mysql之视图&mysql连接案例&索引
文章目录
- 一、视图
-
- 1.1 含义
- 1.2 操作
-
- 1.2.1 创建视图
- 1.2.2 视图的修改
- 1.2.3 删除视图
- 1.2.4 查看视图
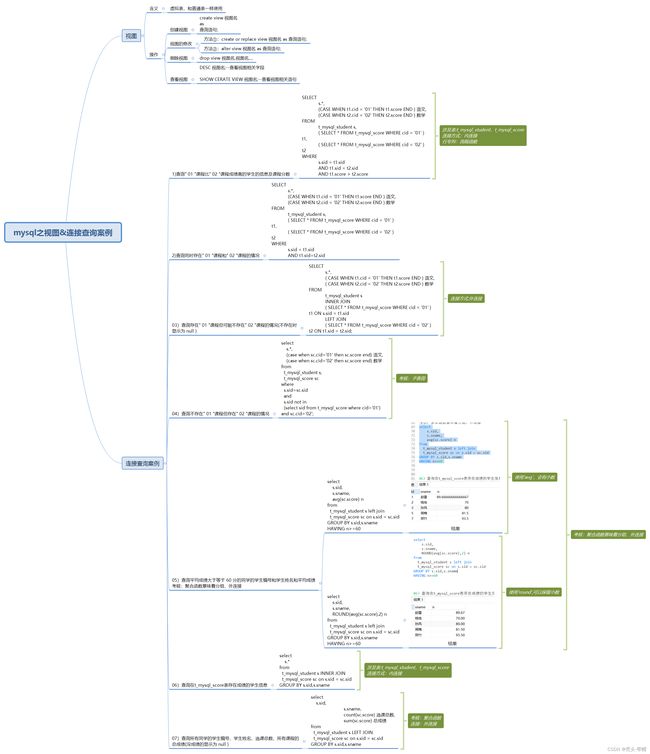
- 二、连接案例
-
- 01)查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
- 02)查询同时存在" 01 "课程和" 02 "课程的情况
- 03)查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
- 04)查询不存在" 01 "课程但存在" 02 "课程的情况
- 05)查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
- 06)查询在t_mysql_score表存在成绩的学生信息
- 07)查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
- 三、流程图
- 四、索引
-
- 4.1 什么是索引
- 4.2 为什么要使用索引
- 4.3 优点
- 4.4 缺点
- 4.5何时不使用索引
- 4.6 索引何时失效
- 4.7 索引分类
一、视图
1.1 含义
虚拟表,和普通表一样使用
1.2 操作
1.2.1 创建视图
create view 视图名
as
查询语句;
1.2.2 视图的修改
方法①:create or replace view 视图名 as 查询语句;
方法②:alter view 视图名 as 查询语句;
1.2.3 删除视图
drop view 视图名,视图名,…
1.2.4 查看视图
DESC 视图名;–查看视图相关字段
SHOW CERATE VIEW 视图名;–查看视图相关语句
二、连接案例
01)查询" 01 “课程比” 02 "课程成绩高的学生的信息及课程分数
SELECT
s.*,
(CASE WHEN t1.cid = '01' THEN t1.score END ) 语文,
(CASE WHEN t2.cid = '02' THEN t2.score END ) 数学
FROM
t_mysql_student s,
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHERE
s.sid = t1.sid
AND t1.sid = t2.sid
AND t1.score > t2.score
02)查询同时存在" 01 “课程和” 02 "课程的情况
SELECT
s.*,
(CASE WHEN t1.cid = '01' THEN t1.score END ) 语文,
(CASE WHEN t2.cid = '02' THEN t2.score END ) 数学
FROM
t_mysql_student s,
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHERE
s.sid = t1.sid
AND t1.sid=t2.sid
03)查询存在" 01 “课程但可能不存在” 02 "课程的情况(不存在时显示为 null )
SELECT
s.*,
( CASE WHEN t1.cid = '01' THEN t1.score END ) 语文,
( CASE WHEN t2.cid = '02' THEN t2.score END ) 数学
FROM
t_mysql_student s
INNER JOIN
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1 ON s.sid = t1.sid
LEFT JOIN
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2 ON t1.sid = t2.sid;
04)查询不存在" 01 “课程但存在” 02 "课程的情况
select
s.*,
(case when sc.cid='01' then sc.score end) 语文,
(case when sc.cid='02' then sc.score end) 数学
from
t_mysql_student s,
t_mysql_score sc
where
s.sid=sc.sid
and
s.sid not in
(select sid from t_mysql_score where cid='01')
and sc.cid='02';
05)查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
select
s.sid,
s.sname,
avg(sc.score) n
from
t_mysql_student s left join
t_mysql_score sc on s.sid = sc.sid
GROUP BY s.sid,s.sname
HAVING n>=60
06)查询在t_mysql_score表存在成绩的学生信息
select
s.*
from
t_mysql_student s INNER JOIN
t_mysql_score sc on s.sid = sc.sid
GROUP BY s.sid,s.sname
07)查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
select
s.sid,
s.sname,
count(sc.score) 选课总数,
sum(sc.score) 总成绩
from
t_mysql_student s LEFT JOIN
t_mysql_score sc on s.sid = sc.sid
GROUP BY s.sid,s.sname
三、流程图
四、索引
4.1 什么是索引
索引是一种特殊的数据库结构,由数据表中的一列或多列组合而成,可以用来快速查询数据表中有某一特定值的记录
4.2 为什么要使用索引
使用索引可以很大程度上提高数据库的查询速度,还有效的提高了数据库系统的性能。
4.3 优点
- 通过创建唯一索引可以保证数据库表中每一行数据的唯一性
- 可以给所有的 MySQL列类型设置索引。
- 可以大大加快数据的查询速度,这是使用索引最主要的原因
- 在实现数据的参考完整性方面可以加速表与表之间的连接。
- 在使用分组和排序子句进行数据查询时也可以显著减少查询中分组和排序的时间
4.4 缺点
- 创建和维护索引组要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
- 索引需要占强盘空间,除了数据表占数据空间以外,每一个索引还要占一定的物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态维护,这样就降低了数据的维护速度。
4.5何时不使用索引
- 表记录太少
- 经常增删改的表
- 数据重复且分布均匀的表字段,只应该为经常查询和最经常排序的数据列建立索引(如果某个数据类包含太多的重复数据,建立索引没有太大意义)
- 频繁更新的字段不适合创建索引(会增加10负担)
- where条件里用不到的字段不创建索引
4.6 索引何时失效
- like以通配符%开头索引失效
- 当全表扫描比走索引查询的快的时候,会使用全表扫描,而不走索引
- 字符串不加单引号索引会失效
- where中索引列使用了函数 (例如substring字符串截取函数)
- where中索引列有运算(用了< or> 右边的索引会失效,用<= or>= 索引不会失效)
- is null可以走索引,is not null无法使用索引 (取决于某一列的具体情况)
- 复合索引没有用到左列字段(最左前缀法则,如果没用用到最左列索引,或中间跳过了某列有索引的列,索引会部分失效)
- 条件中有or,前面的列有索引,后面的列没有,索引会失效。想让索引生效,只能将or条件中的每个列都加上索引
4.7 索引分类
CREATE TABLEt ‘Iog’(
‘id’ varchar(32) NOT NULL COMMENT唯一标识
‘ip’ varchar(15) NOT NULL COMMENT ‘IP地址’,
‘userid’ varchar(32) NOT NULL COMMENT ‘用户ID’,
‘moduleid’ varchar(32) NOT NULL COMMENT ‘模块ID’,
‘content’ varchar(500) NOT NULL COMMENT ‘日志内容’,
‘createdate’ timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建日期’,
‘url’ varchar(100) DEFAULT NULL COMMENT ‘请求URL地’,
PRIMARY KEY (‘id’)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
–1)普通索引:是最基本的索引,它没有任何限制;
–0.762s
select * from t_log;
– 建索引前0.12s
select * from t log where moduleid =10040199’;
– 创建索引所花费的时间:1.593s
Create index idx_moduleid on t_log(moduleid);
– 建索引前 0.001s
select from t_log where moduleid =10040199’;
– 可以查看走过的索引
EXPLAIN select * from t_log where moduleid =‘10040199’;
2)唯一索引:与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一;
– Duplicate entry ‘/quartz/queryJobLst’ for key ‘idx_ur’ 有重复列段
create UNIQUE index idx_url on t_log(url);
drop index idx_url on t_log;
– 3)主键索引:是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值;
– 主键索引所花费的时间: 0s
select * from t_log where id =‘07489cdafd6d4a3489884cd3c00c7b27’;
EXPLAIN select * from t log where id =07489cdafd6d4a3489884cd3c00c7b27’
– 4)组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时道循量左前缀集合;
– 花费的时间:3.959s
create index idx_userid_moduleid_url on t_log(userid,moduleid,url);
– 走组合索引
EXPLAIN select * from t_log where userid = " and moduleid = " and url = ";
EXPLAIN select * from t_log where userid = " and moduleid = ";
EXPLAIN select * from t_log where userid = ";
EXPLAIN select * from t_log where userid = " and url = ";
– 不走组合索引
EXPLAIN select * from t_log where moduleid = ";
EXPLAIN select * from t log where url = ";
EXPLAIN select * from t_log where moduleid = " and url = ";
4.创建索引
CREATE[UNIQUE]FULLTEXT]INDEX 索引名 ON 表名(字段名[(长度][ASCIDESCJ)