Go (一) 基础部分5 -- 单元测试,协程(goroutine),管道(channel)
一、单元测试
Go自带一个轻量级的"测试框架testing"和自带的"go test"命令来实现单元测试和性能测试。
1.确保每个函数时可运行,并且运行结果是正确的。
2.确保写出来的代码性能是好的。
3.单元测试能及时的发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决。而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定。运用测试用例的指令:
go test:运行正确时,无日志,运行错误时,会输出日志。
go test -v:运行正确或者错误都会输出日志。
1.1、单元测试的快速入门(判断一个函数的执行结果是否符合预期)
1.测试用例文件必须以"_test.go"结尾,文件不能命名为:_test.go,test.go,test_xxx.go;
2.测试用例文件内任何 "Test开头且首字母大写"的函数(例:TestXxx)都会被执行,文件内不需要写main函数;
3.TestXxx(t *testing.T)的形参类型必须时*testing.T;
4.出现错误时,可以使用"t.Fatalf"来格式化错误信息,并退出程序;
5."t.Logf"方法可以输出相应的日志;
6.测试用例函数,没有main函数,也正常执行了,这也是测试用例的方便之处;
7.PASS表示测试用例运行成功,FAIL表示测试用例运行失败;
8.测试单个文件"cal_test.go",一定要带上被测试的原文件:go test -v cal_test.go main.go
9.测试单个方法:go test -v -test.run(固定参数) TestAddUpper(函数名)
package main import ( "fmt" "testing" ) // 使用go test命令,能够自动执行如下形式的任何函数 // func TestXxx(*testing.T),其中Xxx可以是任何字母或字符串(第一个字母不能是[a-z]) func TestAddUpper(t *testing.T) { res := AddUpper(10) if res != 55 { t.Fatalf("AddUpper函数执行错误,期望值:%v 返回值:%v",55,res) } t.Logf("AddUpper函数执行成功") } func TestSudada(t *testing.T) { fmt.Println("函数TestSudada被执行") }测试函数:xxx.go,文件内包含要测试的"函数",文件内不需要写main函数。
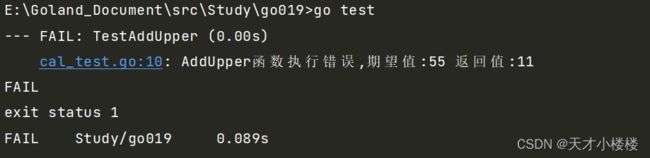
package main // xxx_test.go 内调用的函数 func AddUpper(n int) int { res:=0 for i:=0;i<=10;i++{ res+=i } return res }"go test"命令执行错误时的返回结果
"go test"命令执行正确时的返回
1.2、单元测试-综合案例
测试用例文件:store_test.go(测试结构体的序列化和反序列化)
package main import ( "fmt" "testing" ) // 测试用例TestStore func TestStore(t *testing.T) { // 先创建结构体变量 var monster = Monster{ Name: "牛魔王", Age: 18, Skill: "蛮牛冲撞", } StoreRes:=monster.Store() if !StoreRes { fmt.Println("Store函数测试错误,返回值不为ture") } // 返回值: // === RUN TestStore // Store方法执行成功,test.txt文件保存成功 // --- PASS: TestStore (0.00s) } // 测试用例TestReStore func TestReStore(t *testing.T) { // 先创建结构体变量 var monster = Monster{} ReStoreRes:=monster.ReStore() if !ReStoreRes { fmt.Println("ReStore函数测试错误,返回值不为ture") } // 返回值: // === RUN TestReStore // ReStore方法执行成功,反序列化的值为 &{牛魔王 18 蛮牛冲撞} // --- PASS: TestReStore (0.00s) }被测试对象:main.go(结构体和方法)
package main import ( "encoding/json" "fmt" "io/ioutil" ) type Monster struct { Name string Age int Skill string } func (this *Monster)Store() bool { // 序列化结构体变量 data, err := json.Marshal(this) if err != nil { fmt.Println("序列化失败",err) return false } // 把序列化后的数据,写入到test.txt文件内 WriteFileErr :=ioutil.WriteFile("test.txt",data,0666) if WriteFileErr != nil{ fmt.Println("文件保存失败",WriteFileErr) return false } fmt.Println("Store方法执行成功,test.txt文件保存成功") return true } func (this *Monster)ReStore() bool { // 从文件中,读取序列化的数据 data, ReadFileErr := ioutil.ReadFile("test.txt") if ReadFileErr != nil{ fmt.Println("文件读取失败",ReadFileErr) return false } // 将读到的数据,执行反序列化 err := json.Unmarshal(data, this) if err != nil{ fmt.Println("反序列化失败",err) return false } fmt.Println("ReStore方法执行成功,反序列化的值为:",this) return true }

二、goroutine(协程)
一个go线程上,可以起多个协程,协程是轻量级的线程。
Go协程的特点:有独立的栈空间,共享程序堆空间,调度由用户控制,协程是轻量级的线程
2.1、gorouting快速入门案例
协程的执行流程:
1.程序开始(进程/主线程开始执行);
2.go test() 开启协程:协程此时开始执;行,如果主线程退出了,那么无论协程是否执行完毕,都会退出;
3.主线程(main)执行代码逻辑;
4.主线程结束(程序退出)。案例:在主线程中,启动一个gorouting,该协程每隔1秒输出一个"hello world"
package main import ( "fmt" "time" ) // func test() { for i:=0;i<10;i++ { fmt.Println("test() hello world",i) time.Sleep(time.Second) } } func main() { // 开启一个协程 go test() for i:=0;i<10;i++ { fmt.Println("main() hello world",i) time.Sleep(time.Second) } } // 输出结果 main() hello world 0 test() hello world 0 test() hello world 1 main() hello world 1 main() hello world 2 test() hello world 2 test() hello world 3 main() hello world 3 main() hello world 4 test() hello world 4 test() hello world 5 main() hello world 5 main() hello world 6 test() hello world 6 test() hello world 7 main() hello world 7 main() hello world 8 test() hello world 8 test() hello world 9 main() hello world 92.1.1、协程的快速入门小结
1.主线程是物理线程,作用在CPU上。是重量级的,非常耗费cpu资源。
2.协程是从主线程开启的,是轻量级的线程,是逻辑态,对资源消耗相对小。
3.Golang的协程机制是重要的特点,可以轻松开启上万个协程。
2.2、MPG模式
M:操作系统的主线程
P:协程执行需要的上下文
G:协程(gorouting)
2.3、Go设置运行cpu数目
为了充分利用多CPU的优势,在golang程序中,设置运行的cpu数目(go1.8版本之后,默认让程序运行在多核上,可不设置)
package main import ( "fmt" "runtime" ) func main() { // 常看当前主机的CPU核数 cpuNum:=runtime.NumCPU() fmt.Println(cpuNum) // 可以自定义设置golang运行的cpu数 runtime.GOMAXPROCS(5) fmt.Println("ok") }
三、channel(管道)
在运行程序时,如何知道是否存在资源争抢的问题?
在编译程序时,增加一个参数 -race 即可。
3.1、全局锁的定义和使用
// 定义一个全局互斥锁 var lock sync.Mutex func main() { // 加锁 lock.Lock() 代码逻辑... // 解锁 lock.Unlock() }3.2、channel(管道)的基本介绍 - 引用类型
3.2.1、为什么要使用channel
1.channel本质就是一个数据结构-队列 (先进先出);
2.线程安全,多gorouting访问时,不需要加锁,就是说channel本身就是线程安全的 (多个协程操作同一个管道时,不会发生资源竞争问题);
3.channel是有类型的,一个string类型的channel只能存放string类型数据;
3.2.2、channel的基本语法
var 变量名 chan 数据类型
var intChan chan int (intChan用于存放int数据)
var mapChan chan map[int]string (mapChan用于存放map[int]string数据)
var perChan chan Person (perChan用于存放结构体)
var perChan chan *Person (perChan用于存放结构体指针)
说明:
channel是引用类型
channel必须初始化才能雪茹数据,即make后才能使用
3.3、channel的快速入门(管道创建,写数据,读数据)
package main import "fmt" func main() { // 定义intChan var intChan chan int // 初始化intChan:初始化类型为chan,类型为int,容量为3 intChan = make(chan int, 3) // 查看管道的值是什么 fmt.Println(intChan) // 得到的是一个指针地址 // 向管道中写入数据(写入的数据数量,不能超过管道的容量,如果超过会报错deadlock) intChan<- 10 // "<- 10" 向管道内写入一个数据"10" num:=20 intChan<-num // "<- num" 向管道内写入一个变量的值"20" // 查看管道的长度(追加了2个数据) fmt.Println(len(intChan)) // 返回值:2 // 查看管道的cap(容量)(make时设置的容量为3) fmt.Println(cap(intChan)) // 返回值:3 // 从管道中取出一个值(长度会减少,容量不变) var num2 int num2 = <-intChan fmt.Println(num2) // 返回值为:10 //var num3 int //num3 = <-intChan //fmt.Println(num3) // 返回值为:20 // 取出一个数据,不接收 <-intChan // 管道的数据全部取完后,会报错deadlock var num4 int num4 = <-intChan fmt.Println(num4) // 返回值为:deadlock! }3.3.1、channel的注意事项
1.channel定义好了数据类型之后,只能存放指定的数据类型;
2.channel的数据存满之后,就不能在存入了;
3.channel的数据取完之后,才可以继续存入;
4.在没有使用协程的情况下,如果channel的数据取完了,再取的话,就会报错deadlock。
3.3.2、案例1:创建一个intChan,存放int类型的数据,然后取出
package main import "fmt" func main() { // 定义intChan var intChan chan int // 初始化chan intChan = make(chan int, 10) // 给管道添加值 intChan<-10 intChan<-20 intChan<-30 // 从管道取值 num1:=<-intChan num2:=<-intChan num3:=<-intChan fmt.Println(num1,num2,num3) }3.3.3、案例2:创建一个mapChan,存放map[string]string数据,然后取出
package main import "fmt" func main() { // 定义chan var mapChan chan map[string]string // 初始化chan mapChan = make(chan map[string]string,10) // 给管道添加值(map类型先make) m1 := make(map[string]string,10) m1["name1"]="北京" m1["name2"]="天津" m2 := make(map[string]string,10) m2["name1"]="上海" m2["name2"]="南京" mapChan<-m1 mapChan<-m2 // 从管道取值 m11:=<-mapChan m22:=<-mapChan fmt.Println(m11) // map[name1:北京 name2:天津] fmt.Println(m22) // map[name1:上海 name2:南京] }3.3.4、案例3:创建一个catChan,存放Cat结构体变量数据,然后取出
package main import "fmt" type Cat struct { Name string Age int } func main() { // 定义chan var catChan chan Cat // 初始化chan catChan = make(chan Cat,10) cat1:=Cat{ Name: "Tom", Age: 2, } cat2:=Cat{ Name: "TTome", Age: 2, } // 给管道赋值 catChan<-cat1 catChan<-cat2 // 管道取值 cat11:=<-catChan cat22:=<-catChan fmt.Println(cat11) // 返回值:{Tom 2} fmt.Println(cat22) // 返回值:{TTome 2} }3.3.5、案例4:创建一个allChan,存放任意类型的数据,然后取出
package main import "fmt" type Cat struct { Name string Age int } func main() { // 定义chan allChan := make(chan any,3) // chan赋值 allChan<-"sudada" allChan<-123 cat:=Cat{ Name: "Tom", Age: 2, } allChan<-cat // 只想获取管道的第三个值时(需要现将前2个值推出) <-allChan <-allChan // 获取到的第三个值 cat1:=<-allChan fmt.Println(cat1) // 返回值:{Tom 2} // 查看管道内值的类型 fmt.Printf("%T\n",cat1) // 返回值:main.Cat // fmt.Println(cat1.Name) // 直接获取结构体的值会报错:cat1.Name undefined (type any has no field or method Name) // 使用类型断言 newCat:=cat1.(Cat) fmt.Println(newCat.Name) // 返回值:Tom }3.4、channel的遍历和关闭
3.4.1、channel的关闭 close(xxxChan)
使用内置函数close()就可以关闭channel,当channel关闭后,就不能在往里面写数据了,但是仍然可以读取数据。
package main import "fmt" func main() { // 定义并初始化chan intChan:=make(chan int,3) // 管道赋值 intChan<-100 intChan<-200 // 管道关闭 close(intChan) //intChan<-300 // 管道关闭后,在往里面写数据时,会报错:panic: send on closed channel // 管道关闭后,读取值 num1:=<-intChan num2:=<-intChan fmt.Println(num1) // 返回值:100 fmt.Println(num2) // 返回值:200 }3.4.2、channel的遍历(for -- range)
1.在遍历时,如果channel没有关闭,则会出现deadlock的错误。
2.在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完毕后退出。
package main import "fmt" func main() { // 定义并初始化chan intChan:=make(chan int,100) // 管道赋值 for i:=1;i<=100;i++{ intChan<-i } // 关闭管道(如果不关闭会报错deadlock) close(intChan) // for-range遍历管道 for v:= range intChan { fmt.Println(v) // 返回值:1...100 } }3.5、gorouting和chnnel结合使用的案例
1.开启一个writeData协程,向管道intChan写入10个整数;
2.开启一个readData协程,从管道intChan内读取10个整数;
3.writeData和readData操作的是同一个管道;
4.主线程需要等待writeData和readData协程都完成工作才退出;
流程图解:
代码实现:
package main import ( "fmt" "time" ) func writeData(intChan chan int) { for i:=0;i<10;i++{ // 写之前等1秒,模拟一边写一边读的场景 time.Sleep(time.Second) // 管道内放入数据 intChan<-i fmt.Println("writeData: ",i) } // 关闭管道(不在写数据之后,就把管道关闭,但还可以继续读管道的数据) close(intChan) } func readData(intChan chan int, exitChan chan bool) { for { // 读之前等1秒,模拟一边写一边读的场景 time.Sleep(time.Second) // 管道内取值,并判断是否取值成功 v, ok := <-intChan if !ok { break } fmt.Println("readData: ",v) } // intChan管道内的所有值全部都取出后,往exitChan写一个数据,并关闭管道 exitChan<-true close(exitChan) } func main() { // 创建2个管道 intChan := make(chan int,10) exitChan := make(chan bool,1) // 调用协程 go writeData(intChan) go readData(intChan,exitChan) // 主进程读取exitChan管道内的数据,取到值之后再退出,否则就一直等待 for { // 管道内取值,并判断是否取值成功 _, ok := <-exitChan if ok { break } } } // 返回值: //writeData: 0 //readData: 0 //writeData: 1 //readData: 1 //writeData: 2 //readData: 2 //writeData: 3 //readData: 3 //writeData: 4 //readData: 4 //writeData: 5 //readData: 5 //writeData: 6 //readData: 6 //writeData: 7 //readData: 7 //writeData: 8 //readData: 8 //writeData: 9 //readData: 93.6、阻塞
编译器在运行时,发现一个管道只有写,而没有读,就会阻塞。(如果有(缓慢的)读取管道内的数据时,就不会阻塞)
举例:管道的容量为10,但是放入管道的数据量超过了10,或者一直没有取出管道内的数据,就会阻塞,报错deadlock;
案例1:一直往管道内写数据,当写入的数据量,超过管道的容量时,就会阻塞,报错deadlock
package main import ( "fmt" ) func writeData(intChan chan int) { for i:=0;i<10;i++{ // 写之前等1秒,模拟一边写一边读的场景 //time.Sleep(time.Second) // 管道内放入数据 intChan<-i fmt.Println("writeData: ",i) } // 关闭管道(不在写数据之后,就把管道关闭,但还可以继续读管道的数据) close(intChan) } func readData(intChan chan int, exitChan chan bool) { for { // 读之前等1秒,模拟一边写一边读的场景 //time.Sleep(time.Second) // 管道内取值,并判断是否取值成功 v, ok := <-intChan if !ok { break } fmt.Println("readData: ",v) } // intChan管道内的所有值全部都取出后,往exitChan写一个数据,并关闭管道 exitChan<-true close(exitChan) } func main() { // 创建2个管道 intChan := make(chan int,5) exitChan := make(chan bool,1) // 调用协程 go writeData(intChan) //go readData(intChan,exitChan) // 主进程读取exitChan管道内的数据,取到值之后再退出,否则就一直等待 for { // 管道内取值,并判断是否取值成功 _, ok := <-exitChan if ok { break } } } // 返回值: fatal error: all goroutines are asleep - deadlock!案例2:在往管道内写数据时,如果如果有协程在(缓慢的)去读/取(消费)管道内的数据,那么就不会阻塞
package main import ( "fmt" "time" ) func writeData(intChan chan int) { for i:=0;i<10;i++{ // 写之前等1秒,模拟一边写一边读的场景 //time.Sleep(time.Second) // 管道内放入数据 intChan<-i fmt.Println("writeData: ",i) } // 关闭管道(不在写数据之后,就把管道关闭,但还可以继续读管道的数据) close(intChan) } func readData(intChan chan int, exitChan chan bool) { for { // 读之前等1秒,模拟一边写一边读的场景 time.Sleep(time.Second) // 管道内取值,并判断是否取值成功 v, ok := <-intChan if !ok { break } fmt.Println("readData: ",v) } // intChan管道内的所有值全部都取出后,往exitChan写一个数据,并关闭管道 exitChan<-true close(exitChan) } func main() { // 创建2个管道 intChan := make(chan int,5) exitChan := make(chan bool,1) // 调用协程 go writeData(intChan) go readData(intChan,exitChan) // 主进程读取exitChan管道内的数据,取到值之后再退出,否则就一直等待 for { // 管道内取值,并判断是否取值成功 _, ok := <-exitChan if ok { break } } } // 返回值: writeData: 0 writeData: 1 writeData: 2 writeData: 3 writeData: 4 readData: 0 writeData: 5 readData: 1 writeData: 6 writeData: 7 readData: 2 readData: 3 writeData: 8 readData: 4 writeData: 9 readData: 5 readData: 6 readData: 7 readData: 8 readData: 93.7、协程求素数的实现
统计1-1000个数字中,哪些是素数?
package main import ( "fmt" ) // 往管道内放入1000个数 func putNum(intChan chan int) { for i := 0; i < 100; i++ { intChan <- i } // 关闭intChan close(intChan) } // 从管道intChan内取数据,判断是否为素数,把素数放入primeChan。取完后往exitChan写入一个true func putPrimeNum(intChan chan int, primeChan chan int, exitChan chan bool) { var flag bool for { // 从管道intChan内取数据 num,ok:=<-intChan // 管道intChan内的数据取完就退出 if !ok { break } // 假设是素数 flag = true // 判断是否为素数 for i:=2;i3.8、channel的使用细节和注意事项
1.channel可以定义为只读或者只写模式(应用场景:把一个可读可写的管道传入一个函数,函数内对管道做下封装,只允许读/写)
只读模式,只写模式的代码定义:
package main import "fmt" func main() { // 定义一个"只写"的管道 var intChanWrite chan<- int intChanWrite = make(chan<- int,3) intChanWrite<-10 // "只写"的管道的不能取数据 // num:=<-intChan // 定义一个"只读"的管道 var intChanRead <-chan int intChanRead = make(<-chan int,3) num:=<-intChanRead fmt.Println(num) // 因为管道内没有数据,这里取不到值 // "只读"的管道的不能写数据 //intChanRead<-10 }2.使用select可以解决从管道内取数据阻塞的问题
package main import ( "fmt" ) func main() { // 定义管道并存放值 intChan := make(chan int,10) for i:=0;i<10;i++{ intChan<-i } stringChan := make(chan string,5) for i:=0;i<5;i++{ stringChan<-"hello"+fmt.Sprintf("%d",i) } // 传统的方式在遍历管道时,如果不关闭管道会deadlock(阻塞) // 实际开发中,不好确认什么时候关闭管道,此时使用select(解决从管道内取数据时,阻塞的问题) for { select { // 如果管道intChan没有关闭,同时又取不到值时,不会deadlock(阻塞)会去下一个case取值 case v:= <-intChan: fmt.Println("从intChan管道内取到的值",v) // 如果管道stringChan没有关闭,同时又取不到值时,不会deadlock(阻塞)会去下一个case取值 case v:= <-stringChan: fmt.Println("从stringChan管道内取到的值",v) // 默认逻辑 default: fmt.Println("管道内取不到值了。。。") return } } }3.协程中使用recover,解决协程中出现panic,导致程序崩溃的问题
package main import ( "fmt" "time" ) func test() { // defer + recover 捕获当前函数抛出的panic错误 defer func() { err:=recover() if err != nil { fmt.Println("test函数发生错误",err) } }() // 函数的代码逻辑(这里故意写的错误代码,触发报错) var testmap map[int]string testmap[0]="sudada" } func main() { go test() // 正常的代码执行(不加recover时,协程报错,整个程序就退出了。加上recover后,协程报错了不影响正常代码的执行) for { fmt.Println("main") time.Sleep(time.Second) } // 返回值: // main // test函数发生错误 assignment to entry in nil map // main }

