我们的核心业务逻辑
oj_server用于负载均衡式的调用compile_server


升级一下gcc
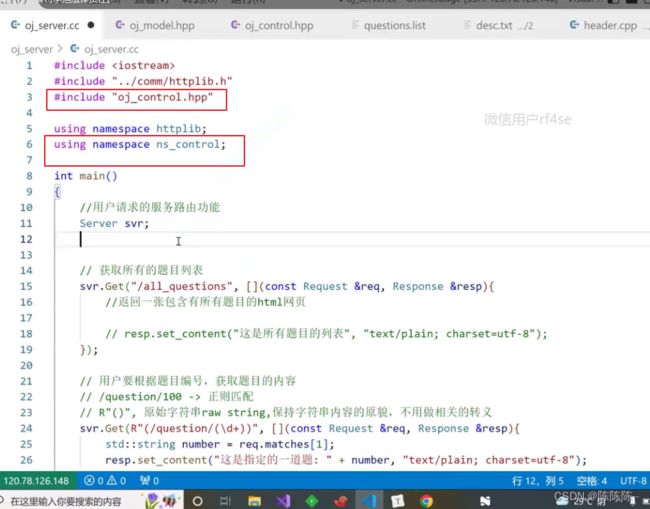
24.编写oj_server的服务路由功能
根据用户的不同需求,给用户展示不同的内容
- 获取所有的题目列表
- 用户要根据题目编号,获取题目的内容
- 用户提交代码,使用我们的判题功能(1. 每道题的测试用例 2. compile_and_run)
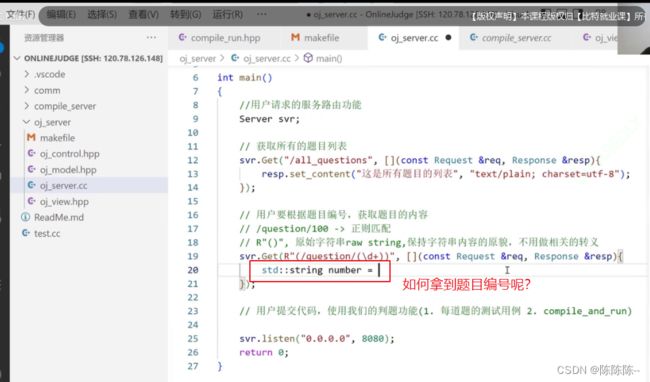
1.获取所有的题目列表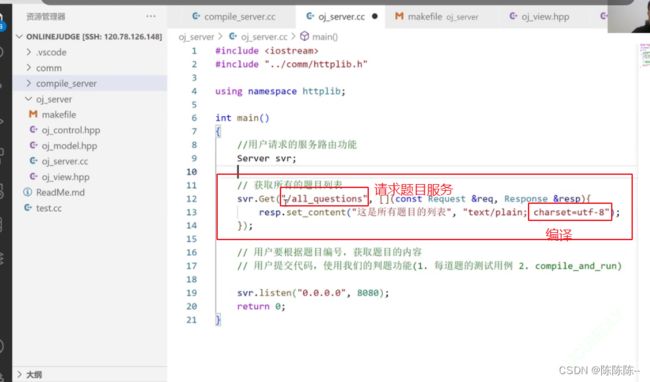
2.用户要根据题目编号,获取题目的内容



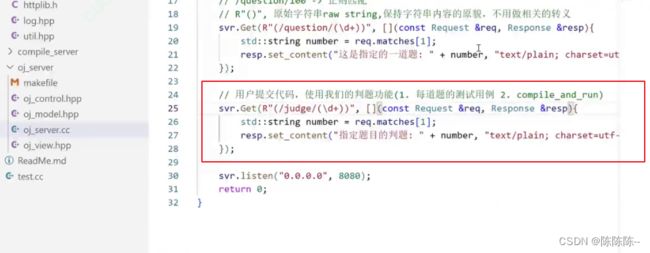
3.判题:用户提交代码,使用我们的判题功能(1. 每道题的测试用例 2. compile_and_run)
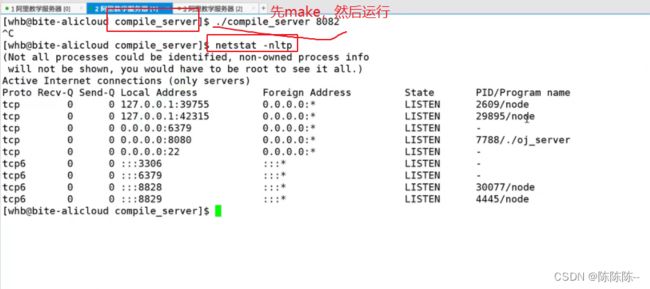
可以看到有一个oj_server绑定了端口号8080
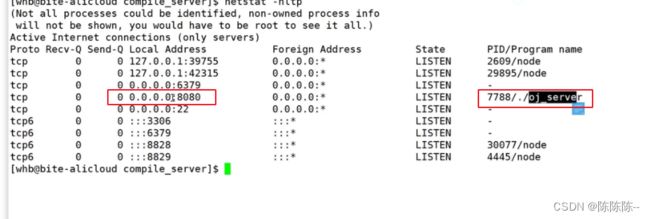
简单检查:
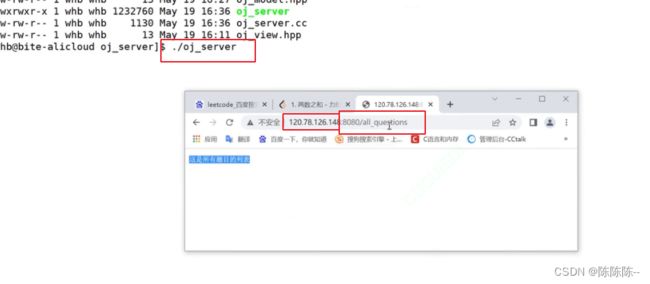
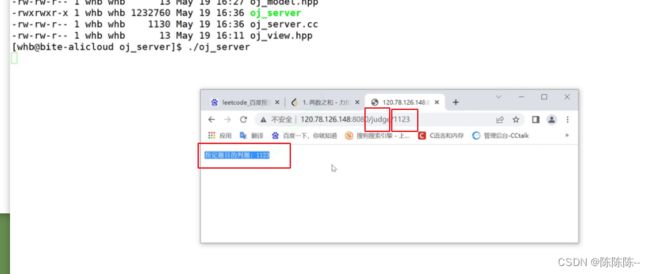
但是我们没有首页,可以写一个简单的首页
添加一个www.root
设置首页默认在www.root目录下

25.建立文件版题库
设计题库:
首先要告诉我们题目在哪里(questions)

题目编号,唯一
题目的标题
题目的难度
题目的描述,题面
题目的时间要求(内部处理)(S)
题目的空间要去(内部处理)(KB)
另外,当我们在oj列表找题目的时候,只有题目标题,点进去才有内容
两批文件构成
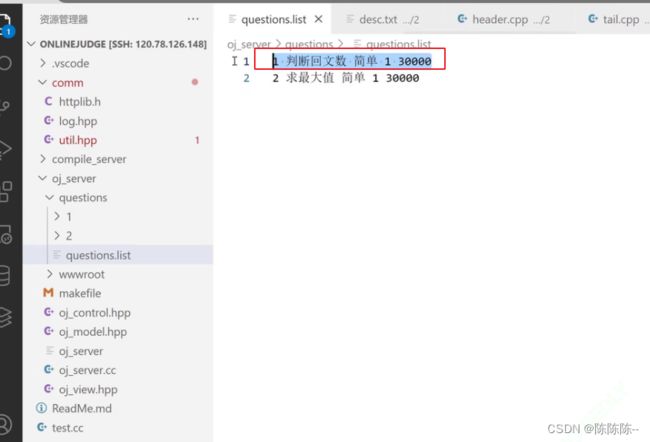
- 第一个:questions.list : 题目列表(不需要题目的内容)
- 第二个:题目的描述,题目的预设置代码(header.cpp), 测试用例代码(tail.cpp)
这两个内容是通过题目的编号,产生关联的
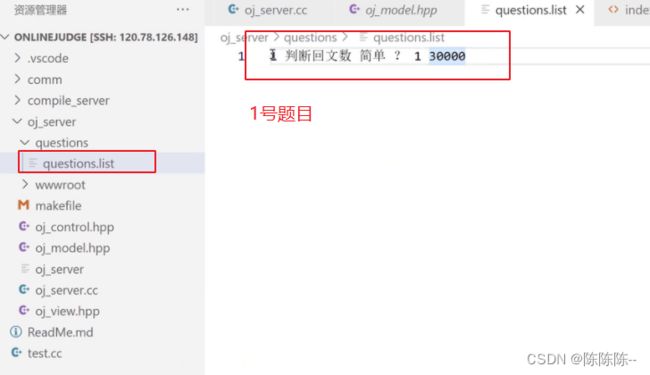
如果questions.list中只有一个题目,那么questions文件夹下就只有一个以题目编号命名的文件夹(questions.list中包括题号,题目,难度, ,时间复杂度,空间复杂度(图中是30M))
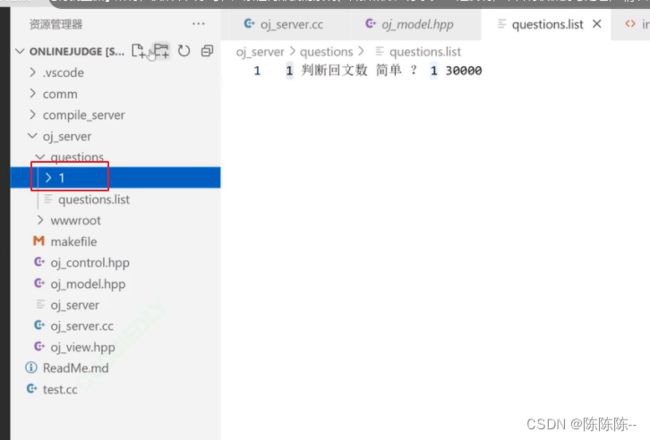
再新建两个文件:文件描述和预设代码
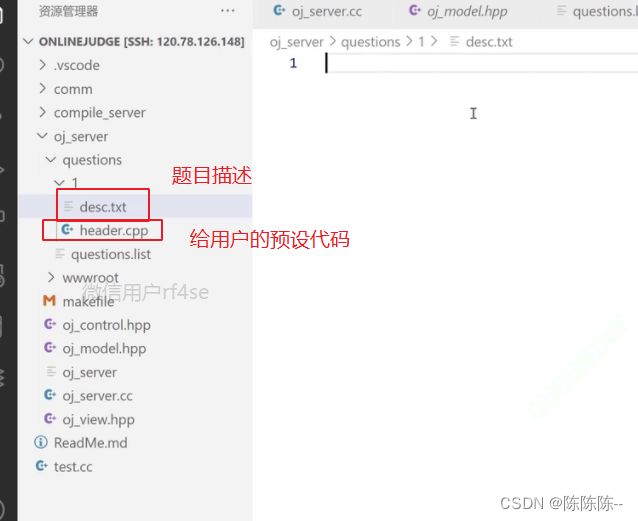
预设代码:
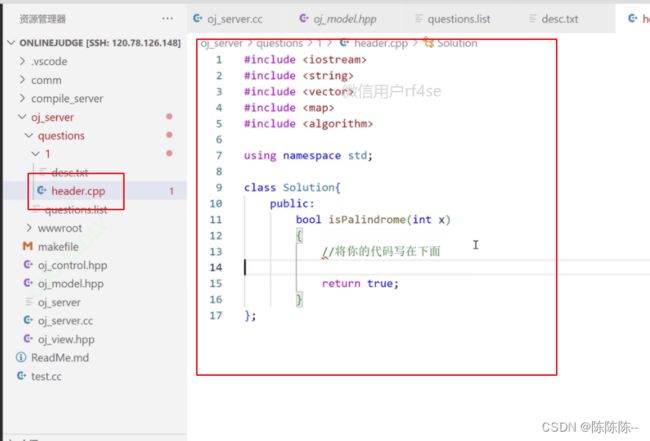
用户输入代码后,你怎么知道是否正确呢》所以需要测试用例模块,新建文件tail.cpp
下图可以实现
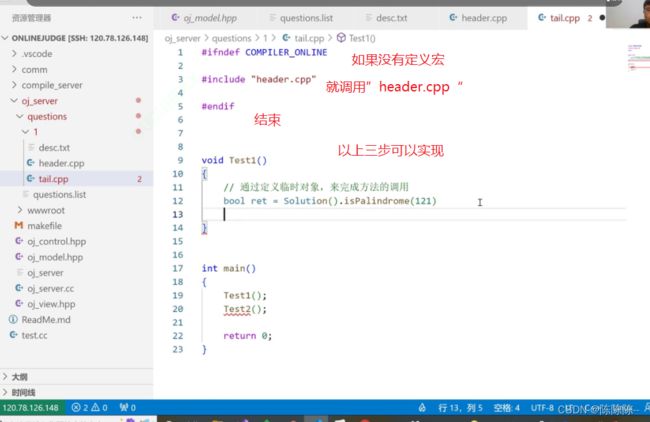
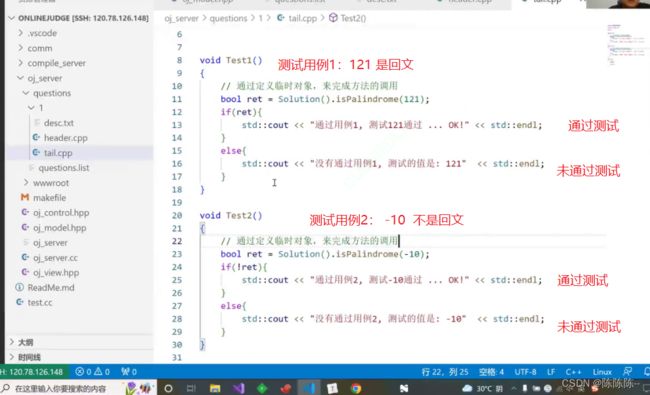
因此,最终提交给后台进行编译的代码是header.cpp + tail.cpp的一份完整的代码,让后端进行运行,运行的时候就开始编译-运行-链接,运行的所有结果最终会输出到stdout文件,以json的形式返回给我,所以它到底通过了几个测试用例,把通过测试用例的个数直接返回给客户端
即完成了判题的功能
#include 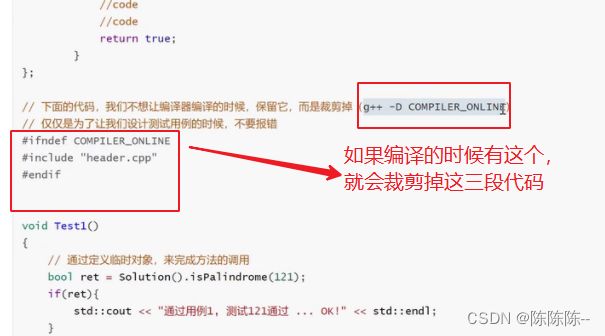
新增题目:

desc.txt
 header.cpp
header.cpp

tail.cpp
添加完毕!
下面需要完成的内容:
1.加载所有的题目
2.加载单个题目
26.构建model代码结构
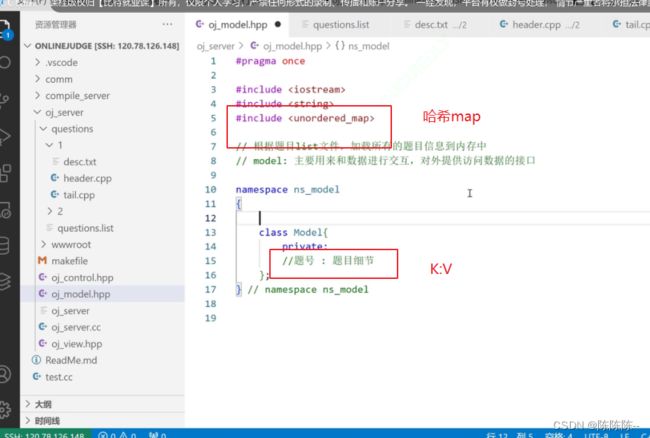
以哈希map(K:V)实现
先写一个题目的结构体
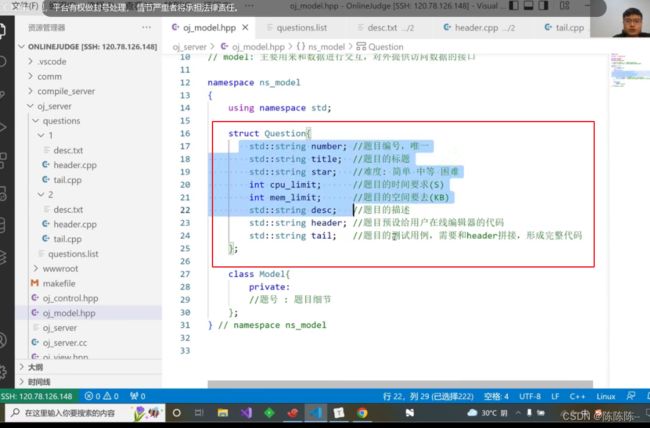
//把数据都保存在undered_map 中。K:V(题号:题目细节)
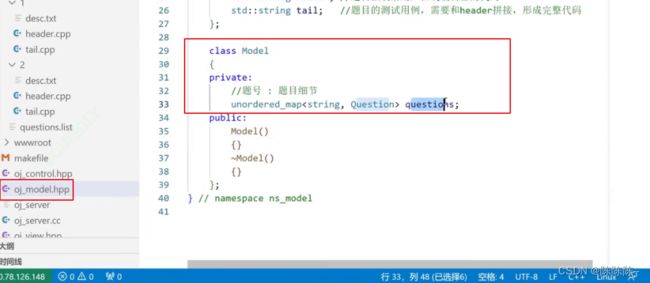
加载配置文件:找到quertion.list,获取每个题目中的header.cpp,tail.cpp,dest.txt
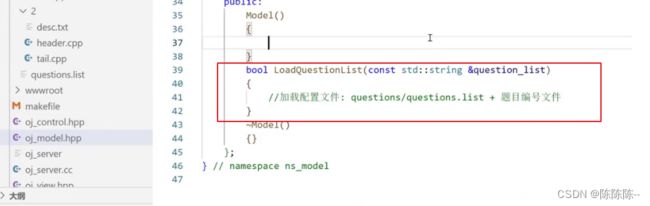

获取一个题目+获取全部题目的函数
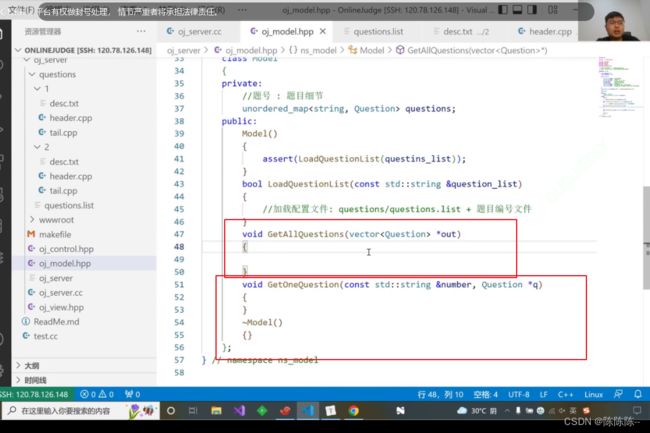
下面的任务:如何编写这三个函数:
- LoadQuestionList
- GetAllQuestions
- GetOneQuestion
27.编写model代码1(获取所有题目和获取1个题目)
1.获取所有题目

2.获取一个题目

28.编写model代码2(加载配置文件)
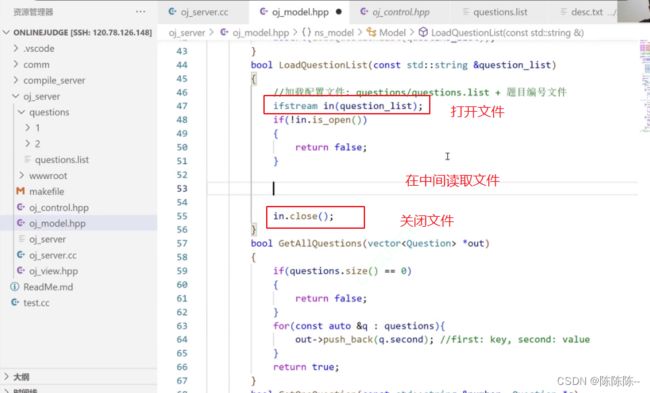
读取文件:按行读取
需要一个字符串工具:切分字符串
切分谁呢?切分题目中的这一行
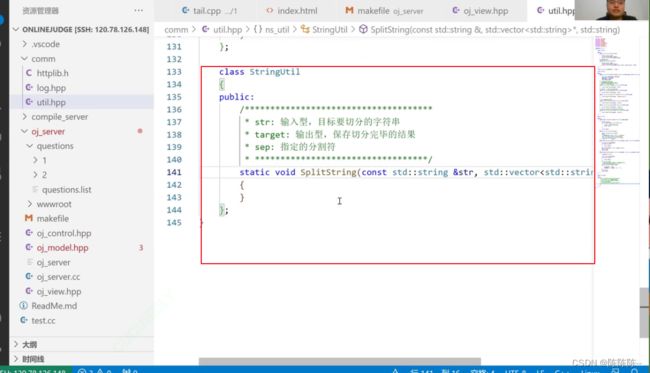
在model中引用的话,引用其命名空间

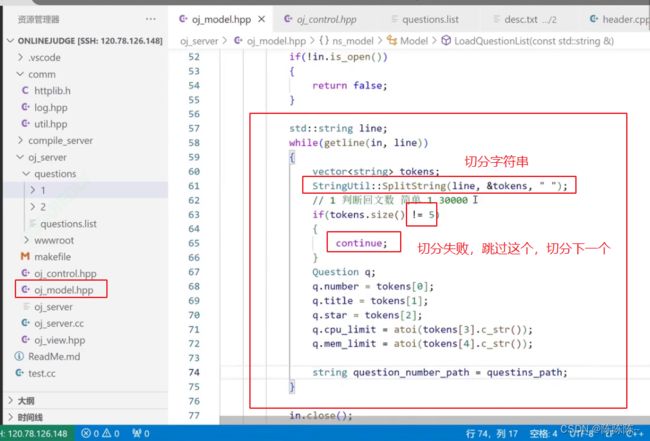
添加题库路径
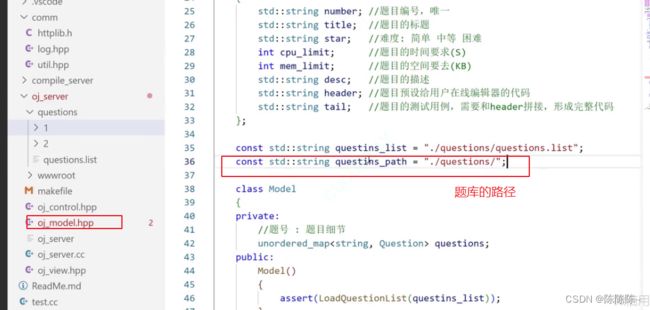
单个题目的路径

读文件
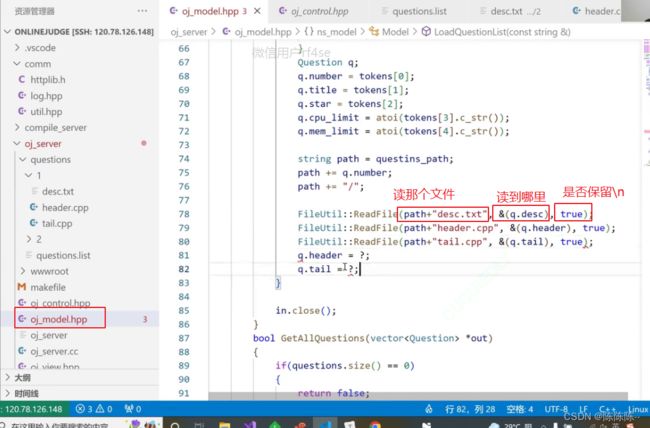
接下来将读出来的插入到questions结构体里面

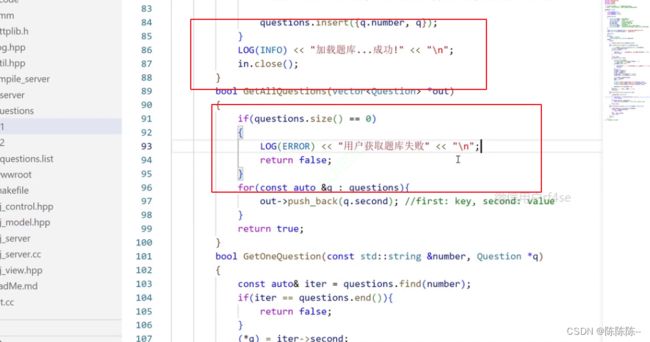
29.model添加日志
加载题库失败

加载部分题目失败


30.使用boost split字符串切分
安装boost库
sudo yum install -y boost-devel //是boost 开发库

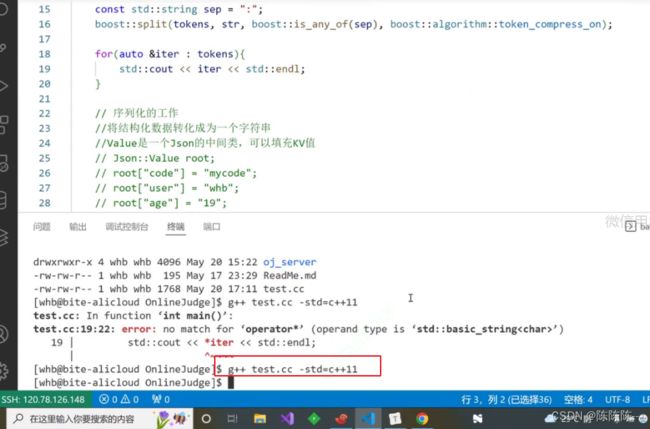
boost分割
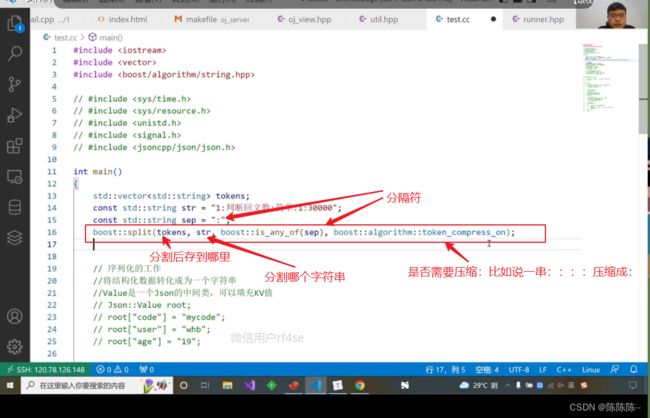
运行

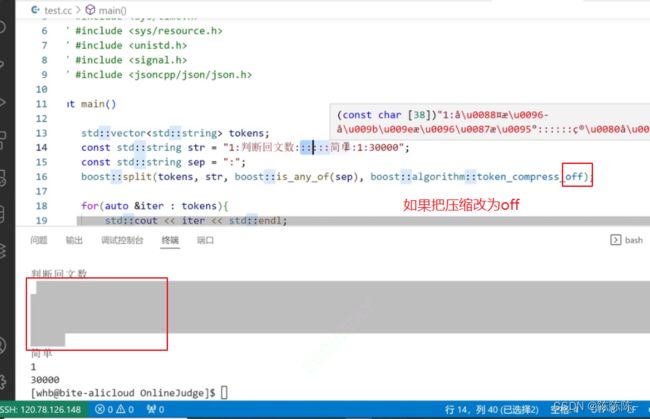
如果不压缩::::::
测试完删掉
完成字符串切分
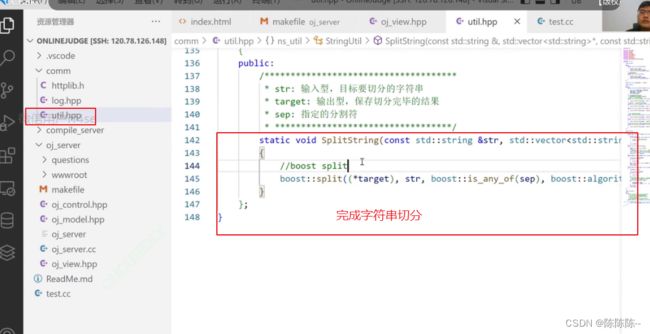
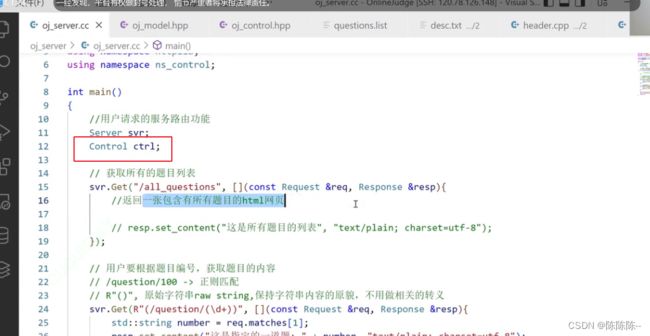
31.编写control模块整体结构
帮我们进行逻辑控制
先写一个命名空间,类
控制器里有什么?control肯定要能访问各个model

当用户想请求访问所有题目,我们应该返回一张包含所有题目的html网页。所以,先在oj_server里面包含控制模块
当用户想请求访问所有题目,在oj_server里面通过control把所有的数据拿到(control里包含了model),用control获取所有的题目,然后给用户返回一个html。
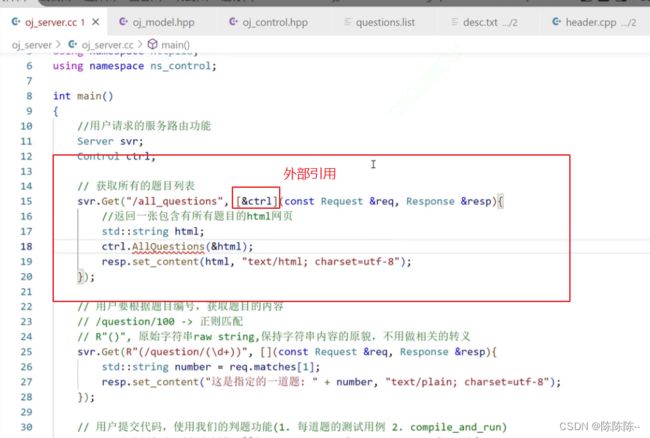
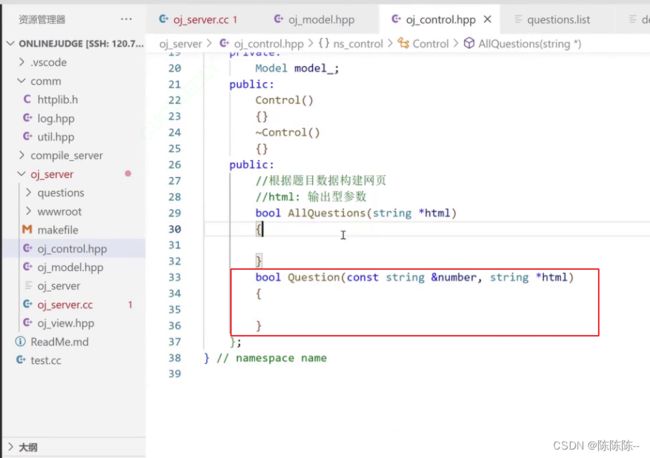
所以在oj_control中构建获取所有题目的函数
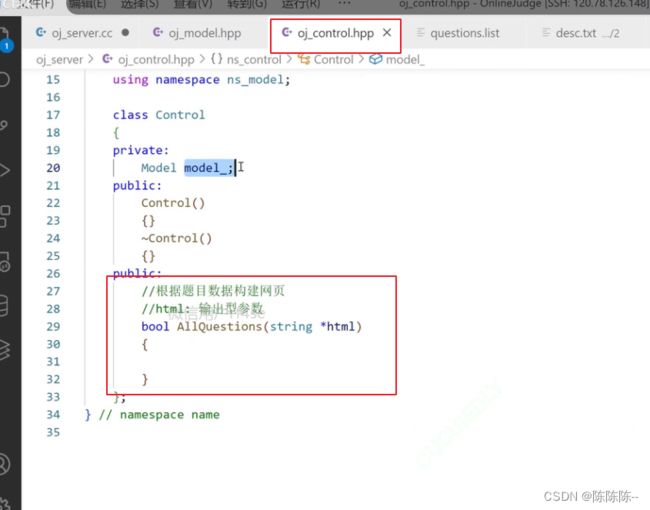
获取单个题目

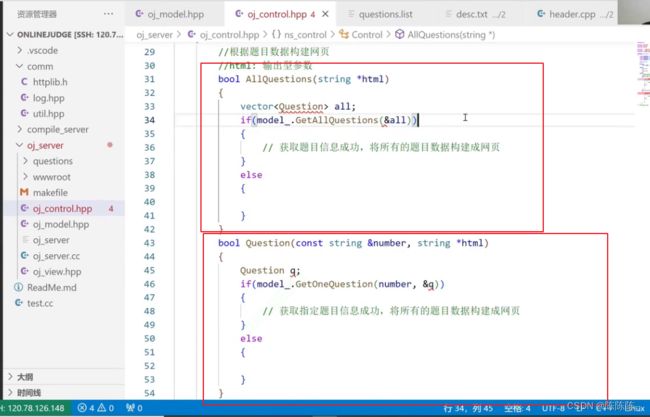
获得数据之后,如何把数据转换成网页呢?则需要包含view模式
32.引入ctemplate测试基本功能

获得数据之后,如何把数据转换成网页呢?则需要包含view模式
接下来引入一个ctemplate渲染库

https://hub.fastgit.xyz/OlafvdSpek/ctemplate

导入库
方法二:导入ctemplate
$ git clone https://gitee.com/mirrors_OlafvdSpek/ctemplate.git
//先进入到 ctemplate 目录下
$ cd ctemplate
$ ./autogen.sh
$ ./configure
$ make //编译
$ make install //安装到系统中
注意gcc版本
如果安装报错,注意使用sudo
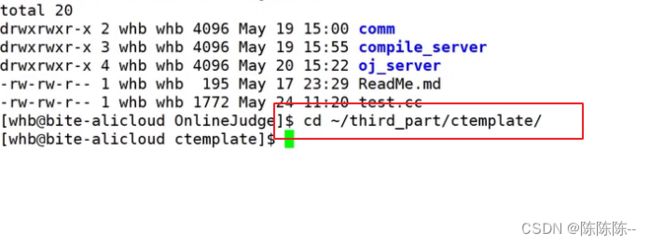
完成安装:
./autogen.sh
./configure
make //编译
make install //安装到系统中
安装库之后,可以测试一下
数据渲染:
我们需要一个数据字典存储key和value
然后需要一个待被渲染的网页内容,可以用数据字典中key值对应的value去替换网页内容里的key
这两个通过ctemplate接口连接起来
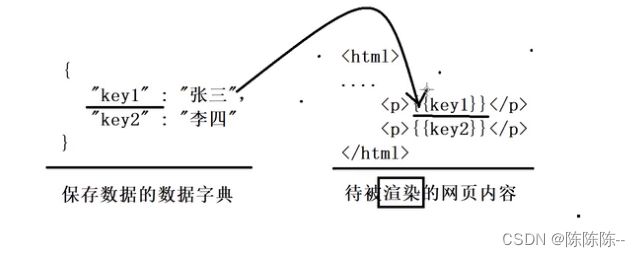
1.形成数据字典

2.获取被渲染网页对象
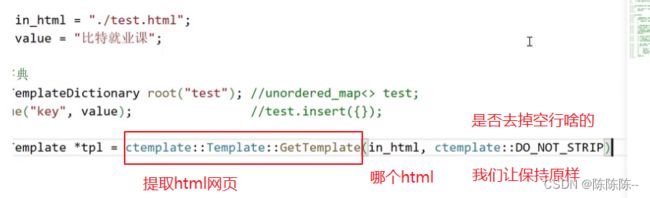
3.将数据字典添加到网页中
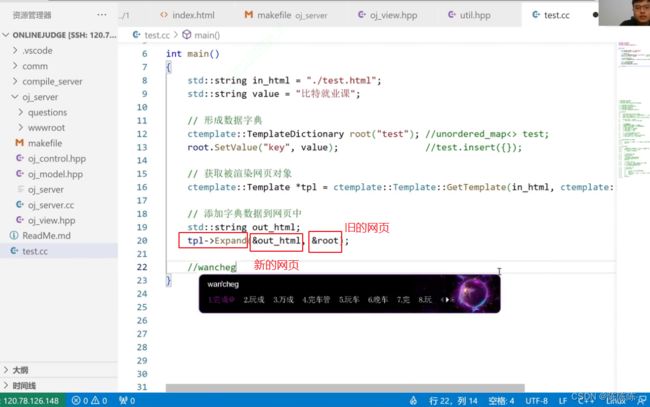
4.完成渲染

接下来如何使用呢?
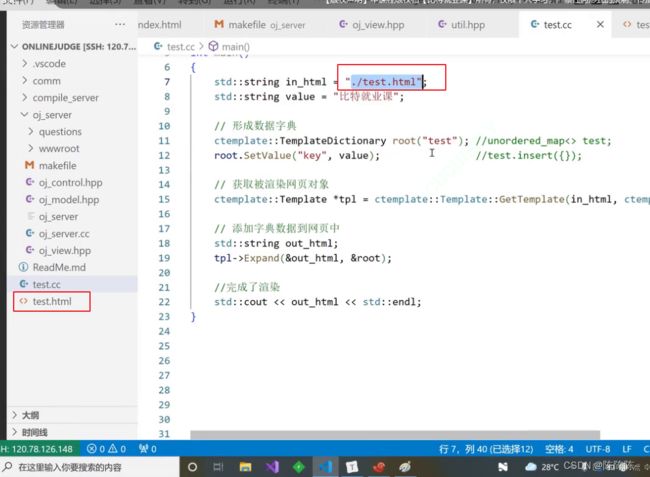
在这个网页里面,牵扯到前端的内容(有一些配置,自动补齐等)
!+table可以自动生成网页基本代码
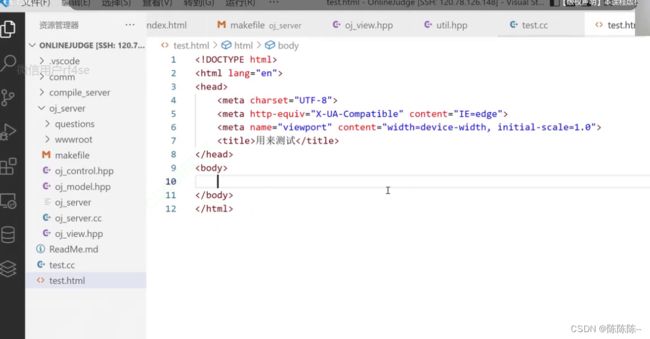
下面我们要把网页里面需要被渲染的数据替换成我们刚刚数据字典里面的内容,所以
(ctemplate的规则就是:被双花括号包着的就是需要被替换的key值)
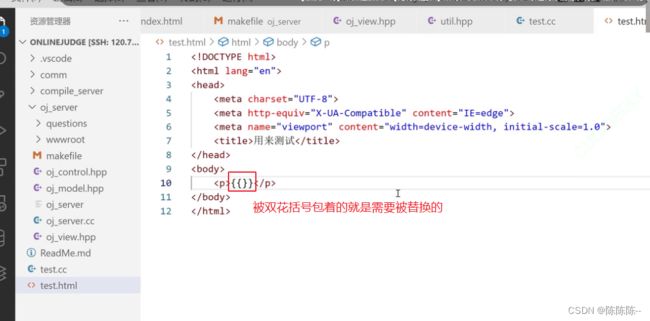
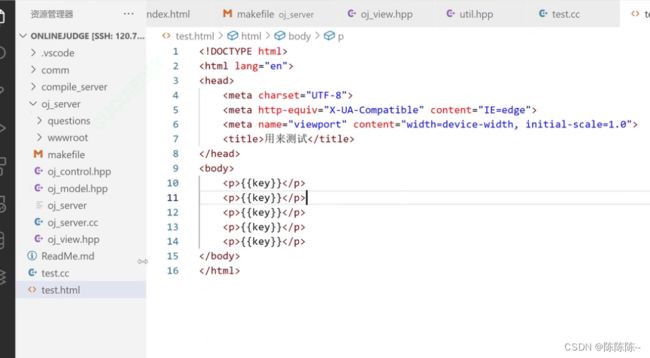
接下来,编译,升级一下编译器
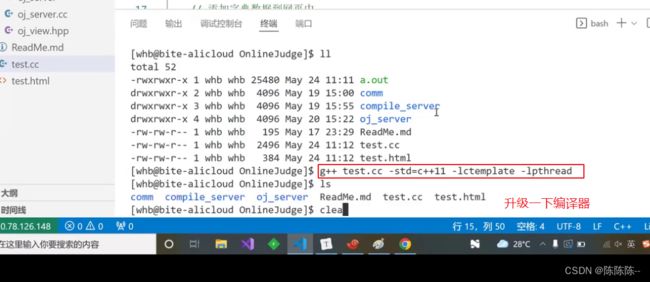
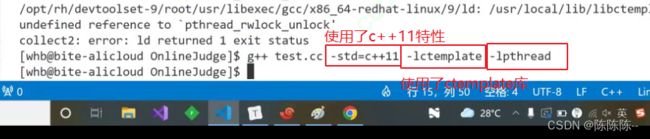
编译的时候加了三个后缀,因为:
- 使用了c++11特性
- 使用了ctemplate库
- ctemplate库里面使用了pthread库
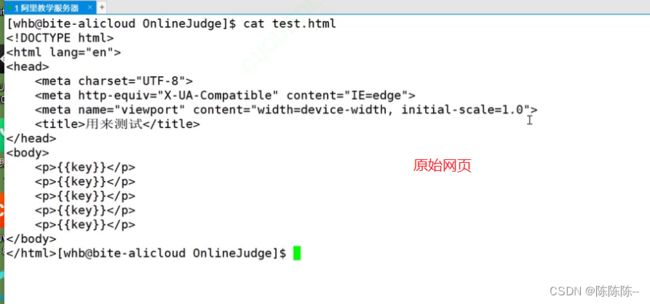
原始网页
经过渲染!!!!!完成替换

接下来将渲染后的制作成view功能
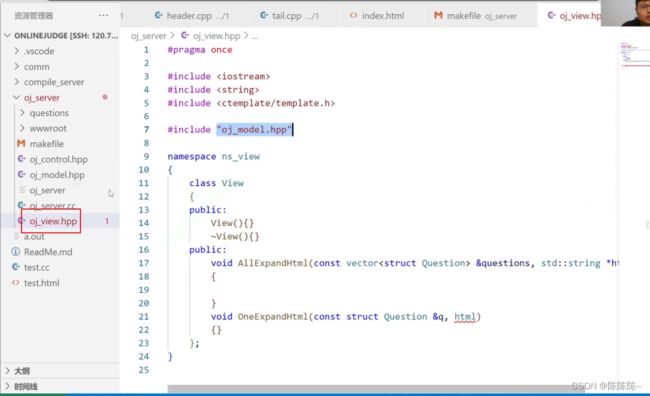
33.编写view模块整体代码结构
如何用view?
先在control中引用view
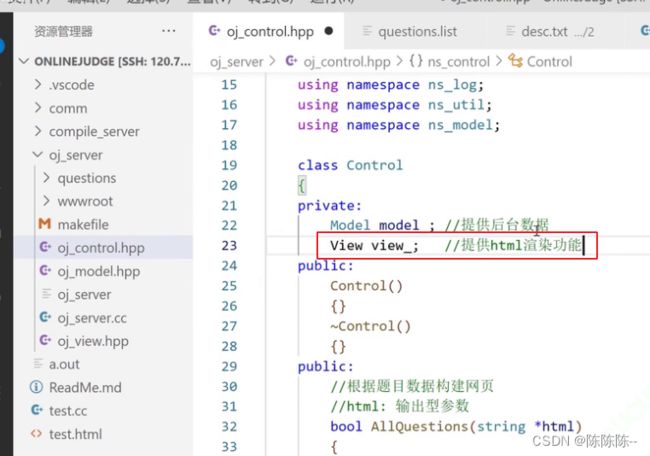
获取所有题目,形成网页
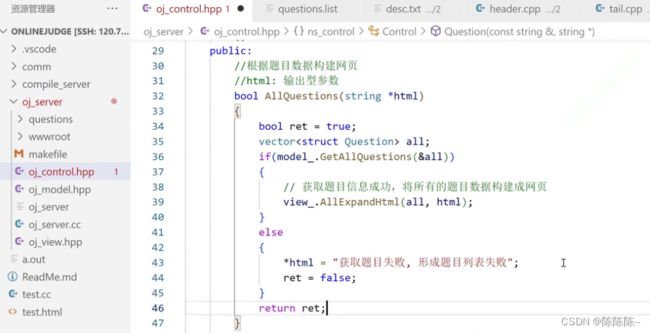
获取指定题目,形成网页
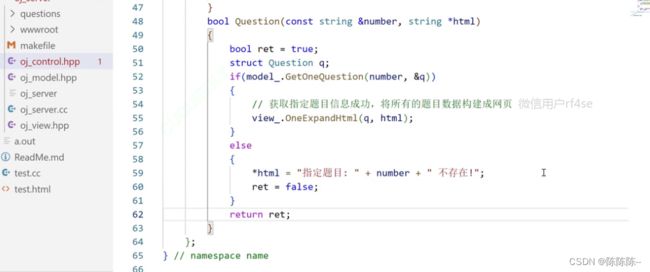
加下来需要编写view类,里面有两个接口,一个是AllExpandHtml,一个是GetOneQuestion
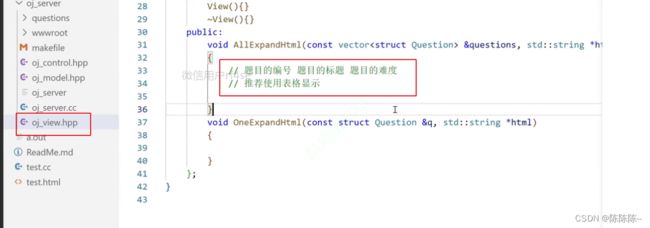
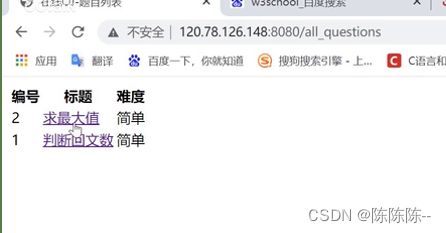
在题目列表里面只需要显示:题号,题目,难度
推荐使用表格显示题目列表
测试:
先make,然后运行
可以搜搜html教程,看看html的表格怎么写

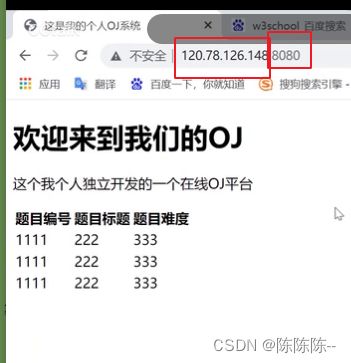
新建两个网页,后续供OJ_view渲染使用
1.所有题目列表

先构建一个根字典root,再构建一个子字典questions_list,然后往子字典里面添加数据

1.形成路径
2.形成数据字典
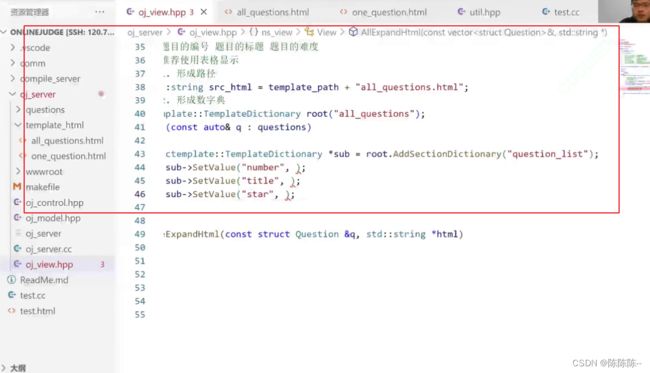
3.获取被渲染的html


4.执行渲染

添加一个跳转链接
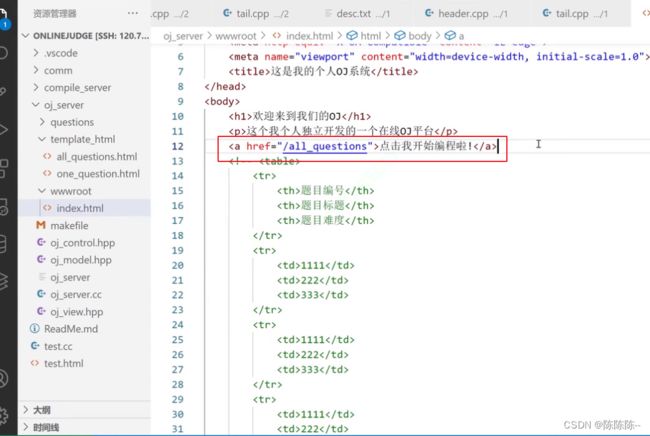

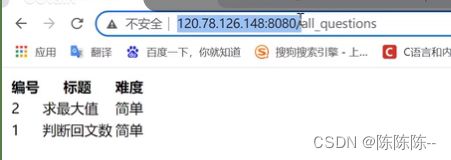
问题:没有按照顺序,有点乱,后面进行排序一下
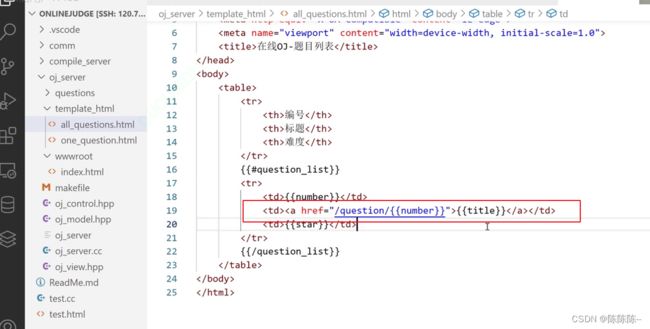
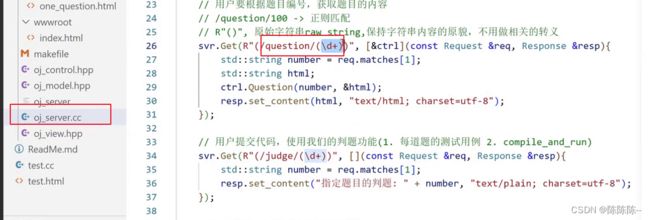
35.编写view获取指定题目功能
接下来想实现:点解某个题目可以跳转
1.形成路径

2.简单编写one_question
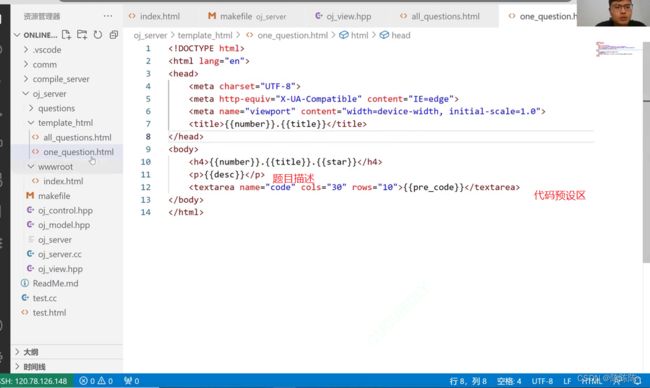
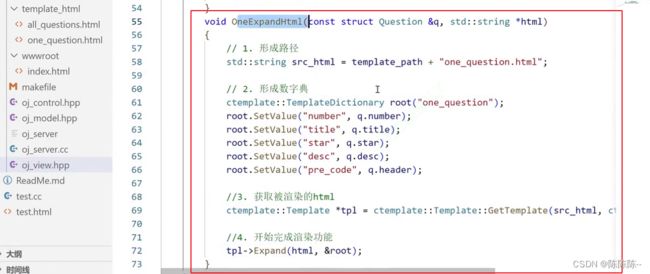
3.在view中渲染
4.在all_question里面添加跳转,即就是在题目列表的时候,点击题目可以跳进单个题目
跳转到了这个请求服务:请求question/某个题目编号
测试:
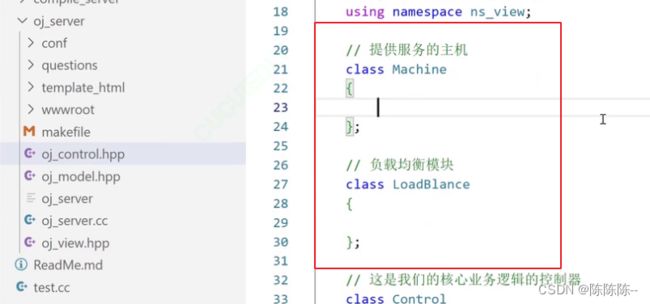
36.编写负载均衡模块代码整体结构
根据control控制器实现一个判题功能
然后设计下一个功能:负载均衡
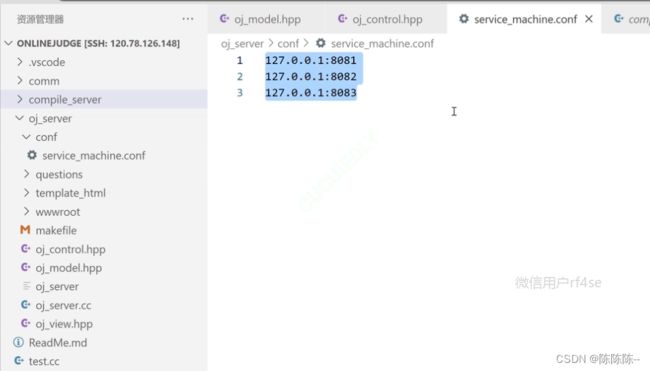
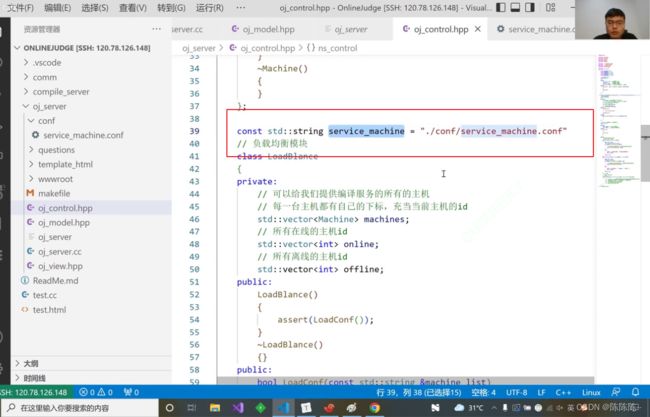
新建文件:可以给我们提供服务的主机列表
如何设计负载均衡呢?
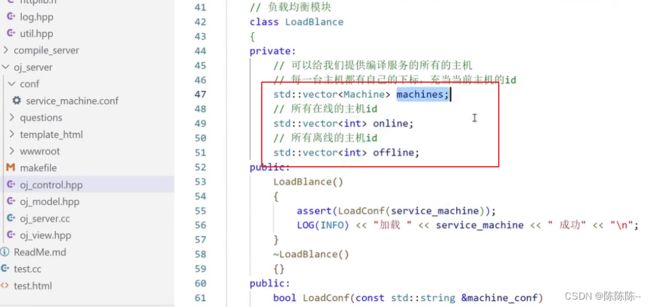
负载均衡模块:

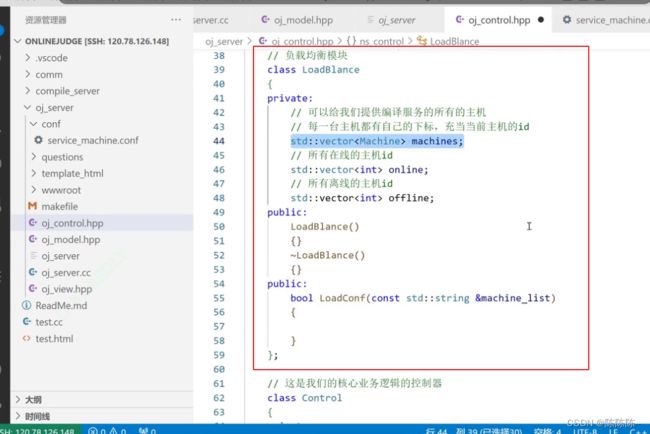
提供服务的主机的路径
启动的时候把所有的主机可以加载进来
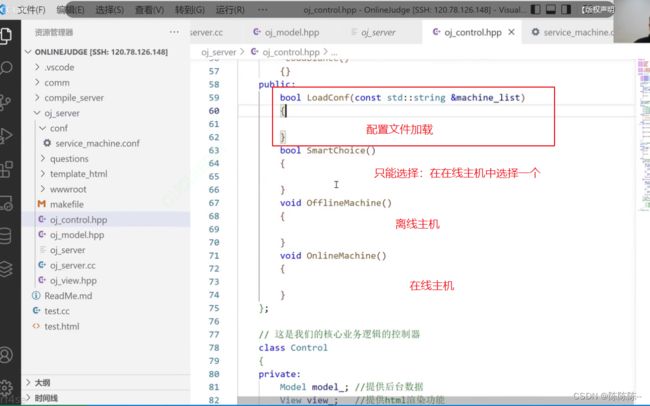
负载均衡式的代码结构:
37.编写负载均衡器代码
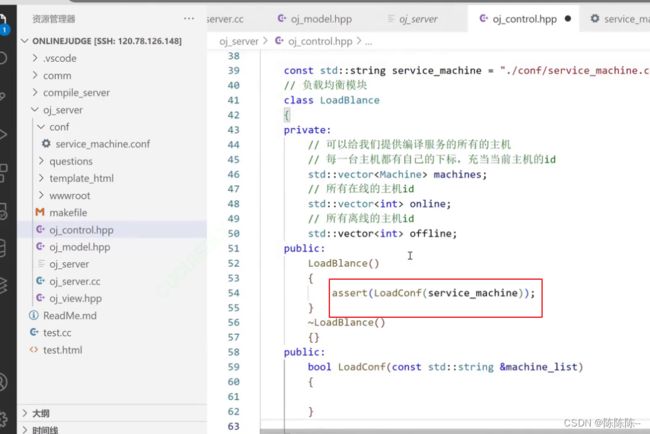
第一个功能:加载配置文件
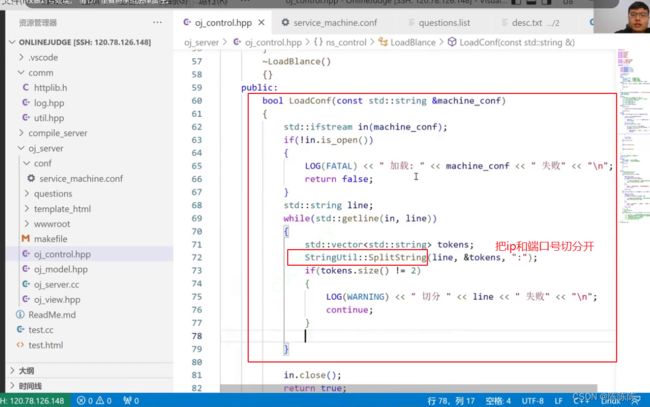
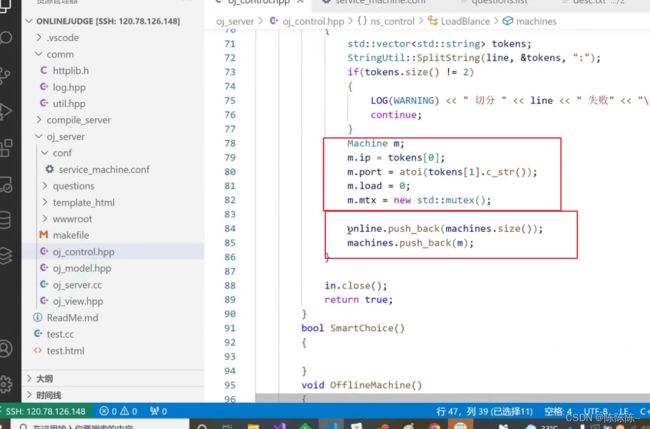
如果把所有的配置文件都加载进来之后,所有的主机已经全在machines中,所有主机下标在online里面
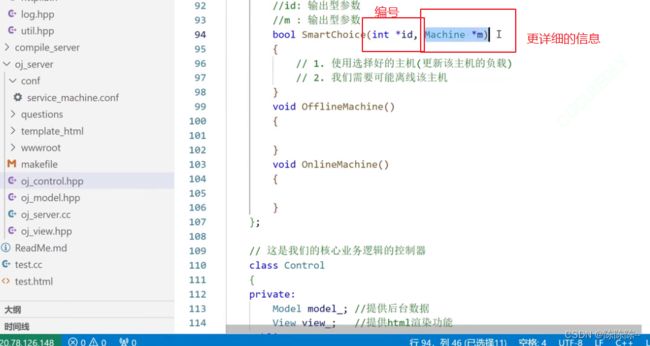
2.智能选择
想拿到主机的编号以及主机更详细的信息
有可能面临无数台主机访问,所以需要加锁。一共加了两个锁,一个是大锁:LoadBlance;一个是给各个主机上锁:

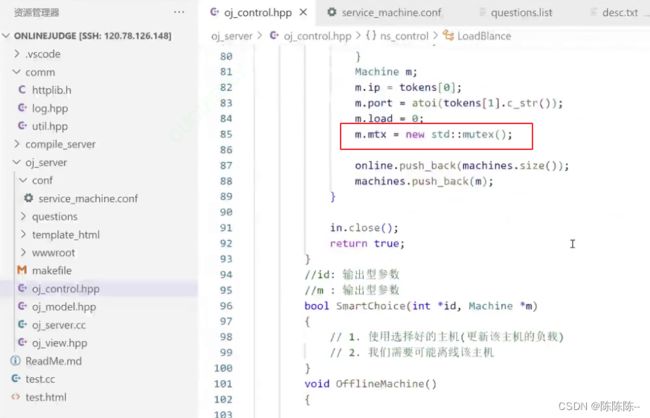
有了锁之后,

错误:没有在线主机
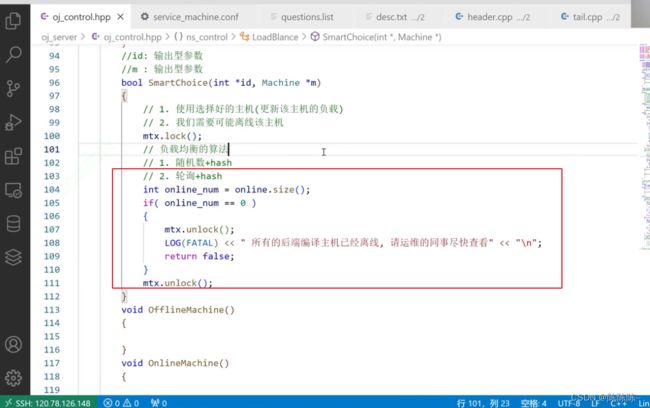
通过遍历的方式,找到所有负载最小的机器
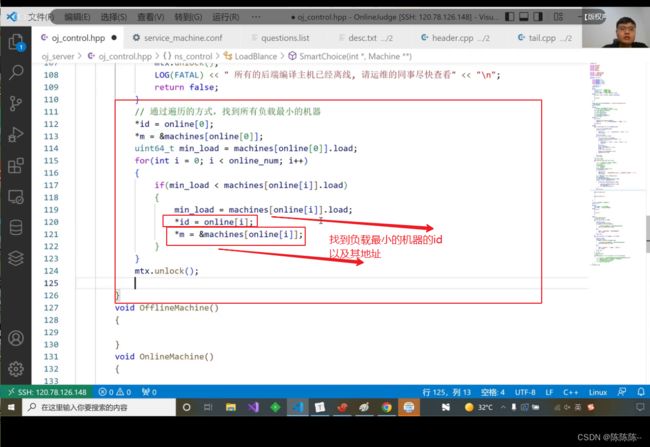
负载有可能递增,也有可能递减,写出对应的函数

获取主机负载,没有太大的意义,只是为了统一接口
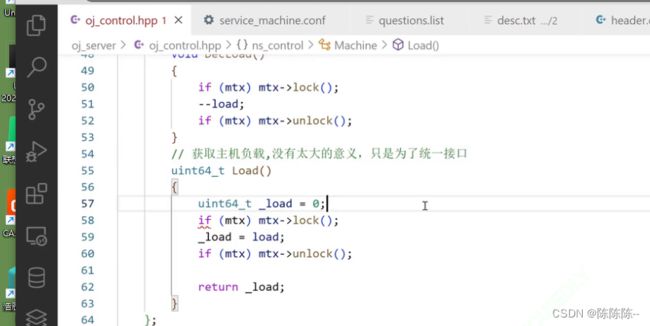
以上完成了:获取负载情况

主机给了,负载均衡算法也给了,下面要进行Judge的编写。
38.编写judge功能1
0. 根据题目编号,直接拿到对应的题目细节
1. in_json进行反序列化,得到题目的id,得到用户提交源代码,input
2. 重新拼接用户代码+测试用例代码,形成新的代码

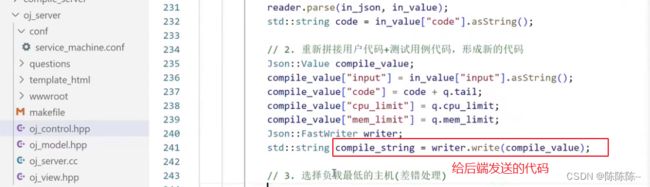
39.编写judge功能2
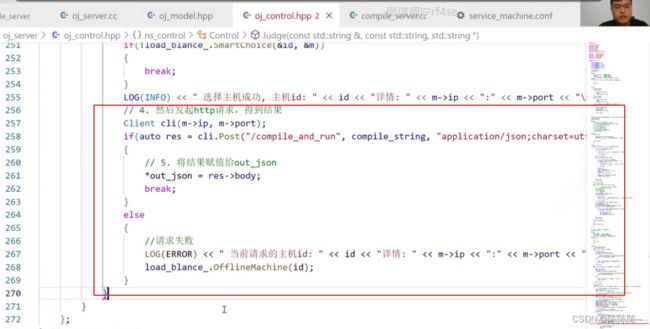
3.选择负载最低的主机(差错处理)
// 规则: 一直选择,直到主机可用,否则,就是全部挂掉
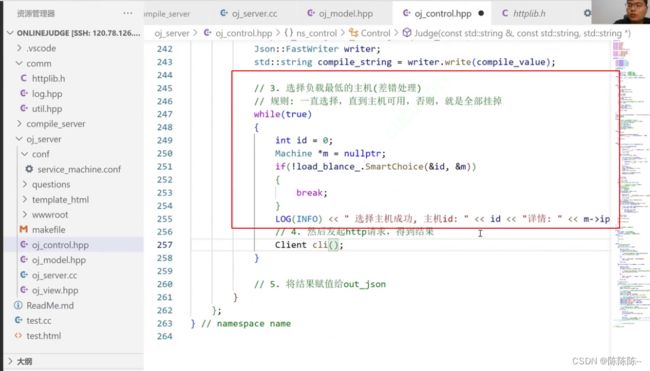
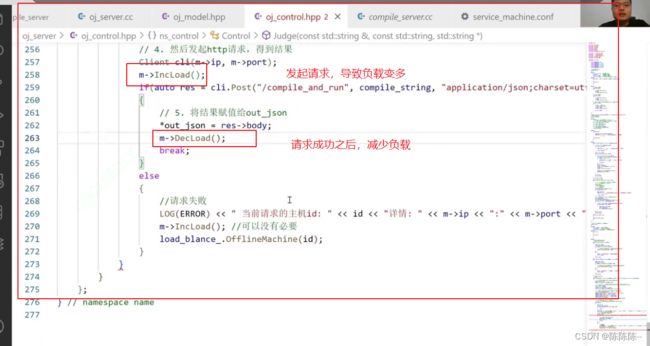
4. 然后发起http请求,得到结果
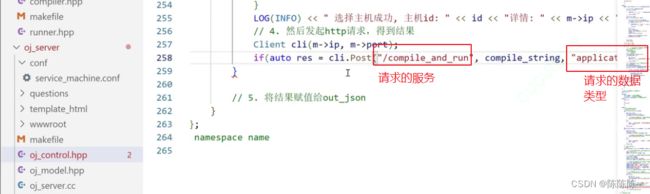
在请求的时候,更新负载:负载递增;负载递减
40.编写judge功能3
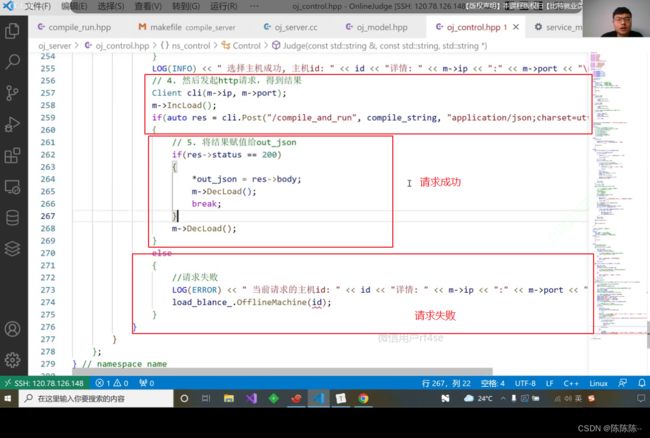
请求成功之后,就会将用户上传的代码传到后端服务器,进行编译运行
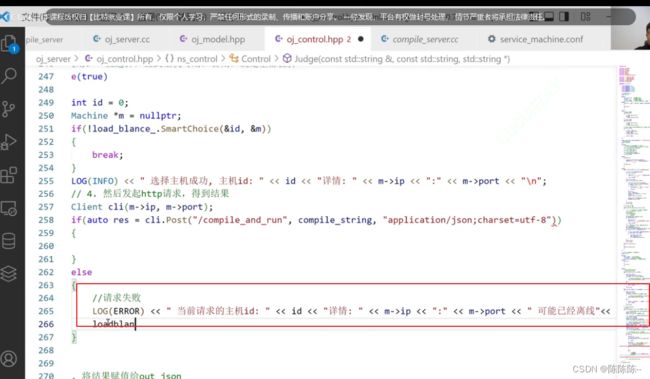
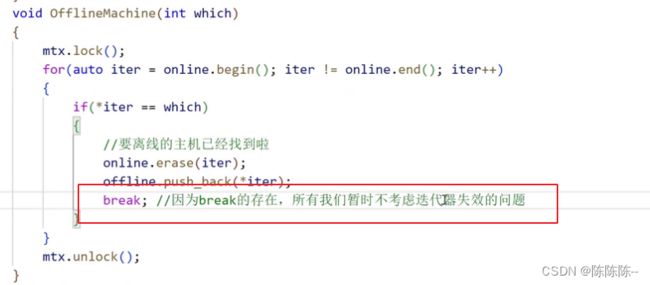
请求失败之后,就离线主机
离线的时候,有人可能会来请求该主机,所以在离线的时候加个锁,就不会有人来请求了
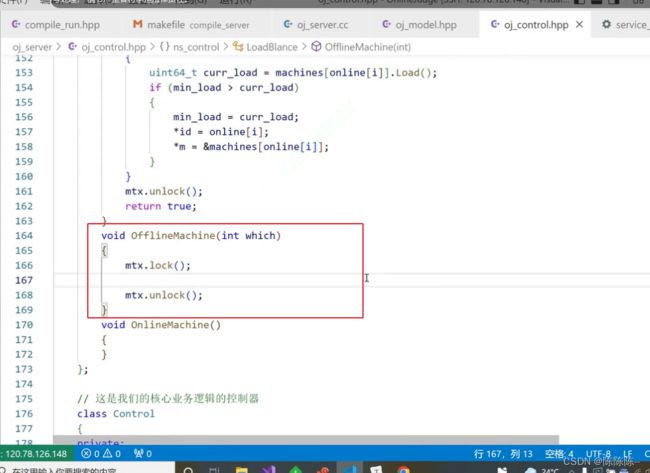
离线主机
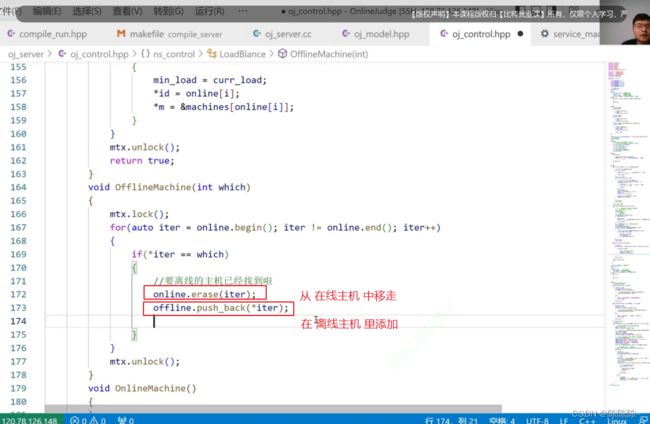
查看当前在线主机列表和离线主机列表


总结:
实现了可以给我们提供负载均衡功能的主机machine(就是一个machine对应一个后端服务),你可以在一台机器上部署三个编译服务,那么就对应三个machine,你将来可以在100个机器上部署200个编译服务,每台机器两个,那么你就有200个machine,所以它是一个逻辑上的概念。

然后,它提供的就是更新自己的负载,减少自己的负载,还有获取自己的负载
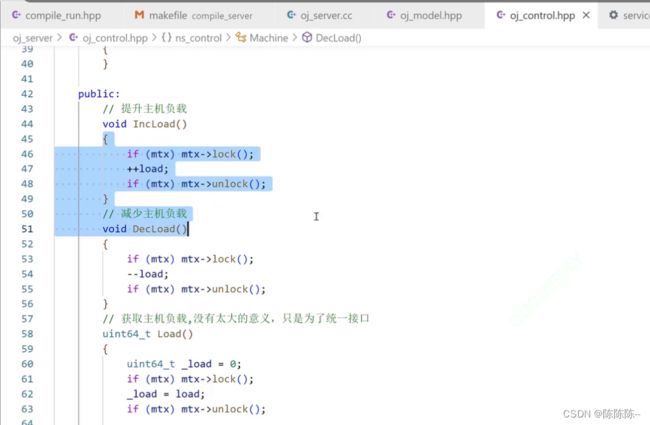
接下来,我们的负载均衡器loadBlance做的就是:根据配置文件把所有我们曾经预配置的主机和端口搞进来,搞进来之后把他push到machines里面。
启动之后,我们所有的主机相当于已经被加载到了我们的内存或者是我们的负载均衡模块之中,并且默认在启动的时候所有的主机都是online的。所以后续负载均衡器要给我们提供的一个功能是智能选择主机(smartchoice),在选择时候,别人可能正在进行离线主机或者正在做什么,但是只要我们加锁。在智能选择中,采用轮询,找到负载最小的主机,然后再采用哈希,也就是id的方式,去索引我们的目标主机。
选择完主机之后,就可以支撑我们后续的Judge:先获得题目,然后把我们客户原始请求过来的json进行反序列化(得到题目的id,源代码),反序列化之后,重新构建json串,里面有一个非常重要的过程,就是把用户的代码和我们自己的测试用例代码拼接(没有这一步的话,就无法判题)。接下来,就把以上所有内容构建成json串,以备后用
接下来,对选择的负载最低的主机进行差错处理:一直选择,直到主机可用,否则,就是全部挂掉。
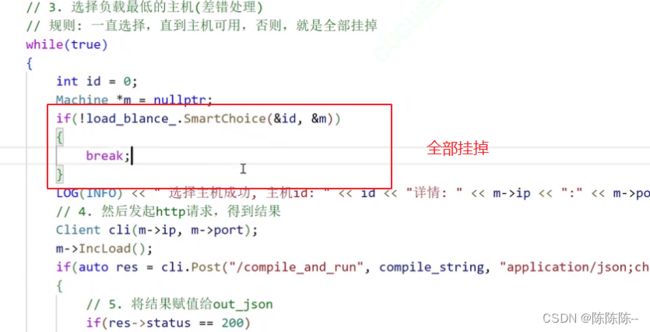
只要主机选择成功,一台机器进行请求,然后通过post方法请求后端,请求后端成功之后,他就会自动帮我们执行曾经编写好的那个服务,进行编译-链接-运行,把结果构成json串给我们,给我们之后,如果请求没有问题,状态码等于200,那我们就返回out——json,负载减少,然后编译服务成功,然后break;否则编译失败之后(状态码不为200),就重新选择.
如果真的找不到主机,就查看所有在线的主机,看看哪些主机在线,哪些离线
关于负载均衡模块全部搞定!!!!!!!!!!!