一周爬虫集训任务三:学习selenium+IP相关知识
一周爬虫集训任务三:学习selenium+IP相关知识
-
- 1 任务
- 2 Selenium
-
- 2.1 介绍
- 2.2 selenium安装
- 2.3 下载浏览器驱动
- 2.4 设置浏览器驱动
- 2.5 Selenium元素定位
- 2.6 Selenium WebDriver功能特性
- 2.7 使用selenium模拟登陆163邮箱
- 3 IP
-
- 3.1 IP的基本概念
- 3.2 为什么会出现IP被封
- 3.3 如何应对IP被封的问题
- 3.4 抓取西刺代理,并构建自己的代理池
- 4 参考
1 任务
Task3(2天)
3.1 安装selenium并学习
1. 安装selenium并学习。
2. 使用selenium模拟登陆163邮箱。
3. 163邮箱直通点:https://mail.163.com/ 。
4. 参考资料:https://blog.csdn.net/weixin_42937385/article/details/88150379
3.2 学习IP相关知识
1. 学习什么是IP,为什么会出现IP被封,如何应对IP被封的问题。
2. 抓取西刺代理,并构建自己的代理池。
3. 西刺直通点:https://www.xicidaili.com/ 。
4. 参考资料:https://blog.csdn.net/weixin_43720396/article/details/88218204
2 Selenium
2.1 介绍
Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器。并且支持多种操作系统:如Windows、Linux、IOS、Android等。
详细教程可见:Selenium官网教程
2.2 selenium安装
对于python库的安装,一般有两种方式:
- 在Windows下以管理员方式打开命令提示符(输入CMD),输入
pip install selenium,即可完成selenium安装。 - 因为我用的IDE是pycharm,可以直接通过pycharm来下载指定库,步骤如下:
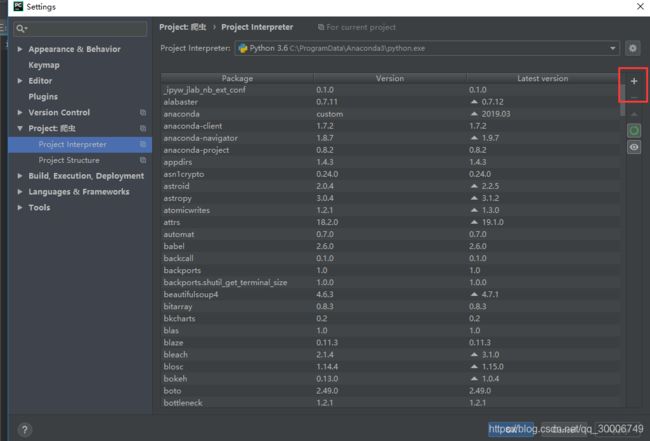
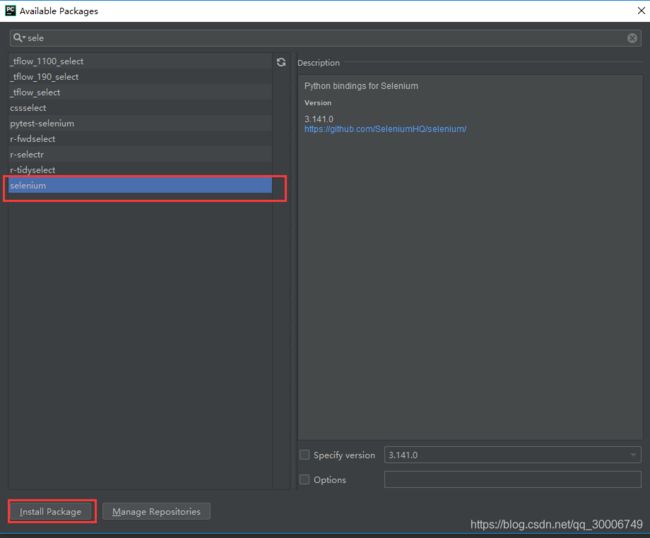
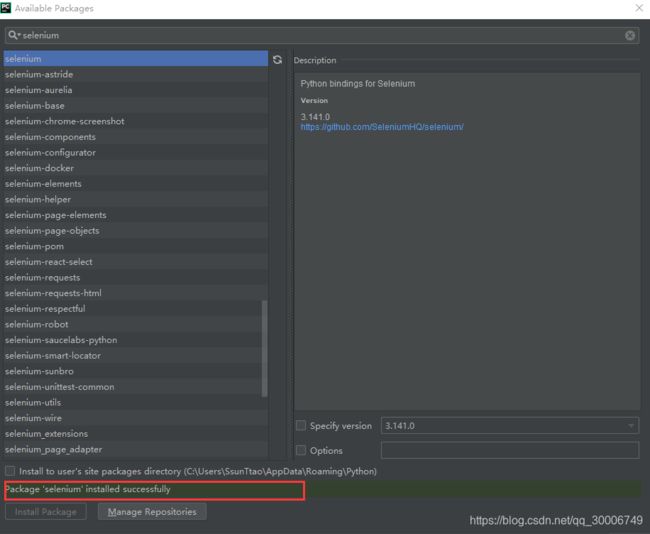
这样selenium库就成功安装啦~
2.3 下载浏览器驱动
Selenium3.x调用浏览器必须有一个webdriver驱动文件。当Selenium升级到3.0之后,对不同的浏览器驱动进行了规范。如果想使用selenium驱动不同的浏览器,必须单独下载并设置不同的浏览器驱动。
因为我用的是Chrome浏览器,所以这里只提供Chrome驱动文件下载(根据自己的浏览器版本对应选择就好):点击下载chromedrive
我的Chrome浏览器版本(在浏览器的帮助选项中可查得)为:70.0.3538.110(正式版本) (32 位),其对应的chromedrive为:chromedrive 密码:5paf
2.4 设置浏览器驱动
设置浏览器的地址非常简单。我们将解压后的chromedriver.exe文件放到Chrome的安装文件中,Chrome的安装路径可以通过右击桌面的Chrome,点击属性就可以查到。放好后将该路径添加到环境变量中。
我的电脑–>属性–>高级系统设置–>环境变量–>系统变量–>Path,将上述路径目录添加到Path的值中。
验证浏览器驱动是否正常使用:
from selenium import webdriver
driver = webdriver.Chrome() # Chrome浏览器
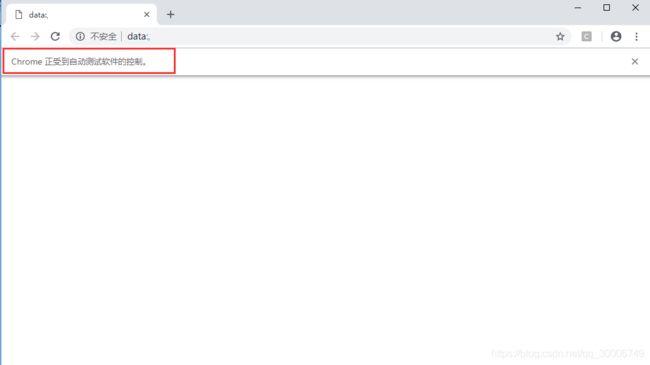
如果正常使用的话,就会弹出chrome的窗口,并显示chrome正受到自动测试软件的控制。
2.5 Selenium元素定位
Selenium提供了8种定位方式。
| 定位方式 | 在Python selenium中所对应的方法 | 含义 |
|---|---|---|
| id | find_element_by_id() | 通过id定位 |
| name | find_element_by_name() | 通过name定位 |
| class name | find_element_by_class_name() | 通过类名进行定位 |
| tag name | find_element_by_tag_name() | 通过标签定位 |
| link text | find_element_by_link_text() | 通过完整超链接定位 |
| partial link text | find_element_by_partial_link_text() | 通过部分链接定位 |
| xpath | find_element_by_xpath() | 通过xpath定位 |
| css selector | find_element_by_css_selector() | 通过css选择器进行定位 |
2.6 Selenium WebDriver功能特性
- 多浏览器支持: Selenium WebDriver支持各种Web浏览器,如Firefox,Chrome,Internet Explorer,Opera等等。它还支持一些非传统或罕见的浏览器,如HTMLUnit。
- 多编程语言支持: WebDriver还支持大多数常用的编程语言,如Java,C#,JavaScript,PHP,Ruby,Pearl和Python。 因此,用户可以基于自己的能力选择任何一种受支持的编程语言并开始构建测试脚本。
- 速度: 与Selenium Suite的其他工具相比,WebDriver的执行速度更快。与RC不同,它不需要任何中间服务器与浏览器通信; 此工具直接与浏览器通信。
- 简单命令: Selenium WebDriver中使用的大多数命令都易于实现。
- WebDriver方法和类: WebDriver提供多种解决方案来应对自动化测试中的一些潜在挑战。WebDriver还允许测试人员通过动态查找器处理复杂类型的Web元素,如复选框,下拉列表和警报。
2.7 使用selenium模拟登陆163邮箱
要求:使用selenium模拟登陆163邮箱
- 登录网页
from selenium import webdriver
import time
#打开浏览器
driver = webdriver.Chrome()
#设置地址
url = "https://mail.163.com/"
#访问网址
driver.get(url)
-
定位登录框
frame标签有frameset、frame、iframe三种,frameset跟其他普通标签没有区别,不会影响到正常的定位。而frame与iframe对selenium定位而言是一样的,内部的元素都会不能直接定位到。Web应用中经常会遇到frame/iframe 表单嵌套页面的应用,WebDriver 只能在一个页面上对元素识别与定位,对于frame/iframe 表单内嵌页面上的元素无法直接定位。这时就需要通过
switch_to.frame()方法将当前定位的主体切换为frame/iframe 表单的内嵌页面中。
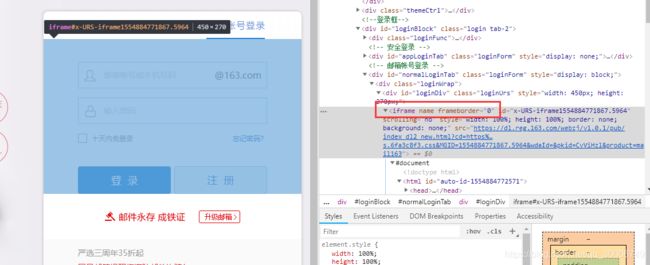
而且加载这个iframe需要一定时间,所以需要设一个等待直至获取到标签
time.sleep(1) #设置等待直至获取标签
driver.switch_to.frame(0)
#找到邮箱账号登录框对应的iframe,由于网页中iframe的id是动态的,所以不能用id寻找。用frame的index来定位,定位第一个frame(index下标从0开始)。
- 输入账号
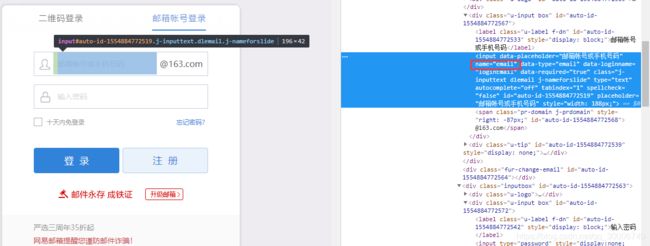
这里用查找name的方法定位:
name=driver.find_element_by_name('email')#找到邮箱账号输入框
name.send_keys("输入自己的163邮箱账号")#将自己的邮箱地址输入到邮箱账号框中
- 输入密码
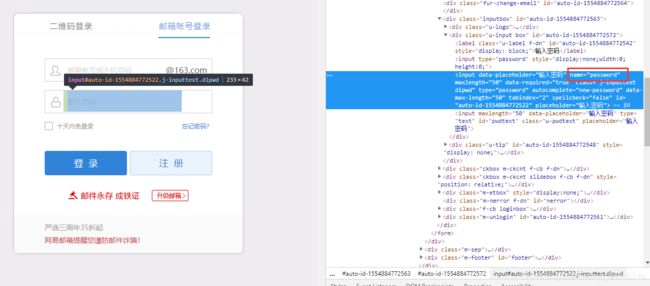
name=driver.find_element_by_name('password')#找到密码输入框
name.send_keys("输入自己的邮箱密码")#输入自己的邮箱密码
- 点击登录
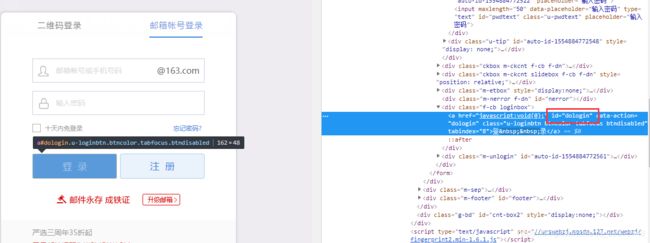
这里用查找id的方法定位:
login = driver.find_element_by_id('dologin')#找到登陆按钮
login.click() #点击登录按钮
全部代码如下:
from selenium import webdriver
import time
#打开浏览器
driver = webdriver.Chrome()
#设置地址
url = "https://mail.163.com/"
#访问网址
driver.get(url)
time.sleep(1)
driver.switch_to.frame(0)#找到邮箱账号登录框对应的iframe,由于网页中iframe的id是动态的,所以不能用id寻找
name = driver.find_element_by_name('email')#找到邮箱账号输入框
name.send_keys('163邮箱账号')#将自己的邮箱地址输入到邮箱账号框中
time.sleep(1)
name = driver.find_element_by_name('password')#找到密码输入框
name.send_keys('163邮箱密码')#输入自己的邮箱密码
login = driver.find_element_by_id('dologin')#找到登陆按钮
login.click()#点击登陆按钮
成功登录页面如下:
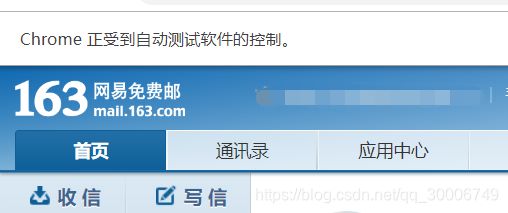
3 IP
3.1 IP的基本概念
- 定义
互联网协议地址(Internet Protocol Address,又译为网际协议地址),缩写为IP地址(IP Address),是分配给用户上网使用的网际协议(IP)的设备的数字标签。常见的IP地址分为IPv4与IPv6两大类,但是也有其他不常用的小分类。 - 基本原理
网络互连设备,如以太网、分组交换网等,它们相互之间不能互通,不能互通的主要原因是因为它们所传送数据的基本单元(技术上称之为“帧”)的格式不同。IP协议实际上是一套由软件、程序组成的协议软件,它把各种不同“帧”统一转换成“网协数据包”格式,这种转换是因特网的一个最重要的特点,使所有各种计算机都能在因特网上实现互通,即具有“开放性”的特点。 - IP地址
(1)IP地址由32位二进制数组成,为便于使用,常以XXX.XXX.XXX.XXX形式表现,每组XXX代表小于或等于255的10进制数。地址可分为A、B、C、D、E五大类,其中E类属于特殊保留地址。
(2)用来在网络中标记一台电脑的一串数字,每个IP地址包括两部分,网络地址和主机地址。网络地址的最高位必须是0。
(3)子网掩码的作用是将IP地址划分成网络地址和主机地址两部分。子网掩码不能单独存在,必须与IP地址一起使用。
(4)主机号全为0,表示网络号;主机号全为1,表示网络广播。
3.2 为什么会出现IP被封
- 定义
IP封锁是指防火墙维护一张IP黑名单,一旦发现发往黑名单中地址的请求数据包,就直接将其丢弃,这将导致源主机得不到目标主机的及时响应而引发超时,从而达到屏蔽对目标主机的访问的目的。 - IP被封的原因
(1)服务器在国内被封,无法正常访问。
(2)网站采取了一些反爬的措施,比如,服务器会检测某个IP在单位时间内的请求次数,如果超过某个阀值,那么服务器会直接拒绝服务,返回一些错误信息。
(3)服务商更换服务器(不常见)。
3.3 如何应对IP被封的问题
- 伪造User-Agent
在请求头中把User-Agent设置成浏览器中的User-Agent,来伪造浏览器访问。
还可以先收集多种浏览器的User-Agent,每次发起请求时随机从中选一个使用,可以进一步提高安全性。 - 在每次重复爬取之间设置一个随机时间间隔
比如:
time.sleep(random.randint(0,3)) # 暂停0~3秒的整数秒,时间区间:[0,3]
或:
time.sleep(random.random()) # 暂停0~1秒,时间区间:[0,1)
- 伪造cookies
若从浏览器中可以正常访问一个页面,则可以将浏览器中的cookies复制过来使用,比如:
cookies = dict(uuid='b18f0e70-8705-470d-bc4b-09a8da617e15',UM_distinctid='15d188be71d50-013c49b12ec14a-3f73035d-100200-15d188be71ffd')
resp = requests.get(url,cookies = cookies)
# 把浏览器的cookies字符串转成字典
def cookies2dict(cookies):
items = cookies.split(';')
d = {}
for item in items:
kv = item.split('=',1)
k = kv[0]
v = kv[1]
d[k] = v
return d
注意: 用浏览器cookies发起请求后,如果请求频率过于频繁仍会被封IP,这时可以在浏览器上进行相应的手工验证(比如点击验证图片等),然后就可以继续正常使用该cookies发起请求。
4. 使用代理
可以换着用多个代理IP来进行访问,防止同一个IP发起过多请求而被封IP,比如:
proxies = {'http':'http://10.10.10.10:8765','https':'https://10.10.10.10:8765'}
resp = requests.get(url,proxies = proxies)
# 注:免费的代理IP可以在这个网站上获取:http://www.xicidaili.com/nn/
3.4 抓取西刺代理,并构建自己的代理池
要求:西刺直通点:西刺免费代理IP
- 先分析网站结构,发现IP地址,端口等信息都在标签内,并且有两个不同的标签。
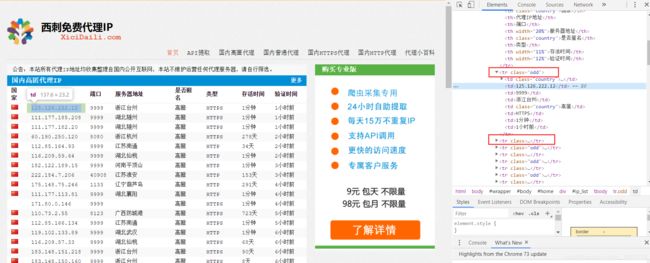
- 使用正则表达式,先把整个内容匹配下来,再匹配重要信息。
#匹配整体数据的正则
root_pattren = 'alt="Cn" />([\d\D]*?)'
#再次匹配数据的正则
key = re.findall('([\d\D]*?) ',s)
- 最后就随机获取一个ip,然后可以先判断是否有用,再拿来做你此时项目的代理ip,判断是否用的方法就是随便拿一个百度获取别的网站,加上代理ip发送get请求,看看status_code()的返回码是不是200,即可。
完整代码如下:
import requests
import traceback
import re
class Downloader(object):
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
def download(self, url):
print('正在下载页面:{}'.format(url))
try:
resp = requests.get(url, headers=self.headers)
if resp.status_code == 200:
return resp.text
else:
raise ConnectionError
except Exception:
print('下载页面出错:{}'.format(url))
traceback.print_exc()
def get_ip_list(self, resp):
try:
# 匹配整体数据的正则
root_pattren = 'alt="Cn" />([\d\D]*?)'
root = re.findall(root_pattren, resp)
list_ip = []
# 再次匹配数据的正则
for i in range(len(root)):
key = re.findall('([\d\D]*?) ', root[i])
list_ip.append(key[3].lower() + '://' + key[0] + ':' + key[1])
return list_ip
except Exception:
print('解析IP地址出错')
traceback.print_exc()
def main():
url = 'https://www.xicidaili.com/'
resp = Downloader().download(url)
info = Downloader().get_ip_list(resp)
for i in info:
print(i)
if __name__ == '__main__':
main()
运行结果为:
正在下载页面:https://www.xicidaili.com/
https://171.41.82.37:9999
https://171.41.82.74:9999
https://180.118.243.185:808
https://49.70.64.221:9999
http://121.61.1.67:9999
http://180.119.141.144:9999
https://125.126.222.12:9999
https://111.177.185.208:9999
https://111.177.182.20:9999
https://60.190.250.120:8080
http://112.85.164.93:9999
http://116.209.59.64:9999
.........
4 参考
- Selenium官网教程
- Selenium Python教程
- Python 爬虫基础Selenium库的使用
- frame标签的理解与获取操作
- switch_to包详解
- 参考6
- 参考7
- 参考8
- python爬虫防止IP被封的一些措施
- User-Agent结构介绍及主流浏览器User-Agent大全
- 参考11