【LLM】2023年大型语言模型训练
2022年底,大型语言模型(LLM)在互联网上掀起了风暴,OpenAI的ChatGPT在推出5天后就达到了100万用户。ChatGPT的功能和广泛的应用程序可以被认可为GPT-3语言模型所具有的1750亿个参数
尽管使用像ChatGPT这样的最终产品语言模型很容易,但开发一个大型语言模型需要大量的计算机科学知识、时间和资源。我们撰写这篇文章是为了让商业领袖了解:
- 大型语言模型的定义
- 大型语言模型示例
- 大型语言模型的体系结构
- 大型语言模型的训练过程,
这样他们就可以有效地利用人工智能和机器学习。
什么是大型语言模型?
大型语言模型是一种机器学习模型,它在大型文本数据语料库上进行训练,以生成各种自然语言处理(NLP)任务的输出,如文本生成、问答和机器翻译
大型语言模型通常基于深度学习神经网络,如Transformer架构,并在大量文本数据上进行训练,通常涉及数十亿个单词。较大的模型,如谷歌的BERT模型,使用来自各种数据源的大型数据集进行训练,这使它们能够为许多任务生成输出。
如果您是大型语言模型的新手,请查看我们的“大型语言模型:2023年完整指南”文章。
按参数大小排列的顶级大型语言模型
我们在下表中按参数大小编译了7个最大的大型语言模型。1
| Model | Developer | Parameter Size |
|---|---|---|
| WuDao 2.0 | Beijing Academy of Artificial Intelligence | 1.75 trillion |
| MT-NLG | Nvidia and Microsoft | 530 billion |
| Bloom | Hugging Face and BigScience | 176 billion |
| GPT-3 | OpenAI | 175 billion |
| LaMDA | 137 billion | |
| ESMFold | Meta AI | 15 billion |
| Gato | DeepMind | 1.18 billion |
Showing 1 to 7 of 7 entries
Check our article on large language model examples for more models with in-depth information.
大型语言模型的架构
大型语言模型的架构,如OpenAI的GPT-3,基于一种称为Transformer架构的深度学习。它由以下主要组件组成(见图1):
Figure 1: Transformer architecture
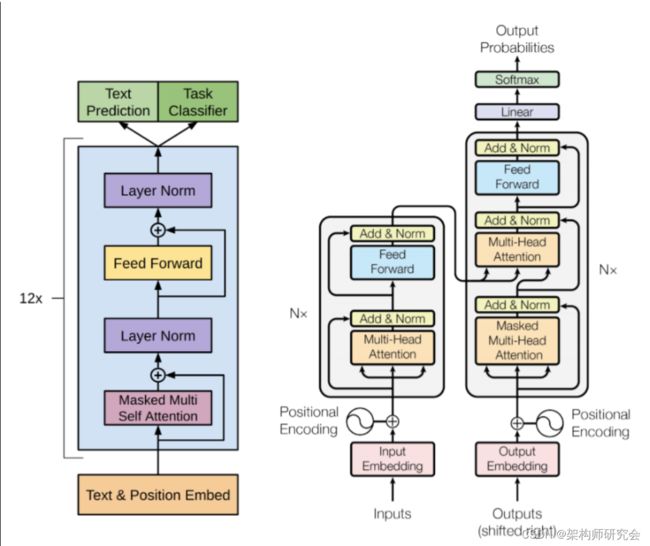 Source:2
Source:2
1.输入嵌入
输入序列首先被转换为密集向量表示,称为嵌入,它捕捉输入中单词之间的关系。
2.多头自我关注
转换器块架构的核心组件是多头自注意机制,它允许模型关注输入序列的不同部分,以捕获其关系和依赖关系。
3.前馈网络
在自我注意机制之后,输出被馈送到前馈神经网络,该网络执行非线性变换以生成新的表示。
4.归一化和剩余连接
为了稳定训练过程,对每一层的输出进行归一化,并添加残差连接,以允许输入直接传递到输出,从而允许模型了解输入的哪些部分最重要。
这些组件被重复多次以形成深度神经网络,该网络可以处理长序列的文本,并为各种语言任务生成高质量的输出,如文本生成、问答和翻译。
开发人员通过实施新技术继续开发大型语言模型,以:
- 简化模型(减少训练所需的模型大小或内存),
- 提高性能,
- 价格更低,
- 减少模型训练时间。
训练大型语言模型
训练大型语言模型有四个步骤:
1.数据收集和预处理
第一步是收集训练数据集,这是LLM将要训练的资源。数据可以来自各种来源,如书籍、网站、文章和开放数据集
查找数据集的流行公共来源包括:
- Kaggle
- Google Dataset Search
- Hugging Face
- Data.gov
- Wikipedia database
然后需要对数据进行清理,并为培训做好准备。这可能包括将数据集转换为小写,删除停止词,并将文本标记为构成文本的标记序列
2.型号选择和配置
谷歌的BERT和OpenAI的GPT-3等大型模型都使用transformer深度学习架构,这是近年来复杂NLP应用程序的常见选择。模型的一些关键元素,例如:
- 变压器组的层数
- 关注头数
- 损失函数
- 超参数
在配置变压器神经网络时需要指定。配置可以取决于期望的用例和训练数据。模型的配置直接影响模型的训练时间。
3.模型培训
使用监督学习在预处理的文本数据上训练模型。在训练过程中,向模型呈现一个单词序列,并对其进行训练以预测序列中的下一个单词。该模型根据其预测和实际下一个单词之间的差异来调整其权重。这个过程重复了数百万次,直到模型达到令人满意的性能水平。
由于模型和数据的大小很大,因此训练模型需要巨大的计算能力。为了减少训练时间,使用了一种名为模型并行的技术。模型并行性使大型模型的不同部分能够分布在多个GPU上,从而允许使用AI芯片以分布式方式训练模型
通过将模型划分为更小的部分,每个部分都可以并行训练,与在单个GPU或处理器上训练整个模型相比,训练过程更快。这导致更快的收敛和更好的整体性能,使训练比以前更大的语言模型成为可能。常见的模型并行类型包括:
- 数据并行性
- 序列并行性
- 管道平行度
- 张量平行度
从头开始训练一个大型语言模型需要大量投资,一个更经济的选择是对现有的语言模型进行微调,使其适合您的特定用例。GPT-3的一次训练预计耗资约500万美元。
4.评估和微调
训练后,在测试数据集上评估模型,该测试数据集尚未用作测量模型性能的训练数据集。根据评估结果,模型可能需要通过调整其超参数、改变架构或对额外数据进行训练来进行一些微调,以提高其性能
针对特定用例培训LLM
LLM的培训包括两个部分:预先培训和特定任务的培训。预训练是训练的一部分,使模型能够学习语言中的一般规则和依赖关系,这需要大量的数据、计算能力和时间才能完成。论文中讨论的大型语言模型需要具有多个人工智能芯片的超级计算机系统(例如NVIDIA DGX A100起价199999美元)。一旦增加维护和电源成本,大型语言模型的预训练就需要数百万美元的投资。
为了让企业更容易访问大型语言模型,LLM开发人员正在为希望利用语言模型的企业提供服务。NVIDIA的NeMO就是这些服务的一个例子,它提供预先训练的LLM,用于微调和特定任务训练,以适应特定的用例。特定任务训练为模型增加了一个额外的层,这需要更少的数据、功率和时间来训练;使大型模型可供企业使用。新的任务特定层是用很少的镜头学习来训练的,目的是用更少的训练数据来获得准确的输出。
由于模型已经经过预先训练并熟悉语言,因此少镜头学习是向模型教授特定领域单词和短语的可行方法。
文章链接
https://pgmr.cloud/large-language-model-training-2023
自我介绍
- 做一个简单介绍,酒研年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师研究会】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。全网同号【架构师研究会】

欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.