STL标准库与泛型编程(侯捷)笔记2
STL标准库与泛型编程(侯捷)
本文是学习笔记,仅供个人学习使用。如有侵权,请联系删除。
参考链接
Youbute: 侯捷-STL标准库与泛型编程
B站: 侯捷 - STL
Github:STL源码剖析中源码 https://github.com/SilverMaple/STLSourceCodeNote/tree/master
Github:课程ppt和源码 https://github.com/ZachL1/Bilibili-plus
下面是第二讲的部分笔记:C++标准库体系结构与内核分析(第二讲)
主要介绍分配器allocator,还有容器list的底层实现,讨论iterator traits的设计
文章目录
- STL标准库与泛型编程(侯捷)
-
- 8 源代码之分布 VCGcc
- 9 OOP 面向对象编程 vs GP 泛型编程
- 10 技术基础:操作符重载and模板泛化, 全特化, 偏特化
- 11 分配器
- 12 容器之间的实现关系与分类
- 13 深度探索list(上)
- 14 深度探索list(下)
- 15 迭代器的设计原则和Iterator Traits的作用与设计
- 后记
8 源代码之分布 VCGcc
学这门课应该有的基础:
C++基本语法
模板基础
数据结构和算法的基础
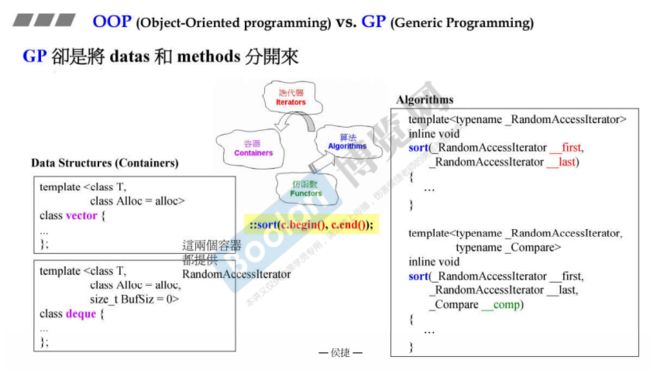
9 OOP 面向对象编程 vs GP 泛型编程
面向对象想要把data和method关联在一起,比如list类内部实现sort函数。

泛型编程想要把data和method分开来,比如vector和deque类没有实现sort函数,而是调用algorithm里面的sort函数,两者分开来。
10 技术基础:操作符重载and模板泛化, 全特化, 偏特化
这部分在侯捷老师的面向对象课程里有详细的介绍,请参考笔者的笔记,里面含有课程的视频链接。
C++面向对象高级编程(侯捷)笔记1
C++面向对象高级编程(侯捷)笔记2
C++程序设计兼谈对象模型(侯捷)笔记
这里补充type_traits里面用到的特化(specialization)的知识
泛化指的是用模板,特化指的是指定模板到具体的类型。下面的代码中__STL_TEMPLATE_NULL指的是 template<> 这种类型,表示空模板。
//type_traits.h文件
// 泛化
template <class _Tp>
struct __type_traits {
typedef __true_type this_dummy_member_must_be_first;
typedef __false_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type;
};
// 特化
__STL_TEMPLATE_NULL struct __type_traits<int> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
__STL_TEMPLATE_NULL struct __type_traits<unsigned int> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};

下图中的allocator这个类也是用到了泛化和特化,比如当allocator指定的是void类型的时候,会调用特化版本的代码。

偏特化:有多个模板参数,只指定部分个参数为特定类型。比如下图中的vector的类型T指定为bool,而后面的Alloc分配器没有指定类型,这就是一种偏特化。是一种个数的偏特化。
另外下图中iterator_traits中也用到了偏特化,只不过这里是对指针类型的一个偏特化,如果传入的是T*,会有一种处理方式。这种偏特化是范围的偏特化,指的是从T类型,范围缩到T *指针类型。

11 分配器
分配器 allocators
先谈operator new() 和malloc()
malloc的内存实际分配情况:
下图中的内存分配,蓝色是块是实际我们需要malloc给我们分配的空间,灰色的块是debug mode需要添加的内存空间,上下两个红色的块是cookie,它记录分配内存的大小(《深度探索c++对象模型》书上称为记录元素的大小,这个指的是delete时,该delete多大的内存空间,即delete掉的数组维度大小),绿色的部分指的是为了内存大小的对齐。

STL对allocator的使用

VC++6编译器所附的标准库
allocator分配内存的时候,调用operator new,而operator new调用c语言的malloc。
而释放内存的时候,调用operator delete,而operator delete调用c语言的free。
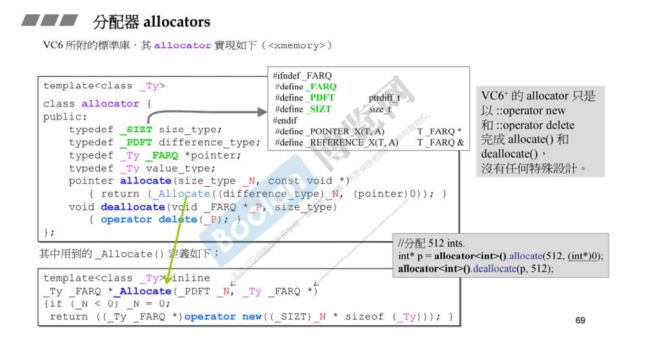
测试,分配512个int型数据:需要指定分配的大小,释放时也要指定大小
// VC的allocate第二个参数没有默认值,需要自己给定,任意值都行
int* p = allocator<int>().allocate(512, (int *)0); // allocator()是一个临时对象
allocator<int>().deallocate(p, 512);
BC5编译器所附的标准库对allocator的使用
_RWSTD_COMPLEX_DEFAULT(a)就是a
所以可以看到下面的分配器用的就是allocator

那么BC5编译器对于allocator的内部设计呢?分配内存和回收内存用的还是operator new和operator delete,底部还是用c语言的malloc和free完成,和VC6的实现别无二致。
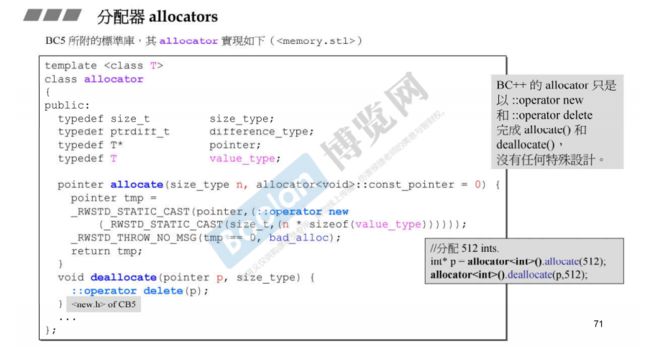
接着示范BC5分配器的使用
测试,分配512个int型数据:需要指定分配的大小,释放时也要指定大小
// BC的allocate第二个参数有默认值为0
int* p = allocator<int>().allocate(512); // allocator()是一个临时对象
allocator<int>().deallocate(p, 512);
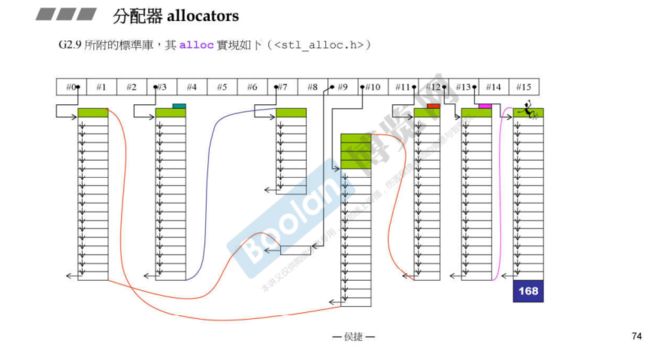
GNU C++(G++) 2.9版本所附的标准库
分配内存和回收内存用的还是operator new和operator delete,底部还是用c语言的malloc和free实现,和上面相同。
参见右下角的说明,这个分配器并没有被SGI STL header引入,即没有被使用。

那GNU C++2.9对allocator的使用是怎么样的呢?
它用的是一个名字叫做alloc的分配器,如下图所示。

G++2.9 alloc的实现如下图所示,共有16条链表,每一条链表负责特定大小的区块,编号为#0的链表负责大小为8B的内存块,编号为#1的链表负责大小为8 x 2 = 16B的内存块,编号为#3的链表负责大小为8 x 3 = 24B的内存块,…,以此类推,每次增加8B。每一条链表都是一次用malloc分配的一大块内存(带cookie),然后切分成小的标准块(不带cookie),当容器需要内存的时候,alloc就会按照需要的大小(变成8B的倍数)在链表中查找进行分配,这样实现在分配小块的时候就不需要存储cookie的开销了。
G++4.9所附的标准库,它的分配器实现
名字叫做new_allocator, 这个4.9版本默认又不再使用alloc分配器,而是继续调用operator new 和operator delete。
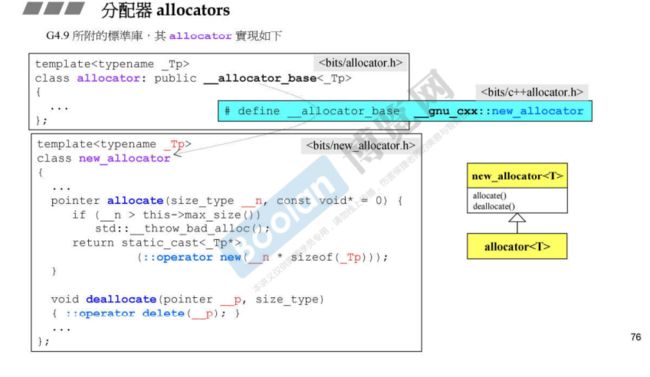
G++4.9所附的标准库中的__pool_alloc就是G++2.9版本的alloc分配器

如果想要使用这个分配器,语法是什么呢?
vector<string, __gnu_cxx::__pool_alloc<string>> vec;// __gnu_cxx是一个命名空间
12 容器之间的实现关系与分类
容器,结构与分类
下图中缩进的函数:下图中的rb_tree(红黑树)下面有4个set,map,multiset,multimap缩进,这表示下面四个和rb_tree是衍生关系(复合composition关系,has-a),拿set举例,表示set里面有(has a)1个rb_tree做底部,拿heap举例,表示heap里面有一个vector做底部,拿priority_queue举例,它是heap的缩进,表示priority_queue里面有一个heap作为底部,等等。

13 深度探索list(上)
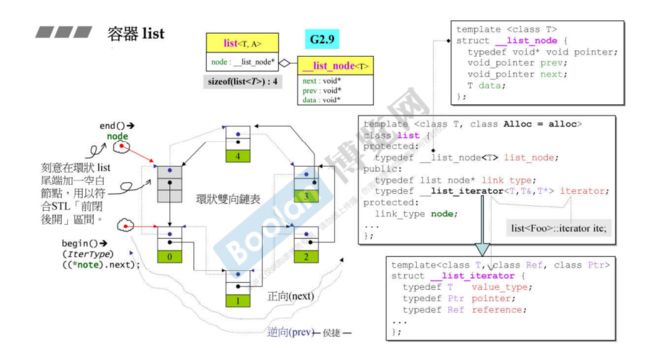
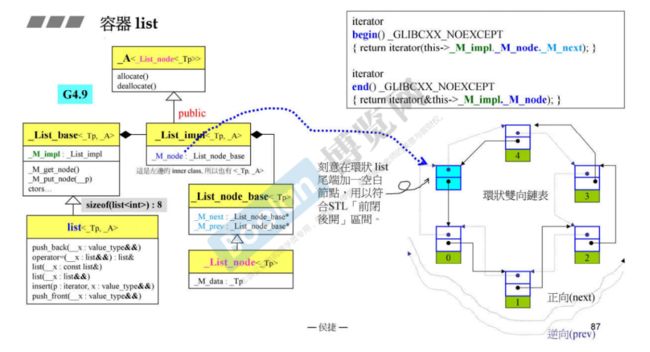
容器list
容器list是双向链表:底部实现是环状双向链表
下面是以GNU C++2.9版本进行介绍
list内部除了存data之外,还要存一个前向指针prev和一个后向指针next。
list的iterator,当迭代器++的时候,是从一个节点走到下一个节点,是通过访问next指针实现的。
template<class T>
struct __list_node {
// 设计不理想,后面需要类型转型
typedef void* pointer; // 这里__list_node中竟然有一种指向void的指针,而不是指向自己类型的指针
void_pointer prev;
void_pointer next;
T data;
};
template<class T, class Alloc = alloc>
class list {
protected:
typedef __list_node<T> list_node;
public:
typdef list_node* link_node;
typedef __list_iterator<T, T&, T*> iterator;
protected:
link_type node;
...
};
template<class T, class Ref, class Ptr>
struct __list_iterator {
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
...
};
list’s iterator
下面看list的迭代器
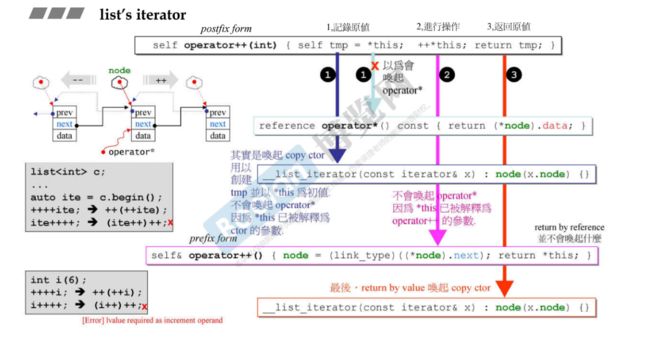
__list_iterator 这个类中主要有两部分:一部分是一堆typedef,另一部分是操作符的重载,如下图所示。

看迭代器iterator,迭代器的++操作
++操作有两种,一种是++ite,另一种是ite++,分别是前置(prefix)和后置(postfix)
先看prefix form:通过取出next指针,指向链表的下一个节点,实现迭代器++的操作。
self&
operator++() // ++操作符重载
{
// node是一个指向结构体__list_node的指针
// 取出结构体里面的成员next指针
node = (link_type)((*node).next); // link_type是指针类型
return *this;
}
// 结构体如下所示
template<class T>
struct __list_node {
typedef void* pointer;
void_pointer prev;
void_pointer next;
T data;
};
再看postfix form:用一个int参数operator++(int) 表示后++,当使用后置递增符号(如ite++)时,意味你想要递增迭代器,但在递增之前返回其先前的值。
self
operator++(int) //++操作符重载
{
self tmp = *this; // 1.记录原值
++*this; // 2.前进一个位置
//整个操作 ++*this 的结果是递增迭代器并返回递增后的迭代器的引用
return tmp; // 3.返回原来的值
}
这里的 self tmp = *this;没有调用operator*这个操作,而是调用拷贝构造的函数,把后面*this解释为拷贝构造的参数
__list_iterator(const iterator& x): node(x.node) {}
再看这里的第2步++*this;,它也没有调用operator* 这个操作,而是因为++在前,调用前置++操作(进行node指向next指针,实现真正的迭代器前进),这里的*this被解释为operator++的参数。
*this 指向的是链表节点,通过 ++*this 可以使得链表迭代器前进到下一个节点。
template<class T,class Ref,class Ptr>
struct __list_iterator {
typedef __list_iterator<T,T&,T*> iterator;
typedef __list_iterator<T,Ref,Ptr> self;
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef __list_node<T>* link_type;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
link_type node; //迭代器内部需要一个普通指针,指向list的节点
//构造函数
__list_iterator(link_type x):node(x) {}
__list_iterator() {}
__list_iterator(const iterator& x):node(x.node) {}
reference operator*() const { return (*node).data;}
pointer operator->() const {return &(operator*());}
//前向迭代器
self& operator++(){ // 前置++ite
node = (link_type)((*node).next);
return *this;
}
self operator++(int){ // 后置ite++
self tmp = *this;
++*this;
return tmp;
}
//后向迭代器
self& operator--(){ // 前置--ite
node=(link_type)((*node).prev);
return *this;
}
self operator--(int){ // 后置ite--
self tmp = *this;
--*this;
return tmp;
}
};
这里的代码参考:https://www.cnblogs.com/ybf-yyj/p/9843391.html
14 深度探索list(下)
GNU C++2.9版本和GNU C++ 4.9版本关于list中iterator的设计差别
G2.9中iterator需要传三个模板参数
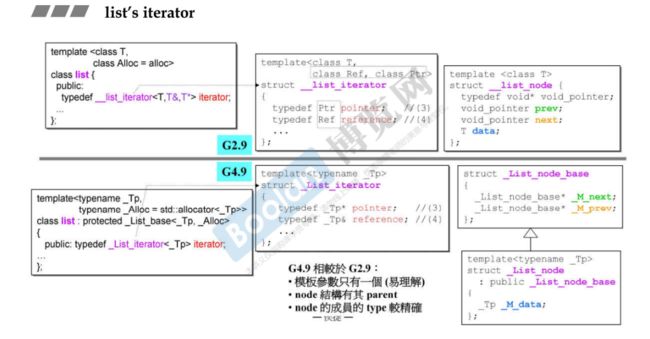
G2.9中list的结构
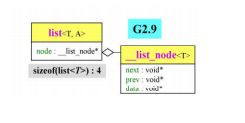
G4.9中list的结构:继承关系更加复杂
15 迭代器的设计原则和Iterator Traits的作用与设计
Iterator需要遵循的原则
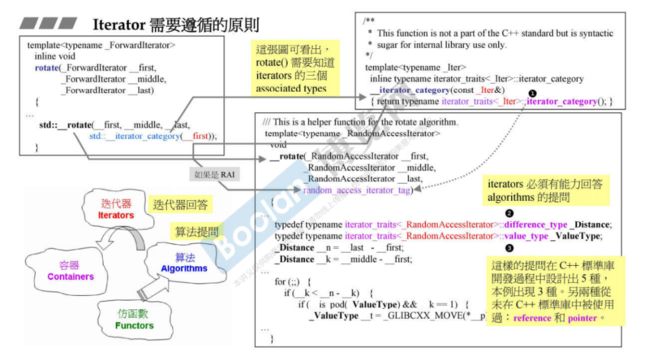
看一下rotate函数,它的参数里调用std::__iterator_category,里面返回iterator_category,这是iterator的一个属性,下面图还有另外两个属性,difference_type和value_type,这里共涉及三个associated types(相关的类型),另外还有两种,分别是reference和pointer。也就是说共有5种associated types。
算法algorithm模块和容器container彼此独立,中间需要迭代器iterator进行交流
iterator必须提供的5种associated types,刚才上面介绍过,如下图所示:iterator_category, value_type, pointer, reference, difference_type。
difference指的是距离, 一个容器中两个iterator的距离
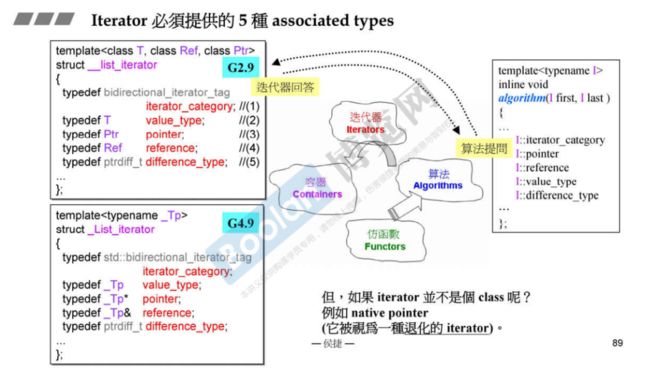
为什么需要traits?指针也被看作是一种退化的iterator,但指针并不是一个类,自然无法在类中定义上述的5种associated types。
traits机制必须有能力分辨它所获得的iterator是class iterator T还是native pointer to T(native pointer,原生指针,指的是non class(template) iterators,它无法定义associated type)
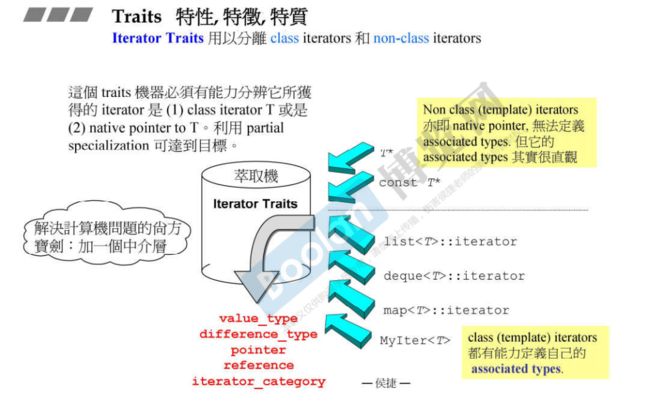
iterator traits用来分离class iterator和non-class iterator

当想知道一个迭代器的value type是什么的时候,不能直接I::value_type,而是
iterator_traits<I>::value_type
这就涉及到iterator_traits的偏特化(指针是范围上的偏特化,前文讲过),如果传入的是指针T*,它就是调用上图中的2或者3,直接定义T为value_type类型,如果传入的是class iterator,那就直接定义I::value_type为value_type。
完整的iterator_traits,这里就全部列出了5个asscicated types,以及偏特化处理传入的是指针的情况

后面还有各种类型的traits,比如type traits, char traits, allocator traits, pointer traits, array traits等等
后记
这是系列笔记连载,会继续更新。