Keepalived 部署及配置
文章目录
- 前言
- 部署
- 配置文件
-
- 全局配置常用指令说明
- vrrp实例常用指令
- 邮件通知
- 配置实现LVS
- 执行脚本检测
- 脑裂解决方案
前言
keepalived的主要由vrrp stack、checkers、ipvs wrapper以及控制组件配置文件分析器,IO复用器,内存管理这些组件组成,其中vrrp stack 是用来实现vip的高可用;checkers用于基于不同协议对后端服务做检测,它两都是基于系统调用和SMTP协议来完成对vip的转移,以及故障转移后的邮件通知,以及vip和后端服务的检测;ipvs wrapper主要用于生成ipvs规则;而对于keepalved的核心组件vrrp stack 和checkers是由watchdog进程一直监控着,一旦vrrp stack 或者checkers宕掉,watchdog会立即启动一个新的vrrp stack或checkers,从而保证了keepalived自身的组件的高可用;
部署
环境说明
准备两台keepalived服务器,各server必须满足时间同步,确保iptables及selinux都是关闭着;如果有必要可以配置各节点通过hosts文件解析以及各节点的ssh互信
还需要确保我们的网卡支持多播功能

如果网卡没有启动多播功能需要用ip link set multicast on dev 网卡名称即可
安装keepalived
yum install keepalived -y
查看keepalived的程序环境
rpm -ql keepalived
主配置文件是/etc/keepalived/keepalived.conf;主程序文件/usr/sbin/keepalived;unit file是/usr/lib/systemd/system/keepalived.service;unit file的环境配置文件是/etc/sysconfig/keepalived
拷贝原配置
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived-template.conf
vi /etc/keepalived/keepalived.conf
[root@node1 ~]# cat /etc/keepalived/keepalived.conf
global_defs { #全局配置
notification_email {
root@localhost
}
notification_email_from node01_keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node01
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.12.132
}
vrrp_instance VI_1 {
state MASTER #
interface ens33
virtual_router_id 51 #路由唯一id,一个集群中唯一
priority 100 #权重比,大的为主
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress { #虚拟ip
192.168.100.33/24 brd 192.168.100.254 dev ens33 label ens33:1
}
}
重启
systemctl restart keepalived.service
查看 ens33 网卡,已经绑定192.168.100.33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:95:6c:38 brd ff:ff:ff:ff:ff:ff
inet 192.168.100.11/24 brd 192.168.100.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.100.33/24 brd 192.168.100.254 scope global secondary ens33:1
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe95:6c38/64 scope link
valid_lft forever preferred_lft forever
配置文件
keepalived的配置文件主要由global configuration、vrrpdconfiguration、LVS configuration这三部分配置段组成;
其中global配置段主要定义全局属性以及静态路由和地址相关配置;
vrrp配置段主要定义VRRP实例或vrrp同步组相关配置;
LVS配置段主要定义IPVS集群和LVS后端各real server相关的配置;
keepalived配置说明 :
全局配置常用指令说明
global_defs {…}:用于定义全局配置段,在这个配置段里可以配置全局属性,以及邮件通知相关配置,包含以下 :
- notification_email {…}:该配置段是globald_defs配置段的一个子配置段用于配置当集群发生状态变化时,接受通知的邮箱;
- notification_email_from:用于指定发送邮件的发件人邮箱地址;
- smtp_server:用于指定邮件服务器地址;
- smtp_connect_timeout:用于指定邮件服务器连接超时时间;
- router_id:集群节点ID,通常这个ID是唯一的,不和其他节点相同;
vrrp_skip_check_adv_addr:忽略检查通告vrrp通告和上一次接收的vrrp是同master地址的通告; - vrrp_strict:严格遵守VRRP协议;打开后Ip无法ping通
- vrrp_garp_interval:设定同一接口的两次arp广播的延迟时长,默认为0表示不延迟;
- vrrp_gna_interval:设定同一接口的两次na消息延迟时长,默认为0表示不延迟;
- vrrp_mcast_group4:设定组播ip地址,默认是224.0.0.18;组播地址是一个D类地址,它的范围是224.0.0.0-239.255.255.255;
vrrp_iptables:关闭生成iptables规则;
例子:
global_defs { #全局配置
notification_email {
root@localhost
}
notification_email_from node01_keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node01
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.12.132
}
vrrp实例常用指令
vrrp_instance:指定一个vrrp示例名称,并引用一个配置实例上下文配置段用大括号括起来;包含以下 :
- state:用于定义该vrrp实例的角色,常用的有MASTER和BACKUP两个角色,并且多个节点上同虚拟路由id的实例,只能有一个MASTER角色且优先级是最高的,其他的都为BACKUP优先级都要略小于MASTER角色的优先级;
- interface:用于指定vrrp实例的网卡名称,就是把vip配置在那个接口上;
- virtual_router_id:虚拟路由ID取值范围是0-255;
- advert_int:指定发送心跳间隔时长,默认是1秒;
- priority:指定该实例的优先级;
- authentication {…}:用于定义认证信息;
- auth_type:指定认证类型,常用认证类型有PASS和AH,PASS指简单的密码认证,AH指IPSEC认证;如果使用PASS类型,默认只会取前8个字符作为认证密码;
- auth_pass:指定认证密码
- virtual_ipaddress {…}:用于设定虚拟ip地址的配置,用大括号括起来;定义虚拟ip的语法格式为:/ brd dev scope label ;其中brd用于指定广播地址,dev用于指定接口名称,scope用于指定作用域,label用于指定别名;可以配置多个虚拟ip,通常一个实例中只配置一个虚拟ip;
例 :
vrrp_instance VI_1 {
state MASTER #
interface ens33
virtual_router_id 51 #路由唯一id,一个集群中唯一
priority 100 #权重比,大的为主
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress { #虚拟ip
192.168.100.33/24 brd 192.168.100.254 dev ens33 label ens33:1
}
}
邮件通知
keepalived的故障通知邮件机制,是通过判断当前节点keepalived的角色来触发邮件通知;
keepalived的邮件通知配置
编写邮件通知脚本
[root@node01 keepalived]# cat notify.sh
#!/bin/bash
#
contact='root@localhost'
notify() {
local mailsubject="$(hostname) to be $1, vip floating"
local mailbody="$(date +'%F %T'): vrrp transition, $(hostname) changed to be $1"
echo "$mailbody" | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}"
exit 1
;;
esac
该脚本主要实现了,根据传递不同参数来发送不同内容的邮件
给脚本加上执行权限,并把脚本从node01复制到node02上

安装mail命令
[root@node01 keepalived]# mail
-bash: mail: command not found
[root@node01 keepalived]#
[root@node01 keepalived]# yum install mailx
给脚本传递master|backup参数,测试在本机是否能够发送邮件
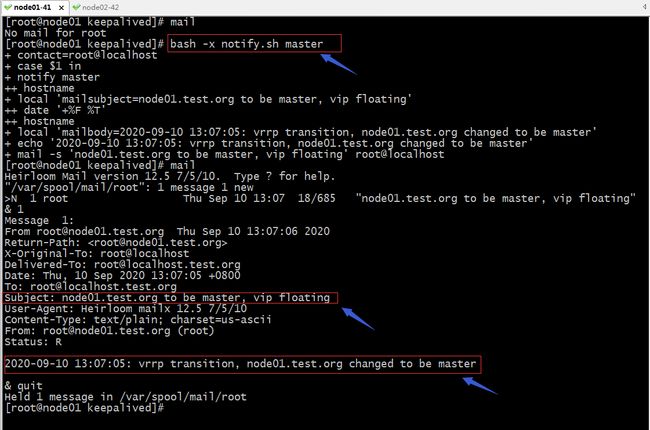
配置keepalived邮件通知
配置keepalived邮件的接收者和发送者

以上配置表示当发生故障转移,邮件通知接收者为root@localhost,发送者为node01_keepalived@localhost,邮件服务器地址为127.0.0.1,超时时长为30秒;
配置keepalived发生故障转移时,触发执行的脚本
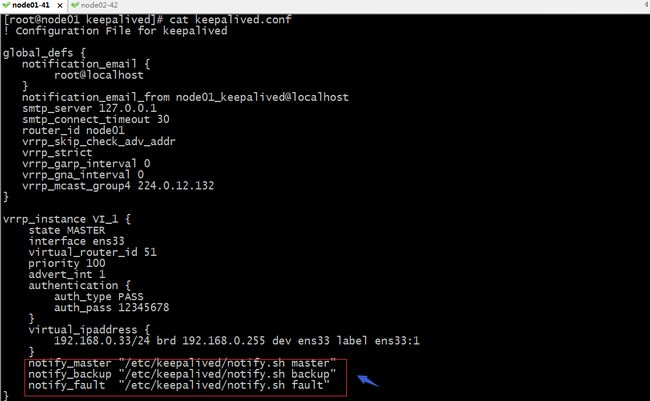
以上配置表示当vrrp VI_1发生故障转移是,如果从master角色转变为backup角色时,就会触发notify_backup指令说指定的脚本和参数发送邮件;如果从backup角色转变为master角色就会触发notify_master指令所指定的脚本和参数来发送邮件,如果当前节点从master或backup角色转变为fault状态时,它会触发notify_fault指令说指定的脚本和参数来发送邮件;
发邮件原文
配置实现LVS

virtual_server用于定义LVS对外集群ip地址和端口(vip),用大括号括起来,包含以下配置 :
- delay_loop用于指定对后端rs做健康状态检查的时间间隔;
- lb_algo/lvs_sched用于指定lvs的调度算法,常用的算法有rr,wrr,lc,wlc,lblc,sh,dh;
- lb_kind/lvs_method用于指定lvs集群的类型,常用的类型有DR,NAT,TUN,需注意这里的类型的值必须大写,否则服务有异常;有关LVS集群类型的相关说明请参考https://www.cnblogs.com/qiuhom-1874/p/12327506.html;
- protocol用于指定4层协议,常用的4层协议有TCP ,UDP,SCTP,需注意这里的值必须大写;
- sorry_server用于指定,当后端RS都宕机情况下,临时对用户说sorry的服务器地址和端口;
- real_server:用来定义后端RS的相关配置,其中weight用于指定当前rs的权重,- nb_get_retry用指定对rs检测的重试次数,如果在指定的次数上都监测失败就标记该RS为下线状态,并从当前集群中下线;
- delay_before_retry用于指定重试之前延迟的时间;
- connect_timeout用于指定对rs检测的超时时长;
- HTTP_GET 用于配置对rs的检查方法,HTTP_GET表示应用层http检测,其中path用于指定检测到uri,status_code用于指定对指定URI检测到状态码,通常为200;
例 :
[root@node01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from node01_keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node01
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.12.132
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
192.168.0.111/24 brd 192.168.0.255 dev ens33 label ens33:1
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
virtual_server 192.168.0.111 80 {
delay_loop 3
lb_algo wrr
lb_kind DR
protocol TCP
sorry_server 127.0.0.1 80
real_server 192.168.0.43 80 {
weight 1
nb_get_retry 2
delay_before_retry 2
connect_timeout 30
HTTP_GET {
url {
path /index.html
status_code 200
}
}
}
real_server 192.168.0.44 80 {
weight 1
nb_get_retry 2
delay_before_retry 2
connect_timeout 30
HTTP_GET {
url {
path /index.html
status_code 200
}
}
}
}
[root@node01 ~]#
以上virtual_server的配置在node02上也是相同的配置;
执行脚本检测
为了实现能够检测到高可用的服务是否正常,keepalived提供了调用外部脚本的接口,让我们配置对高可用的服务做可用性检测;根据我们定义的脚本,keepalived会周期性的去执行我们的定义的脚本,根据脚本执行退出码判断服务是否可用,一旦发生服务不可用,或者可用性检测不通过,它就会触发当前keepalived节点的优先级降低,从而实现当前节点在通告优先级时,触发备份节点接管VIP,从而实现VIP转移,服务的高可用;
在keepalived的配置文件中,我们可以用vrrp_script {…} 来定义我们可以执行的脚本相关信息;用track_script {…}在对应vrrp实例中调用vrrp_script定义的脚本;
定义 :
vrrp_script <SCRIPT_NAME> { #定义一个检测脚本,在global_defs 之外配置
script <STRING>|<QUOTED-STRING> #shell命令或脚本路径
interval <INTEGER> #间隔时间,单位为秒,默认1秒
timeout <INTEGER> #超时时间
weight <INTEGER:-254..254> #默认为0,如果设置此值为负数,当上面脚本返回值为非0时,会将此值与本节点权重相加可以降低本节点权重,即表示fall.
#如果是正数,当脚本返回值为0,会将此值与本节点权重相加可以提高本节点权重,即表示 rise.通常使用负值fall
#执行脚本连续几次都失败,则转换为失败,建议设为2以上
rise <INTEGER> #执行脚本连续几次都成功,把服务器从失败标记为成功
user USERNAME [GROUPNAME] #执行监测脚本的用户或组
init_fail #设置默认标记为失败状态,监测成功之后再转换为成功状态
}
调用 :
vrrp_instance VI_1 {
...
track_script {
<SCRIPT_NAME>
}
}
1、编写脚本
[root@node01 keepalived]# vi check_lvs.sh
#!/bin/bash
ping -c 2 192.168.0.1 &> /dev/null
if [ $? -eq 0 ];then
exit 0
else
exit 1
fi
[root@node01 keepalived]#
以上脚本主要是利用ping 192.168.0.1这个地址来判断推出码是0还是1,正常退出时0,非正常退出为1;
nginx 检查
[root@node01 keepalived]# vi check_nginx.sh
#!/bin/bash
killall -0 nginx
if [ $? -eq 0 ];then
exit 0
else
exit 2
fi
[root@node01 keepalived]#
以上脚本利用killall命令对nginx进程发送0号信号,去判断对应的nginx进程是否存在,如果存在该命令会返回0,否则返回非0;利用命令的返回值来确定脚本退出码;
2、配置keepalived调用上面的脚本,并在VIP所在实例中引用;

以上配置表示定义了一个脚本,名为check_LVS(这个名称可以任意起,主要起标识作用,后面在实例中引用的一个标识);这个脚本执行时间间隔为每2秒执行一次,超时时长为2秒,如果脚本执行失败(退出码非0)就把对应节点的优先级降低20(通常这个降低的值要大于两节点优先级之差就行,意思就是降低后的优先级要小于备份节点优先级,这样才有意义);脚本执行连续3次检测都为成功状态(脚本退出码都为0),则keepalived就标记该实例为OK状态,并会一直检测下去,如果连续3次检查都为失败状态(退出码非0),则标记对应实例为KO状态;一旦标记对应实例为失败状态就会触发当前节点的优先级降低;从而在通告心跳时,会通告降低后的优先级,从而实现备份节点接管VIP来完成vip转移;
keepalived 代码:
[root@node01 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from node01_keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node01
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_iptables
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.12.132
}
vrrp_script check_LVS {
script "/etc/keepalived/check_lvs.sh"
interval 2
timeout 2
weight -20
rise 3
fall 3
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
interval 2
timeout 2
weight -20
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 12345678
}
virtual_ipaddress {
192.168.0.111/24 brd 192.168.0.255 dev ens33 label ens33:1
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
track_script {
check_LVS
check_nginx
}
}
[root@node01 ~]#
vrrp_script需要定义在实例之外,表示引用一段上下文来定义脚本相关信息;定义了脚本信息,如果不在实例中引用,它是不会周期性的去执行脚本,只有在实例中引用的脚本名称以后(这里的名称是vrrp_script后面的名称)才会使对应的脚本周期性的去执行;
详细讲解博客
脑裂解决方案
(1)可以采用第三方仲裁的方法。由于keepalived体系中主备两台机器所处的状态与对方有关。如果主备机器之间的通信出了网题,就会发生脑裂,此时keepalived体系中会出现双主的情况,产生资源竞争。
(2)一般可以引入仲裁来解决这个问题,即每个节点必须判断自身的状态。最简单的一种操作方法是,在主备的keepalived的配置文件中增加check配置,服务器周期性地ping一下网关,如果ping不通则认为自身有问题 。
(3)最容易的是借助keepalived提供的vrrp_script及track_script实现。如下所示:
#vim /etc/keepalived/keepalived.conf
......
vrrp_script check_local {
script "/root/check_gateway.sh"
interval 5
}
......
track_script {
check_local
}
脚本内容:
# cat /root/check_gateway.sh
#!/bin/sh
VIP=$1
GATEWAY=192.168.1.1
/sbin/arping -I em1 -c 5 -s $VIP $GATEWAY &>/dev/null
check_gateway.sh 就是我们的仲裁逻辑,发现ping不通网关,则关闭keepalived。
写一个while循环,每轮ping网关,累计连续失败的次数,当连续失败达到一定次数则运行service keepalived stop关闭keepalived服务。
如果发现又能够ping通网关,再重启keepalived服务。最后在脚本开头再加上脚本是否已经运行的判断逻辑,将该脚本加到crontab里面。
1.使用shell脚本对这两个主机之间的连通性进行监测,如果发现有问题,就会立即关闭keepalived服务来防止脑裂的产生。
2.增加一条链路作为备用链路,即使主链路挂掉了,备用链路也会顶上来,master主机可以继续给backup主机发送心跳消息。
3.3.使用监控软件的方法,这边主要是采用的zabbix来监控的,主要就是创建监控项,创建触发器来测试关闭keepalived服务。
参考脚本 :
[root@lb02 scripts]# vim check_keepalived.sh
#!/bin/bash
while true do
if [ `ip a show eth0 |grep 10.0.0.3|wc -l` -ne 0 ]
then echo "keepalived is error!"
else echo "keepalived is OK !"
fi
done