Pandas: 交叉表(crosstab)和透视表(pivot_table)的用法
Pandas版本:V1.5.1
1 交叉表和透视表
总体而言,Pandas中的交叉表和透视表的功能与Excel中的功能类似。为了方便展示这两个方法的效果,先构建如下DataFrame,具体如下:
import pandas as pd
data=pd.DataFrame([['foo','one','small',1],['foo','one','large',5],
['foo','one','medium',3],['foo','two','samll',2],
['foo','two','large',20],['foo','two','medium',7],
['bar','one','small',10],['bar','two','samll',10],
['bar','one','large',10],['bar','two','large',50]],
columns=list('ABCD'))data的结果如下:

1.1 交叉表(crosstab)
Pandas中的crosstab函数中的常见参数及其作用具体如下表:
| 参数 | 参数说明 |
|---|---|
| index | 该参数可以接受array、list、series等类型。该参数指明分组依据,并形成row。 |
| columns | 跟index相同,但其值会形成columns的值。 |
| values | 聚合函数操作的值。 |
| aggfunc | 聚合函数。如果没有指定values,则aggfunc默认统计频率。 |
| rownames | 指定新的row值 |
| colnames | 指定新的columns值 |
| margins | 布尔类型。对所有的行和列进行汇总 |
| margins_name | 指定汇总行/列的名称。 |
| dropna | 布尔类型。默认值为True。当某一列中所有的值都是NULL时,则删除该列。 |
具体用法举例如下:
import numpy as np
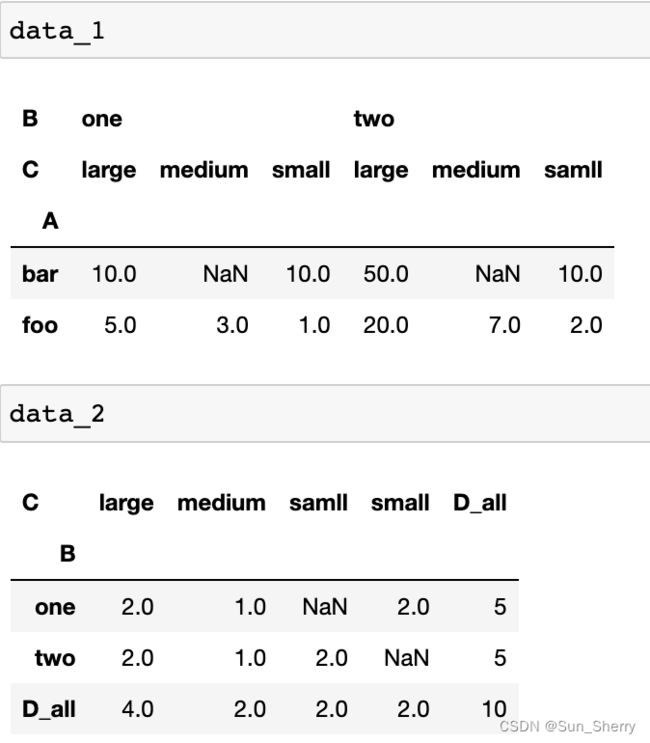
data_1=pd.crosstab(index=data['A'],columns=[data['B'],data['C']],values=data['D'],
aggfunc=np.sum)
data_2=pd.crosstab(index=data['B'],columns=data['C'],values=data['D'],aggfunc='count',
margins=True,margins_name='D_all')其结果如下:
1.2 透视表(pivot_table)
Pandas中的pivot_table()函数中有几个非常重要的参数,其作用具体如下
| 参数 | 参数说明 |
|---|---|
| data | 原始数据。只接收DataFrame类型的输入。 |
| values | 指示将要用于聚合的列。 |
| index | 可以是一个列名,grouper或者是与data同样长度的array。或者这三种组成的list。这些将作为透视表的分组依据,并形成新的row |
| columns | 与index相同。但是新的columns. |
| aggfunc | 可以为单个函数,也可以为多个函数组成的集合类型。当为函数集合时,每个函数的结果会水平排列(作为列的最顶级的索引,列名即为函数名) |
| fill_value | 指定值的来填充缺失值 |
| margins | 布尔类型。是否对所有行和列进行汇总 |
| dropna | 布尔型。当某一列全为NULL值时,dropna=True时删除该列,否则保留 |
| margins_name | 字符串类型。当margins=True时而未指定margins_name时,汇总列的名称为‘All’。而margins_names则指定汇总列的名称。 |
其用法举例如下:
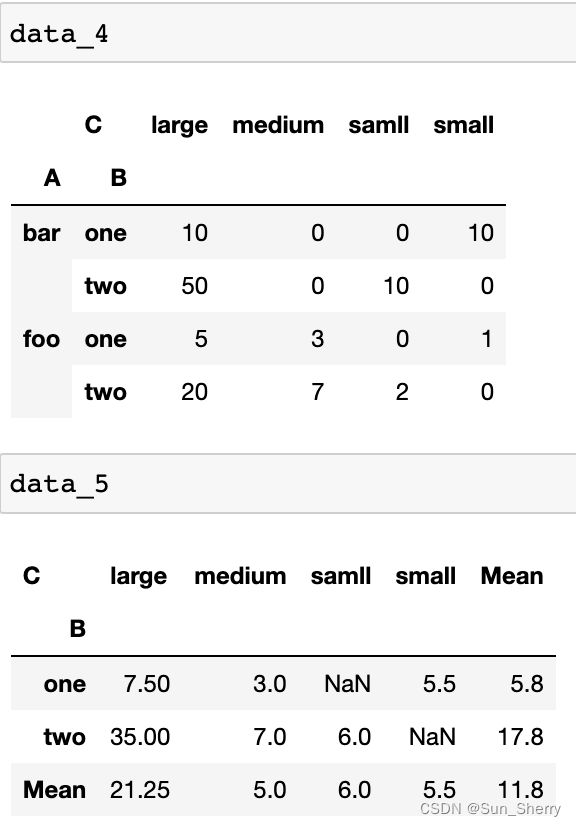
data_4=data.pivot_table(index=['A','B'],values='D',columns='C',
aggfunc=np.sum,
fill_value=0)
data_5=pd.pivot_table(data=data,index='B',columns='C',values='D',
aggfunc='mean',
margins=True,margins_name='Mean')其结果如下:
1.3 总结
Pandas中的交叉表和透视表的作用相似。其计算过程都是先将整个数据集依照index和columns参数指定的数据进行分组,然后使用aggfunc方法运用到values参数指定的数据,最后将结果转化为DataFrame。这两个函数的区别主要如下:
- crosstab只能使用pd.crosstab()的形式,而pivot_table可以同时使用DataFrame.pivot_table()和pd.pivot_table()的形式。使用pd.pivot_table()的时候,需要使用data参数指定数据集。
- 因为pivot_table方法关联到了具体的DataFrame,所以其方法中的参数index、columns、values可以直接写DataFrame的列名,而crosstab中的同名参数就必须使用Series、list等数据类型来指定计算的数据集。
- pivot_table方法可以填充缺失值。
2 案例
下列数据给出了500个用户每人的7月ARPU和8月ARPU金额(部分数据),现需要分析出用户的ARPU掉档情况。

jupyter notebook具体代码如下:
import pandas as pd
data=pd.read_excel('homework_1.xlsx',hearer=0,index_col=0)
bins=list(range(0,5001,500))
data['7月ARPU']=pd.cut(data['7月ARPU'],bins,right=False)
data['8月ARPU']=pd.cut(data['8月ARPU'],bins,right=False)
cross_tab=pd.crosstab(data['7月ARPU'],data['8月ARPU'])
cross_tab=cross_tab.loc[pd.DataFrame.any(cross_tab>0,axis=1)]
cross_tab=cross_tab.div(cross_tab.sum(axis=1),axis=0)
cross_tab=cross_tab.applymap(lambda x:'' if x==0 else str(x*100)[:6]+'%')
def showH1(row):
row=[float(row[item][:-1]) if len(row[item])>0 and row.name>item else 0 for item in row.index]
c=[True if item>30 else False for item in row]
return ['color:red'if v else '' for v in c]
cross_tab.style.apply(showH1,axis=1)其结果如下:
