Docker实战03|Cgroups
在上一文《Docker实战02|Namespace》中主要介绍了Linux Namespace的基本原理以及实现。相信读完以后可以更加深入的了解Docker关于Namespace的底层实现原理了。
本文继续针对Cgroups技术展开讲解并利用Go语言进行实践。
本系列所有代码均已经开源。关公众号回复「Go语言实现Docker」即可获得。
目录
- 2.2.1 什么是 Linux Cgroups
- 2.2.2 如何使用Cgroups
- 2.2.3 Docker 是如何使用 Cgroups 的
2.2 Linux Cgroups介绍
在上一文中,主要讲述了构建Linux容器的Namespace技术,它帮助进程隔离出自己单独的空间,但Docker是怎么限制每个空间的大小,保证它们不会互相争抢的呢?这就要用到Linux的Cgroups技术。
2.2.1 什么是 Linux Cgroups
Cgroups 是 Linux 下的一种将进程按组进行管理的机制,它提供了对一组进程及将来子进程的资源限制控制和统计的能力。
这些资源包括 CPU、内存、存储、网络等。通过 Cgroups 可以方便地限制某个进程的资源占用,并且可以实时地监控进程的监控与统计信息
Cgroups 中的 3 个组件
-
cgroups 本身:cgroup 是对进程分组管理的一种机制,一个 cgroup 包含一组进程,并可以在这个 cgroup 上增加 Linux subsystem 的各种参数配置,将一组进程和一组 subsystem 的系统参数关联起来。
-
subsystem: 一个 subsystem 就是一个内核模块,他被关联到一颗 cgroup 树之后,就会在树的每个节点(进程组)上做具体的操作。subsystem 经常被称作"resource controller",因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如 perf_event subsystem。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU 的使用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等,后续会对它们一一进行介绍。
-
hierarchy:一个 hierarchy 可以理解为一棵 cgroup 树,树的每个节点就是一个进程组,每棵树都会与零到多个 subsystem 关联。在一颗树里面,会包含 Linux 系统中的所有进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗 cgroup 树,每棵树都和不同的 subsystem 关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,只是这些进程组和不同的 subsystem 关联。目前 Linux 支持 12 种 subsystem,如果不考虑不与任何 subsystem 关联的情况(systemd 就属于这种情况),Linux 里面最多可以建 12 颗 cgroup 树,每棵树关联一个 subsystem,当然也可以只建一棵树,然后让这棵树关联所有的 subsystem。当一颗 cgroup 树不和任何 subsystem 关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定,systemd 就是一个这样的例子。
3 个部分间的关系
- 系统在创建了新的 hierarchy 之后,系统中所有的进程都会加入这个 hierarchy 的 cgroup 根节点,这个 cgroup 根节点是 hierarchy 默认创建的。
- 一个 subsystem 只能附加到 一 个 hierarchy 上面。
- 一个 hierarchy 可以附加多个 subsystem 。
- 一个进程可以作为多个 cgroup 的成员,但是这些 cgroup 必须在不同的 hierarchy 中。
- 一个进程 fork 出子进程时,子进程是和父进程在同一个 cgroup 中的,也可以根据需要将其移动到其他 cgroup 中。
看完上面的内容好像依旧对三者之间的关系很模糊。
来看下图:
Cgroups层级结构
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级结构。cgroups层级结构可以 attach 一个或者几个 cgroups 子系统,当前层级结构可以对其 attach 的 cgroups 子系统进行资源的限制。每一个 cgroups 子系统只能被 attach 到一个 cpu 层级结构中。
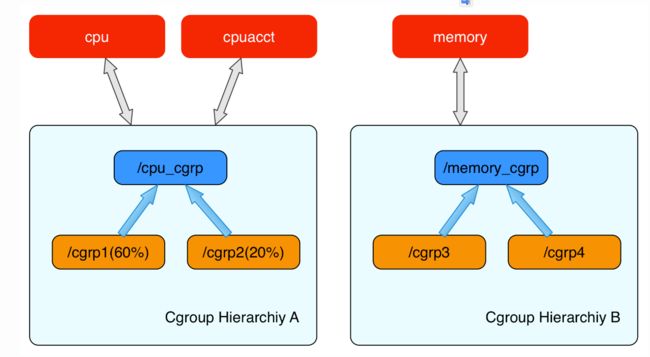
比如上图表示两个cgroups层级结构,每一个层级结构中是一颗树形结构,树的每一个节点是一个 cgroup 结构体(比如cpu_cgrp, memory_cgrp)。第一个 cgroups 层级结构 attach 了 cpu 子系统和 cpuacct 子系统, 当前 cgroups 层级结构中的 cgroup 结构体就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。 第二个 cgroups 层级结构 attach 了 memory 子系统,当前 cgroups 层级结构中的 cgroup 结构体就可以对 memory 的资源进行限制。
在每一个 cgroups 层级结构中,每一个节点(cgroup 结构体)可以设置对资源不同的限制权重。比如上图中 cgrp1 组中的进程可以使用60%的 cpu 时间片,而 cgrp2 组中的进程可以使用20%的 cpu 时间片。
Cgroups与进程
在创建了 cgroups 层级结构中的节点(cgroup 结构体)之后,可以把进程加入到某一个节点的控制任务列表中,一个节点的控制列表中的所有进程都会受到当前节点的资源限制。同时某一个进程也可以被加入到不同的 cgroups 层级结构的节点中,因为不同的 cgroups 层级结构可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。
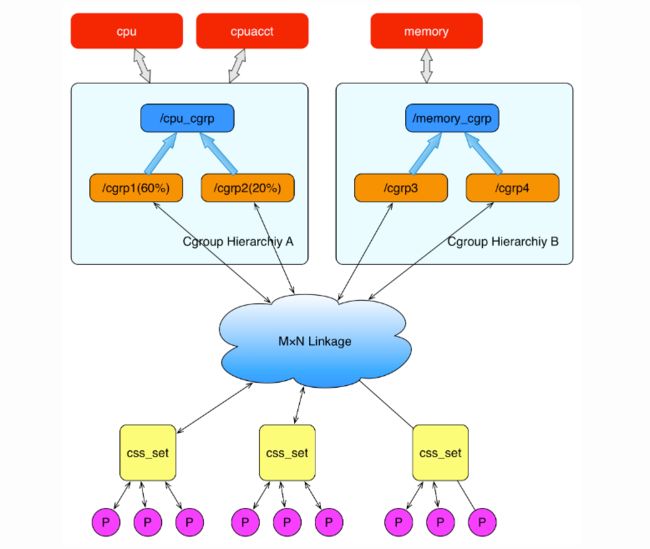
上面这个图从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级结构下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
2.2.2 如何使用Cgroups
查看subsystem列表
可以通过查看/proc/cgroups(since Linux 2.6.24)知道当前系统支持哪些 subsystem,下面是一个例子:

从左到右,字段的含义分别是:
- subsys_name:subsystem 的名字
- hierarchy:subsystem 所关联到的 cgroup 树的 ID,如果多个 subsystem 关联到同一颗 cgroup 树,那么他们的这个字段将一样,比如这里的 cpu 和 cpuacct 就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为 0:
- 当前 subsystem 没有和任何 cgroup 树绑定
- 当前 subsystem 已经和 cgroup v2 的树绑定
- 当前 subsystem 没有被内核开启
- num_cgroups:subsystem 所关联的 cgroup 树中进程组的个数,也即树上节点的个数
- enabled:1 表示开启,0 表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制 subsystem 的开启).
hierarchy 相关操作
挂载
Linux 中,用户可以使用 mount 命令挂载 cgroups 文件系统:
语法为:
mount -t cgroup -o subsystems name /cgroup/name
- 其中 subsystems 表示需要挂载的 cgroups 子系统
- /cgroup/name 表示挂载点
这条命令同在内核中创建了一个 hierarchy 以及一个默认的 root cgroup。
示例:挂载一个和 cpuset subsystem 关联的 hierarchy 到 ./cg1 目录
# 首先肯定是创建对应目录
mkdir cg1
# 具体挂载操作--参数含义如下
# -t cgroup 表示操作的是 cgroup 类型,
# -o cpuset 表示要关联 cpuset subsystem,可以写0个或多个,0个则是关联全部subsystem,
# cg1 为 cgroup 的名字,
# ./cg1 为挂载目标目录。
mount -t cgroup -o cpuset cg1 ./cg1
# 挂载一颗和所有subsystem关联的cgroup树到cg1目录
mkdir cg1
mount -t cgroup cg1 ./cg1
#挂载一颗与cpu和cpuacct subsystem关联的cgroup树到 cg1 目录
mkdir cg1
mount -t cgroup -o cpu,cpuacct cg1 ./cg1
# 挂载一棵cgroup树,但不关联任何subsystem,这systemd所用到的方式
mkdir cg1
mount -t cgroup -o none,name=cg1 cg1 ./cg1
卸载
作为文件系统,同样是使用umount命令卸载。
# 指定路径来卸载,而不是名字。
$ umount /path/to/your/hierarchy
2.2.3 Docker 是如何使用 Cgroups 的
我们知道Docker是通过Cgroups实现容器资源限制和监控的,下面以一个实际的容器实例来看一下Docker是如何配置Cgroups的。
# docker run -m 设置内存限制
#docker run -itd -m 128m ubuntu
bd15e72b14ff3d3edb8fdd67323a3670270b1b8e883d251b1699458a9292f849
# docker 会为每个容器在系统的 hierarchy 中创建 cgroup
查看内存使用大小与限制

2.2.4 Go语言实现通过Cgroups限制容器资源
package cgroups
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strconv"
"syscall"
)
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
// cGroups cGroups初体验
func CGroups() {
// /proc/self/exe是一个符号链接,代表当前程序的绝对路径
if os.Args[0] == "/proc/self/exe" {
// 第一个参数就是当前执行的文件名,所以只有fork出的容器进程才会进入该分支
fmt.Printf("容器进程内部 PID %d\n", syscall.Getpid())
// 需要先在宿主机上安装 stress 比如 apt-get install stress
cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println(err)
os.Exit(1)
}
} else {
// 主进程会走这个分支
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWNS | syscall.CLONE_NEWPID}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start(); err != nil {
fmt.Println(err)
os.Exit(1)
}
// 得到 fork 出来的进程在外部namespace 的 pid
fmt.Println("fork 进程 PID:", cmd.Process.Pid)
// 在默认的 memory cgroup 下创建子目录,即创建一个子 cgroup
err := os.Mkdir(filepath.Join(cgroupMemoryHierarchyMount, "testmemorylimit"), 0755)
if err != nil {
fmt.Println(err)
}
// 将容器加入到这个 cgroup 中,即将进程PID加入到cgroup下的 cgroup.procs 文件中
err = ioutil.WriteFile(filepath.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "cgroup.procs"),
[]byte(strconv.Itoa(cmd.Process.Pid)), 0644)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
// 限制进程的内存使用,往 memory.limit_in_bytes 文件中写入数据
err = ioutil.WriteFile(filepath.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "memory.limit_in_bytes"),
[]byte("100m"), 0644)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
cmd.Process.Wait()
}
}

未完待续。。。
下一篇将会继续介绍Docker中AUFS的核心原理。
所有Docker实战内容合集:《Docker就应该这么学》
本文所有内容都是基于「动手写Docker」此书。关注公众号,后台回复“动手写Docker”即可领取。
同时,准备了一份云原生实战大礼包送给大家,关注公众号,后台回复“云原生资料”即可领取。

在上一文《Docker实战02|Namespace》中主要介绍了Linux Namespace的基本原理以及实现。相信读完以后可以更加深入的了解Docker关于Namespace的底层实现原理了。
本文继续针对Cgroups技术展开讲解并利用Go语言进行实践。
本系列所有代码均已经开源。关公众号回复「Go语言实现Docker」即可获得。
目录
- 2.2.1 什么是 Linux Cgroups
- 2.2.2 如何使用Cgroups
- 2.2.3 Docker 是如何使用 Cgroups 的
2.2 Linux Cgroups介绍
在上一文中,主要讲述了构建Linux容器的Namespace技术,它帮助进程隔离出自己单独的空间,但Docker是怎么限制每个空间的大小,保证它们不会互相争抢的呢?这就要用到Linux的Cgroups技术。
2.2.1 什么是 Linux Cgroups
Cgroups 是 Linux 下的一种将进程按组进行管理的机制,它提供了对一组进程及将来子进程的资源限制控制和统计的能力。
这些资源包括 CPU、内存、存储、网络等。通过 Cgroups 可以方便地限制某个进程的资源占用,并且可以实时地监控进程的监控与统计信息
Cgroups 中的 3 个组件
-
cgroups 本身:cgroup 是对进程分组管理的一种机制,一个 cgroup 包含一组进程,并可以在这个 cgroup 上增加 Linux subsystem 的各种参数配置,将一组进程和一组 subsystem 的系统参数关联起来。
-
subsystem: 一个 subsystem 就是一个内核模块,他被关联到一颗 cgroup 树之后,就会在树的每个节点(进程组)上做具体的操作。subsystem 经常被称作"resource controller",因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如 perf_event subsystem。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU 的使用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等,后续会对它们一一进行介绍。
-
hierarchy:一个 hierarchy 可以理解为一棵 cgroup 树,树的每个节点就是一个进程组,每棵树都会与零到多个 subsystem 关联。在一颗树里面,会包含 Linux 系统中的所有进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗 cgroup 树,每棵树都和不同的 subsystem 关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,只是这些进程组和不同的 subsystem 关联。目前 Linux 支持 12 种 subsystem,如果不考虑不与任何 subsystem 关联的情况(systemd 就属于这种情况),Linux 里面最多可以建 12 颗 cgroup 树,每棵树关联一个 subsystem,当然也可以只建一棵树,然后让这棵树关联所有的 subsystem。当一颗 cgroup 树不和任何 subsystem 关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定,systemd 就是一个这样的例子。
3 个部分间的关系
- 系统在创建了新的 hierarchy 之后,系统中所有的进程都会加入这个 hierarchy 的 cgroup 根节点,这个 cgroup 根节点是 hierarchy 默认创建的。
- 一个 subsystem 只能附加到 一 个 hierarchy 上面。
- 一个 hierarchy 可以附加多个 subsystem 。
- 一个进程可以作为多个 cgroup 的成员,但是这些 cgroup 必须在不同的 hierarchy 中。
- 一个进程 fork 出子进程时,子进程是和父进程在同一个 cgroup 中的,也可以根据需要将其移动到其他 cgroup 中。
看完上面的内容好像依旧对三者之间的关系很模糊。
来看下图:
Cgroups层级结构
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级结构。cgroups层级结构可以 attach 一个或者几个 cgroups 子系统,当前层级结构可以对其 attach 的 cgroups 子系统进行资源的限制。每一个 cgroups 子系统只能被 attach 到一个 cpu 层级结构中。

比如上图表示两个cgroups层级结构,每一个层级结构中是一颗树形结构,树的每一个节点是一个 cgroup 结构体(比如cpu_cgrp, memory_cgrp)。第一个 cgroups 层级结构 attach 了 cpu 子系统和 cpuacct 子系统, 当前 cgroups 层级结构中的 cgroup 结构体就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。 第二个 cgroups 层级结构 attach 了 memory 子系统,当前 cgroups 层级结构中的 cgroup 结构体就可以对 memory 的资源进行限制。
在每一个 cgroups 层级结构中,每一个节点(cgroup 结构体)可以设置对资源不同的限制权重。比如上图中 cgrp1 组中的进程可以使用60%的 cpu 时间片,而 cgrp2 组中的进程可以使用20%的 cpu 时间片。
Cgroups与进程
在创建了 cgroups 层级结构中的节点(cgroup 结构体)之后,可以把进程加入到某一个节点的控制任务列表中,一个节点的控制列表中的所有进程都会受到当前节点的资源限制。同时某一个进程也可以被加入到不同的 cgroups 层级结构的节点中,因为不同的 cgroups 层级结构可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。

上面这个图从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级结构下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
2.2.2 如何使用Cgroups
查看subsystem列表
可以通过查看/proc/cgroups(since Linux 2.6.24)知道当前系统支持哪些 subsystem,下面是一个例子:

从左到右,字段的含义分别是:
- subsys_name:subsystem 的名字
- hierarchy:subsystem 所关联到的 cgroup 树的 ID,如果多个 subsystem 关联到同一颗 cgroup 树,那么他们的这个字段将一样,比如这里的 cpu 和 cpuacct 就一样,表示他们绑定到了同一颗树。如果出现下面的情况,这个字段将为 0:
- 当前 subsystem 没有和任何 cgroup 树绑定
- 当前 subsystem 已经和 cgroup v2 的树绑定
- 当前 subsystem 没有被内核开启
- num_cgroups:subsystem 所关联的 cgroup 树中进程组的个数,也即树上节点的个数
- enabled:1 表示开启,0 表示没有被开启(可以通过设置内核的启动参数“cgroup_disable”来控制 subsystem 的开启).
hierarchy 相关操作
挂载
Linux 中,用户可以使用 mount 命令挂载 cgroups 文件系统:
语法为:
mount -t cgroup -o subsystems name /cgroup/name
- 其中 subsystems 表示需要挂载的 cgroups 子系统
- /cgroup/name 表示挂载点
这条命令同在内核中创建了一个 hierarchy 以及一个默认的 root cgroup。
示例:挂载一个和 cpuset subsystem 关联的 hierarchy 到 ./cg1 目录
# 首先肯定是创建对应目录
mkdir cg1
# 具体挂载操作--参数含义如下
# -t cgroup 表示操作的是 cgroup 类型,
# -o cpuset 表示要关联 cpuset subsystem,可以写0个或多个,0个则是关联全部subsystem,
# cg1 为 cgroup 的名字,
# ./cg1 为挂载目标目录。
mount -t cgroup -o cpuset cg1 ./cg1
# 挂载一颗和所有subsystem关联的cgroup树到cg1目录
mkdir cg1
mount -t cgroup cg1 ./cg1
#挂载一颗与cpu和cpuacct subsystem关联的cgroup树到 cg1 目录
mkdir cg1
mount -t cgroup -o cpu,cpuacct cg1 ./cg1
# 挂载一棵cgroup树,但不关联任何subsystem,这systemd所用到的方式
mkdir cg1
mount -t cgroup -o none,name=cg1 cg1 ./cg1
卸载
作为文件系统,同样是使用umount命令卸载。
# 指定路径来卸载,而不是名字。
$ umount /path/to/your/hierarchy
2.2.3 Docker 是如何使用 Cgroups 的
我们知道Docker是通过Cgroups实现容器资源限制和监控的,下面以一个实际的容器实例来看一下Docker是如何配置Cgroups的。
# docker run -m 设置内存限制
#docker run -itd -m 128m ubuntu
bd15e72b14ff3d3edb8fdd67323a3670270b1b8e883d251b1699458a9292f849
# docker 会为每个容器在系统的 hierarchy 中创建 cgroup
查看内存使用大小与限制

2.2.4 Go语言实现通过Cgroups限制容器资源
package cgroups
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strconv"
"syscall"
)
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
// cGroups cGroups初体验
func CGroups() {
// /proc/self/exe是一个符号链接,代表当前程序的绝对路径
if os.Args[0] == "/proc/self/exe" {
// 第一个参数就是当前执行的文件名,所以只有fork出的容器进程才会进入该分支
fmt.Printf("容器进程内部 PID %d\n", syscall.Getpid())
// 需要先在宿主机上安装 stress 比如 apt-get install stress
cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println(err)
os.Exit(1)
}
} else {
// 主进程会走这个分支
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWNS | syscall.CLONE_NEWPID}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Start(); err != nil {
fmt.Println(err)
os.Exit(1)
}
// 得到 fork 出来的进程在外部namespace 的 pid
fmt.Println("fork 进程 PID:", cmd.Process.Pid)
// 在默认的 memory cgroup 下创建子目录,即创建一个子 cgroup
err := os.Mkdir(filepath.Join(cgroupMemoryHierarchyMount, "testmemorylimit"), 0755)
if err != nil {
fmt.Println(err)
}
// 将容器加入到这个 cgroup 中,即将进程PID加入到cgroup下的 cgroup.procs 文件中
err = ioutil.WriteFile(filepath.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "cgroup.procs"),
[]byte(strconv.Itoa(cmd.Process.Pid)), 0644)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
// 限制进程的内存使用,往 memory.limit_in_bytes 文件中写入数据
err = ioutil.WriteFile(filepath.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "memory.limit_in_bytes"),
[]byte("100m"), 0644)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
cmd.Process.Wait()
}
}

未完待续。。。
下一篇将会继续介绍Docker中AUFS的核心原理。
所有Docker实战内容合集:《Docker就应该这么学》
本文所有内容都是基于「动手写Docker」此书。关注公众号,后台回复“动手写Docker”即可领取。
同时,准备了一份云原生实战大礼包送给大家,关注公众号,后台回复“云原生资料”即可领取。