Linux基础命令@grep、wc、管道符
目录
- grep
-
- 概念
- 语法
- 作用
-
- 演示一
- 演示二
- 演示三,带选项 -n
- wc
-
- 概念
- 语法
- 作用
-
- wc,不带选项
- -c,统计字节数
- -m,统计字符数
- -l,统计行数
- -w,统计单词数
- 管道符
-
- 语法
- 作用
-
- 演示一
- 演示二
- 演示三
- 演示四
- 演示五
- 总结
grep
概念
grep 是一个在Unix和类Unix系统中广泛使用的文本搜索工具,用于在文件中查找包含特定模式的文本行。其名称来源于"Global Regular Expression Print",最初设计是用于在文本流中查找匹配正则表达式的文本。
语法
grep [-n] 关键字 文件路径
》选项-n:可选填。作用是在结果中显示匹配的行的行号。
》 关键字:必填。表示过滤的关键字,带有空格或其他特殊符号的,建议使用双引号“ ” 将关键字包围起来。
》文件路径:必填。表示要过滤内容的文件路径,可作为内容的输入端口
作用
通过关键字,筛选出指定文件中想要的内容。
演示一
如下图所示,( 我事先在test.txt文件里,写入如图所示的内容 )通过cat指令获取文件test,txt的内容。
然后使用grep指令,针对test.txt文件,过滤出有 “about” 单词的行,如图所示:
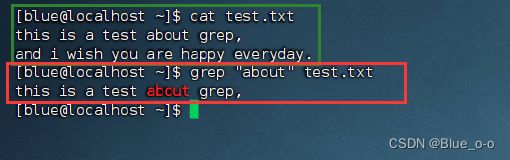
终端只出现了test.txt文件中有 “about” 单词的行的信息,同时对于指定的“about”关键字着重显示。
演示二

对test.txt文件过滤出来有 “i” 关键字的行的信息。并且对于关键字着重的显示。
演示三,带选项 -n

终端出现有“happy” 关键字的行的信息。并且在前面基础上,还多显示了该行在test.txt文件中的第几行。
wc
概念
wc 是一个在 Unix 和类 Unix 系统中使用的命令,用于统计文件中的字节数、字数和行数。wc 的名称来自 “word count”(单词计数)的缩写,但它不仅仅用于计算单词数量,还提供其他计数选项。
语法
wc [ -c -m -l -w ] 文件路径
》选项-c:作用是统计bytes字节的数量。
》选项-m:作用是统计字符数量。
》选项-l:作用是统计行(line)数。
》选项-w:作用是统计单词(words)数量。
》文件路径:文件路径,被统计的文件,可作为内容的输入端口
作用
wc,不带选项
如下,使用cat命令,读取test.txt文件的内容为:
this is a test about grep,
and i wish you are happyeveryday.
使用wc命令读test.txt文件,如下:

终端显示: 2 13 62 test.txt
从左到右,一次代表的信息为:读取文件的行数、读取文件的单词数(根据空格做单词判断的依据)、读取文件的字节数、读取文件的文件名。
那么信息对不对,是不是呢?
对于行数和单词数,我们可以肉眼统计出来,而有多少个字节数,如果嫌麻烦,我们可以通过命令 “ ls -l ” 进行查看,如下:

如上,test.txt文件的大小有62个字节,即test.txt文件内有62个字节数。验证正确。
-c,统计字节数

如上,使用选项 -c,可以单独在终端显示搜索文件的字节数。
-m,统计字符数

如上,使用选项 -m 可以单独显示test.txt文件内容的字符数。
注意:
要区分字节和字符这两个概念:
字节:一个字节是计算机存储的基本单位,通常由8个比特(bits)组成,每个比特可以表示二进制的0或1。字节的最小地址able单元,是计算机中数据传输和存储的基本块,在计算机系统中,存储器、文件大小、网络传输等通常以字节为单位。
字符:字符通常是指人类可读的文本中的一个单元,例如字母、数字、标点符号等,字符可以由一个或多个字节组成,具体取决于所使用的字符编码。计算机中常见的字符编码包括ASCII(一个字节表示一个字符)、UTF-8、UTF-16等。UTF-8使用1到4个字节表示一个字符,而UTF-16使用2或4个字节。
-l,统计行数

如上,使用选项 -l 可以单独显示test.txt文件内容有多少行数。
-w,统计单词数
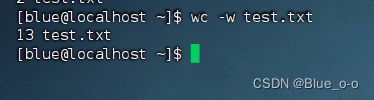
如上命令,使用选项 -w 可以单独显示test.txt文件内容有个单词。
管道符
语法
|
》 管道符 “ | ” ,左边的输出结构,作为右边的输入。
作用
演示一
如上,我们用通过cat命令获取文件test,txt的内容。
接着我们使用管道符,管道符的左边依旧是上述的命令,而管道符的右边是用来统计有多少行数的命令 “wc -l”。如下:

和前面对test.txt文件进行统计有多少行的结果是一样的。这其中还涉及到一个知识点,就是前面对于“ wc ”语法那里对于 ‘ 文件路径 ’的解释:参数‘ 文件路径 ’ 可以作为内容的输入端口有关。
当管道符右边,统计文件或内容中有多少行的命令“ wc -l ” 中缺少文件路径或内容输入,那么管道符左边的结果,将会作为右边 wc 命令的内容输入。
即左边的结果,作为了右边的第二个参数。可以理解为,最终的效果是:
wc -l “this is a test about grep,\r\n and i wish you are happy everyday.”
因此对内容,进行统计有多少行,结果显示为2.
(注:为了方便理解,用\r\n表示换行。)
演示二
以下,我们用 ls 命令的结果,即终端中显示的内容作为结果。
充当管道符右边命令 “ grep ” 的第二个参数。

结果终端过滤显示出来有 “test” 字符串的内容
演示三
以上的演示,可能未能体现出这个管道符的妙用之处,因为上述中对于管道符左边的内容都很少,少到即便是人为去统计都能统计出来。可是,如果你选择要过滤的文件特别特别多呢?而你只需要找到有指定的内容即可,显然再靠人为去寻找、统计是不切实际的,这时便是该管道符的发挥之处了,如下:

如上,命令 “ ls -l /usr/bin | grep gtf ”,表示对 /usr/bin 文件的全部内容,筛选过滤出有 “gtf” 字符串的内容。结果:
终端便只显示了带有“gtf”的信息。
(注:需要留意终端的显示格式,以上是用ls -l 的格式去显示的。)
同样的,我们可以统计一下这个文件具体有多少行,如下:

终端显示结果为1720,即该文件用 ls -l 展开时拥有1720的行数。想想,如果没有管道符这个工具,对于这个量级再人为去找,那可就不太礼貌了。
演示四
管道符还可以多重使用。如下:

“ cat test.txt” 的结果作为 “ grep this ” 的内容输入,
“ cat test.txt | grep this ” 又可以作为 “ grep a ” 的内容输入。
结果终端显示如上,
“ cat test.txt | grep this ”结果为:“ this is a test about grep”。
最终命令为: grep a “ this is a test about grep”
结果显示如上,对于输入内容过滤出有关键字 “ a ”的行数,并且着重显示关键字。
演示五

总结
1、grep
》从文件中通过关键字过滤文件行。
》语法:grep [-n] 关键字 文件路径
》选项-n,可选填。表示在结果中显示匹配的行的行号。
》参数:关键字,必填。表示过滤的关键字,建议使用双引号” ”将关键字包围起来。
》参数:文件路径,必填。表示要过滤内容的文件路径,可作为管道符的输入。
2、wc
》命令计文件的行数、单词数量、字节数、字符数等。
》语法: wc [ -c -m -l -w ] 文件路径
》不带选项默认统计:行数、单词数、字节数
》-c 字节数、-m 字符数、-l 行数、-w 单词数
》参数:被统计的文件路径。可作为管道符的输入。
3、管道符
》将管道符左边命令的结果,作为右边命令的输入